一种聋哑人语音辅助手机系统
文献发布时间:2024-01-17 01:26:37
技术领域
本发明涉及语音识别及手机技术领域,具体涉及一种聋哑人语音辅助手机系统。
背景技术
目前,随着语音识别技术的不断发展,越来愈多的设备(比如手机、电视机、空调器等家用电器)都可以通过语音控制来执行相应的功能,例如:受控设备检测到语音控制指令时,可以根据检测到的控制指令来执行相应的操作,因此,语音交互给用户的日常生活带来了很多便利。
但是,对于聋哑人,在日常生活、学习环境中的交流存在障碍,相比健康人群,给语音交互提出新的挑战。
发明内容
本发明提出一种聋哑人语音辅助手机系统,旨在解决聋哑人日常生活、学习环境中的交流障碍,使得人与人之间的交流更加顺畅,提升聋哑人对生活的自信心。
具体的,本发明提出一种聋哑人语音辅助手机系统,包括:
显示模块,设置为用于显示文字信息;
语音录入模块,设置为录入用户日常生活中交流用语的语音信息;
智能语音处理模块,设置为提取用户日常生活交流用语的语音信息,与文字信息建立一一对应关系的数据库;
语音识别模块,设置为通过用户的外界语音信息输入,识别语音信息内容,对应的从数据库获取文字信息,并将文字信息输出到显示模块;
语音播放模块,设置为能够将显示模块显示的文字信息转化成语音信息进行播放。
作为优选的技术方案,智能语音处理模块设置为定期复核数据库中文字信息建立一一对应关系,修正数据库中存在的对应错误的关系。
作为优选的技术方案,数据库上传到云端服务器进行备份。
作为优选的技术方案,智能语音处理模块设置为定期统计语音信息与文字信息对应关系的使用频率,根据使用频率更新数据库。
作为优选的技术方案,语音识别模块根据外界语音信息输入,识别语音特点,语音特点包括普通话、方言或口音。
作为优选的技术方案,识别模块根据语音特点,确定与语音特点对应的语音匹配模型,并采用与语音特点对应的语音匹配模型对输入的语音信息进行识别。
作为优选的技术方案,智能语音处理模块,提取用户日常生活交流用语的语音信息,确定与语音特点对应的语音匹配模型,并采用与语音特点对应的语音匹配模型对输入的语音信息进行识别,输出语音识别结果,再与文字信息建立一一对应关系的数据库。
作为优选的技术方案,语音播放模块能够根据语音特点将显示模块显示的文字信息转化成对应语音特点的语音信息进行播放。
作为优选的技术方案,语音播放模块设置有提醒功能,能够发出文字提醒信息,提醒信息弹窗显示于显示模块显示的文字信息旁;提醒信息可以为提醒用户本次对话识别结果准确度不高,是否要重新识别语音。
作为优选的技术方案,语音识别模块还包括语音转化去噪模块,用以去除噪音,进行语音分析。
本发明相对于现有技术取得了以下技术效果:本发明技术方案在手机中融入聋哑人辅助交流系统,包括语音识别模块,智能语音处理模块、语音播放模块等,在日常交流中使用者可以带着手机,录入会话者语音,通过语音识别模块识别对话内容,通过智能语音处理模块对应出回答信息,进而通过语音播放模块将回答的信息转化为语音,如此,完成了一次聋哑人的日常交流。该系统与手机系统兼容,方便用户日常使用。而且,该系统使得人与人之间的交流更加顺畅,提升聋哑人对生活的自信心。
本申请的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本申请而了解。
附图说明:
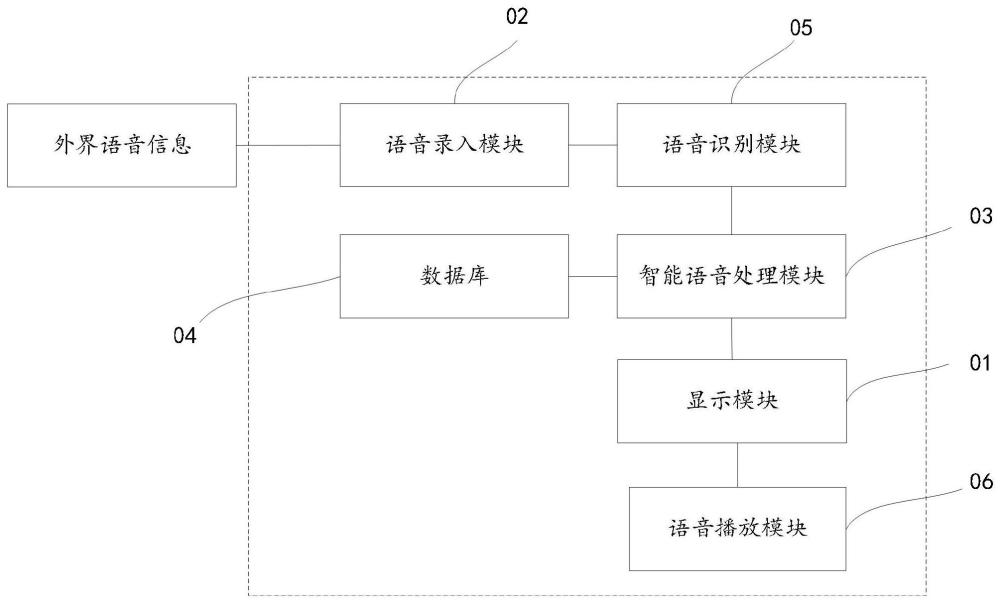
图1本发明实施例提出的一种聋哑人语音辅助手机系统结构框图;
图2本发明实施例提出的一种聋哑人语音辅助手机系统结构框图。
附图标记说明:
显示模块01;语音录入模块02;智能语音处理模块03;数据库04;语音识别模块05;语音播放模块06;语音转化去噪模块07。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明具体实施例及相应的附图对本发明技术方案进行清楚、完整地描述。在本发明的描述中,需要说明的是,术语“或”通常是以包括“和/或”的含义而进行使用的,除非内容另外明确指出外。
应当理解,本申请的方法实施方式中记载的各个步骤可以按照不同的顺序执行,和/或并行执行。此外,方法实施方式可以包括附加的步骤和/或省略执行示出的步骤。本申请的范围在此方面不受限制。
本文使用的术语“包括”及其变形是开放性包括,即“包括但不限于”。术语“基于”是“至少部分地基于”。术语“一个实施例”表示“至少一个实施例”;术语“另一实施例”表示“至少一个另外的实施例”;术语“一些实施例”表示“至少一些实施例”。其他术语的相关定义将在下文描述中给出。
需要注意,本申请中提及的“一个”、“多个”的修饰是示意性而非限制性的,本领域技术人员应当理解,除非在上下文另有明确指出,否则应该理解为“一个或多个”。“多个”应理解为两个或以上。
如图1所示,为本实施例提出的一种聋哑人语音辅助手机系统,该系统包括:
显示模块01,设置为用于显示文字信息;
语音录入模块02,设置为录入用户日常生活中交流用语的语音信息;
智能语音处理模块03,设置为提取用户日常生活交流用语的语音信息,与文字信息建立一一对应关系的数据库04;
语音识别模块05,设置为通过用户的外界语音信息输入,识别语音信息内容,对应的从数据库04获取文字信息,并将文字信息输出到显示模块01;
语音播放模块06,设置为能够将显示模块01显示的文字信息转化成语音信息进行播放。
关于数据库04,本手机系统可以由一个健康的人,带着手机,录取生活区周边环境日常生活中经常出现的语音(包括问题和回答),收集完语音后,再由健康的人通过打字等,将语音与文字一一对应联系起来,本手机系统再记录这种联系。例如,日常中常见的买东西,聋哑人用户可以拿着手机,通过语音录入模块02,录入会话者的语音内容,经常的问题有,“这个多少钱”,“能否便宜点”等等。而回答经常可以是数字,或者“OK”,“我确认买它”等等。
优选的,智能语音处理模块03设置为定期复核数据库04中文字信息建立一一对应关系,修正数据库04中对应错误的关系。由于在日常交流中,会存在口音、方言等语音信息录入,语音识别模块05会出现错误识别,进而出现对应关系错误的情况发生,因此智能语音处理模块03需要设置为定期进行修正复核,对于一直出现错误的对应关系,还可以通过强制建立某种文字与语音的对应关系,完成数据库04的复合并重新建立。通过对数据库04的复核和修正,可以保证数据库04中文字与语音的对应关系,从而可以更准确地帮助聋哑人用户识别对话内容,同时回答出准确的答案信息,使得交流更加顺畅。
优选的,数据库04上传到云端服务器进行备份。具体的,可以将建立后的数据库04在设备内进行存储,并上传到云服务器进行备份,例如:可以将建立好的数据库04存储在手机上,并通过手机上传到云服务器上,这样方便调用数据库04,也可以避免更换设备后导致数据库04的丢失。
优选的,智能语音处理模块03设置为定期统计语音信息与文字信息对应关系的使用频率,根据使用频率更新数据库04。通过定期统计对应关系的使用频率更新数据库04,设置优先级,提高对应关系响应速度,更快的输出会话信息,提高沟通效率。
优选的,语音识别模块05根据外界语音信息输入,识别语音特点,语音特点包括普通话、方言或口音。进一步的,识别模块根据语音特点,确定与语音特点对应的语音匹配模型,并采用与语音特点对应的语音匹配模型对输入的语音信息进行识别。可以从预先建立的多个模型中确定出对应的语音匹配模型,再采用该对应的语音匹配模型进行语音识别,例如,得到语音特点是川渝话,则可以采用川渝话对应的语音匹配模型进行对输入语音进行语音识别。上述描述了先确定语音特点再确定语音匹配模型,可选的,语音特点和语音匹配模型可以同步确定。
具体的,可以为语音信息进行特征提取,得到特征信息。本领域技术人员可以理解,特征提取可以为基频特征提取,谱特征提取或能量特征提取等。根据特征信息以及预先建立的多个语音匹配模型,进行语音识别,得到每个模型对应的信度值。多个语音匹配模型可以是预先建立的所有模型,或者,从预先建立的所有模型中选择的多个模型。本领域技术人员应该可以理解,日常的生活交流多为社区,语言模式比较固定,容易匹配出正确的会话信息。但是随着生活的便利,聋哑人的交际范围越来越广,日常生活交流的对象会来自不同的地域,因此,需要匹配多个模型识别语音内容。例如,语音匹配模型可以分别是东北话对应的匹配模型,陕北话对应的匹配模型,闽南话对应的匹配模型,川渝话对应的匹配模型。语音输入后,每个语音匹配模型对语音识别,会产生一个对应的信度值。根据信度值得到最优的语音匹配模型,并获取最优的语音匹配模型对应的语音特点和语音识别结果。数据库04的建立过程中,通过不断地迭代,驯化,使得数据库04中的对应关系更加趋向于准确。
另外,可以理解的是,如果找不到与特征信息一致的语音特点和语音匹配模型,可以根据信度值,找到最相似的语音匹配模型,采用该最相似的语音匹配模型进行语音识别。语音识别后,从数据库04中获取对应的回答文字或者图片。在语音播放时,可以根据语音匹配模型获得的语音特点,自动采用该中语音特点播放对应的文字。
优选的,智能语音处理模块03,提取用户日常生活交流用语的语音信息,确定与语音特点对应的语音匹配模型,并采用与语音特点对应的语音匹配模型对输入的语音信息进行识别,输出语音识别结果,再与文字信息建立一一对应关系的数据库04。
如图2所示,在一些优选的实施例中,语音识别模块05还包括语音转化去噪模块07,用以去除噪音,进行语音分析。对输入语音进行预处理,预处理为降噪处理,方便更准确识别语音内容。
优选的,语音播放模块06能够根据语音特点将显示模块01显示的文字信息转化成对应语音特点的语音信息进行播放。
进一步优选的,语音播放模块06设置有提醒功能,能够发出文字提醒信息,提醒信息弹窗显示于显示模块01显示的文字信息旁;提醒信息可以为提醒用户本次对话识别结果准确度不高,是否要重新识别语音。语音识别模块05根据语音识别过程中,语音特点与语音匹配模型的匹配度以及匹配时间,设置信度值,信度值越高,则匹配度越高,则对应的文字回答信息就会越正确。相反,如果信度值很低,则代表对应的文字回答信息与输入的语音内容不是很匹配,此时,语音识别模块05可以发送信息给语音播放模块06及显示模块01,在语音播放前,或同步,显示在文字的旁边一条提醒信息,提醒用户是否要重新输入语音内容,如果使用者要重新输入,可以重复使用语音录入模块02重新录入语音内容,重新进行对话。
显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
- 一种基于zigbee的盲聋哑人使用的手机系统
- 多种语言适用的聋哑人语音学习计算机辅助方法