基于轻量化LA Transformer网络的图像分类系统及方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及图像识别技术和机器学习技术领域,具体涉及一种基于通道注意力机制设计的轻量化视觉Transformer架构的图像分类方法。
背景技术
图像分类任务是现代计算机视觉领域中的重要问题。深度神经网络模型在图像分类任务中展现的性能和效率往往直接反映了该模型对于图像的特征提取能力。近年来,Transformer在自然语言处理领域的优秀表现引起了计算机视觉领域研究人员的极大关注。相比于传统的卷积神经网络,视觉Transformer架构有更大的感受野,在网络的输入端即可捕获图像数据全局的信息。因此,视觉Transformer架构表现出了更强的特征提取能力,也在图像分类,目标检测等任务中展现出了更高的性能。但是主流的视觉Transformer架构仍存在着训练难度大,模型复杂度更高等一系列缺点。在当前的计算机视觉领域,轻量化的Transformer架构是一个备受关注的研究领域,研究人员希望通过改进视觉Transformer的架构来在降低模型时间和空间复杂度的前提下不降低其特征提取能力,使模型达到效率和效果之间更好的平衡。
主流的视觉Transformer架构通常由多个同构的Transformer块堆叠而成。每个Transformer块包括自注意力模块用于建模特征图的空间相关性和前馈神经网络用于建模通道间的相关性,在自注意力模块和前馈神经网络中,利用了大量的全连接层对于特征进行处理,引入了大量的可学习参数,极大地提高了模型的空间复杂度。同时,自注意力模块在对图像数据进行特征提取的过程中,时间复杂度和图像的尺寸的平方成正比,这也导致了传统的视觉Transformer模型在处理高分辨率图像时的计算量难以控制。由此可见,视觉Transformer架构虽然有着较强的特征提取能力,但是也带来了较大的时间复杂度和空间复杂度。
为了实现对于视觉Transformer架构的轻量化,当前主要的技术路线有以下两种:
第一种是利用小型的卷积神经网络代替视觉Transformer架构中的令牌嵌入部分。基于图像数据固有的局部相关性这一特点,该方案解决了视觉Transformer架构无法更有效捕获空间中局部信息的缺陷,利用该设计思路搭建的轻量化Transformer架构往往可以在堆叠更少的Transformer块实现和原本架构类似的特征提取能力,从而实现对于模型的轻量化效果。但是方案并没有从根本上解决传统Transformer架构中自注意力模块和前馈神经网络时间和空间复杂度过大的问题。
第二种方案是对于Transformer架构中的特征图进行动态剪枝的方案。该方案主要关注自注意力模块建模特征的空间相关性的过程中时间复杂度过大的问题。在该解决方案中的若干工作都提出了各自的动态的补丁剪枝策略,可以融合语义信息相近的特征令牌,降低在计算自注意力过程中的时间复杂度。但是目前的类似工作仍存在着不足之处,例如无法有效解决视觉Transformer架构参数量较大的问题,在实际应用中,利用该方案仍需要面对模型较大的存储空间负担。且目前所提出的令牌融合方案并不够高效,无法保证在融合一定比例的令牌数量的情况下,仍能使模型的特征提取能力不受到明显的影响。
因此,如何改进模型的架构实现对图像特征进行更高效地建模目前仍存在着较大的挑战。
发明内容
为克服现有方法与技术的不足,本发明旨在提出一种基于轻量化LA Transformer架构的图像分类方法,构建基于局部注意力机制的新型的轻量化视觉Transformer架构LATransformer(Local Attention Transformer)用于图像信息中不同特征的识别,实现图像分类。
本发明利用以下技术方案实现:
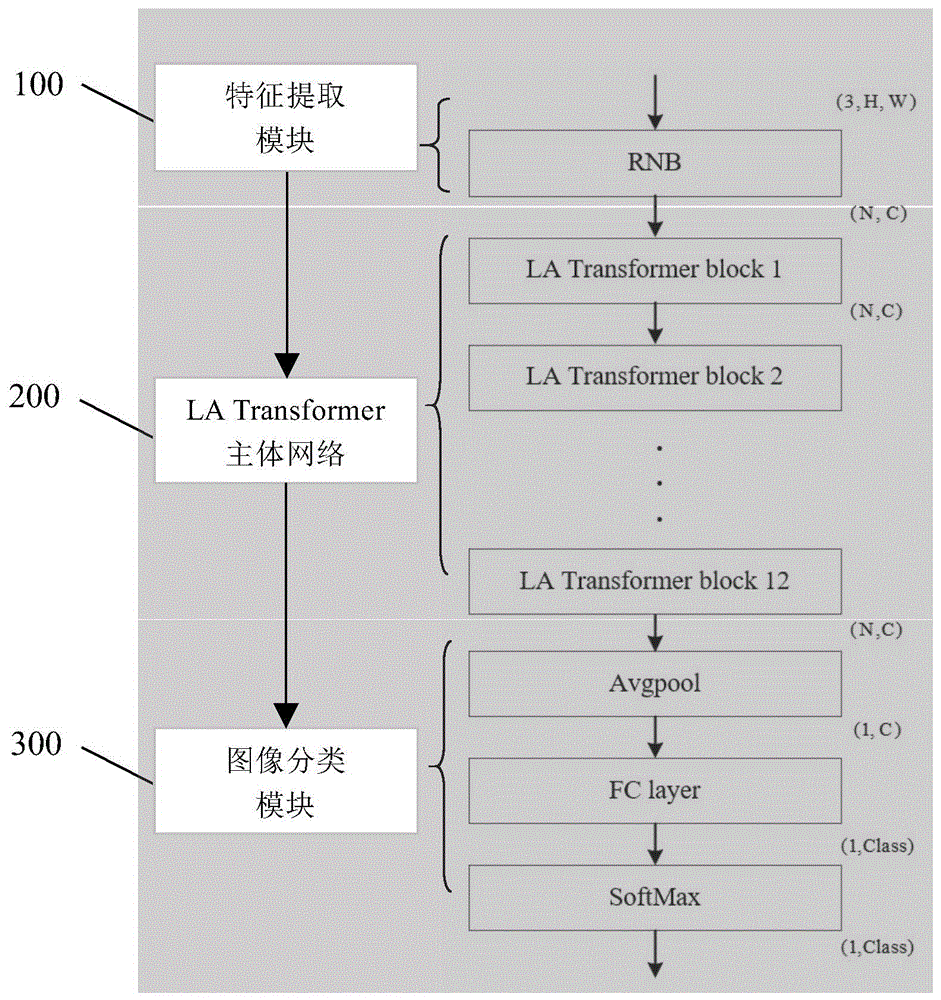
一种基于轻量化LA Transformer网络的图像分类系统,该系统包括特征提取模块、LA Transformer主体网络和图像分类模块,其中:
所述特征提取模块,负责利用带有残差连接的卷积神经子网络对输入RGB图像进行局部特征提取,实现了输入图像的下采样,输出
所述LA Transformer主体网络,负责利用多个级联的LA Transformer块对图像特征进行进一步的特征提取,所述LA Transformer主体网络包括多个级联的LA Transformer块,每个所述LA Transformer块由局部自注意力子网络和归一化操作层、归一化操作层和注意力前馈神经子网络两部分构成;通过局部自注意力子网络利用局部自注意力机制建模补丁和补丁之间的空间相关性信息,以及通过注意力前馈神经子网络建模通道和通道之间的相关性信息;
所述图像分类处理模块,负责生成针对每个图像分类的概率,完成输入RGB图像的分类。
一种基于轻量化LA Transformer网络的图像分类方法,该方法包括以下步骤:
步骤S1、利用带有残差连接的卷积神经子网络对输入RGB图像进行局部特征提取,实现了输入图像的下采样,输出
步骤S2、利用多个级联的LA Transformer块对图像特征进行进一步的特征提取,所述LA Transformer主体网络包括多个级联的LA Transformer块,每个所述LATransformer块由局部自注意力子网络和归一化操作层、归一化操作层和注意力前馈神经子网络两部分构成;通过局部自注意力子网络利用局部自注意力机制建模补丁和补丁之间的空间相关性信息,以及通过注意力前馈神经子网络建模通道和通道之间的相关性信息;
步骤S3、生成针对每个图像分类的概率,完成输入RGB图像的分类。
相比于经典的ViT模型,本发明的基于轻量化LA Transformer网络的图像分类系统及方法,在参数量和计算量更低的同时还能够达到更高的图像分类精度,该结果可以在ImageNet-1k等公开数据集上进行验证。
附图说明
图1为本发明的基于轻量化LA Transformer网络的图像分类系统结构图;
图2为带有残差连接的卷积神经子网络(RNB)架构示意图;(2a)为RNB的整体结构,(2b)为RNB的Bottleneck子结构;
图3为每个LA Transformer主体网络结构图;
图4为局部自注意力模块(LSA)结构图;
图5为注意力前馈神经网络(AFFN)结构图;
图6为本发明的基于轻量化LA Transformer网络的图像分类方法流程图。
具体实施方式
下面将结合附图和实施例,对技术方案进行详细描述。基于本发明中的实施例,本领域普通技术人员在不脱离本发明精神和没有做出创造性劳动情况下所获得的所有其他实施例和实施例的技术替换,都将落入本发明保护的范围。
如图1所示,本发明的基于轻量化LA Transformer网络的图像分类系统结构图。该系统包括特征提取模块100、LA Transformer主体网络200和图像分类处理模块300。
所述特征提取模块100,采用带有残差连接的卷积神经子网络(ResNet block,RNB)对输入图像数据的RGB图像
如图2所示,为带有残差连接的卷积神经子网络(RNB)架构示意图;(2a)为RNB整体结构,RNB整体结构包括子网络输入端的二维卷积层Conv2d、全局最大池化层、Bottleneck结构和子网络输入端的二维卷积层Conv2d。Bottleneck结构包括三个级联的Bottleneck子结构。每个Bottleneck子结构包括两个异构的分支结构,其中,左侧分支结构由三个二维卷积层和批归一化层(Batchnorm)交替堆叠组成,其中第一个和第三个二维卷积层的卷积核大小为1×1,而第二个二维卷积层的卷积核大小为3×3,且卷积的步长为2×2,对输入特征进行下采样;对于任意尺寸的输入特征图,第一个和第二个二维卷积层的输出特征的通道数都为64,而在最后一个二维卷积层进行升维操作,将通道数升至256。最后利用修正线性单元激活函数(ReLU)对特征进行非线性激活处理,作为左分支结构的输出。右侧分支结构只包括一个卷积核大小为1×1,卷积步长为2×2的二维卷积层和一个批归一化层,输出特征通道数为256,和左侧分支的输出特征的通道数相等,且两个分支结构都进行了一次下采样操作。将图像特征尺寸处理为(64,112,112)像素。将两个分支结构的输出特征进行叠加处理,作为Bottleneck子结构的输出特征。在经过三个级联Bottleneck子结构处理后,利用一个卷积核大小为1×1的二维卷积层(ConV2d)将特征的通道数降低至192,且特征的尺寸降采样至14×14,作为RNB的输出特征图
所述LA Transformer主体网络200,由重复的多个LA Transformer块堆叠组成,每个LA Transformer块进一步包括局部自注意力子网络(LSA,Local Self-Attention)和注意力前馈神经子网络(AFFN,Attention Feed-Forward Network)。通过局部自注意力子网络利用局部自注意力机制建模图像特征补丁和补丁之间的空间相关性信息,以及通过注意力前馈神经子网络建模图像特征通道和通道之间的相关性信息。具体来讲,就是根据图像特征,在网络中使用卷积操作、全连接操作或是自注意力操作,通过其中的可学习参数来捕获通道间的相关性信息,或是空间上像素和像素间的相关性信息,或是空间上补丁和补丁之间的相关性信息。所以此处图像特征前向传播的过程就是建模相关性信息的过程。
如图3所示,为每个LA Transformer块的结构图。LA Transformer块的整体架构由上下两部分组成,分别是局部自注意力子网络LSA和归一化操作层LA Transformer、归一化操作层LA Transformer和注意力前馈神经子网络AFFN。与经典的Transformer块架构相比,创新点在于以局部自注意力子网络LSA代替了传统Transformer块中的全局自注意力网络,以及,以注意力前馈神经子网络代替了传统Transformer块中的前馈神经网络。
如图4所示,为局部自注意力子网络(LSA)结构图。
所述局部自注意力子网络中,首先将特征图
利用Sigmoid激活函数进行非线性激活处理,得到三种特征图Y_c、Y_h、Y_w,表示如下:
Y
Y
Y
利用三个注意力权重向量和特征图Y
如图5所示,为注意力前馈神经子网络(AFFN)结构图。对于输入AFFN的特征图
分别进入两个分支结构:
左侧的注意力(att)分支包括一个平均池化层(Avgpool)、两个全连接层(FClayer)和一个Sigmoid激活函数。对于该分支的输入特征图
再利用两个全连接层和Sigmoid激活函数的处理,得到通道注意力权重W
之后对于y
z=W
这里使用两个FC层根据每个通道的全局空间信息,建模了通道之间的相关性,以及生成通道注意力权重z。
右侧的前馈神经网络分支结构(FFN)包括两个全连接层(FC layer),对于该分支的输入特征图
输出特征图表达式如下:
从而实现了在通道维度上对特征图进行建模;
最后使用左侧注意力(att)分支输出的通道注意力权重z对右侧分支结构输出的特征图
。
上述过程中数学表达式归纳如下:
经RNB初步提取的特征图表示如下:
X
各个LA Transformer块对应的特征图表示如下:
其中,t为LA Transformer块的编号。
LA Transformer块从第一个到第t个结构相同,但是随着网络对特征逐层地提取,靠近输出端的LA Transformer块自发地学习到更高层的语义特征。利用第t个LATransformer块的输出
所述图像分类模块300,以注意力前馈神经子网络的输出特征图
本发明所提出的LA Transformer架构主要在三个角度上进行了创新,这里首先对三个主要创新点进行定性的分析:
首先,利用带有残差连接的卷积神经子网络(RNB)对图像数据进行局部特征提取,在引入较少的额外参数量的同时有效提升了模型在图像分类任务上的性能。该部分结构的设计方案主要参考了经典的卷积神经网络架构ResNet,更有利于模型的训练。解决了视觉Transformer架构无法更有效捕获空间中局部信息的缺陷,利用该设计思路搭建的轻量化Transformer架构往往可以在堆叠更少的Transformer块实现和原本架构类似的特征提取能力,从而实现对于模型的轻量化效果。进一步从根本上解决传统Transformer架构中自注意力模块和前馈神经网络时间和空间复杂度过大的问题。
其次,用局部自注意力子模块代替传统视觉Transformer架构中的自注意力模块,引入了可以忽略的额外参数量的同时,仍保有基本的局部空间特征建模能力,同时在面对尺寸较大的输入图像特征,该局部注意力模块的计算量有着更为明显的优势。在有效建模特征图的空间信息的同时,大幅降低了参数量和计算量注意力前馈神经网络在传统的前馈神经网络中引入了通道注意力机制,进一步提高了网络对特征通道间相关性的建模能力。
最后,第三个创新注意力前馈神经网络,则是利用了通道注意力模块在融合通道间信息的重要作用,在降低前馈神经网络处理特征的通道数的同时,能保持通道间信息融合的能力,有效提高了模型的特征提取能力。
具体实施例:采用数据集ImageNet,用于图像分类任务。在ImageNet数据集上训练网络模型时,本发明采用了与ViT相同的数据增广方式,除了尺寸、颜色和翻转增强,也采用mixup,randAugment,cutmix,和label smooth方案。
在图像分类任务的训练阶段中,本实例利用ImageNet-1K数据集中的训练集,对LATransformer架构进行训练。在训练中利用AdamW优化算法和余弦退火的训练策略。设定的权重衰减参数为1e-4,动量参数为0.9,训练数据批次大小为256,初始学习率为0.1,模型训练迭代轮次为300次。
- 一种基于边Transformer图神经网络的小样本图像分类方法及系统
- 一种基于边Transformer图神经网络的小样本图像分类方法及系统