一种基于安全多方计算技术的隐私保护实体识别工具
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及信息安全技术领域,尤其涉及一种基于安全多方计算技术的隐私保护实体识别工具。
背景技术
隐私保护实体识别旨在匹配出来自不同数据库的两条记录是否属于真实世界的同一个实体,同时不会暴露敏感信息。在大规模预训练语言模型Bert的支撑下,实体记录之间的相似度判别可以不仅仅受限于文本层面,还能受益于可以捕获语义的深度神经网络架构,因此实体识别本身的效率有了很大的提升。而如何在保护隐私信息的条件下,高效地完成Bert上的实体识别任务,就成为了一个亟待解决的问题。
现有的解决方案要么适用于很少有非线性操作的小模型,要么适用于非机器学习的低效实体识别方案。将安全多方计算技术引入实体识别任务是一个新颖的方案,它可以让每个参与方在不获取任何明文信息的情况下,独立完成Bert模型上的实体识别计算任务。我们采用了安全多方计算中的秘密共享技术,该技术具有信息论安全性和密码学安全性的双重保护。在此技术中,利用随机数和对应的加密算法,使得每个参与方拥有原始数据的一部分密文份额,而当且仅当所有的密文份额都被获取到后,原始明文才能被正确恢复。
现有技术存在一种安全多方计算技术应用于机器学习模型的工具Crypten,它提供了基本的安全多方计算和通信原语,以及一些神经网络中出现的非线性函数的多项式近似算法。Crypten提供模型加密和数据加密两个模块,模型通过安全类注册以及参数秘密共享来实现,数据通过直接进行秘密共享实现。由于秘密共享协议只具有同台可加性,对于神经网络中出现的e指数、倒数、平方根等非线性模块,采用牛顿-拉普森迭代、豪斯霍尔德迭代等算法进行近似。
但该技术存在如下问题:
首先,Bert模型含有需要明文索引的词嵌入模块,现有技术Crypten很难应用于其上,使得秘密共享份额能够与加密模型的输入端所匹配。其次,由于Bert模型的维度大,层数深,Crypten中的很多近似算法在Bert模型计算的过程中不收敛,导致整个模型输出错误结果。最后,Crypten没有覆盖一个完整的实体识别任务流程,缺少实体识别任务中的预分块步骤。
本发明解决的问题是:如何在大规模语言模型Bert上正确、稳定地应用安全多方计算方法,以完成隐私保护实体识别任务,并且不损失实体识别的准确度。
具体来说,实现Bert模型中的明文词嵌入模块与安全多方计算技术的匹配,不易收敛的高敏感模块(HSM)的优化,以及带有隐私保护的实体识别预分块模块的设计。
发明内容
为此,本发明首先提出一种基于安全多方计算技术的隐私保护实体识别工具,
包含嵌入矩阵共享、高敏感模块优化以及隐私保护预分块三个模块;
所述嵌入矩阵共享模块采用嵌入共享算法处理模型,通过对电商平台作为模型拥有者提供的共享嵌入矩阵进行索引,获得高维词矩阵;
所述高敏感模块优化模块对现有的bert模型中的四种高敏感模块进行优化,并使用秘密共享协议对数据和模型进行加密,参与者各自获得数据和模型的一半密文,并通过密文推理阶段,每个参与方独立地计算自己的密文各自独立地进行密文上的计算操作;
所述隐私保护预分块模块对两个计算参与方得到各自对应的一半结果A和结果B,并通过秘密共享协议的解密算法得到完整的明文结果“0”或“1”,即在电商活动各方都不暴露自己信息的情况下,通过相似度计算得出实体“匹配”或“不匹配”,即是否属于同一实体的结论。
所述公向算法处理模型当存在一个数据对s和一个经过微调的模型M时,模型拥有者首先将其Embedding层参数共享给数据拥有者,数据拥有者使用特定的分词器将数据对划分为tokens,然后,对于每个token,使用查找表来获得训练阶段得到的Embedding矩阵,以及其他Bert模型特有的Embedding,经过嵌入部分后,再进行层的归一化操作,最后应用秘密共享技术为数据拥有者和模型拥有者各自生成秘密共享份额;在加密数据集的Embedding得到数据共享份额之后对模型加密,得到加密模型。
所述其他Bert模型特有的Embedding包括位置、标记类型。
所述现有的四种高敏感模块进行优化具体包括,首先对Softmax函数进行优化,当上一层的输入进入softmax模块时,首先对其进行解密,让数据拥有者和模型拥有者得到softmax的明文输入,分别独立进行明文上的softmax计算,最后将结果重新利用秘密共享协议加密;
其次对平方根函数进行优化,首先引入一个因子r,利用此因子将原始值缩小到对应的收敛范围内,通过小范围的平方根逼近函数处理之后,再对结果乘以因子r,得到最终结果。我们在输入值上首先做max操作,判断最大值是否超过迭代次数为6时的收敛上界,若超过,便按照10的倍数设定因子r,从而动态扩展设置近似函数的收敛域;
之后对倒数的多项式近似优化,使用Newton-Raphson迭代法:
首先在初始化阶段,由于此近似算法的收敛条件为:
最后对Bert中的激活函数进行优化,使用GELU作为默认激活函数,其中包含高斯误差函数erf:
并设置GELU函数的近似:x*sigmoid(1.702x)。
所述隐私保护预分块模块采用PrivBlocking算法,对每个数据拥有者都保存一个原始数据库或表,这些数据库或表是方案感知的或方案感知的,首先进行预处理,使每个记录都是一个纯文本,去除属性界限,其余部分将同步在不同的数据拥有者上使用相同的方法执行,对于每个记录,使用Bert的Tokenizer生成Token列表,并创建一个Bloom过滤器结构,然后,对于每个Token,通过不同的哈希函数将“1”生成到相应的Bloom过滤器位置,在这个迭代结束时,每条数据都将持有一个只有“1”和“0”的Bloom过滤器;
在每个数据拥有者获得其私有的Bloom过滤器后,进行笛卡尔积,并获得可能匹配的索引对[x,y],而不泄漏敏感信息,最后,通过检查在相同的对应位置中有多少个“1”,并使用阈值s,锁定减少的候选对索引。
本发明所要实现的技术效果在于:
提出了一个兼具稳定性和鲁棒性的隐私保护实体识别框架PRIBER,能够在Bert模型上采用安全多方计算技术执行实体识别二分类任务,并且不牺牲实体识别本身的准确性。
附图说明
图1隐私保护实体识别框架PRIBER;
图2两个不同电商数据平台的4条记录处理示意;
图3square root函数与其多项式近似;
图4动态平方根近似算法;
图5迭代参数为6时的倒数与其多项式近似对比;
图6基于Bloom过滤器的隐私保护预分块;
图7在14个实体识别数据集上的结果
具体实施方式
以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于此实施例。
本发明提出了一种基于安全多方计算技术的隐私保护实体识别工具。应用于电商数据的隐私保护。
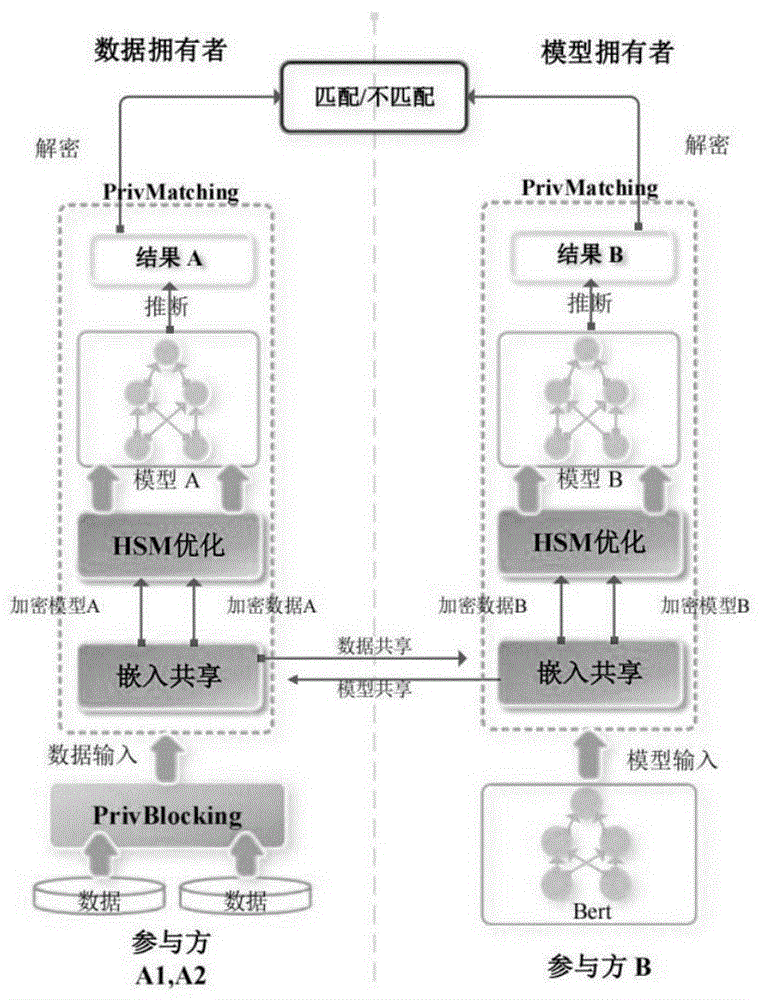
采用框架PRIBER,框架PRIBER支持两个或三个参与者,每个参与者代表一个数据拥有者或模型拥有者,如图1所示。在两个参与者的情况下,PRIBER可以跳过PrivBlocking模块,直接进行模型在数据上的推断操作。对于图1中所示的三个参与者,PRIBER可以实现从不同数据集匹配相同记录的实体识别问题。排除掉为乘法三元组提供随机种子的第三方之外,PRIBER中只有一台来自模型拥有者和一台来自数据拥有者的机器参与密文计算过程。最后只有收集到所有参与者的共享份额时,才能获得真实的明文结果。由于秘密共享协议的特点,数据拥有者和模型拥有者处在一个平等的关系上,他们可以同时独立地在加密的Bert模型中执行计算。与其他相关研究类似,我们的框架基于半诚实的模型环境,其中没有参与者恶意地进行攻击。
如图2所示,来自两个不同电商数据平台的4条记录,在各方都不暴露自己信息的情况下,通过相似度计算得出第一对不是同一实体,而第二对属于同一实体。
PRIBER的输入可以分为数据输入和模型输入,其中数据输入来自两个参与方A1、A2中的一个或单一的参与方A。通过PrivBlocking隐私预分块模块,每个数据拥有者可以获得两个原始数据集的候选索引对。要匹配的实际数据对输入也通过索引对来获得。对于模型输入,首先我们设计了嵌入共享算法处理模型,通过对模型拥有者提供的共享嵌入矩阵进行索引,获得高维词矩阵。然后,使用秘密共享协议对数据和模型进行加密。在该操作之后,参与者可以各自获得数据和模型的一半密文。在接下来的密文推理阶段,每个参与方可以独立地计算自己的密文。由于密文操作的局限性,需要乘法三元组和多项式近似算法的支持,为此我们设计并优化了高敏感模块(HSM)。最后,两个计算参与方得到各自对应的一半结果A和结果B,并通过秘密共享协议的解密算法得到完整的明文结果“0”或“1”,即实体“匹配”或“不匹配”。
在框架之内,具体来说,我们的发明包含嵌入矩阵共享、高敏感模块优化以及隐私保护预分块三个关键模块。
嵌入矩阵共享:
在隐私保护的环境下,Bert模型首先存在的问题是,对于一个应用于自然语言处理任务的预训练语言模型,嵌入层Embedding是必要的,它的核心是一个类似查找表的操作。因为此操作需要明文索引,我们不能直接在秘密共享之后的密文上来执行,否则明文信息就会暴露。
设计一种算法,让模型拥有者先在明文训练集上训练一个模型,并与数据拥有者共享嵌入矩阵。此Embedding层也是仅有的模型拥有者需要共享的一小部分。具体的算法如下所述:
当存在一个数据对s和一个经过微调的明文模型M时,模型拥有者首先从M中使用分离函数将Embedding层参数抽取出来,共享给数据拥有者。并封装好剩下的Encoder部分供后面使用。数据拥有者使用特定的分词器将数据对划分为子词列表。然后,对于每个子词,迭代使用Embedding层的明文查找表来获得接下来计算阶段所需的Embedding矩阵,以及其他Bert模型特有的Embed ding(位置、标记类型等)参数。经过上述嵌入部分后,再进行层内的归一化操作。最后,应用秘密共享技术为数据拥有者和模型拥有者各自生成数据部分的秘密共享份额。
在加密数据集的Embedding得到数据共享份额(EE)之后,通过模型加密所需的安全类注册(将Bert模型存在的类进行注册以防恶意类混入)模块以及参数加密操作,得到同样被数据拥有者和模型拥有者各占一部分加密模型(EM)。
高敏感模块(HSM)优化:
拥有一份加密数据对和一份加密模型,理想情况下每个参与方可以独立地对它们进行评估。但是,由于受限于密文有限域的限制和多项式近似方法的不稳定性,存在一些容易产生错误输出的模块,我们称之为高敏感模块(HSM)。事实上,有三种情况可能导致密文计算产生错误的结果:(1)运算溢出:当乘积或矩阵相乘的规模很大时。像Bert这类基于Transformer的模型通常在隐藏层宽度和深度方面都特别大。(2)不收敛:每个多项式逼近都有自己的收敛域,在函数求值时,收敛域不一定包含所有可能的值。(3)截断错误:当每个共享份额的总和超过使用秘密共享之前定义的环大小Q时,将秘密共享值
/>
因此,除法运算的截断错误会在θ≠0的时候产生不正确的结果,在两方安全计算的情况下此概率为
在上述条件的限制下,应该针对高敏感模块HSM做可靠的设计和改进使其能够应用于复杂的模型体系结构。首先为了防止密文溢出,我们将定点数编码缩放因子S设为2
第一个HSM是Softmax,它已经被证明是Transformer注意力层中一个非常耗时的模块,它包含许多指数运算:
此外,由于指数的近似需要进行大量的乘法运算(参考2.1.2的指数多项式近似),通信成本也不容忽视。为了平衡成本和精度,我们用迭代次数n=8来模拟极限,此时的收敛下界为-500附近。
在我们的例子中,我们发现这里的Softmax模块很容易产生错误的输出,这是由本节开头所述的几条错误条件所致。Softmax内部的max操作也使得它对大的错误值非常敏感。
在不对softmax层本身做改动的情况下,最多只能在特定的某几个数据集上完成含有4个Transformer编码器深度的密文计算,且最大隐藏层大小为512。因此,对于更复杂的体系结构,使用本地化技术对其进行改进。如前面所述,softmax模块不仅容易产生错误的结果,而且是一个非常耗时的部分,这对于开销巨大的密文计算来说是一个不容忽视的问题。所以当上一层的输入进入so ftmax模块时,首先对其进行解密,让数据拥有者和模型拥有者得到softmax的明文输入,分别独立进行明文上的softmax计算,最后将结果重新利用秘密共享协议加密。
第二个HSM是平方根函数。近似算法首先通过如下多项式近似的方法进行对平方根倒数的逼近:
首先初始化阶段用一个经验上快速收敛的值y
我们通过分析发现,上述算法根据不同的迭代次数,分别在某个确定的范围内可以很好地收敛。但超过此范围后,近似便不再有效,如图3所示是迭代次数为6时的平方根函数:
然而,Bert这类复杂架构模型的中间层结果范围很广,其范围可能是此收敛域的数倍。为了解决这个问题,我们改进得到动态平方根近似算法。首先引入一个因子r,利用此因子将原始值缩小到对应的收敛范围内,通过小范围的平方根逼近函数处理之后,再对结果乘以因子r,得到最终结果。考虑到收敛域的放大会导致在较小数值部分的近似误差变大,且大部分情况网络的中间结果并不会超出此收敛范围,我们改进的动态平方根近似算法如下所述:
首先引入一个缩放因子r,利用此因子将原始输入值缩小到对应函数的收敛范围内,通过小范围的平方根逼近函数处理之后,再对结果乘以因子r,得到最终结果。具体来说,我们首先在输入值上做max操作,判断输入的最大值m是否超过近似函数的迭代次数为6时的收敛上界t,若超过,便按照10的倍数设定因子r,利用公式:
r=(int(m.divide(t).divide(10))+1)*10
设定因子r的大小,然后令输入值除以r
第三个HSM是倒数的多项式近似。倒数的多项式近似使用Newton-Raphson迭代法,其公式如下:
首先在初始化阶段,由于此近似算法的收敛条件为:
对于前文所述的问题,模型中间结果浮动范围很大,我们改进了其初始值公式:
y
此初始赋值公式可以在任意的正数范围内收敛,因此可以很好地工作在我们的高可扩展性隐私保护计算系统中。
除了上述基础多项式近似函数之外,还值得注意的是,Bert中的激活函数也属于一个高敏感模块HSM。BERT使用GELU作为默认激活函数,其中包含高斯误差函数erf:
然而,该函数还没有鲁棒性的多项式逼近。Crypten中实现的现有近似方案为:
此公式有三个缺点:(1)幂运算的近似x
x*sigmoid(1.702x)
最终通过实验验证,第二种近似方法具有很好的鲁棒性,可以在精度损失极小的情况下得到更快更稳定的计算。
隐私保护预分块:
为了覆盖一个完整的隐私保护实体识别流程,我们设计了一种能够在保持原始概率特征的同时提高其信息保护能力的PrivBlocking算法,流程如图6所示。该算法可以有效地执行实体识别预分块步骤,并且对于数据拥有者来说,非常易于使用:
在PrivBlocking算法中,每个数据拥有者都保存一个原始数据库或表,这些数据库或表是模式可知(有属性界限)的或模式不可知(无属性界限)的,无论是什么类型的数据对,我们用(A,B)来表示,都需要进行预处理操作,使每个记录都是一个纯文本,去除属性界限。其余部分将同步在不同的数据拥有者上使用相同的方法执行。对于每个记录,使用Bert的Tokenizer生成Token列表,并创建一个Bloom过滤器结构。然后,对于每个Token,通过不同的哈希函数将“1”生成到相应的Bloom过滤器位置。在这个迭代结束时,每条数据都将持有一个只有“1”和“0”的Bloom过滤器。
在每个数据拥有者获得其私有的Bloom过滤器后,他们可以进行笛卡尔积,并获得可能匹配的索引对[x,y],而不泄漏敏感信息。最后,通过检查在相同的对应位置中有多少个“1”,并使用阈值s,锁定减少的候选对索引。
通过采用我们上述的优化算法,PRIBER可以在主流Bert模型上对大部分实体识别公共数据集进行二分类,方便扩展到其他自然语言处理任务以及其他模型上。
我们在一台机器上通过多个进程模拟多参与方进行实验。我们选取了14个实体识别领域的公共数据集,其中包括结构化数据、脏数据以及纯文本数据的不同类型。每一条记录都是以数据对加标签的形式存储,中间由Bert模型所识别的分隔符SEP区分:
[CLS]Sequence(a)[SEP]Sequence(b)[SEP]Label
我们首先在明文上训练一个准确率较高,表现较稳定的Bert模型,采用当前表现最好的的实体识别训练框架Ditto[3]。然后利用微调之后的模型,分别在明文和密文上进行实体识别推断任务。为了比较我们的高可扩展性隐私保护计算系统结果和明文上结果的性能,我们选取了能够平衡精度和召回率的指标F1:
我们分别测试了明文推理和密文推理上的计算时间、通信时间,以及密文推理上的通信总数据量。目前已有的实验结果证明,我们的高可扩展性隐私保护实体识别框架可以在F1指标不会有太大损失的情况下,在12*768规模的Bert模型上稳定工作,且对数据集不敏感。图7展示了在16个公共数据集上已完成的对比实验,其中C*为密文结果,P*为明文结果。该实验采用Bert的主流版本bert-base,包含12层Transformer编码器,768维度的隐藏层大小。Batch的大小选取256。对于每一个数据集,我们都做了3次相同环境下的实验,最后结果取平均值。实验结果表明,我们的框架得到的密文推断结果相比于明文推断结果只有很小的F1指标损失。该损失的差异与原始明文推断指标的优劣有关,明文推断表现越好,密文上F1的损失越小。密文上的计算时间相较于明文会慢几十至200倍,与现有的隐私保护计算研究大致符合。对于通信开销来说,我们的实验展示了每个数据集所用的通信规模和时间,根据此结果计算得到的通信速率与吉比特网络的速率相差不大,因此我们的框架可以在不需要高性能专业硬件成本的条件下复现。
- 基于Shamir安全多方计算的隐私保护多方强化学习系统及方法
- 一种基于安全多方计算的特征融合隐私保护方法