一种基于注意力机制循环神经网络的三维声速场预测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于声场预报领域,尤其涉及一种基于注意力机制循环神经网络的三维声速场预测方法。
背景技术
海洋蕴含着丰富的资源,开发海洋为人类带来了巨大效益,对海洋环境进行长期、及时、可靠的观测日益受到重视。但不同于空气介质,电磁波在海洋中传播受到各种限制,因此声波成为观测海洋最重要的手段,在通讯、定位、观测等领域广泛应用。影响声传播的因素有很多,其中声传播速度是至关重要的一部分。声传播速度在海洋环境中受到海域的温度、盐度、深度的影响,由于海洋环境复杂多变,温度、盐度在空间、时间上都呈现非线性变化,因此预测三维声速场具有较大难度。
预测声速场需要满足实时性、精确性的要求。常见的数值仿真方法分为预报驱动模式和后报驱动模式。后报驱动模式需要同化实时采样的水下设备采集的环境场数据,具有较高的精确度,但无法满足实时性的要求。预报驱动模式不需要实时采样的环境场数据,但预报准确度会随着预测时间增加而下降,无法满足精确性的要求。此外数值仿真方法通过将海域细分为小网格,通过变分法以及纳维-斯托克斯方程计算所有网格的数值,因此需要使用超级计算机或工作站,有较高的算力需求,而且需要消耗大量时间进行运算。
发明内容
本发明的目的在于针对现有技术的不足,提供一种基于注意力机制循环神经网络的三维声速场预测方法。本发明能够实现实时、高准确度、大范围的三维声速场预报。
本发明的目的是通过以下技术方案来实现的:一种基于注意力机制循环神经网络的三维声速场预测方法,包括以下步骤:
(1)将时序连续的k个预报三维声速场和后报三维声速场作为输入,并与随后输出的h个后报三维声速场组成多组数据对,以构建训练集;
(2)构建DA-RNN,并根据训练集对构建的DA-RNN进行训练,以获取最终的DA-RNN;
(3)将预报三维声速场输入到最终的DA-RNN中,以获取预测的后报三维声速场,并评价DA-RNN预测的准确度。
可选地,所述步骤(2)包括以下子步骤:
(2.1)构建DA-RNN,所述DA-RNN包括空间注意力层和时间注意力层,所述空间注意力层和时间注意力层连接;
(2.2)根据步骤(1)得到的训练集对步骤(2.1)构建的DA-RNN进行训练,并更新DA-RNN的参数以获取最终的DA-RNN。
可选地,所述步骤(2.1)包括以下子步骤:
(2.1.1)将预报三维声速场输入三维卷积层以获取空间注意力特征,以完成空间注意力层的构建;
(2.1.2)将空间注意力特征输入时间注意力层以获取预测的后报三维声速场,以完成时间注意力层的构建。
可选地,所述步骤(2.1.1)包括以下子步骤:
(2.1.1.1)将三维声速场定义为三维数组;
(2.1.1.2)将预报三维声速场输入空间注意力层,并根据t-1时刻LSTM单元的状态p
(2.1.1.3)通过softmax函数对空间注意力矩阵进行归一化,计算t时刻的注意力权重矩阵;
(2.1.1.4)根据注意力权重矩阵与预报三维声速场获取加权后的预报三维声速场;
(2.1.1.5)根据加权后的预报三维声速场获取k个时序连续的空间注意力特征,以完成空间注意力层的构建。
可选地,所述步骤(2.1.2)包括以下子步骤:
(2.1.2.1)将空间注意力特征以及对应时刻的后报三维声速场输入时间注意力层,并根据t-1时刻LSTM单元的状态s
(2.1.2.2)通过softmax函数对时间注意力矩阵进行归一化,计算时间注意力加权矩阵;
(2.1.2.3)根据时间注意力加权矩阵对空间注意力特征进行加权获取时-空注意力特征;
(2.1.2.4)将后报三维声速场与时-空注意力特征进行拼接,获取加权后的预报三维声速场;
(2.1.2.5)根据加权后的预报三维声速场与时-空注意力特征获取预测的后报三维声速场,以完成时间注意力层的构建。
可选地,所述步骤(2.2)包括以下子步骤:
(2.2.1)将训练集中的预报三维声速场输入到DA-RNN中,输出后报三维声速场预测值;
(2.2.2)使用均方误差计算后报三维声速场预测值与训练集中的后报三维声速场的误差;
(2.2.3)判断所述步骤(2.2.2)中的误差是否小于等于设置的误差阈值,若误差小于等于设置的误差阈值,则停止训练,以获取最终的DA-RNN;否则,则通过梯度下降法调整DA-RNN的参数的数值,再通过后向传播算法更新DA-RNN的参数,返回所述步骤(2.2.1)。
可选地,所述DA-RNN预测的准确度通过均方根误差进行判断,其表达式为:
其中,RMSE表示预测的后报三维声速场和真实测量的后报三维声速场之间的误差,c
本发明的有益效果是,本发明提高了预测三维声速场的精确性,对比预报驱动的数值仿真方法,克服随预测时间增加导致预测准确度下降的局限;本发明提高了预测三维声速场的实时性,对比后报驱动的数值仿真方法,不需要布放水下设备实时采样环境场数据,避免了环境场数据通过卫星回传至岸基的时间开销;本发明提高预测三维声速场的易用性,需要的算力开销小,对比需要使用工作站或超级计算机进行计算的数值仿真方法,训练完成的DA-RNN可以部署在个人电脑以及可移动设备上。
附图说明
图1是本发明预测后报三维声速场的流程图;
图2是本发明用于训练神经网络的训练集的示意图;
图3是本发明训练神经网络过程的示意图;
图4是本发明的整体神经网络模型的示意图;
图5是本发明的LSTM单元的示意图;
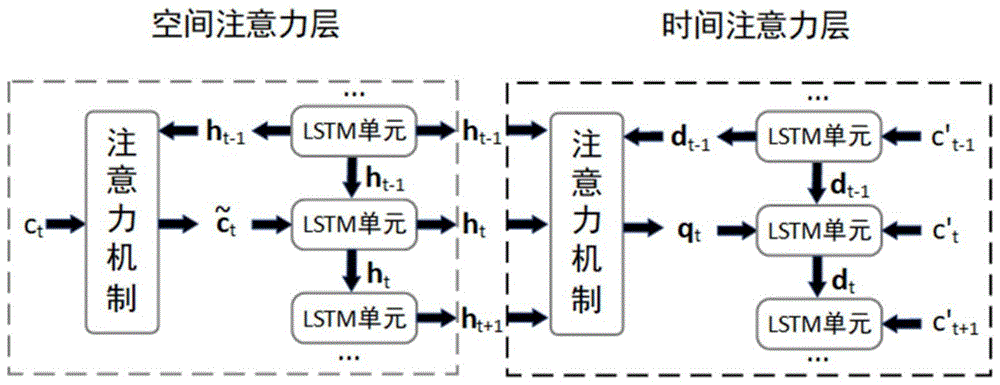
图6是本发明的空间注意力层的示意图;
图7是本发明的时间注意力层的示意图;
图8是本发明预测120小时后报三维声速场的实例。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明使用双阶段注意力机制循环神经网络(Dual-Stage Attention-BasedRecurrent Neural Network,DA-RNN)学习已有的后报声速场与预报声速场之间的联系,经过训练后得到收敛的DA-RNN;将已有的预报声速场输入训练后的DA-RNN预测后报声速场,实现实时、高精确度的三维声速场预报。
参见图1,本发明的基于注意力机制循环神经网络的三维声速场预测方法,包括以下步骤:
(1)如图2所示,将时序连续的k个预报三维声速场和后报三维声速场作为输入,并与随后输出的h个后报三维声速场组成一个数据对,共组成n组数据对,将总共n组数据对作为训练集用于训练DA-RNN。
本实施例中,作为输入的k个预报三维声速场和后报三维声速场表示为:
其中,C
随后输出的h个后报三维声速场表示为:
C
其中,C
训练集的n组数据对表示为:
其中,Trainset为训练集,C
本实施例中,构建完成的训练集用于训练DA-RNN。
(2)构建DA-RNN,并根据训练集对构建的DA-RNN进行训练,以获取最优的DA-RNN。
(2.1)构建DA-RNN,其中,DA-RNN包括空间注意力层(Spatial Attention Layer,SAL)和时间注意力层(Temporal Attention Layer,TAL),空间注意力层和时间注意力层连接。
本实施例中,构建一个用于预测后报三维声速场的注意力机制循环神经网络模型,即DA-RNN。如图4所示,DA-RNN主要包括空间注意力层(Spatial Attention Layer,SAL)和时间注意力层(Temporal Attention Layer,TAL)。输入的预报三维声速场经过空间注意力层,输入的后报三维声速场经过时间注意力层,最终预测未来的后报三维声速场。
其中,空间注意力层基于长短期记忆(Long Short-Term Memory,LSTM)单元,用于计算三维声速场每个部分的空间注意力加权矩阵。
(2.1.1)将预报三维声速场输入三维卷积层以获取空间注意力特征,空间注意力层的构建如图6所示。
(2.1.1.1)将三维声速场定义为三维数组,表示为C:
其中,X、Y、Z分别为三维声速场在x轴、y轴、z轴上的采样点数,c(i,j,m)表示三维声速场在位置(i,j,m)上的声速值,i、j、m分别表示三维声速场在x轴、y轴、z轴上的位置坐标。
(2.1.1.2)将预报三维声速场输入空间注意力层,经过如下流程计算,如图5所示:
其中,
应当理解的是,sigmoid函数和双曲正切函数都是激活函数,可以在保持自身可导性的前提下实现记忆或遗忘输入数据,在此不再赘述。elemental-wise乘积用于将两个数组内的对应元素进行相乘。
注意力机制通过t-1时刻LSTM单元的状态p
其中,
进一步地,t时刻的注意力矩阵e与预报三维声速场c具有相同维度,即:
(2.1.1.3)通过softmax函数对空间注意力矩阵进行归一化,计算t时刻的注意力权重矩阵,其表达式为:
其中,exp(·)表示指数函数。
(2.1.1.4)将t时刻的注意力权重矩阵与t时刻的预报三维声速场做element-wise乘积,得到加权后的t时刻预报三维声速场:
(2.1.1.5)得到加权后的t时刻预报三维声速场后
本实施例中,将k个时序连续的预报三维声速场输入空间注意力层,最终可以得到k个时序连续的空间注意力特征,表示为:
其中,
应当理解的是,
(2.1.2)将空间注意力特征输入时间注意力层以获取预测的后报三维声速场,以完成时间注意力层的构建。
(2.1.2.1)如图7所示,将k个时刻的空间注意力特征:
以及对应时刻的后报三维声速场:
C′={c
输入时间注意力层,同样使用注意力机制进行加权,对变化较大的时刻赋予较高权重,时间注意力层同样基于LSTM单元,具体操作如下:
其中,σ
然后通过t-1时刻LSTM单元的状态s
其中,i代表所有的输入时刻,l
(2.1.2.2)同样通过softmax函数对时间注意力矩阵进行归一化,计算时间注意力加权矩阵β
其中,exp(·)表示指数函数,β
(2.1.2.3)根据时间注意力加权矩阵对每个时刻预报三维声速场的空间注意力特征
(2.1.2.4)t时刻的LSTM单元将t时刻的后报三维声速场c
/>
其中,
(2.1.2.5)根据加权后的预报三维声速场与时-空注意力特征获取预测的后报三维声速场,以完成时间注意力层的构建。
具体地,k时刻的LSTM单元(最后一个LSTM单元)输出预测的后报三维声速场特征d
其中,
(2.2)根据步骤(1)得到的训练集对步骤(2.1)构建的DA-RNN进行训练,并更新DA-RNN的参数以获取最终的DA-RNN。
具体地,训练集包括多组数据对,对于每一组数据对均有:
(2.2.1)如图3所示,将训练集中的预报三维声速场输入到DA-RNN中,输出后报三维声速场预测值,表示为:
C
其中,f·代表DA-RNN,C
(2.2.2)使用均方误差(Mean Square Root,MSE)计算后报三维声速场预测值C
loss=(C
(2.2.3)判断步骤(2.2.2)中的误差是否小于等于设置的误差阈值,若误差小于等于设置的误差阈值,则停止训练,以获取最终的DA-RNN;否则,则通过梯度下降法调整DA-RNN的参数的数值,再通过后向传播算法(Back Propagation,BP)更新DA-RNN的参数,返回步骤(2.2.1)。
本实施例中,DA-RNN的参数包括空间注意力层的LSTM单元中的w
通过梯度下降法调整所有参数偏的数值,使误差loss的数值下降至小于等于所设置的误差阈值,结束DA-RNN的训练并固定所有参数的数值。
(3)在DA-RNN训练完成固定参数后,不需要再输入后报三维声速场,只需要将预报三维声速场输入到最终的DA-RNN中,以获取预测的后报三维声速场,并评价DA-RNN预测的准确度。
具体地,将不属于训练集的时序连续的k个预报三维声速场输入步骤(2)得到的最终的DA-RNN,获取预测到的后报三维声速场。
不属于训练集的时序连续的k个预报三维声速场表示为:
C
预测到的后报三维声速场表示为:
C
其中,f′(·)代表训练后的最终的DA-RNN。
将真实和预测的后报三维声速场进行比较,评估DA-RNN的预测准确度。具体地,使用均方根误差(Root Mean Square Error,RMSE)评价DA-RNN预测后报三维声速场的准确度。DA-RNN预测的准确度采用均方根误差进行判断,其表达式为:
其中,RMSE表示预测的后报三维声速场和真实测量的后报三维声速场之间的误差,c
很容易理解的是,均方根误差越小,说明DA-RNN预测的准确度越大;均方根误差越大,说明DA-RNN预测的准确度越小。
应当理解的是,均方根误差(RMSE)与均方误差(MSE)在判断预测误差上具有相同的特性,MSE便于神经网络迭代中计算导数,RMSE在数值上是MSE的开二次方,能够更加直观的表现出误差大小。
下面根据实施例详细描述本发明的使用三维卷积循环神经网络的三维声速场预测方法,本发明的目的和效果将变得更加明显。
实施例
为验证使用DA-RNN预测后报三维声速场方法的有效性,开展仿真分析。选择中国南海区域长度为80km,宽度为80km,深度为375m的海域的声速场,在x轴、y轴上采样点数为6,采样分辨率为13km,z轴上采样点数为15,采样分辨率为25m,则有:
使用的三维卷积核在x轴、y轴的长度为2,在z轴的长度为5,则有:
输入序列长度k为6小时,预测时间h为2小时,训练集大小n为168,则有:
使用训练集对DA-RNN进行训练。
如图8所示,使用不属于训练集的120组预报三维声速场输入DA-RNN:
C
预测120小时的后报三维声速场:
/>
使用RMSE评价预测准确度,灰色虚线代表预报三维声速场与后报三维声速场的RMSE随时间的变化,黑色实线代表使用DA-RNN预测的三维声速场与后报三维声速场的RMSE随时间的变化,可以看到使用DA-RNN预测的三维声速场有较大的精度提升,说明本发明预测三维声速场的有效性。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。