一种基于特征精炼与多视图的人物物交互动作检测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及计算机视觉技术领域,特别涉及一种基于特征精炼与多视图的人物物交互动作检测方法。
背景技术
交互动作检测任务旨在检测人和物体之间的交互行为并对其进行定位。目前针对交互动作识别的方法大体可以分为两大类,分别是基于单帧的交互动作检测方法和基于时序的交互动作检测方法。
对于基于单帧的交互动作检测方法而言,为了更好的检测人物交互动作,现有的一些方法通过捕获人和物体的视觉信息或者空间信息来表示交互动作。在图传递神经网络方法中,提出将图形模型和神经网络结合起来的方法,整合了来自人和物体的视觉特征信息。该方法迭代地学习图结构并推理消息传递权重以输出最终解析图,该解析图包括人与的物的图结构以及交互动作的标签。在视觉空间图网络方法中,提出将空间结构与图网络相结合的方法,整合了人和物体之间的相对空间位置信息,该架构基于人物对的空间位置从人物对中提取和细化视觉特征,并通过图卷积网络检测人的交互动作。
然而,所有这些方法都没有对人和物体之间的时间依赖关系进行建模,无法更好地基于时序信息理解人与对象的交互。并且这些方法都需要通过枚举所有的成对人和物体的组合进行动作分析,因此存在计算和推理时间成本高的问题。
对于基于时序的交互动作检测方法而言,为了更好的利用时间线索,现有的一些方法通过采用视频时序特征建模人物时序交互表征,从而准确的表示交互动作。在异步交互聚合方法中,提出通过整合不同的交互行为以促进动作检测的方法。该方法首先通过异步内存更新算法提取长期时序特征,然后分别建模人人交互特征,人物交互特征和时序特征,最后通过交互聚合结构建模交互特征。在高级关系建模方法中,提出通过推断多个参与者与上下文之间的交互关系,间接的建模高阶交互关系的方法。该方法首先建模一阶的人与上下文之间的关系,然后构建高阶关系推理模型,最后通过推理模型利用一阶关系对二阶关系进行建模。
尽管这些方法相较于基于单帧的交互动作检测方法取得了更好的结果,但是他们获取视频特征的方法均是基于视频片段特征和ROI对齐相结合的方法,这将会导致对于具有快速移动性质的动作,无法准确的获取其时序特征。并且现有的动作检测方法无法准确有效地建模与表征人物物交互动作,导致模型存在不可解释性并且检测准确率较差的问题。
发明内容
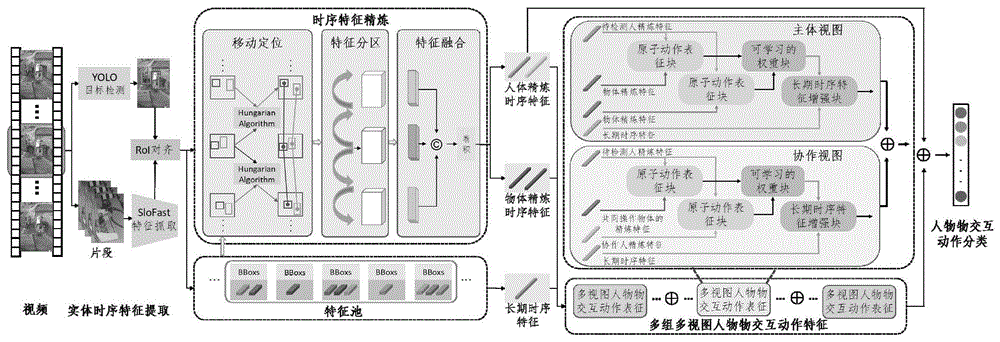
为解决上述问题,本发明提供了一种基于特征精炼与多视图的人物物交互动作检测方法,利用YOLO目标检测算法、ROI对齐算法以及SlowFast时序特征生成算法抓取实体的时序特征,之后采用移动定位方法实现实体运动轨迹的跟踪定位,执行特征精炼操作,基于定位结果级联不同时间步下的时序特征,提高实体时序特征的准确性,解决了空间偏移造成的时序特征不准确的问题,最后从多视图探索待检测的人与多个实体之间的动作关系,分别表征主体视图下的和协作视图下的人物物交互动作,通过融合不同视图下的特征构建了多视图特征,并基于多组多视图特征表征人物物交互动作,解决人物物交互动作建模问题,增强了人物物交互动作表征的鲁棒性。
本发明提供了一种基于特征精炼与多视图的人物物交互动作检测方法,具体技术方案如下:
S1:对待检测的视频帧进行实体时序特征提取,获取实体时序特征;
S2:对实体时序特征进行精练,获得精练后的实体时序特征;包括如下步骤:
S201:通过移动定位操作,对实体运动轨迹进行跟踪定位;
S202:基于定位的实体位置,逐段提取时序特征并进行时序特征精炼;
S3:基于精炼的实体时序特征,获取以人为中心的交互动作建模模型;
S4:采用以人为中心的交互动作建模模型,构建和融合多组多视图人物物交互动作特征,获得人物物交互动作分类特征;包括如下步骤:
S401:采用以人为中心的交互动作建模模型,构建主体视图下的人物物交互动作特征;
S402:采用以人为中心的交互动作建模模型,构建协作视图下的人物物交互动作特征;
S403:基于主体视图和协作视图下的人物物交互动作特征构建人物物交互动作分类特征;
S5:通过动作分类器对人物物交互动作进行分类。
进一步的,步骤S1中,包括如下步骤:
S101:采用YOLO目标检测算法实时检测出当前帧中人和物的类别以及坐标框;
S102:通过SlowFast时序特征提取算法生成当前帧的时序特征;
S103:采用ROI对齐算法和最大池化算法根据检测出的实体坐标和当前帧的时序特征提取人和物的时序特征;
S104:将当前帧的实体的坐标框和时序特征存储到特征池中。
进一步的,步骤S201中,所述移动定位操作,包括渐进式扩展和自适应定位,通过迭代执行渐进式扩展和自适应定位两个步骤,定位当前帧中每一个实体在之前和之后的帧中发生偏移后的实体位置。
进一步的,所述渐进式扩展,为将上一次迭代中定位好的实体坐标框,复制到相邻的未定位的帧中。
进一步的,如果是第一次迭代则将当前帧中所有实体的坐标框,复制到相邻的未定位的帧中。
进一步的,所述自适应定位,具体过程如下:
从特征池中获取相邻的未定位帧中存储的实体坐标框,然后计算相邻帧中的实体坐标框和在渐进式扩展步骤中复制的实体坐标框的中心点,并计算两组坐标框中心点之间的距离;
利用匈牙利算法求解中心点之间的对应关系;
基于对应关系获取每一个复制的实体坐标框其对应的存储的实体坐标框的位置,并将该位置作为定位后的实体位置。
进一步的,步骤S202中,时序特征精练的具体过程如下:
将当前帧的时序特征拆成2D+1个特征块,其中,D表示总的迭代次数;
利用定位的实体位置和ROI对齐方法抓取每个实体在每个特征块中的分区时序特征;
将每个实体的所有分区时序特征进行级联,并通过卷积操作构建精炼后的实体时序特征。
进一步的,所述卷积操作由两组堆叠的卷积层、Dropout层和ReLU层组成。
进一步的,步骤S3中,所述以人为中心的交互动作建模模型,模型包括可学习的权重块、长期时序特征增强块以及两个原子动作表征块;
所述原子动作表征块以待检测人体的精炼时序特征和参与交互的其他人/物体的精炼时序特征为输入,所述原子动作表征块的输出与所述可学习的权重块的输入连接,所述可学习的权重块的输出与长期时序特征作为所述长期时序特征增强块的输入。
进一步的,步骤S401中,构建主体视图下的人物物交互动作特征具体过程如下:
通过步骤S3中,以人为中心的交互动作建模方法,将待检测的人体的精炼时序特征以及参与交互的两个物体的精炼时序特征作为输入,获取主体视图下的人物物交互动作特征。
进一步的,步骤S402中,构建协作视图下的人物物交互动作特征具体过程如下:
通过步骤S3中,以人为中心的交互动作建模方法,将待检测的人体的精炼时序特征以及协助交互的人体的精炼时序特征和共同操作的物体的精炼时序特征作为输入,获取协作视图下的人物物交互动作特征;
进一步的,步骤S403中,构建人物物交互动作分类特征具体过程如下:
将主体视图下的人物物交互动作特征和协作视图下的人物物交互动作特征的相加,得到多视图人物物交互动作特征;
构建多组多视图人物物交互动作特征;
相加融合多组多视图人物物交互动作特征,获得人物物交互动作分类特征。
本发明的有益效果如下:
1、提取实体的时序特征后,基于移动定位进行时序特征精练,有效的解决时序特征提取中由于空间位移带来的特征描述不准确性的问题,提高了时序特征的准确性。
2、给出了以人为中心的交互动作建模模型,模型通过两个原子动作表征块、一组可学习的权重以及长期时序特征增强块构成,并基于该模型从两个不同的视图分别地表征人物物交互动作,最后通过融合不同视图下的特征构建了多视图特征,并基于多组多视图特征表征人物物交互动作,有效的解决了现有方法无法建模人物物交互特征的问题,并基于多视图的方法增强了人物物交互特征的鲁棒性。
附图说明
图1是方法整体过程模块示意图;
图2是以人为中心的交互动作建模模型结构示意图。
具体实施方式
在下面的描述中对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在发明实施例的描述中,需要说明的是,指示方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,或者是本领域技术人员惯常理解的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于区分描述,而不能理解为指示或暗示相对重要性。
在本发明实施例的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是直接连接,也可以通过中间媒介间接连接。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
实施例1
本发明的实施例1公开了一种基于特征精炼与多视图的人物物交互动作检测方法,如图1所示,包括如下步骤:
S1:对待检测的视频帧进行实体时序特征提取,获取实体时序特征;
本实施例中,定义一个待检测的视频为
具体的,步骤如下:
S101:采用YOLO目标检测算法实时检测出当前帧中人和物的类别以及坐标框,人和物的坐标框分别记为Bh
S102:通过SlowFast时序特征提取算法生成当前帧的时序特征;
S103:采用ROI对齐算法和最大池化算法根据检测出的实体坐标和当前帧的时序特征提取人和物的时序特征,分别记为Fh
S104:将当前帧的实体的坐标框和时序特征存储到特征池中,特征池表示为
S2:对实体时序特征进行精练,获得精练后的实体时序特征;
由于在交互过程中实体往往具有快速移动的特性,因此传统的基于ROI对齐的方法提取实体时序特征容易因为实体移动偏移较大,而造成特征提取不准确问题;
本实施例中,通过对实体时序特征进行精练,以提高实体时序特征的准确性。
具体步骤如下:
S201:通过移动定位操作,对实体运动轨迹进行跟踪定位;
移动定位的目的是对关键帧中的每一个实体在之前和之后的帧中,定位发生偏移后的实体位置。
所述移动定位操作包括渐进式扩展和自适应定位,本实施例中,通过迭代执行渐进式扩展和自适应定位两个步骤,定位当前帧中每一个实体在之前和之后的帧中发生偏移后的实体位置。在每一次迭代中,首先执行渐进式扩展操作为位移定位提供实体位置参考,然后执行自适应定位操作匹配移动后的实体坐标框。
具体的,所述渐进式扩展,是将上一次迭代中定位好的实体坐标框,复制到相邻的未定位的帧v
如果是第一次迭代则将当前帧中所有实体的坐标框,复制到相邻的未定位的帧中。
所述自适应定位,具体过程如下:
从特征池P中获取相邻的未定位的帧中,例如v
j∈[1,Se],Dis(i,j)=|center(i)-center(j)|;
其中,Sc和Se分别是Bc
之后利用匈牙利算法求解中心点之间的对应关系,如下:
Π
其中,Π表示中心点之间的对应关系,Dis是一个矩阵用于存储中心点之间的距离,Π
本实施例中总迭代次数D的计算如下:
D=[Nc/Ns]/2
其中,Nc为SlowFast模型提取当前帧时序特征时需要输入的视频帧数,为了避免逐帧偏移定位造成迭代次数过多增大计算量的问题,本实施例中,以一秒为间隔进行位移定位,即Ns表示一秒钟内视频的帧数。
最后基于对应关系求解每一个复制的坐标框Bc
其中,proj用于投影该中心点到对应的边界框,
S202:基于定位的实体位置,逐段提取时序特征并进行时序特征精炼;
具体过程如下:
将当前帧的时序特征拆成2D+1个特征块,其中,D表示总的迭代次数;
利用定位的实体位置和ROI对齐方法抓取实体在每个特征块中的分区时序特征,记为Fe;
将每个实体的所有分区时序特征进行级联,并通过卷积操作构建精炼后的实体时序特征。
本实施例中,所述卷积操作由两组堆叠的卷积层、Dropout层和ReLU层组成,能够从级联的特征中选择和放大有助于动作识别的特征;
具体处理过程表示如下:
其中,Wr表示卷积堆操作,Fe为分区时序特征,Re表示精炼的实体时序特征,包含了精炼的人和物体的时序特征Rh,Ro。
S3:基于精炼的实体时序特征,获取以人为中心的交互动作建模模型。
如图2所示,以人为中心的交互动作建模模型结构如下:
包括可学习的权重块、长期时序特征增强块以及两个原子动作表征块;
所述原子动作表征块以待检测人体的精炼时序特征和参与交互的其他人/物体的精炼时序特征为输入,所述原子动作表征块的输出与所述可学习的权重块的输入连接,所述可学习的权重块的输出与长期时序特征作为所述长期时序特征增强块的输入。
具体的,模型包括两个原子动作表征块,分别记为原子动作表征块1、原子动作表征块2、可学习的权重块以及长期时序特征增强块;
所述原子动作表征块以及长期时序特征增强块可通过多种方式实现,例如AvgPooling、Transformer和Non-Local Block;由于Non-Local Block可以更有效地捕获特征之间的依赖选择对目标人特征高度激活的其他特征,并且可以将他们合并以增强目标人特征,此外还不会消耗大量的计算资源,因此,本实施例中,采用Non-Local Block来提取原子动作特征。
原子动作表征块1和原子动作表征块2输入待检测人体的精炼时序特征和参与交互的其他人/物体的精炼时序特征,并输出原子交互动作特征;
可学习的权重块由多个卷积堆叠组成用于融合两个原子交互特征实现对原子交互动作的组合,输出组合后的交互特征。
长期时序特征块首先从特征池P中提取以当前帧为中心时间跨度为5秒的所有实体的时序特征并级联5秒内的所有实体特征构建长期时序特征L,然后实现对组合后的交互特征的增强。
S4:采用以人为中心的交互动作建模模型,构建和融合多组多视图人物物交互动作特征,获得人物物交互动作分类特征;
结合图1所示,为了实现更鲁棒地提取人物物交互动作特征,采用以人为中心的交互动作建模模型,分别提取主体视图以及协作视图下的人物物交互动作特征;
具体步骤如下:
S401:采用以人为中心的交互动作建模模型,构建主体视图下的人物物交互动作特征。
对于主体视图,主要建模直接发生交互的主体。考虑交互过程中分别与两个物体产生交互,因此可以基于两个物体的特征直接地建模人物物交互动作。
在主体视图下,人物物交互动作由待检测人分别地与两个物体进行交互这两个原子动作组成。通过步骤S3中,以人为中心的交互建模方法,主体视图下的人物物交互动作表征如下:
Isub=Hc_sub(Rh1,Ro1,Ro2,L)
其中,Hc_sub表示以人为中心的交互动作建模函数,Rh1表示待检测的人体精炼特征,Ro1和Ro2分别表示发生交互的两个物体的精炼特征,L表示长期时序特征,Isub表示输出的主体视图下的人物物交互动作特征。
S402:采用以人为中心的交互动作建模模型,构建协作视图下的人物物交互动作特征。
对于协作视图,主要建模协助交互的人体和共同操作的物体。考虑交互过程中存在其他人协作完成的情况,因此可以基于协作人的特征以及共同操作的物体特征建模人物物交互动作。
在协作视图下,人物物交互动作由待检测人分别地与协作人和共同操作的物体进行交互这两个原子动作组成。通过步骤S3中,以人为中心的交互建模方法,协作视图下的人物物交互动作表征如下:
Icol=Hc_col(Rh1,Ro1,Rh2,L)
其中,Hc_col表示以人为中心的交互动作建模函数,Rh1和Rh2表示参与交互的以及协助交互的两个人体的精炼特征,Ro1代表共同操作的一个物体的精炼特征,L表示长期时序特征,Isub表示输出的协作视图下的人物物交互动作特征。
S403:基于主体视图和协作视图构建人物物交互动作分类特征;
通过采用主体视图下的人物物交互动作特征和协作视图下的人物物交互动作特征的相加,得到多视图人物物交互动作特征。并构建多组多视图人物物交互动作特征,通过相加融合多组多视图人物物交互动作特征,获得人物物交互动作分类特征。
具体处理过程表示如下:
其中,g为多组多视图人物物交互动作特征的组数,F
S5:通过动作分类器对人物物交互动作进行分类,
由于精炼的人体时序特征包含了丰富的交互语义信息适用于交互动作的识别,本实施例中,通过相加精炼的人体时序特征和人物物交互动作分类特征来进行人物物交互动作分类。
具体表示如下:
P=Wc(F
其中,Wc表示由两个完全连接层和一个softmax分类器组成的动作分类器,F
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。
- 基于DETR的人物成对解码交互的人与物交互检测方法
- 一种基于动作和面部表情的人物交互关系识别方法