联邦学习建模的多环节自定义优化方法、装置、设备和存储介质
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及隐私计算领域,尤其涉及隐私计算发起方在联邦建模过程中的模型优化。
背景技术
在如今的大数据和人工智能时代,个人信息隐私保护成为人们广泛关注的焦点,关乎个人、企业乃至国家的利益,隐私计算技术随之应运而生。受限于法律法规、政策监管、商业机密、个人隐私等数据隐私安全上的约束,多个数据来源方无法直接交换数据,形成“数据孤岛”现象,制约着人工智能模型能力的进一步提高。在人工智能大数据应用的大背景下,近年来比较火热的联邦学习也是隐私计算领域主要推广和应用的方法。联邦学习(Federated Learning)是一种分布式机器学习技术,其核心思想是通过在多个拥有本地数据的数据源之间进行分布式模型训练。
传统优化模型超参数搜索的方法有网格搜索(GridSearchCV)、随机搜索(RandomizedSearchCV)、遗传算法(GA)。对于联邦模型优化过程中的超参数选择问题,几种方法普遍存在的问题是:
1.对于网格搜索,我们要对每个超参数提前列出可能选择的超参值,多个超参数形成各种组合。如果超参值过多,组合情况就非常大,计算时间会指数级上升,如果超参值过少,又很难找到效果好的超参值。
2.遗传算法的主要缺点是收敛速度慢,并且无确定的终止准则。在联邦学习中,计算时间会更久。
3.随机搜索在搜索最优超参数效率上比网格搜索相对提升了超参数搜索效率,但效果提升有限。它的过程和网格搜索类似,但不是尝试所有的可能组合,而是选择每一个超参数的一个随机值,这样通过设定搜索次数,选择相对较少的参数组合,同时又能多探索每个超参数的可能性。
隐私计算发起方在应用联邦建模过程中,由于联邦学习消耗的计算资源和时间比较多,可能出现训练模型时间过长,或者达不到很好的模型效果。
发明内容
为了克服上述技术缺陷,本发明的第一个方面提供一种联邦学习建模的多环节自定义优化方法,其包括:
步骤S1:从多个拥有本地数据的数据源获取原始特征数据;
步骤S2:对原始特征数据进行特征工程,特征工程包括特征清洗、特征预处理、特征选择以及特征降维,所述特征清洗选自删除异常值、补充缺失值或者控制采样比例中的一种或多种,所述特征预处理选自归一化、标准化、onehot中的一种或多种,所述特征选择基于IV或VIF,所述特征降维基于PCA或LDA;
步骤S3:选择LightGBM、纵向神经网络或Logistic Regression作为模型;
步骤S4:采用贝叶斯优化库中的HpyerOpt或Optuna对步骤S3中选择的模型进行超参数优化,从而确定最优超参数组合;
步骤S5:将步骤S2筛选出的特征数据和步骤S4获得的最优超参数组合代入步骤S3中选择的模型并训练模型,从而得到优化后的联邦学习模型。
进一步地,联邦学习建模的多环节自定义优化方法进一步包括:步骤S6:对比上一次优化后的联邦学习模型与步骤S5获得的优化后联邦学习模型,覆盖并保存效果最优的联邦学习模型,输出当前效果最优的联邦学习模型。
进一步地,在步骤S3中,最适宜业务场景的模型选择顺序为:最适宜业务场景的模型排序:LightGBM>纵向神经网络>Logistic Regression;如果计算资源和时间足够,模型选择排序为:纵向神经网络>LightGBM>Logistic Regression。
进一步地,所述联邦学习包括纵向联邦学习、横向联邦和联邦迁移学习。
本发明的第二个方面提供一种联邦学习建模的多环节自定义优化装置,其包括:
特征输入模块,所述特征输入模块用于从多个拥有本地数据的数据源获取原始特征数据;
特征工程模块,所述特征工程模块用于对原始特征数据进行特征工程,特征工程包括特征清洗、特征预处理、特征选择以及特征降维,所述特征清洗选自删除异常值、补充缺失值或者控制采样比例中的一种或多种,所述特征预处理选自归一化、标准化、onehot中的一种或多种,所述特征选择基于IV或VIF,所述特征降维基于PCA或LDA;
模型选择模块,所述模型选择模块用于选择LightGBM、纵向神经网络或LogisticRegression作为模型;
超参数优化模块,所述超参数优化模块用于采用贝叶斯优化库中的HpyerOpt或Optuna对选择的模型进行超参数优化,从而确定最优超参数组合;
模型训练模块,所述模型训练模块用于将特征工程模块筛选出的特征数据和超参数优化模块获得的最优超参数组合代入选择的模型并训练模型,从而得到优化后的联邦学习模型。
进一步地,联邦学习建模的多环节自定义优化装置进一步包括:输出模块,所述输出模块用于对比上一次优化后的联邦学习模型与步骤S5获得的优化后联邦学习模型,覆盖并保存效果最优的联邦学习模型,输出当前效果最优的联邦学习模型。
进一步地,最适宜业务场景的模型选择顺序为:最适宜业务场景的模型排序:LightGBM>纵向神经网络>Logistic Regression;如果计算资源和时间足够,模型选择排序为:纵向神经网络>LightGBM>Logistic Regression。
进一步地,所述联邦学习包括纵向联邦学习、横向联邦和联邦迁移学习。
本申请的第三个方面提供一种电子设备,其包括:存储器、处理器以及存储于所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述联邦学习建模的多环节自定义优化方法中的步骤。
本申请的第四个方面提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述联邦学习建模的多环节自定义优化方法中的步骤。
本申请中的缩略语和关键术语定义如下:
特征工程:是指用工程化的方式从原始数据中筛选出更好的数据特征,并获得能够输入给模型进行训练的数据。
LR:Logistic Regression,逻辑回归算法。
LightGBM:一种树模型算法。
IV:Information Value,信息价值,评估数据特征在模型训练中的价值程度。
WOE:Weight of Evidence,证据权重,描述根据真实值分组后,数据特征在其分箱中的权重。
VIF:variance inflation factor,方差膨胀系数,衡量回归问题中共线性严重程度的值。
AutoML:是Google的自动化AI平台,提供许多让机器学习更便捷和高效的开源方法和过程。
Bayesian Optimization(贝叶斯优化):主要用来解决计算成本很高的黑盒算法优化问题。在AutoML中,Bayesian Optimization(贝叶斯优化)问题下,有一个名字也叫Bayesian Optimization的优化库,两者不是一个概念,前者包含后者的关系。
HyperOpt:distributed HPO package implemented with a Tree of ParzenEstimators。
Optuna:automatic HPO framework that allows to dynamically constructthe search space。
PCA:Principal Component Analysis,主成分分析法,是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
LDA:Linear Discriminant Analysis,线性判别分析法,是模式识别的经典算法,LDA的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同样样例的投影尽可能接近、异样样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。其实可以用一句话概括:就是“投影后类内方差最小,类间方差最大”。LDA是一种有监督的学习的降维算法。
Onehot:独热编码,属于一种数据预处理方式,onehot编码又叫独热编码,其为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。Onehot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
采用了上述技术方案后,与现有技术相比,具有以下有益效果:
其他的联邦学习优化技术,多是在某一环节上进行优化。相对于其他联邦学习优化技术,本方案提供的是一整套的优化方案,涵盖了特征工程优化、模型选择、超参数优化等环节,在模型训练的时候可以给使用方多种选择,能够获得更好的优化效果。特征工程阶段根据数据和特征就有多种可选方案,比如特征清洗、特征预处理、特征选择有许多种处理方式,文中介绍的是比较有效有借鉴意义的方法。超参数优化也有其他一些优化库可替代,推荐的AutoML优化库中保护很多优化开源库,另外其他python package,例如scikit-learn,也有类似的超参数优化库。本专利站在联邦学习使用方角度,利用数据特征工程手段和超参数优化方案,用更高效的方式优化联邦模型,并得到更好的模型效果,节省算力资源和运行时间,可以解决隐私计算发起方调试模型时效率不高的问题。
附图说明
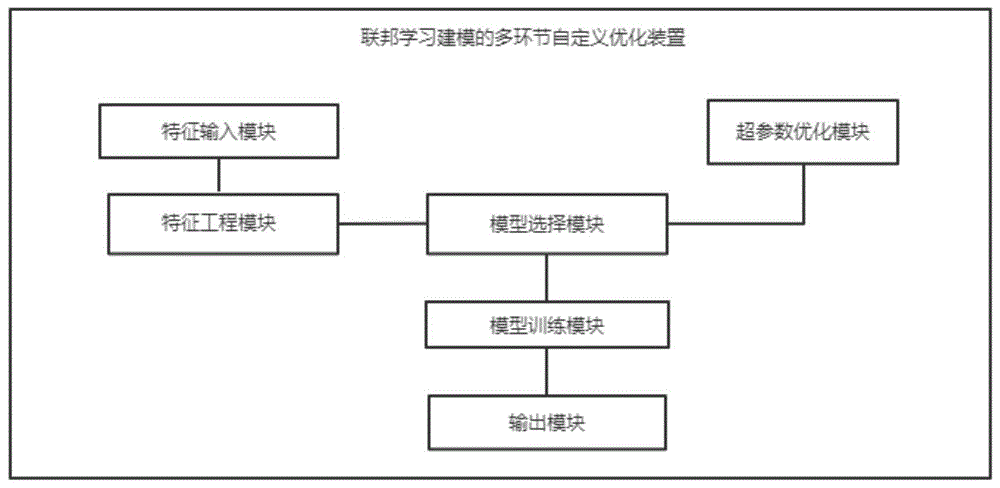
图1为本申请一实施例的联邦学习建模的多环节自定义优化装置的结构模块图;
图2为本申请一实施例的联邦学习建模的多环节自定义优化方法的流程图。
具体实施方式
以下结合附图与具体实施例进一步阐述本发明的优点。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
通常隐私计算发起方在应用联邦学习任务的过程中,首先需要对数据做很多特征工程的工作,然后需要在很多模型中选择模型,同时每个模型又需要调试很多超参数。联邦学习模型效果的好坏取决于特征工程、模型选择和超参数优化。
本实施例提供的联邦学习优化方案是一整套优化过程,其中有很多可选方案。
特征工程阶段根据数据和特征就有多种可选方案,比如特征清洗、特征预处理、特征选择有许多种处理方式,文中介绍的是比较有效有借鉴意义的方法。
超参数优化也有其他一些优化库可替代,推荐的AutoML优化库中保护很多优化开源库,另外其他python package,例如scikit-learn,也有类似的超参数优化库。
现有的联邦学习优化技术大多是在某一环节上进行优化。但是本发明提供的是一整套的优化方案,涵盖了特征工程优化、模型选择、超参数优化等环节,在模型训练的的时候可以给使用方多种选择,能够获得更好的优化效果。
如图1所示,本实施例提供一种联邦学习建模的多环节自定义优化装置包括:特征输入模块、特征工程模块、模型选择模块、超参数优化模块,模型训练模块和输出模块。本实施例是应用在纵向联邦学习问题上。对于横向联邦和联邦迁移学习问题,也可以同样应用本专利的方法做优化。
所述特征输入模块用于从多个拥有本地数据的数据源获取原始特征数据。
所述特征工程模块用于对原始特征数据进行特征工程,特征工程包括特征清洗、特征预处理、特征选择以及特征降维,所述特征清洗选自异常值、缺失值、采样比例中的一种或多种,所述特征预处理选自归一化、标准化、onehot中的一种或多种,所述特征选择基于IV或VIF,所述特征降维基于PCA或LDA。
所述模型选择模块用于选择LightGBM、纵向神经网络或Logistic Regression作为模型。
所述超参数优化模块用于采用贝叶斯优化库中的HpyerOpt或Optuna对选择的模型进行超参数优化,从而确定最优超参数组合。
所述模型训练模块用于将特征工程模块筛选出的特征数据和超参数优化模块获得的最优超参数组合代入选择的模型并训练模型,从而得到优化后的联邦学习模型。
所述输出模块用于对比上一次优化后的联邦学习模型与优化后联邦学习模型,覆盖并保存效果最优的联邦学习模型,输出当前效果最优的联邦学习模型。
如图2所示,采用上述联邦学习建模的多环节自定义优化装置进行联邦学习建模的多环节自定义优化方法包括以下步骤:
步骤S1:通过特征输入模块从多个拥有本地数据的数据源获取原始特征数据。
联邦学习是隐私计算核心技术,是一种分布式机器学习技术,其核心思想是通过在多个拥有本地数据的数据源之间进行分布式模型训练。因此,联邦学习优化的第一步就是通过特征输入模块从多个拥有本地数据的数据源获取原始特征数据。
步骤S2:通过特征工程模块对原始特征数据进行特征工程,特征工程包括特征清洗、特征预处理、特征选择以及特征降维。
隐私计算发起方在应用联邦建模过程中,由于联邦学习消耗的计算资源和时间比较多,可能出现训练模型时间过长,或者达不到很好的模型效果。因此,优化模型的其中一个重要方面就是对原始特征数据进行特征工程,包括特征清洗、特征预处理、特征选择、特征降维或者其他特征加工方法。
特征清洗可以自定义选择为删除异常值、补充缺失值或者控制采样比例中的一种或多种。特征预处理可以自定义选择为归一化、标准化或者onehot中的一种或多种。特征选择可以自定义选择基于IV或VIF。特征降维可以自定义选择基于PCA或LDA。
特征工程主要目的是处理数据,然后得到可以放到模型训练的数据。由于联邦学习对资源消耗比较大,所以特征工程另一个目的是要精简数据特征维度,避免大量无效低效特征进入模型训练,浪费大量计算资源。因此特征选择和特征降维是联邦学习中很重要的步骤。
特征选择:
(1)基于IV(即信息价值)的特征选择
在联邦学习分类模型中,我们需要对信息量较小的自变量进行筛选,节约计算资源。考量筛选自变量的因素有很多,比如自变量的预测能力、相关性、可解释性等等,IV值可以作为量化自变量预测能力的指标。一般认为IV<0.02是无用特征,0.02 而计算IV是以WOE为基础的,计算WOE之前需要对变量做分箱处理,对于每个分箱计算一个WOE值,记作WOE bin_n和bin_p分别是分箱中的负样本和正样本数量,total_n和total_p分别是全量数据中的负样本和正样本数量。 然后计算IV值,每个分箱的IV值记作IV 最终IV值是: (2)基于VIF(即方差膨胀系数)的特征选择 在联邦学习回归模型中,VIF是衡量特征共线性严重程度的量,换言之就是某特征跟其他特征相似程度的量,如果很相似就可以移除该特征。 一般VIF>10可以认为是严重共线性,可以移除其中一个变量。 特征降维: (1)基于PCA(即主成分分析法)的特征降维 主要方法是将原本具有一定相关性的指标,重新组成一组较少个数的互不相关的新指标,达到特征降维的目的。python中的sklearn有现成的包: 1.from sklearn.decomposition import PCA 2.PCA().fit_transform(data) (2)基于LDA(即线性判别分析法)的特征降维 python中的sklearn有现成的包: 1.from sklearn.lda import LDA 2.LDA().fit_transform(data,target) 步骤S3:通过模型选择模块选择LightGBM、纵向神经网络或Logistic Regression作为模型。 LR(Logistic Regression):模型简单,训练速度快,有较好的模型效果。 LightGBM:速度很快,树结构不复杂的情况下,比LR更快得到结果,并且可以训练出很好的模型,同时超参数对模型效果影响一般,不需要过度寻找最优超参数,节省训练模型时间。类似的模型有Xgboost,但LightGBM比Xgboost要快很多。 纵向神经网络:速度最慢,在纵向联邦中花费时间是LightGBM的十几甚至几十倍。而且更依赖超参数提升模型效果,找不到合适超参数的情况下,树模型(比如lightgbm)效果可能更好。 综上,模型总结: 一般情况,最适宜业务场景的模型选择顺序为:最适宜业务场景的模型排序:LightGBM>纵向神经网络>Logistic Regression;如果计算资源和时间足够,模型选择排序为:纵向神经网络>LightGBM>Logistic Regression。 除了LightGBM、纵向神经网络或Logistic Regression之外,还可以选择其他模型。 步骤S4:通过超参数优化模块采用贝叶斯优化库中的HpyerOpt或Optuna对步骤S3中选择的模型进行超参数优化,从而确定最优超参数组合。 超参数优化是优化模型很重要的一步,模型的效果好坏取决于数据和超参数选择。 超参数优化问题中,在前面提到的网格搜索、随机搜索等方法,都是在比较大的超参数空间中,对组合的可能性进行验证的方法。这一类方法都可以归纳为后验过程,也就是计算出每组超参数的模型实际效果,然后比较出效果最好的超参数。在超参数组合特别多的情况下,这种后验方式的计算资源消耗一定是指数上升的。 贝叶斯优化的调参过程是一种先验过程的调参,也就是借助数学理论提出假设,通过不断调整假设来避免大量超参数组合的计算,来快速找到最优超参数,本申请中的贝叶斯优化采用本领域常规技术。 贝叶斯优化是一整套框架,其中的优化算法非常丰富,它主要用于找到最优化问题的全局最优解。贝叶斯优化在很多科学研究和工业设计行业都有应用,其中包括优化算法模型的超参数。贝叶斯优化采用的是先验过程,其中包含很多的数学理论和公式的推导。本论文的主要核心是利用贝叶斯优化解决模型选择超参数问题,所以不会过多介绍其理论,重点是介绍贝叶斯优化的过程。 贝叶斯优化框架的核心是两个部分:概率代理模型和采集函数。概率代理模型用于代理未知目标函数。从假设先验,再增加验证点,得到验证结果再修正先验,通过不断迭代这个过程增加信息量,最终得到较为准确的代理模型,采集函数是根据后验概率分布构造的函数,用来选择下一个最有潜力的评估点。 超参数优化过程: 以联邦学习超参数优化为例,每一种超参数组合都会学习到一个联邦模型,根据验证数据集会得到一个验证指标的结果。如果穷尽超参数组合空间,就会得到超参数组合和验证指标结果的对应关系,这个对应关系可以用函数拟合出来。但是我们不会用那么大的算力来寻找这个对应关系出来,因此最高效的方式是利用先验加验证再修正的方式,不断逼近这个对应关系,概率代理模型就是最终要拟合一个在超参数空间中算法效果的模型。 概率代理模型是先验过程,对于已知的几个超参数组合验证点可以得到结果,对于验证点之间的未知超参数空间结果需要用数学方法进行概率分布的预估。其中一种是高斯过程,用来计算估计值和置信度,评估估计值和置信度用到的是均值和方差,其背后原理是基于正态分布来进行的。高斯过程本身是多元高斯分布的扩展,是一种随机过程,在高斯过程中,超参数空间中每一点都是与一个正态分布的随机变量相关联。高斯过程的具体原理本文不便赘述,总而言之,通过高斯过程可以拟合出超参数空间每一点的估计值的均值和置信度。另一种进行概率分布建模的方式叫TPE(Tree Parzer Estimator),它的原理是利用贝叶斯公式和选择阈值来计算期望收益,进而选择下一个验证点。 在概率代理模型不断验证和修正的迭代过程中,每一次需要选择一个验证点,选择这个验证点的策略是应用采集函数。采集函数反映的是增加新验证点将会给优化带来的收益。贝叶斯优化过程有多种优化方式的采集函数可选择。 代码实现: 贝叶斯优化库有很多种优化方式,在本领域已有的常规技术AutoML中有非常丰富的库可供选择使用。其中的Bayesian Optimization是比较基础的库,很多示例以应用这个库来调试贝叶斯优化超参数的过程,但本身它的优化效率一般,而且有各种应用的限制,因此不推荐在实际应用时采用这个库。本文推荐的库分别是本领域已有的常规优化库HyperOpt和Optuna。HyperOpt的概率代理模型迭代应用的是TPE,Optuna是把贝叶斯优化和遗传算法相结合的方式,动态构建超参数搜寻空间,该过程属于本领域常规技术手段,此处不再赘述细节。 本节利用代码样例展示如何应用贝叶斯优化库,在代码过程中,基于贝叶斯优化的很多方法有现成的优化库,可以比较方便的调用这些库来实现贝叶斯优化。这些库的调用过程基本类似,以python代码为例,主要分为以下几步: (1)导入贝叶斯优化库的python包 本论文以optuna为例展示联邦学习中的超参数优化过程。本文也推荐使用这个优化库。 如果需要使用其他优化库,可以参考上面的AutoML优化库链接。 (2)对联邦模型过程进行封装 无论哪种贝叶斯优化库,其优化更新的方式需要不断迭代,每次迭代相当于要训练和验证一遍模型,因此调用贝叶斯优化之前需要封装联邦模型训练加验证的过程。同时需要确定好优化的评价指标,比如auc、logloss、accuracy等 /> (3)建立优化超参数的函数方法 该函数方法需要做两件事:第一是确定要优化的超参数空间。第二是加载封装的联邦模型过程,并给出优化指标。 optuna库有指定超参数范围选择的方法,类别型、整数型、浮点型的超参数都可以找到对应的方法,分别是sugguest_categorical、suggest_float、suggest_int,只要指定对应方法即可,如果想固定某一超参数,直接传入固定值。 (4)调用优化库的包,设定其参数 1.#定义优化方向,取最大值还是最小值 2.study=optuna.create_study(direction="maximize") 3.#设定优化迭代次数或者消耗时长(单位是秒) 4.study.optimize(objective,n_trials=100,timeout=20) 5.#最优超参数结果 6.trial=study.best_trial optuna库可以设定优化的迭代次数和消耗时长,消耗时长这个参数尤为重要,一般的优化过程我们并不确定需要多久时间,但是实际项目可能不会等我们花太长时间优化,所以当运行了设定时间后,会自动停止并给出目前最优的超参数组合方案。 步骤S5:通过模型训练模块将步骤S2筛选出的特征数据和步骤S4获得的最优超参数组合代入步骤S3中选择的模型并训练模型,从而得到优化后的联邦学习模型。 模型的效果好坏取决于数据和超参数选择。在对特征数据进行清洗、预处理、选择和降维之后,并确定了最优超参数组合之后,就可以代入并训练最终模型,从而得到优化后的联邦学习模型。 步骤S6:通过输出模块对比上一次优化后的联邦学习模型与步骤S5获得的优化后联邦学习模型,覆盖并保存效果最优的联邦学习模型,输出当前效果最优的联邦学习模型。 实际应用中,由于训练一次模型开销本身比较大,在每次优化迭代一次后,对比前后模型并覆盖保存当前效果最优的模型,当优化结束时,输出保留下来的模型即可。 本申请的另一实施例提供一种电子设备,其包括:存储器、处理器以及存储于所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述联邦学习建模的多环节自定义优化方法中的步骤。 电子设备包括但不限于用户设备、网络设备或用户设备与网络设备通过网络相集成所构成的设备。所述用户设备其包括但不限于任何一种可与用户通过触摸板进行人机交互的移动电子产品,例如智能手机、平板电脑等,所述移动电子产品可以采用任意操作系统,如android操作系统、IOS操作系统等。其中,所述网络设备包括一种能够按照事先设定或存储的指令,自动进行数值计算和信息处理的电子设备,其硬件包括但不限于微处理器、专用集成电路、可编程门阵列、数字处理器、嵌入式设备等。所述网络设备其包括但不限于计算机、网络主机、单个网络服务器、多个网络服务器集或多个服务器构成的云;在此,云由基于云计算的大量计算机或网络服务器构成,其中,云计算是分布式计算的一种,由一群松散耦合的计算机集组成的一个虚拟超级计算机。 本申请的另一实施例提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述联邦学习建模的多环节自定义优化方法中的步骤。 计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器、只读存储器、可擦式可编程只读存储器、静态随机存取存储器、便携式压缩盘只读存储器、数字多功能盘、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。这里所描述的计算机可读程序指令可以从计算机可读存储介质下载到各个计算/处理设备,或者通过网络、例如因特网、局域网、广域网和/或无线网下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光纤传输、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或者网络接口从网络接收计算机可读程序指令,并转发该计算机可读程序指令,以供存储在各个计算/处理设备中的计算机可读存储介质中。 应当注意的是,本发明的实施例有较佳的实施性,且并非对本发明作任何形式的限制,任何熟悉该领域的技术人员可能利用上述揭示的技术内容变更或修饰为等同的有效实施例,但凡未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何修改或等同变化及修饰,均仍属于本发明技术方案的范围内。
- 基于半监督学习的联邦建模方法、设备及可读存储介质
- 基于迁移学习的神经网络联邦建模方法、设备及存储介质
- 基于迁移学习的联邦建模方法、设备及可读存储介质
- 自定义打印方法、装置、计算机设备和存储介质
- 可自定义的AR信息生成方法、装置、存储介质及设备
- 联邦学习建模优化方法、电子设备、存储介质及程序产品
- 联邦学习建模优化方法、设备、可读存储介质及程序产品