基于语义感知的电力作业智能协同增强现实系统及方法
文献发布时间:2024-01-17 01:26:37
技术领域
本发明涉及增强现实领域,具体是基于语义感知的电力增强现实智能协同方法与系统。
背景技术
电力设备维护过程中,不同场景(或位置)下电力作业人员之间需要进行协同工作。而单个的电力作业人员只能够获取在视线内的设备状态;如何将不同的电力作业人员获取的在视线内的设备状态,通过增强现实(AR)眼镜与其他电力作业人员获取的视线内的设备状态电力场景下的信息进行融合,以便于电力操作,是当下研究人员需要研究的问题。
发明内容
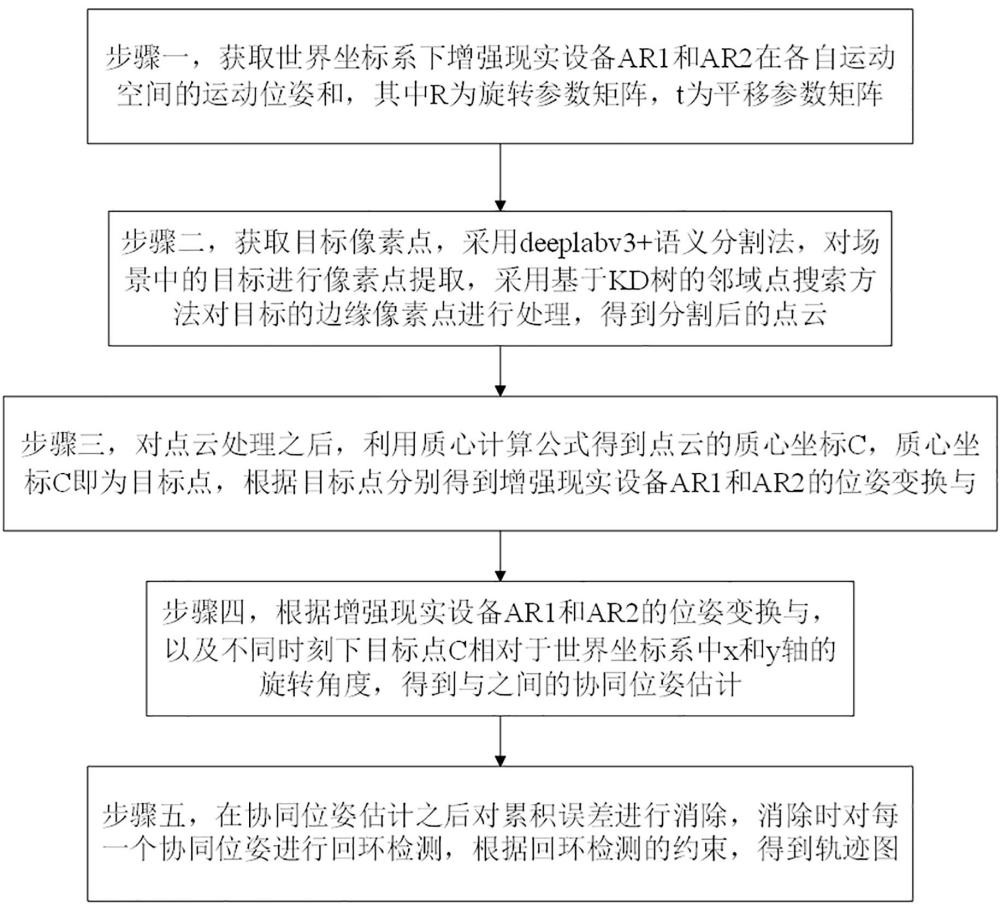
本发明的目的在于克服现有技术的不足,提供基基于语义感知的电力增强现实系统智能协同方法,包括如下步骤:
步骤一,获取世界坐标系下增强现实设备AR1和AR2在各自运动空间的运动位姿
步骤二,获取目标像素点,采用deeplabv3+语义分割法,对场景中的目标进行像素点提取,采用基于KD树的邻域点搜索方法对目标的边缘像素点进行处理,得到分割后的点云;
步骤三,对点云处理之后,利用质心计算公式得到点云的质心坐标C,质心坐标C即为目标点,根据目标点分别得到增强现实设备AR1和AR2的位姿变换
步骤四,根据增强现实设备AR1和AR2的位姿变换
步骤五,在协同位姿估计之后对累积误差进行消除,消除时对每一个协同位姿进行回环检测,根据回环检测的约束,得到轨迹图。
进一步的,所述的获取目标像素点,采用deeplabv3+语义分割法,对场景中的目标进行像素点提取,采用基于KD树的邻域点搜索方法对目标的边缘像素点进行处理,得到分割后的点云,包括:采用deeplabv3+语义分割法获取场景中的目标像素分割结果,采用基于KD树的邻域点搜索方法对目标像素边缘部分进行进一步分割处理,提高边缘部分像素点的提取精度,结合像素点的深度信息,将目标三维信息转换成点云数据格式,即得到分割后的点云。
进一步的,所述的对点云处理之后,利用质心计算公式得到点云的质心坐标C,质心坐标C即为目标点,根据目标点分别得到增强现实设备AR1和AR2的位姿变换
点云的质心坐标
AR2满足以下关系:
进一步的,所述的根据增强现实设备AR1和AR2的位姿变换
进一步的,所述的在协同位姿估计之后对累积误差进行消除,消除时对每一个协同位姿进行回环检测,根据回环检测的约束,得到轨迹图,包括:由于每一次的协同位姿估计都会产生误差,通过对相邻帧的图像进行相似性评分,当大于设置值时即完成了回环检测,然后测量回环的准确率和召回率,根据具体数值判断是否有回环,从而对累积误差进行消除,得到轨迹图。
本发明的有益效果是:本发明通过分析影响语义协同过程精度、稳定性的因素,解决目前场景信息提取和语义协同位姿估计等关键技术中存在的问题。通过分析场景特征信息对协同位姿精度的影响,建立智能协同估计模型,并满足算法对实时性与稳定性的要求,从而保证增强现实系统的稳定性。
附图说明
图1为基于语义感知的电力增强现实系统智能协同方法的流程示意图;
图2为协同位姿估计流程示意图。
具体实施方式
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
为了使本发明的目的,技术方案及优点更加清楚明白,结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。需要说明的是,术语“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。
而且,术语“包括”,“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程,方法,物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程,方法,物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程,方法,物品或者设备中还存在另外的相同要素。
以下结合实施例对本发明的特征和性能作进一步的详细描述。
如图1所示,基于语义感知的电力增强现实系统智能协同方法,包括如下步骤:
步骤一,获取世界坐标系下增强现实设备AR1和AR2在各自运动空间的运动位姿
步骤二,获取目标像素点,采用deeplabv3+语义分割法,对场景中的目标进行像素点提取,采用基于KD树的邻域点搜索方法对目标的边缘像素点进行处理,得到分割后的点云;
步骤三,对点云处理之后,利用质心计算公式得到点云的质心坐标C,质心坐标C即为目标点,根据目标点分别得到增强现实设备AR1和AR2的位姿变换
步骤四,根据增强现实设备AR1和AR2的位姿变换
步骤五,在协同位姿估计之后对累积误差进行消除,消除时对每一个协同位姿进行回环检测,根据回环检测的约束,得到轨迹图。
所述的获取目标像素点,采用deeplabv3+语义分割法,对场景中的目标进行像素点提取,采用基于KD树的邻域点搜索方法对目标的边缘像素点进行处理,得到分割后的点云,包括:采用deeplabv3+语义分割法获取场景中的目标像素分割结果,采用基于KD树的邻域点搜索方法对目标像素边缘部分进行进一步分割处理,提高边缘部分像素点的提取精度,结合像素点的深度信息,将目标三维信息转换成点云数据格式,即得到分割后的点云。
所述的对点云处理之后,利用质心计算公式得到点云的质心坐标C,质心坐标C即为目标点,根据目标点分别得到增强现实设备AR1和AR2的位姿变换
点云的质心坐标
AR2满足以下关系:
所述的根据增强现实设备AR1和AR2的位姿变换
所述的在协同位姿估计之后对累积误差进行消除,消除时对每一个协同位姿进行回环检测,根据回环检测的约束,得到轨迹图,包括:由于每一次的协同位姿估计都会产生误差,通过对相邻帧的图像进行相似性评分,当大于设置值时即完成了回环检测,然后测量回环的准确率和召回率,根据具体数值判断是否有回环,从而对累积误差进行消除,得到轨迹图。
具体的,系统应用的场景为两个或多个电力作业场景,可以是室内或者室外。
针对不同环境建立语义分割数据集,获取场景中的像素级语义点云分类结果,得到多层次特征。
提出结合语义分割的智能协同理论模型,通过对点云空间中任意点的邻域进行统计学分析,获取协同位姿。
通过分析影响语义协同位姿的估计精度因素,建立优化模型,提出减小累积误差新方法。
本发明旨在通过分析影响语义协同过程精度、稳定性的因素,解决目前场景信息提取和语义协同位姿估计等关键技术中存在的问题。通过分析场景特征信息对协同位姿精度的影响,建立智能协同估计模型,并满足算法对实时性与稳定性的要求,从而保证增强现实系统的稳定性。
本发明拟对基于语义感知的增强现实协同方法进行研究。
稳定的协同注册需要首先从场景中提取特征信息,再对设备的协同位姿变化进行估计。
基于特征点的注册方法有一定的局限性,在稀疏场景中易发生特征丢失。
通过分析影响注册精度的因素,利用深度学习语义分割算法获取场景中的目标信息,语义分割能够得到场景的像素级分割结果,在获取目标所属类别的同时,得到目标的像素级分割结果。
结合不同场景中的语义信息对协同位姿进行估计,通过建立语义协同位姿估计模型,得到协同位姿的估计结果。
提取出场景的语义目标后,为了节省人工标定的成本,获得精确的标签,在完成位置识别后,利用位姿优化算法将位姿和场景三维坐标进行优化,以得到稳定的语义协同注册结果。
基于国内外的研究进展情况,由于场景的纹理、目标数量、结构复杂度等因素,对设备之间的协同的处理都有一定的影响,增强现实系统的稳定性有望提高。本发明重点解决语义协同位姿估计问题:
(1)语义场景信息提取
由于环境的变化性与多样性,在电力作业场景下,需要对电力场景进行理解,对电力场景中的电力设备等信息,获取其图像特征(如目标的特征点或特征点云),从而保证注册的稳定性与准确性,是其中一个难点。语义分割,通过深度卷积神经网络将目标进行提取,通过训练的方式在网络终端输出目标的分类结果,以及目标的分割结果,结合此目标的深度信息,从而得到目标的分类及分割点云。
(2)语义协同位姿估计
在不同的场景中,各个设备之间需要对多个视图进行对齐和融合,这就需要能够在不同时间下获得场景的实时姿态信息,并且能够形成环境的全局跟踪注册模型。语义协同的位姿估计能够实时地获取不同设备的运动姿态,是增强现实关键技术中的一个重要科学问题。通过对点云空间中任意点的邻域进行统计学分析,保留运动主体在当前时刻和过去时刻的位姿,结合语义分割的结果,获取语义协同位姿。
设世界坐标系为W,假设有两个增强现实设备(增强现实眼镜),分别为AR眼镜1和AR眼镜2,两个眼镜分别观察不同的场景,要想让两个场景融合得到全局地图,需要获取两个设备之间的协同位姿。
假设AR眼镜1在场景中运动,其在世界坐标系W中的运动位姿为R,t,其中R为旋转参数矩阵,t为平移参数矩阵。根据坐标系之间的映射关系,将AR眼镜1的姿态变化映射到AR眼镜2的运动空间中。
在获取运动点时,语义分割方法采用deeplabv3+语义分割方法,首先对场景中的目标进行提取,点云边缘部分容易出现分割误差,此时对点云空间的邻域进行统计学分析,以提高点云分割的精度,语义分割的像素点具有一定的不确定度,针对此问题,采用基于KD树的邻域点搜索方法对目标边缘的像素点进行处理,从而预测像素分类的准确程度。
对点云处理之后,利用质心计算公式得到点云的质心坐标
AR眼镜2满足以下关系:
若
至此得到了带有语义信息的协同位姿。
在语义协同位姿估计的过程中,在每一次的估计之后都会产生误差,长时间的误差累积会造成三维跟踪注册算法的失效,因此要在语义协同位姿估计之后对累积误差进行消除,消除时需要对每一个协同位姿进行回环检测,根据回环检测的约束,得到轨迹图,以得到语义协同位姿的闭环。
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 一种基于车路协同感知系统的语义地图构建方法
- 基于肌电感知技术的可穿戴增强现实作业指导系统及方法