一种纵向联邦逻辑回归训练方法及装置
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及联邦学习技术领域,尤其涉及一种纵向联邦逻辑回归训练方法及装置。
背景技术
随着上个世纪反向传播算法的出现,深度学习以更快的速度向前发展。当今世界,从医学图像分析,汽车的自动驾驶,谷歌的AlphaGo围棋机器人,到购物网站、视频网站的推荐系统等等,人工智能在各个领域都有广泛应用。但是一个性能优良的人工智能预测模型需要海量的训练数据,在人工智能高速发展的今天,如何获取海量的训练数据成为本领域内重点研究的问题。
以医学领域为例,一个医学领域的癌症预测模型需要的训练样本数量往往很难仅由一家医学机构支撑,需要两家甚至多家医学机构将数据传输至一数据中心,在数据中心对数据做统一的训练,最终得到预测模型,但是由于政策上的原因并非所有的参与机构都可以贡献自己的数据,这样会形成“数据孤岛”导致各个医疗机构的预测模型都不能正常的预测。
数据无法共享主要考虑到两个方面:数据价值方面和隐私保护方面。数据价值方面只要是因为数据是可以复制的,而参与方的数据出库后对于其他方来说是可获取的,这对提供数据的参与方是不利的。隐私保护方面,由于一些数据涉及到某些群体的个人隐私,用户方面也不愿意将涉及隐私的数据公开研究。所以数据参与方有责任和义务保护用户数据的隐私安全。纵向来看,行业顶尖的巨头公司垄断了大量的数据信息,小公司往往很难得到这些数据,导致企业间的层级和差距不断拉大;横向来看,同一层级不同行业的公司,由于系统和业务的闭塞性与阻隔性,很难实现数据信息的交流与整合,联合建模需要跨越重重壁垒。
在这些方面的限制下,为了统筹利用多方数据,亟需一种新的模型训练方法。
发明内容
鉴于此,本发明实施例提供了一种纵向联邦逻辑回归训练方法及装置,以消除或改善现有技术中存在的一个或更多个缺陷,解决由于数据分布在多方主体产生信息孤岛,从而导致模型训练无法快速高效地利用多方数据进行模型训练的问题。
本发明的一个方面提供了一种纵向联邦逻辑回归训练方法,所述方法由纵向联邦学习的两个参与方执行,该方法包括以下步骤:
由各参与方分别生成各自的CKKS公私钥对,并交换各自的CKKS公钥;
由各参与方初始化模型的权重参数;
在一轮迭代中,由有标签的第一参与方确定当前轮次参与训练的数据ID并同步至没有标签的第二参与方;
由所述第一参与方利用己方参数计算对应的第一半梯度列表,所述第一半梯度列表按照所述数据ID的顺序排列;
由所述第二参与方利用己方参数计算对应的第二半梯度列表,所述第二半梯度列表按照所述数据ID的顺序排列;
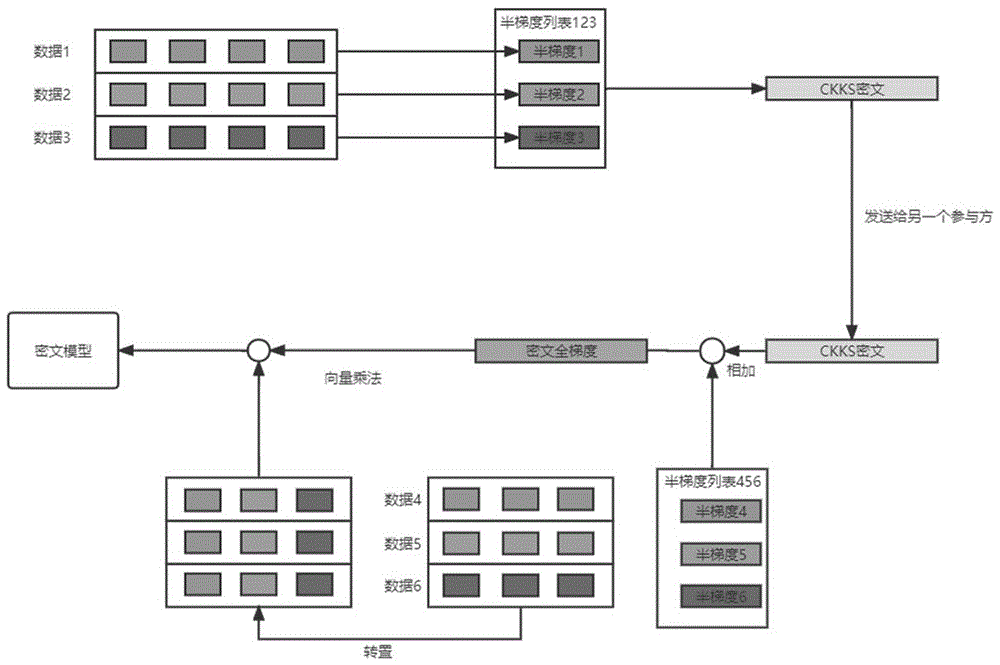
由所述第一参与方利用己方CKKS公钥对所述第一半梯度列表进行加密,并发送至对应的第二参与方;由所述第二参与方利用己方CKKS公钥对所述第二半梯度列表进行加密,并发送至所述第一参与方;
结合第二参与方的CKKS公钥,由第一参与方利用CKKS算法将接收到的加密状态下的所述第二半梯度列表与本地明文状态下的第一半梯度列表相加,得到对应的第一加法结果密文;将所述数据ID对应的本地明文数据矩阵作转置后与所述第一加法结果密文做向量乘法,得到第一中间结果密文,并添加混淆后发送至所述第二参与方;
由所述第二参与方利用己方的CKKS私钥,解密添加混淆后的所述第一中间结果密文,得到第一全梯度列表并发送至所述第一参与方,以供所述第一参与方减去混淆后更新模型;
结合第一参与方的CKKS公钥,由第二参与方利用CKKS算法将接收到的加密状态下的所述第一半梯度列表与本地明文状态下的第二半梯度列表相加,得到第二加法结果密文;所述第二参与方将所述数据ID对应的本地明文数据矩阵作转置后与所述第二加法结果密文做向量乘法,得到第二中间结果密文,并添加混淆后发送至所述第一参与方;
由所述第一参与方利用己方的CKKS私钥,解密添加混淆后的所述第二中间结果密文,得到第二全梯度列表并发送至所述第二参与方,以供所述第二参与方减去混淆后更新模型。
在一些实施例中,由所述第一参与方利用己方参数计算对应的第一半梯度列表,计算式为:
;
;
其中,
在一些实施例中,由所述第二参与方利用己方参数计算对应的第二半梯度列表,计算式为:
;
;
其中,
在一些实施例中,所述第一中间结果密文的计算式为:
;
其中,
所述第二中间结果密文的计算式为:
;
其中,
在一些实施例中,将所述数据ID对应的本地明文数据矩阵作转置后与所述第一加法结果密文做向量乘法,得到第一中间结果密文,并添加混淆后发送至所述第二参与方中,添加混淆的步骤包括:在所述第一中间结果密文中的每一项上添加一个随机数,并将各随机数记录为混淆向量。
在一些实施例中,所述随机数采用不经意伪随机函数生成。
在一些实施例中,所述方法采用tenseal库实现CKKS全同态加密。
在一些实施例中,所述方法中当迭代次数达到设定数值时停止训练。
另一方面,本发明还提供一种纵向联邦逻辑回归训练装置,包括处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该装置实现上述方法的步骤。
另一方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。
本发明的有益效果至少是:
本发明所述纵向联邦逻辑回归训练方法及装置,各参与方使用CKKS全同态加密将本地计算的半梯度列表加密发送给对方,将接收到的对方加密后的半梯列表,与本地计算的明文半梯度列表相加并与明文数据矩阵的转置相乘,计算得到加密状态下完整的梯度。对加密状态下完整的梯度添加混淆后发送至对方参与方进行解密后返回,消除混淆后得到最终的明文梯度用于更新模型。基于纵向逻辑回归的训练模式,引入CKKS进行全同态加密,极大简化了同态加密过程,提升了计算效率。
本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,并不构成对本发明的限定。在附图中:
图1为本发明一实施例所述纵向联邦逻辑回归训练方法的流程示意图。
图2为本发明另一实施例所述纵向联邦逻辑回归训练方法的流程示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施方式和附图,对本发明做进一步详细说明。在此,本发明的示意性实施方式及其说明用于解释本发明,但并不作为对本发明的限定。
在此,还需要说明的是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与根据本发明的方案密切相关的结构和/或处理步骤,而省略了与本发明关系不大的其他细节。
应该强调,术语“包括/包含”在本文使用时指特征、要素、步骤或组件的存在,但并不排除一个或更多个其它特征、要素、步骤或组件的存在或附加。
在此,还需要说明的是,如果没有特殊说明,术语“连接”在本文不仅可以指直接连接,也可以表示存在中间物的间接连接。
在下文中,将参考附图描述本发明的实施例。在附图中,相同的附图标记代表相同或类似的部件,或者相同或类似的步骤。
基于模型训练过程中,对数据价值和隐私保护的需求,联邦学习应运而生,旨在解决数据孤岛的问题,可以让各个数据参与方在数据不出库的前提下完成联合建模,建好的模型在各自的区域只为本地的目标服务,即保护了各方的数据安全和隐私,又避免了大量数据的传输。联邦学习分为横向联邦学习,纵向联邦学习和联邦迁移学习,横向联邦学习是多个参与方数据维度一致,但是数据id不一致,纵向联邦学习指的是多个参与方之间数据id一致,但是维度不一致,联邦迁移学习指的是多个参与方之间数据维度和id都不一致的情况,本发明主要用于纵向联邦学习场景下的逻辑回归训练过程,纵向联邦逻辑回归的实现依赖于同态加密技术:同态加密技术允许数值在密文状态下进行计算,解密后能得到密文计算之后的结果。
联邦学习方案中,各个移动设备为一个数据方,拥有的数据仅仅是一个设备上所有的数据。每个设备用本地数据在本地计算出一个模型,并将本地计算的模型或者模型更新利用同态加密算法加密后发送至中央服务器端,中央服务器收到各个参与方发送来的模型,由于同态加密的特殊性,服务器可以利用联邦平均算法FedAvg将各个参与方发来的密文模型或模型更新根据数据占比权重聚合为一个新的模型,然后将新模型发回给各个参与方。参与方在新模型的基础上进行迭代训练。重复这个过程,直到模型收敛。这个场景中数据分布在许多设备上,每个设备都是一个数据参与方,每个参与方拥有的数据是同维度的,只是样本不同,这种联邦学习称为横向联邦学习,与之相对的是纵向联邦学习,纵向联邦学习中各个数据参与方的数据样本有较大重叠,但是数据的特征维度不同,同时还有第三种联邦学习方案,在数据样本和特征维度都不同时,可以采用联邦迁移学习的方案。
其中,纵向联邦学习之前需要进行一步数据对齐,找到多个参与方中的重叠数据集,并在重叠数据集上进行训练。纵向联邦学习不能像横向联邦学习一样对所有的模型普适,它需要针对不同模型的不同目标函数进行分解,在各个参与方中计算本地可以计算的部分并加密,然后互相交换密文信息进行合并计算,最后进行解密,各个参与方即可拿到更新的模型参数。
具体的,本发明的提供了一种纵向联邦逻辑回归训练方法,所述方法由纵向联邦学习的两个参与方执行,参照图1和图2,该方法包括以下步骤S101~S110:
步骤S101:由各参与方分别生成各自的CKKS公私钥对,并交换各自的CKKS公钥。
步骤S102:由各参与方初始化模型的权重参数。
步骤S103:在一轮迭代中,由有标签的第一参与方确定当前轮次参与训练的数据ID并同步至没有标签的第二参与方。
步骤S104:由第一参与方利用己方参数计算对应的第一半梯度列表,第一半梯度列表按照数据ID的顺序排列。
步骤S105:由第二参与方利用己方参数计算对应的第二半梯度列表,第二半梯度列表按照数据ID的顺序排列。
步骤S106:由第一参与方利用己方CKKS公钥对第一半梯度列表进行加密,并发送至对应的第二参与方;由第二参与方利用己方CKKS公钥对第二半梯度列表进行加密,并发送至第一参与方。
步骤S107:结合第二参与方的CKKS公钥,由第一参与方利用CKKS算法将接收到的加密状态下的第二半梯度列表与本地明文状态下的第一半梯度列表相加,得到对应的第一加法结果密文;将数据ID对应的本地明文数据矩阵作转置后与第一加法结果密文做向量乘法,得到第一中间结果密文,并添加混淆后发送至第二参与方。
步骤S108:由第二参与方利用己方的CKKS私钥,解密添加混淆后的第一中间结果密文,得到第一全梯度列表并发送至第一参与方,以供第一参与方减去混淆后更新模型。
步骤S109:结合第一参与方的CKKS公钥,由第二参与方利用CKKS算法将接收到的加密状态下的第一半梯度列表与本地明文状态下的第二半梯度列表相加,得到第二加法结果密文;第二参与方将数据ID对应的本地明文数据矩阵作转置后与第二加法结果密文做向量乘法,得到第二中间结果密文,并添加混淆后发送至第一参与方。
步骤S110:由第一参与方利用己方的CKKS私钥,解密添加混淆后的第二中间结果密文,得到第二全梯度列表并发送至第二参与方,以供第二参与方减去混淆后更新模型。
在步骤S101中,本发明引入CKKS同态加密方案,提出一种使用CKKS同态加密算法完成纵向联邦逻辑回归的方法,大大加速了纵向联邦逻辑回归的计算过程。CKKS同态加密算法是利用分圆多项式的映射关系进行编码,其逆过程进行解码的一种同态加密方式,和paillier同态加密算法相比,CKKS同态加密拥有支持批量数据加密、支持浮点数计算、密文较小、密文计算速度快的优点,但是这些优点的前提是数据批量加密,也就是对一个数据列表进行加密。CKKS的安全性依赖于RLWE问题。明文是实数向量,表示为定点类型计算方式(实数表示方法:浮点计算和定点计算)。该方案很支持以SIMD方式在这些向量之间进行定点运算。
在实际应用过程中,各参与方可以基于预设算法自行生成CKKS公私密钥对,也可以通过请求可信任的第三方机构生成CKKS公私密钥对。各参与方包括有标签的第一参与方和没有标签的第二参与方,第一参与方记为guest方,第二参与方记为host方。
在步骤S102中,第一参与方和第二参与方分别对模型进行参数的初始化,其中,guest方的模型权重参数记为
在步骤S103中,基于纵向联邦学习的原理,首先对第一参与方和第二参与方的数据进行对齐,以统一本次迭代训练过程中的训练数据。具体的,由第一参与方guest将参与本轮训练的数据的ID按照一定顺序同步至第二参与方host。
在步骤S104和S105中,第一参与方和第二参与方分别基于本地的数据计算相应的半梯度列表,由于是完整梯度能在本地计算的部分,所以称为半梯度。
在一些实施例中,由第一参与方利用己方参数计算对应的第一半梯度列表,计算式为:
;
;
其中,
在一些实施例中,由第二参与方利用己方参数计算对应的第二半梯度列表,计算式为:
;
;
其中,
在步骤S106中,为了保证己方数据的隐蔽性,第一参与方利用己方的CKKS公钥对第一半梯度列表进行加密后发送至第二参与方host,这能保证其本地数据信息不会被泄露。相应的,第二参与方利用己方的CKKS公钥对第二半梯度列表进行加密后发送至第一参与方guest。
在步骤S107和S108中,第一参与方guest在接收到加密状态下的host方的第二半梯度列表后,与本地明文状态下本地的第一半梯度列表进行相加,后与本地明文矩阵的转置做向量乘法,以计算得到加密状态下完整的梯度,通过发送至第二参与方解密并返回,最终用于模型更新,这其中,添加混淆也是为了实现保密,隐藏本地数据的信息。
在一些实施例中,第一中间结果密文的计算式为:
;
其中,
步骤S109和S110同理,第二参与方host在接收到加密状态下的guest方的第一半梯度列表后,与本地明文状态下本地的第二半梯度列表进行相加,后与本地明文矩阵的转置做向量乘法,以计算得到加密状态下完整的梯度,通过发送至第一参与方解密并返回,最终用于模型更新。同样的,通过添加混淆,隐藏本地数据的信息。
所述第二中间结果密文的计算式为:
;
其中,
在一些实施例中,将数据ID对应的本地明文数据矩阵作转置后与第一加法结果密文做向量乘法,得到第一中间结果密文,并添加混淆后发送至第二参与方中,添加混淆的步骤包括:在第一中间结果密文中的每一项上添加一个随机数,并将各随机数记录为混淆向量。
在一些实施例中,随机数采用不经意伪随机函数生成。
在一些实施例中,所述方法采用tenseal库实现CKKS全同态加密。
在一些实施例中,所述方法中当迭代次数达到设定数值时停止训练。当然,也可以基于所构建的损失设置迭代停止的条件。
另一方面,本发明还提供一种纵向联邦逻辑回归训练装置,包括处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该装置实现上述方法的步骤。
另一方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。
下面结合具体实施例对本发明进行说明:
使用CKKS全同态加密提升联邦学习计算效率,由于CKKS密文采用批量加密形式,所以需要设计新的计算过程。标记有标签的参与方为guest,标记没有标签的参与方为host。
参照图1和图2,纵向联邦逻辑回归的计算过程:
步骤1:guest方和host方各自生成一对CKKS公私钥对{pka,ska}、{pkb,skb}。
步骤2:guest方和host方根据己方参数初始化模型参数
步骤3:host和guest交换公钥。
步骤4:host方和guest方开始并行计算。host方计算
步骤5:host方收到
guest方收到
步骤6:host和guest分别收到对方发来的
步骤7:双方得到各自的明文梯度后减去混淆并更新模型,并开始下一轮迭代。
不同于以往同态加密算法中所追求的解密结果和明文完全一致,CKKS算法的目标是做近似计算。这并不偏离需求,因为现实生活中大部分运算,面对的是实数(复数),而实数(复数)的运算,往往只需要保留一部分有效数字即可。此外,允许误差,放宽准确性的限制,使得CKKS对比于其他基于LWE/RLWE难题的同态方案,细节有了较大的简化,计算效率也有了很大提升。有些python的开源库实现了CKKS全通态加密方案,比如seal库以及以seal库为基础的tenseal库,本课题选用tenseal库实现CKKS加密,将本地计算的半梯度向量整体加密发送给对方参与方,对方参与方将数据按列转为向量,由于CKKS密文长度会对加解密之后的准确率有关,这个长度在1000左右,若数据量过大需要将数据分为多个向量进行加密和计算,分别和CKKS密文做向量相乘后得到最终结果。
进一步的,对纵向联邦学习过程中,引用传统paillier同态加密算法和CKKS同态加密算法进行性能比对,使用569条的breast数据集进行纵向联邦逻辑回归,数据共有31个维度,将数据切分为10个维度+标签以及20个维度两部分,guest方持有10维数据和1维的标签信息,host方持有20维数据,两个参与方联合训练模型。为了对比paillier同态加密和CKKS同态加密的效率,实现了CKKS和paillier两个版本,paillier同态加密算法采用的是FATE中使用的paillier实现,CKKS同态加密算法的实现采用的是微软开源的tenseal库中的实现。由于加密方式的参数设置会影响计算和加密效率,查阅相关资料后,对两种加密方式采用相同安全级别的加密参数,pailleir同态加密的加密参数设置为2048,CKKS同态加密的加密参数设置为[8192,[60,40,40,60],40],其他参数均保持一致,训练结束后对得到的模型进行预测对比,结果如表1:
表1 paillier和CKKS性能对比结果(breast数据集)
结果显示虽然CKKS在训练过程中有一些排序开销,但是使用CKKS同态加密训练的效率还是比paillier同态加密训练的效率高了10倍以上,并且得到了和paillier同样的训练结果。
综上所述,本发明所述纵向联邦逻辑回归训练方法及装置,各参与方使用CKKS全同态加密将本地计算的半梯度列表加密发送给对方,将接收到的对方加密后的半梯列表,与本地计算的明文半梯度列表相加并与明文数据矩阵的转置相乘,计算得到加密状态下完整的梯度。对加密状态下完整的梯度添加混淆后发送至对方参与方进行解密后返回,消除混淆后得到最终的明文梯度用于更新模型。基于纵向逻辑回归的训练模式,引入CKKS进行全同态加密,极大简化了同态加密过程,提升了计算效率。
与上述方法相应地,本发明还提供了一种装置/系统,该装置/系统包括计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该装置/系统实现如前所述方法的步骤。
本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时以实现前述边缘计算服务器部署方法的步骤。该计算机可读存储介质可以是有形存储介质,诸如随机存储器(RAM)、内存、只读存储器(ROM)、电可编程ROM、电可擦除可编程ROM、寄存器、软盘、硬盘、可移动存储盘、CD-ROM、或技术领域内所公知的任意其它形式的存储介质。
本领域普通技术人员应该可以明白,结合本文中所公开的实施方式描述的各示例性的组成部分、系统和方法,能够以硬件、软件或者二者的结合来实现。具体究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。当以硬件方式实现时,其可以例如是电子电路、专用集成电路(ASIC)、适当的固件、插件、功能卡等等。当以软件方式实现时,本发明的元素是被用于执行所需任务的程序或者代码段。程序或者代码段可以存储在机器可读介质中,或者通过载波中携带的数据信号在传输介质或者通信链路上传送。
需要明确的是,本发明并不局限于上文所描述并在图中示出的特定配置和处理。为了简明起见,这里省略了对已知方法的详细描述。在上述实施例中,描述和示出了若干具体的步骤作为示例。但是,本发明的方法过程并不限于所描述和示出的具体步骤,本领域的技术人员可以在领会本发明的精神后,作出各种改变、修改和添加,或者改变步骤之间的顺序。
本发明中,针对一个实施方式描述和/或例示的特征,可以在一个或更多个其它实施方式中以相同方式或以类似方式使用,和/或与其他实施方式的特征相结合或代替其他实施方式的特征。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种欺诈检测模型训练方法和装置及欺诈检测方法和装置
- 一种神经网络模型训练方法及装置、文本标签确定方法及装置
- 一种绿光估计模型训练方法及装置、影像合成方法及装置
- 纵向联邦学习线性回归和逻辑回归模型训练方法及装置
- 一种基于FTRL和学习率的纵向联邦逻辑回归训练方法及装置