基于几何特征提取和位置信息编码的车道线检测方法
文献发布时间:2024-01-17 01:27:33
技术领域
本发明属于图像处理技术领域,更进一步涉及图像分割技术领域中的一种基于几何特征提取和位置信息编码的车道线检测方法。本发明可用于通过自动驾驶设备实现机动车在行驶过程中对车道线的检测。
背景技术
在车道线检测中,每条车道的确切形状是由安装在车辆上的摄像头捕捉到的二维前视图像获得的。除了获得车道线的方向和形状外,系统还必须能够区分每条车道。也正因为如此,车道线检测往往被视作一种语义分割任务。之前的绝大部工作都采用纯分割的方法,即通过编码器来捕捉其语义特征,再进行解码后处理得到最终结果。车道线检测是一种相对特殊的检测问题,它具有不同于其他检测问题的挑战,如噪声大(多阴影遮挡),属于正样本的像素占全图的比例低(车道线细长),形式多样(有不同颜色和形状的车道线),场景多样(受到天气因素影响)。因此,如果仅将其视作传统的语义分割问题来处理,采用纯分割的方法无法有效地处理一些复杂场景如阴影,强光,夜间等,适用范围小。而且对于车道线,除了最为基本的语义特征以外,还有一个重要的特点就是车道线属于人工物体,这不同的一般的自然物体,其拥有强烈的先验几何特征(车道线一般都是细长的平行四边形结构,如果利用其几何特征将带来更好的检测性能。同时,车道线之间具有位置信息,例如现实世界种车道线之间是平行的。因此如果不考虑位置信息,也会丧失一些检测性能。
华东交通大学在其申请的专利文献“一种基于深度学习的车道线检测方法”(申请号:2022110592895,申请公布号:CN 115376089 A,申请公布日:2022.11.22)中提出了一种自动驾驶设备实现机动车车道线检测方法。该方法的实现步骤是:(1)对数据集中已有的图片样本进行多尺度图像增强操作,再根据标注的车道线位置信息和图像生成训练样本;(2)根据生成的图像构建适用的卷积神经网络;(3)利用生成的车道线图像进行训练;(4)对该卷积神经网络的性能进行评估;(5)使用训练好的模型进行车道线检测。该方法的优势是结合深度学习方法增强了整体模型的鲁棒性,能够在车道线破损、遮挡、阴影情况下有效检测直道及弯道。但是,该方法仍然存在的不足之处是,把车道线检测当作单纯的像素分割任务,其网络结构完全由普通的二维卷积层和激活层构成,既没有捕捉车道线的几何特征也没有考虑车道线的位置信息,这导致该方法在对面一些车道线语义信息不明显甚至缺失的场景的时候,检测性能较差甚至检测不到车道线。
广东工业大学在其申请的专利文献“基于深度学习的车道线检测方法、系统、计算机及存储介质”(申请号:2021112642095申请公布号:CN114022863A,申请公布日:2022.02.08)中提出了一种基于自注意力结构的自动驾驶设备实现机动车车道线检测方法。其实现步骤是:(1)通过交通监控摄像枪拍摄带有车道线的视频,并从视频中截取多张带有车道线的图像生成数据集;(2)对生成的数据集进行预处理,并将预处理后的数据集划分为训练集和测试集;(3)构建双分支的车道线检测模型,两个分支分别设特征提取器和图像分割器;(4)通过训练集训练双分支的车道线检测模型;(5)通过训练好的双分支的车道线检测模型对测试集进行检测。该发明引入了注意力机制能够更加有效地提取图像特征尤其是全局信息,全局信息能够反映一些车道线自身的情况,但是,该方法仍然存在的不足之处是,还是没有考虑车道线与车道线之间的位置信息关系,以至于自动驾驶机动车在行驶过程中面对多条车道线排列较紧密的情况时,会将其识别为一条车道线,进而导致车道线检测技术检测效果不佳的问题。
发明内容
本发明的目的在于针对上述现有技术的不足,提供一种基于几何特征提取和位置信息编码的车道线检测方法,用于解决车道线检测技术检测效果不佳,同时计算量较大以及车道线检测在复杂道路场景中检测准确率较低的问题。
实现本发明目的的技术思路是,本发明首先利用ResNet作为编码器进行初步的特征提取,然后分别构建几何特征提取模块和位置信息编码模块,上下并行处理特征图。几何特征提取模块以条状卷积核的形式,在行间和行内由左至右分别进行注意力操作。条状卷积核契合车道线的几何形状还能降低计算复杂度,而行间内注意力的形式能够有效融合局部和全局信息。由于采用条形卷积核代替传统的方形卷积核,减少了参数量和计算量,缓解了现有技术计算量较大的问题。同时条形卷积核相对于方形卷积核往往横跨整个特征图,在某一方向上具有更大的感受野,能够提供更多的上下文信息,有助于捕获长距离依赖,解决了车道线检测在复杂道路场景中检测准确率较低的不足。本发明构建的位置信息编码模块时将首先生成相对位置向量,然后将位置向量融入到transformer中,形成带位置信息编码的注意力机制。位置向量编码能有效捕捉车道线自身和车道线之间的潜在的位置关系。通过以上两种方式的并行处理,最终进行特征融合,然后进行双分支解码,分别得到实例分支结果和存在分支结果,再进行解码得到车道线检测结果。挖掘捕捉图像中车道线分布的潜在位置信息,直接对位置向量进行编码。由于多车道线紧密的情况一般仅存在于路面的消失点附近,在靠近车身附近的车道线是相对分散的,是由相机拍摄角度所决定的。本发明的位置编码初始是由全局编码矩阵重排列为向量而形成的,也就是说对于同一张图片,相对分散的车道线的位置编码信息也会作用于车道线密集处,而车道线分散处的车道线是便于分类的,这就有助于车道线密集处的车道线分类,克服了现有技术在自动驾驶机动车行驶过程中面对多条车道线排列较紧密的情况时,会将其识别为一条车道线的检测效果不佳的缺陷。
本发明的实现步骤如下:
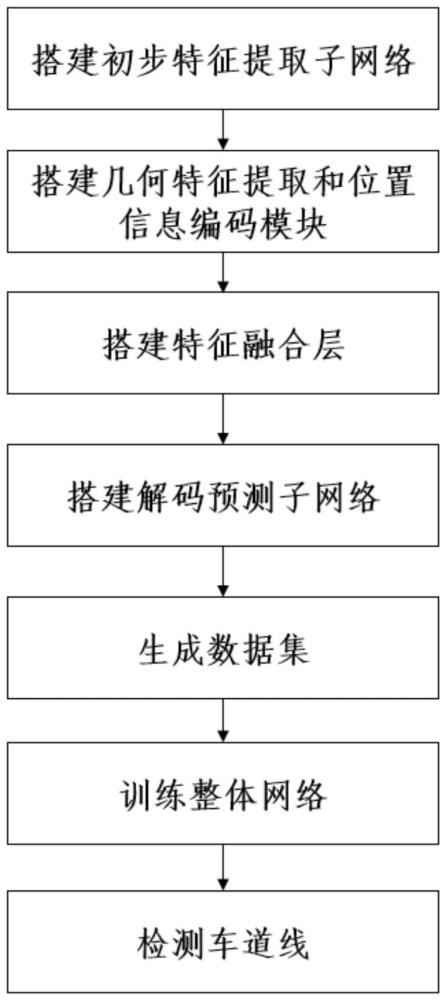
步骤1,构建初步特征提取子网络;
步骤2,构建几何特征提取模块:
搭建由高级特征输入层,行内自注意力子模块,行间自注意力子模块,几何特征输出层依次串联而成的几何特征提取模块;
所述的行内自注意力子模块由两条支路组成,第一条支路由输入层,第1维度重排层,线性层,分割层,自注意力层依次串联组成;第二条支路由矩阵加法层,第2维度重排层,输出层依次串联组成;第二条支路中的矩阵加法层跨接在第一条支路的输入层和自注意力层之间;
所述的行间自注意力子模块由两条支路组成,第1条支路由行间自注意力输入层,卷积层,第1分割层,堆砌层,第1维度重排层,第2分割层,自注意力层依次串联组成,第2条支路由矩阵加法层,第2维度重排层,行间自注意力输出层依次串联组成,矩阵加法层跨接在第1条支路的行间自注意力和自注意力层之间;将卷积层的卷积核大小设置为1×1,步长设置为1,填充设置为0,自注意力层采用标准的自注意力操作;
步骤3,构建位置信息编码模块:
搭建由低级特征输入层,向量编码层,自注意力层,位置信息编码输出层依次串联组成的位置信息编码模块;所述向量编码层由相对位置向量编码层与qkv特征生成层并联组成;位置信息编码模块中的自注意力层将进行多头注意力操作;
所述的相对位置向量编码层由相对位置矩阵生成层,展平层,下标选择层,分割层依次串联组成;
所述的qkv特征生成层由第1维度重排层,卷积层,归一化层,第2维度重排层,分割层依次串联组成;将卷积层的卷积核大小设置为1×1,步长设置为1,填充设置为0;
所述自注意力层由2条支路组成,第1条支路中的第1矩阵加法层分别与第1矩阵乘法层,第2矩阵乘法层,第3矩阵乘法层相连;第2条支路中的softmax层分别与第2矩阵加法层,第4矩阵乘法层,第5矩阵乘法层相连,第2矩阵加法层分别与第4矩阵乘法层,第5矩阵乘法层和相连softmax层以及第1条支路的第1矩阵加法层相连;
步骤4,构建非对称双边注意力网络:
步骤4.1,构建特征融合层;
步骤4.2,搭建由实例分支和存在分支并行组成的解码预测子网络;
步骤4.3,将几何特征提取模块与位置信息编码模块并联组成模块组;
步骤4.4,将初步特征提取子网络,模块组,特征融合层,解码预测子网络级联成非对称双边注意力网络;
步骤5,生成训练集:
选取至少3000张含有车道线的图像组成样本集,每张图像的分辨率均为1280×720,且每张图像中包括0至4条车道线,同时每张图像对应有一张二值分割标签图;对样本集中的每张图像依次进行裁剪,旋转,模糊的预处理;将预处理后的图像组成训练集;
步骤6,训练非对称双边注意力网络:
步骤6.1,设置训练参数:将momentum率设置为0.9,权重衰减率设置为0.0004,初始学习率设置为0.02;
步骤6.2,权重初始化,将ImageNet预训练的ResNet-34的权重作为非对称双边注意力网络的初始权重,采用SGD优化算法,将训练集按批次输入到非对称双边注意力网络中,利用梯度下降法,对网络参数进行迭代更新,直至网络总损失函数收敛为止,得到训练好的网络并保存权重;
步骤7,检测车道线:
采用与步骤5相同的方法,将预处理后待检测的含有车道线的图像依次输入训练好的非对称双边注意力网络,输出车道线检测结果。
本发明与现有技术相比较,具有如下优点:
第一,本发明构建了几何特征提取模块,采用条形卷积核改进自注意力机制,克服了现有技术计算量较大以及车道线检测在复杂道路场景中检测准确率较低的不足,使得本发明能够较好的平衡车道线检测准确率和时效性。
第二,本发明构建了位置信息编码模块,挖掘捕捉图像中车道线分布的潜在位置信息,直接对位置向量进行编码,并嵌入到注意力模块中,克服了现有技术在自动驾驶机动车行驶过程中面对多条车道线排列较紧密的情况时,会将其识别为一条车道线的检测效果不佳的缺陷,使得本发明的自动驾驶机动车在行驶过程中充分利用车道线与车道线之间的位置信息,有效提升了车道线检测的准确性和鲁棒性。
附图说明
图1是本发明的流程图;
图2是本发明的非对称双边注意力网络结构图;
图3是本发明的初步特征提取子网络的结构图;
图4是本发明的几何特征模块结构图;
图5是本发明的几何特征模块中的行内自注意力子模块结构图;
图6是本发明的几何特征模块中的行间自注意力子模块结构图;
图7是本发明的位置信息编码模块结构图;
图8是本发明的位置信息编码模块中的相对位置向量编码层结构图;
图9是本发明的位置信息编码模块中的qkv特征生成层结构图;
图10是本发明的位置信息编码模块中的自注意力层结构图;
图11是本发明的解码预测子网络中的实例分支结构图;
图12是本发明的解码预测子网络中的存在分支结构图。
具体实施方式
下面结合附图和实施例,对本发明作进一步的描述。
参照图1,对本发明实施例的实现步骤作进一步的描述。
本发明实施例的非对称双边注意力网络中包括初步特征提取子网络,几何特征提取模块,位置信息编码模块,解码预测子网络,如图2所示。
步骤1,构建非对称双边注意力网络中的初步特征提取子网络。
搭建由图像输入层,初步特征提取层,输出层组依次串联组成的初步特征提取子网络,所述输出层组由高级特征输出层与低级特征输出层并联组成,如图3所示。
所述输入层为车道线图片的输入。所述初步特征提取层采用ResNet-34用作对输入的车道线图片进行初步的特征提取。初步特征提取后,以ResNet-34的直接输出作为高级特征输出层输出,以ResNet-34的第一层特征图作为低级特征的输出。
步骤2,非对称双边注意力网络中的几何特征提取模块。
构建由高级特征输入层,行内自注意力子模块,行间自注意力子模块,几何特征输出层依次串联而成的几何特征提取模块,如图4所示。
所述的行内自注意力子模块由两条支路组成,第一条支路由输入层,第1维度重排层,线性层,分割层,自注意力层依次串联组成;第二条支路由矩阵加法层,第2维度重排层,输出层依次串联组成;第二条支路中的矩阵加法层跨接在第一条支路的输入层和自注意力层之间,如图5所示。
当尺寸为(B,C,H,W)的特征图X输入到行内自注意力子模块后,先通过第1维度重排层,将X维度重排为(B*H,W,C)后,再通过线性层在通道维度上扩张,得到尺寸为(B*H,W,3C)的特征图,经过分割层将尺寸为(B*H,W,3C)的特征图在通道维度上切割为3份,分别得到3个尺度为(B*H,W,C)的特征图。将这3个特征图分别作为query,key,value输入到自注意力层中,经该层标准的自注意力操作,将操作结果与尺寸为(B,C,H,W)的特征图X通过矩阵加法层进行相加,再经过第2维度重排层使其尺寸变为(B,C,H,W),将该结果作为输出,即行内自注意力子模块的结果。其中,B表示一次操作的特征图的个数,C表示特征图的通道数,H表示特征图的高,W表示特征图的宽,
所述的行间自注意力子模块由两条支路组成,第1条支路由行间自注意力输入层,卷积层,第1分割层,堆砌层,第1维度重排层,第2分割层,自注意力层依次串联组成,第2条支路由矩阵加法层,第2维度重排层,行间自注意力输出层依次串联组成,矩阵加法层跨接在第1条支路的行间自注意力和自注意力层之间,如图6所示。将卷积层的卷积核大小设置为1×1,步长设置为1,填充设置为0,自注意力层采用标准的自注意力操作。
当尺寸为(B,C,H,W)的特征图进入行间自注意力子模块后,经过一层卷积层,卷积核大小1×1,得到尺寸为(B,3C,H,W)的特征图后经过分割层在通道维度上切割为3份,分别得到3个尺度为(B,C,H,W)的特征图;经过堆砌层在第一个维度上堆砌张量得到尺度为(3B,C,H,W)的特征图,进行维度重排得到(3B,H,W*C),按第一个维度切割为3份,尺寸均为(B,H,W*C)。将这3个张量分别作为query,key,value输入到标准的自注意力模块中,将结果与输入层的特征图进行矩阵加法,再经过维度重排层将尺度变为(B,C,H,W),最终得到输出结果,即行间自注意力的结果。
步骤3,构建非对称双边注意力网络中的位置信息编码模块。
搭建由低级特征输入层,向量编码层,自注意力层,位置信息编码输出层依次串联组成的位置信息编码模块。所述向量编码层由相对位置向量编码层与qkv特征生成层并联组成,如图7所示。
位置信息编码模块中的自注意力层将进行多头注意力操作,本发明的实施例中设置多头的注意力的分组数G=8。
所述的相对位置向量编码层由相对位置矩阵生成层,展平层,下标选择层,分割层依次串联组成,如图8所示。
当尺寸为(B,C,H,W)的特征图进入相对位置向量编码层后,先在相对位置矩阵生成层中生成0~79的常数序列,分别在第0维度和第1维度上进行扩张,用后者减去前者(这里利用了张量的广播机制)再加上79,得到相对位置矩阵。通过展平层将其拉伸称为一个向量,得到相对位置序列。在下标选择层中先利用服从标准正态函数的随机函数生成尺寸为(2C/G,80*2-1)的随机数矩阵,以相对位置序列作为下标选取的标准,对该随机数矩阵在第2个维度上进行重排列,得到尺寸为(2C/G,80,80)的张量,最后在第1个维度上分为3份,得到尺寸依次为(C/2G,80,80)、(C/2G,80,80)和(C/G,80,80)的3个位置信息编码向量,记作l
所述的qkv特征生成层由第1维度重排层,卷积层,归一化层,第2维度重排层,分割层依次串联组成,如图9所示。将卷积层的卷积核大小设置为1×1,步长设置为1,填充设置为0;归一化层的归一化操作在第二个维度上进行,输入输出通道一致。
当尺寸为(B,C,H,W)的特征图进入qkv特征生成层后,首先将其维度重排为(B*W,C,H),经过1个卷积层,卷积核大小为1×1,步长为1,填充为0。在第2个维度上进行一次BatchNorm操作,即归一化层,得到尺寸为(B*W,2C,H)的特征图。对该特征图进行维度重排得到尺寸为(B*W,G,2C/G,H)的特征图,再在第3个维度上进行分割,得到3份张量,尺寸分别为(B*W,G,C/2G,H)、(B*W,G,C/2G,H)和(B*W,G,C/G,H),依次记作X
所述自注意力层由2条支路组成,第1条支路中的第1矩阵加法层分别与第1矩阵乘法层,第2矩阵乘法层,第3矩阵乘法层相连。第2条支路中的softmax层分别与第2矩阵加法层,第4矩阵乘法层,第5矩阵乘法层相连,第2矩阵加法层分别与第4矩阵乘法层,第5矩阵乘法层和相连softmax层以及第1条支路的第1矩阵加法层相连,如图10所示。
将相对位置编码层和qkv特征生成层得到结果经过分别经过第1,2,3矩阵乘法层得到X
步骤4,搭建由张量堆砌层和卷积层串联的特征融合层,将卷积层的卷积核大小设置为1×1,步长设置为1,无填充。
步骤5,搭建由实例分支和存在分支并行组成的解码预测子网络。
步骤5.1,实例分支由dropout层、卷积层和上采样层依次串联组成,如图11所示。其中dropout层中dropout的概率为0.1;卷积层的卷积核大小设置为1×1,步长设置为1,填充设置为0;上采样层采用的算法为双线性插值算法。
步骤5.2,存在分支由dropout层、卷积层、softmax层、平均池化层、维度重排层、第1线性层、第1激活层、第2线性层和第2激活层依次串联组成,如图12所示。其中dropout层中dropout的概率为0.1;卷积层的卷积核大小设置为1×1,步长设置为1,填充设置为0;softmax在输入特征图的第2个维度上进行;平均池化层的池化核大小设置为2×2,步长设置为2,填充设置为0;第1激活层采用的激活函数是ReLU函数,第2激活层采用的激活函数是sigmoid函数。
步骤6,构建非对称双边注意力网络。
步骤6.1,将几何特征提取模块与位置信息编码模块并联组成模块组。
步骤6.2,将初步特征提取子网络,模块组,特征融合层,解码预测子网络级联成非对称双边注意力网络。
步骤7,生成训练集。
步骤7.1,本发明的实施例是从Tusimple数据集选取至少3000张含有车道线的图像组成训练集,每张图像的分辨率均为1280×720,且每张图像中包括0至4条车道线,同时每张图像对应有一张二值分割标签图;
步骤7.2,对训练集中的每张图像依次进行裁剪,旋转,模糊的预处理,其中,采用OpenCV中的resize函数,将图像尺寸裁剪为320×800;旋转操作为随机角度旋转,角度均匀分布在[-10°,+10°]之间;模糊操作采用OpenCV中的GaussianBlur函数,模糊核大小为5×5,在水平和竖直方向上的高斯核标准差分别为1.0×10
步骤8,训练非对称双边注意力网络。
步骤8.1,设置训练参数:将momentum率设置为0.9,权重衰减率设置为0.0004。初始学习率设置为0.02。
步骤8.2,权重初始化,将ImageNet预训练的ResNet-34的权重作为非对称双边注意力网络的初始权重,将训练集输入到非对称双边注意力网络中,利用梯度下降法,对网络参数进行迭代更新。采用SGD优化算法,一个batch至少需要送入4张图片,训练200轮并且前1000个batch采用指数型训练热身算法。直至网络总损失函数值下降至稳定值时停止训练,得到训练好的网络并保存权重。
所述网络总损失函数如下:
L=w
其中,L表示非对称双边注意力网络的总损失函数,w
其中,S表示输入到解码预测子网络中存在分支的一张图片中像素点的总数,i表示输入到解码预测子网络中存在分支的一张图片中像素点的序号,y
其中,∑表示求和操作,M表示车道线分类的总数,j表示车道线的序号,p
步骤9,检测车道线。
采用与步骤7相同的方法,将预处理后待检测的含有车道线的图像依次输入训练好的非对称双边注意力网络,输出车道线检测结果。
下面结合仿真实验对本发明的效果做进一步的说明:
1.仿真实验条件:
本发明的仿真实验的硬件平台:显卡为NVIDIA RTX2080Ti x4、显存为11GB x4、处理器为Intel(R)Core(TM)CPUi9-10900X@3.70GHz、内存为32GB。
软件平台是Ubuntu18.04操作系统下的Anaconda的Python 3.6虚拟环境中搭建了包含PyTorch-1.1.0+cu100、Matplotlib-3.3.3重要环境库的代码运行环境。
本发明仿真实验所使用的输入图像为图森未来公司所创建的公开数据集Tusimple,该车道线数据成像时间为2017年,图像大小为1280×720,采集自中等天气条件,不同的时间,不同的交通状况,图像格式为PNG。本仿真实验选取Tusimple数据集中除开训练集以外的图片至少2000张作为测试集,并按照步骤7.2的方法进行预处理。
2.仿真内容及其结果分析:
本发明仿真实验是采用本发明和三个现有技术(LaneAF,LSTR,LaneATT)分别对输入的图森数据集Tusimple车道线图像进行检测,获得检测准确度结果。
在仿真实验中,采用的三个现有技术是指:
现有技术LaneNet是指Abualsaud,Hala等人在“Laneaf:Robust multi-lanedetection with affinity fields.IEEE Robotics and Automation Letters 6.4(2021):7477-7484.”中提出的一种车道线检测方法,简称为LaneAF。
现有技术LSTR是指Liu,Ruijin等人在“End-to-end lane shape predictionwith transformers.Proceedings of the IEEE/CVF winter conference onapplications of computer vision.2021.”中提出的一种车道线检测方法,简称LSTR。
现有技术LaneATT是指Tabelini,Lucas等人在“Keep your eyes on the lane:Real-time attention-guided lane detection.Proceedings of the IEEE/CVFconference on computer vision and pattern recognition.2021.”中提出的一种车道线检测方法,简称LaneATT。
利用三个评价指标(准确度Accuracy、误报率FP、误检率FN)分别对四种方法的检测准确度结果进行评价。利用下面公式,计算准确度Accuracy、误报率FP、误检率FN,将所有计算结果绘制成表1:
其中,Accuracy表示车道线检测的准确率,N表示测试集中所有的图片数量,i表示图片的序号,C
其中,FP表示误报率,F
其中,FN表示误检率,M
将所生成的测试图像输入到训练好的车道线特征提取网络中对车道线进行检测,本发明中车道线检测的准确率为96.76%。
表1.仿真实验中本发明和各现有技术分类结果的定量分析对比表
由表1可以看出本发明的准确率、FN和FP均优于现有三种方法,说明本发明性能上的优越性,证明本发明提出的几何特征提取模块和位置信息编码模块是有效的。
以上仿真实验表明:不同于以往的方法仅利用车道线的语义特征,本发明所提出的几何特征提取模块和位置信息编码模块能够有效地利用车道线的几何特性和位置信息,跳出了语义分割检测车道线的思维限制,特化了车道线检测方法从而提升了检测性能,同时在模块中用部分条形卷积核代替方形卷积核,在一定程度上降低了计算量,便于实际应用。因此,本发明是一种兼顾性能和速度的基于深度学习的车道线检测方法。
- 一种基于三阶段特征提取的车道线检测方法
- 一种基于ORB特征提取的车道线检测方法