用于通信和广播系统的速率匹配的方法和装置
文献发布时间:2024-01-17 01:27:33
本申请为申请日为2018年6月18日、申请号为201880041164.5、发明名称为“用于通信和广播系统的速率匹配的方法和装置”的中国发明专利的分案申请。
技术领域
本公开涉及纠错码,用于当由于各种原因(诸如在发送或存储数据的过程中的噪声或干扰)而发生或可能发生错误或丢失时,纠正或恢复该错误或丢失。更具体地,本公开涉及用于极化码(polar code)的速率匹配的方法、实施方式和装置。本公开可用于各种领域,并且可以有效地用于移动通信系统(诸如全球移动通信系统(GSM)、宽带码分多址(WCDMA)、长期演进(LTE)和第五代新无线电接入技术(5G-NR))所使用的极化码的速率匹配。
背景技术
为了满足自从部署第四代(4G)通信系统以来增长的无线数据业务(traffic)的需求,已经在努力开发改进的5G或预5G(pre-5G)通信系统。因此,5G或前5G通信系统也被称为“超(beyond)4G网络”或“后(post)LTE系统”。
5G通信系统被认为是在更高频(毫米波)频带(例如,60GHz频带)中实施的,以便实现更高的数据速率。为了降低无线电波的传播损耗以及增加传输距离,在5G通信系统中探讨了波束成形、大规模多输入多输出(multiple-input multiple-output,MIMO)、全尺寸MIMO(FD-MIMO)、阵列天线、模拟波束成形、大规模天线技术。
此外,在5G通信系统中,基于高级小小区、云无线电接入网络(radio accessnetwork,RAN)、超密集网络、设备对设备(device-to-device,D2D)通信、无线回程、移动网络、协作通信、协调多点(coordinated multi-points,CoMP)、接收端干扰消除等,系统网络改进的开发正在进行中。
在5G系统中,已经开发了作为高级编码调制(advanced coding modulation,ACM)的混合频移键控(frequency shift keying,FSK)和正交幅度调制(quadrature amplitudemodulation,QAM)调制(FSK and QAM modulation,FQAM)、和滑动窗口叠加编码(slidingwindow superposition coding,SWSC),以及作为高级接入技术的滤波器组多载波(filterbank multi carrier,FBMC)、非正交多址接入(non-orthogonal multiple access,NOMA)和稀疏码多址接入(sparse code multiple access,SCMA)。
因特网是以人为中心的人类在其中生成和消耗信息的连接网络,因特网现在正在演变为物联网(Internet of things,IoT),在物联网中,诸如事物的分布式实体在没有人类干预的情况下交换和处理信息。万物互联网(Internet of everything,IoE)已经出现,它是IoT技术和大数据处理技术通过与云服务器连接的结合。由于IoT实施方式需要诸如“传感技术”、“有线/无线通信和网络基础设施”、“服务接口技术”和“安全技术”等的技术元素,最近已经研究了传感器网络、机器对机器(machine-to-machine,M2M)通信、机器类型通信(machine type communication,MTC)等。这样的IoT环境可以提供智能因特网技术服务,该智能因特网技术服务通过收集和分析所连接的事物当中生成的数据,为人类生活创造新的价值。IoT可以通过现有信息技术(information technology,IT)和各种工业应用之间的融合和结合,应用于各种领域,包括智能家居、智能建筑、智能城市、智能汽车或联网汽车、智能电网、医疗保健、智能电器和高级医疗服务。
与此一致,已经进行了各种尝试来将5G通信系统应用于IoT网络。例如,诸如传感器网络、机器类型通信(MTC)和机器对机器(M2M)通信的技术可以通过波束成形、MIMO和阵列天线来实施。作为上述大数据处理技术的云无线电接入网络(RAN)的应用也可以被认为是5G技术和IoT技术之间融合的示例。
通常,当在通信系统中的发送器和接收器之间发送或接收数据时,由于通信信道中存在的噪声,可能会发生数据错误。纠错编码方案是被设计用于在接收器处纠正通信信道生成的错误的编码方案。这些纠错码也被称为信道编码。纠错编码技术是将冗余比特添加到要发送的数据中,然后发送该数据的技术。
纠错编码技术有各种方案。例如,在本领域中已知的卷积编码方案、turbo编码方案、低密度奇偶校验(low-density parity-check,LDPC)编码方案和极化码方案。其中,极化码是第一种在理论上被证明通过使用信道极化现象来实现点对点信道容量的码。极化码允许利用密度演化、高斯近似(Gaussian approximation,GA)、互易信道近似(reciprocalchannel approximation,RCA)等为每个信道或码率优化的码设计。
同时,最近被提议为下一代移动通信系统的5G移动通信技术主要涉及以下三种场景:增强型移动宽带(enhanced mobile broadband,eMBB)场景、超可靠低延迟通信(ultra-reliable and low latency communication,URLLC)场景和大规模MTC(massive MTC,mMTC)场景。用于支持这样的场景的纠错码也应该支持各种具有稳定性能的码率。
然而,到目前为止,在不增加存储器的复杂性的情况下满足上述所有场景的方案还不可用。因此,有必要提供这样的编码方案。
上述信息仅作为背景信息呈现,以帮助理解本公开。对于任何上述内容是否可以应用为本公开的现有技术,尚未做出确定,也未做出断言。
发明内容
技术问题
本公开的各方面是至少解决上述问题和/或缺点,并且至少提供下面描述的优点。因此,本公开的一方面是提供一种在极化码的编码和解码系统中具有稳定性能的速率匹配操作。特别地,当根据以适当次序交织编码后的比特、将所得比特序列存储在循环缓冲器中、然后从缓冲器中提取比特的方法来执行速率匹配时,本公开的各种实施例在长期演进(LTE)或第五代新无线电接入技术(5G-NR)通信系统中实现了优异的性能。此外,本公开的各种实施例在由于通过以上操作的速率匹配而发生打孔、缩短和重复的所有情况下都实现了优异的性能。
附加的各个方面部分将在下面的描述中阐述,并且部分将根据描述变得明显,或者可以通过所呈现的实施例的实践来了解。
问题的解决方案
根据本公开的一方面,提供了一种由通信系统中的发送器执行的方法,所述方法包括:识别要被编码的第一比特序列,所述第一比特序列包括信息比特序列和所述信息比特序列的循环冗余校验CRC比特;通过用极化码对第一比特序列进行编码来识别第二比特序列;通过基于交织模式对第二比特序列执行交织来识别第三比特序列;通过基于第一比特序列的长度、第二比特序列的长度和速率匹配输出序列的长度将重复或打孔或缩短之一确定为速率匹配,对所述第三比特序列执行所述速率匹配;以及通过执行所述速率匹配来获得所述速率匹配输出序列,其中,所述交织模式对应于{0,1,2,4,3,5,6,7,8,16,9,17,10,18,11,19,12,20,13,21,14,22,15,23,24,25,26,28,27,29,30,31}。
根据本公开的一方面,提供了一种通信系统中的装置,所述装置包括:收发器;和控制器,与所述收发器耦合,并且被配置为:识别要被编码的第一比特序列,所述第一比特序列包括信息比特序列和所述信息比特序列的循环冗余校验CRC比特,通过用极化码对第一比特序列进行编码来识别第二比特序列,通过基于交织模式对第二比特序列执行交织来识别第三比特序列,通过基于第一比特序列的长度、第二比特序列的长度和速率匹配输出序列的长度将重复或打孔或缩短之一确定为速率匹配,对所述第三比特序列执行所述速率匹配,以及通过执行所述速率匹配来获得所述速率匹配输出序列,其中,所述交织模式对应于{0,1,2,4,3,5,6,7,8,16,9,17,10,18,11,19,12,20,13,21,14,22,15,23,24,25,26,28,27,29,30,31}。
根据本公开的一方面,提供了一种在装置处使用极化码发送信息的方法。该方法包括识别第一比特序列,识别通过用极化码编码第一比特序列而生成的第二比特序列,将第二比特序列划分为预定数量的子块,以及基于根据第一模式交织划分后的子块的结果来识别第三比特序列。
根据本公开的另一方面,提供了一种使用极化码发送信息的装置。该装置包括收发器和与该收发器相关联的至少一个处理器。该至少一个处理器被配置为识别第一比特序列,识别通过用极化码编码第一比特序列而生成的第二比特序列,将第二比特序列划分为预定数量的子块,以及基于根据第一模式交织所划分的子块的结果来识别第三比特序列。
根据本公开的另一方面,提供了一种用于在装置处使用极化码接收信息的方法。该方法包括接收至少一个比特序列并基于所接收的至少一个比特序列来识别信息比特,通过用极化码编码第一比特序列来生成第二比特序列,将第二比特序列划分为预定数量的子块,基于根据第一模式交织所划分的子块的结果来识别第三比特序列,以及基于第三比特序列生成所接收的至少一个比特序列。
根据本公开的另一方面,提供了一种用于使用极化码接收信息的装置。该装置包括收发器和与收发器相关联的至少一个处理器。该至少一个处理器被配置为接收至少一个比特序列,基于所接收的至少一个比特序列识别信息比特,通过用极坐标码编码第一比特序列来生成第二比特序列,将第二比特序列划分成预定数量的子块,基于根据第一模式交织所划分的子块的结果来识别第三比特序列,以及基于第三比特序列来生成所接收的至少一个比特序列。
本发明的有益效果
根据本公开的各种实施例,包括选择母码(mother code)、选择打孔、缩短或重复技术、配置交织器、以及操作循环缓冲器的极化码速率匹配方法可以在使用极化码的通信和广播系统中实现优异且稳定的性能。此外,根据本公开的各种实施例,极化码速率匹配方法可以通过使用统一交织器和循环缓冲器操作来简化系统操作,而不管是打孔、缩短或重复。
根据以下结合附图公开了本公开的各种实施例的详细描述,本公开的其他方面、优点和显著特征对于本领域技术人员而言将变得明显。
附图说明
根据以下结合附图的描述,本公开的某些实施例的上述和其他方面、特征和优点将变得更加明显,其中:
图1是示出根据本公开实施例的极化编码和速率匹配的过程的框图;
图2是示出根据本公开实施例的极化编码和速率匹配的过程的流程图;
图3是示出根据本公开实施例的确定极化码的母码大小的过程的图;
图4是示出根据本公开的实施例的用于为极化码速率匹配选择打孔、缩短和重复之一的过程和标准的图;
图5是示出根据本公开实施例的基于按照大小为8的小极化码序列的次序的子块置换(permutation)的交织器操作的图;
图6是示出根据本公开实施例的基于按照大小为16的小极化码序列的次序的子块置换的交织器操作的图;
图7是示出根据本公开实施例的将通过执行基于子块置换的交织器操作获得的比特序列存储在缓冲器中并从缓冲器加载比特的过程的图;
图8是示出根据本公开第一实施例的在基于块置换的交织器操作之后提取存储在循环缓冲器中的比特的次序的图;
图9是示出根据本公开第一实施例的当打孔发生于用于在基于块置换的交织器操作之后提取比特的速率匹配操作时,在编码过程中确定强制冻结子信道的过程的图;
图10是示出根据本公开第一实施例的当缩短发生于用于在基于块置换的交织器操作之后提取比特的速率匹配操作时,在编码过程中确定强制冻结子信道的过程的图;
图11是示出根据本公开第二实施例的在基于块置换的交织器操作之后提取存储在循环缓冲器中的比特的次序的图;
图12是示出根据本公开第二实施例的当打孔发生于用于在基于块置换的交织器操作之后提取比特的速率匹配操作时,在编码过程中确定强制冻结子信道的过程的图;
图13是示出根据本公开第三实施例的在基于块置换的交织器操作之后提取存储在循环缓冲器中的比特的次序的图;
图14是示出根据本公开第四实施例的在基于交叉的交织器操作之后提取存储在循环缓冲器中的比特的次序的图;
图15是示出根据本公开第四实施例的当打孔发生于用于在基于块置换的交织器操作之后提取比特的速率匹配操作时,在编码过程中确定强制冻结子信道的过程的图;
图16是示出根据本公开实施例的确定图2中描述的交织的详细过程的流程图;
图17是示出根据本公开实施例的基于块置换的交织器与子块中的子信道分配调整操作或置换操作一起使用的情况下的过程的流程图;
图18是示出根据本公开实施例的发送器装置的框图;和
图19是示出根据本公开实施例的接收器装置的框图。
在所有附图中,应当注意,相同的附图标记用于描绘相同或相似的元件、特征和结构。
具体实施方式
提供以下参考附图的描述是为了帮助全面理解由权利要求及其等同物限定的本公开的各种实施例。它包括有助于理解的各种具体细节,但这些仅仅被认为是示例性的。因此,本领域普通技术人员将认识到,在不脱离本公开的范围和精神的情况下,可以对本文描述的各种实施例进行各种改变和修改。此外,为了清楚和简明,可以省略对众所周知的功能和结构的描述。
在以下描述和权利要求中使用的术语和词语不限于文献意义,而是仅仅由发明人使用以使能够清楚和一致地理解本公开。因此,对于本领域技术人员来说明显的是,提供本公开的各种实施例的以下描述仅仅是为了说明的目的,而不是为了限制由所附权利要求及其等同物限定的本公开的目的。
应当理解,单数形式“一”、“一个”和“该”包括复数指代物,除非上下文另有明确指示。因此,例如,对“部件表面”的引用包括对一个或多个这样的表面的引用。
在各种实施例的以下描述中,省略了对本领域众所周知且与本公开不直接相关的技术的描述。这是为了通过省略任何不必要的解释来清楚地传达本公开的主题。
出于同样的原因,附图中的一些元件被放大、省略或示意性示出。此外,每个元件的大小并不完全反映实际大小。在附图中,相同或相应的元件由相同的附图标记表示。
参考下面详细描述的各种实施例并且参考附图,本公开的优点和特征以及实现它们的方式将变得明显。然而,本公开可以以许多不同的形式来体现,并且不应该被解释为局限于本文阐述的各种实施例。相反,提供这些实施例以使得本公开是彻底和完整的,并将本公开的范围完全传达给本领域技术人员。为了向本领域技术人员完全公开本公开的范围,本公开仅由权利要求的范围限定。
应当理解,流程图图示中的每个块以及流程图图示中的块的组合可以通过计算机程序指令来实施。这些计算机程序指令可以被提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,以产生机器,使得经由计算机或其他可编程数据处理装置的处理器执行的指令生成用于实施流程图块或多个流程图块中指定的功能的装置。这些计算机程序指令也可以存储在计算机可用或计算机可读存储器中,其可以引导计算机或其他可编程数据处理装置以特定方式运行,以使得存储在计算机可用或计算机可读存储器中的指令产生包括实施流程图块或多个流程图块中指定的功能的指令装置的制品。计算机程序指令也可以被加载到计算机或其他可编程数据处理装置上,使得在计算机或其他可编程装置上执行一系列操作,从而产生计算机实施过程,使得在计算机或其他可编程装置上执行的指令提供用于实施流程图块或多个流程图块中指定的功能的操作。
此外,流程图图示的每个块可以表示代码的模块、段或部分,其包括用于实施指定(多个)逻辑功能的一个或多个可执行指令。还应当注意,在一些替代实施方式中,块中标注的功能可能无序发生。例如,取决于所涉及的功能性,连续示出的两个块可能实际上是基本上同时执行,或者这些块有时可能以相反的次序执行。
本文使用的术语“单元”可以指代执行某些任务的软件或硬件组件或设备,诸如现场可编程门阵列(field programmable gate array,FPGA)或专用集成电路(applicationspecific integrated circuit,ASIC)。单元可以被配置为驻留在可寻址存储介质上,并且被配置为在一个或多个处理器上执行。因此,作为示例,模块或单元可以包括组件,诸如软件组件、面向对象的软件组件、类组件和任务组件、进程、功能、属性、过程、子程序、程序代码段、驱动程序、固件、微码、电路系统、数据、数据库、数据结构、表、数组和变量。组件和单元中提供的功能性可以组合成更少的组件和单元,或者进一步分离成附加的组件和模块。此外,组件和单元可以被实施为操作设备或安全多媒体卡中的一个或多个中央处理单元(central processing units,CPU)。
现在,将参考附图详细描述本公开的各种实施例。
极化码是E.Arikan在2008年提出的纠错码,并且是第一种被证明在所有二进制离散无记忆信道(binary discrete memoryless channels,B-DMC)中实现信道容量(即,数据传输极限)同时具有低编码/复杂度性能的码。与诸如turbo码和低密度奇偶校验(low-density parity-check,LDPC)码的其它信道容量逼近码相比,当发送短长度码时,极化码在纠错性能和解码复杂度方面具有优势。因此,在2017年,极化码已被确定用于第五代(5G)移动通信的第三代合作伙伴项目(3rd generation partnership project,3GPP)NR标准化中的短长度控制信息的传输。
图1示出了根据本公开实施例的极化码的编码过程。
参考图1,公开了一种极化编码方法。
在该实施例中,在编码过程中要发送的信息比特的数量是K,并且编码后通过信道发送的码字比特的数量是M。此外,极化码的母极化码比特的数量是N。
1)信息比特生成
给定要发送的信息比特序列b={b
2)外码
在操作110处,信息比特序列b被编码成用于性能增强的外码。所使用的外码是诸如循环冗余校验(cyclic redundancy check,CRC)码的检错码、或者诸如Bose-Chaudhuri-Hocquenghem(BCH)码的纠错码、或单奇偶校验码。由外码生成的奇偶校验(parity)的长度由K
3)子信道分配
在操作120处,对于极化编码,比特序列b'被映射到长度为N的比特序列u={u
A.首先,确定在编码之后不能通过打孔或缩短来携带信息的子信道的位置。也就是说,在比特序列u的比特当中确定外部编码比特没有通过打孔或缩短映射到的比特的索引。极化码的打孔是指不发送通过发送器编码生成的母码比特序列的一部分。因为码字比特即使生成也不被发送,所以接收器不能知道关于码字比特的概率信息,因此可以将接收值或对数似然比(log-likelihood ratio,LLR)值设置为零。此外,极化码的缩短是指将编码器输入比特序列的一部分固定为零,以使得通过编码生成的码字比特的一部分变为零。发送器不发送根据编码结果总是变为零的码字比特。因为知道码字比特即使没有被接收也具有零值,所以接收器将该比特的接收值或LLR值设置为指示零比特值的非常大的值。在这种缩短过程中,在编码输入端被缩短的比特和在输出端相应的比特不需要具有零比特值,并且可以使用满足极化码的编码等式的任何值。然而,为了实施方便,这通常被固定为零。如果在编码之后被打孔或缩短的比特的数量用N
B.输入比特序列b'的各个比特被映射到u的剩余比特。b'的比特将被映射到的、序列u中的比特位置由序列u的每个比特将穿过的子信道的信道容量来确定。也就是说,b'被映射为在序列u的子信道当中具有最大信道容量的子信道上发送。用于此的是其中序列u的子信道索引按照信道容量的次序排列的序列。这被称为极化码序列。极化码序列可以存储在发送器/接收器存储器中,或者通过每次发射/接收处的特定操作来获得。
C.序列u的最终剩余的比特被称为冻结(frozen)比特。尽管作为上述操作的结果,可以发送信息,但是穿过具有低信道容量的子信道的序列u的比特变成冻结比特。冻结比特被设置为发送器和接收器承诺的值,如果没有特定目的,通常被固定为零。
4)生成器矩阵乘法
在操作130处,将长度为N的比特序列u乘以极化码的NxN生成器矩阵G,以生成长度为N的比特序列x。比特序列x被称为极化码的母码。当Arikan提出极化码时,生成器矩阵G定义如下。
在上式中,
在下文中,除非另有说明,假设生成器矩阵被定义为
5)交织和速率匹配
在操作140处,通过生成器矩阵乘法生成的长度为N的比特序列x被交织,以用于高效的速率匹配。在操作150处,交织后的比特序列被存储在大小为N的缓冲器中。在诸如长期演进(LTE)或5G-NR的移动通信系统中,通常假设虚拟循环缓冲器。交织后的比特序列被顺序存储在虚拟循环缓冲器中,并且从中顺序加载和发送M个比特。如果M小于N,则可以按照存储在虚拟循环缓冲器中的相反次序打孔N-M个比特,或者按照存储的次序缩短N-M个比特。如果M大于N,则按照存储在虚拟循环缓冲器中的次序重复M-N个比特。交织器应该设计成即使在打孔、缩短和重复(repetition)的情况下也能获得稳定的性能。
用于速率匹配的交织器应该适当设计,以符合极化码的特性。一些码字比特可以因速率匹配而被打孔、缩短或重复,因此在极化码的解码器处x向量的比特所经历的信道中发生变化。在打孔的情况下,对应的比特不被发送,因此这种比特可以被视为经历了非常降级的信道。在缩短的情况下,对应的比特的值是精确已知的,因此这种比特可以被视为经历了非常好的信道。在重复的情况下,通过两次或更多次接收关于对应比特的概率信息来执行软合并,因此与未重复的比特相比,这种比特可以被视为经历了相对好的信道。因为x向量的比特所经历的信道的这样的变化显著影响极化码的性能,所以有必要适当地选择打孔、缩短和重复比特的位置。比特交织器执行这种功能。
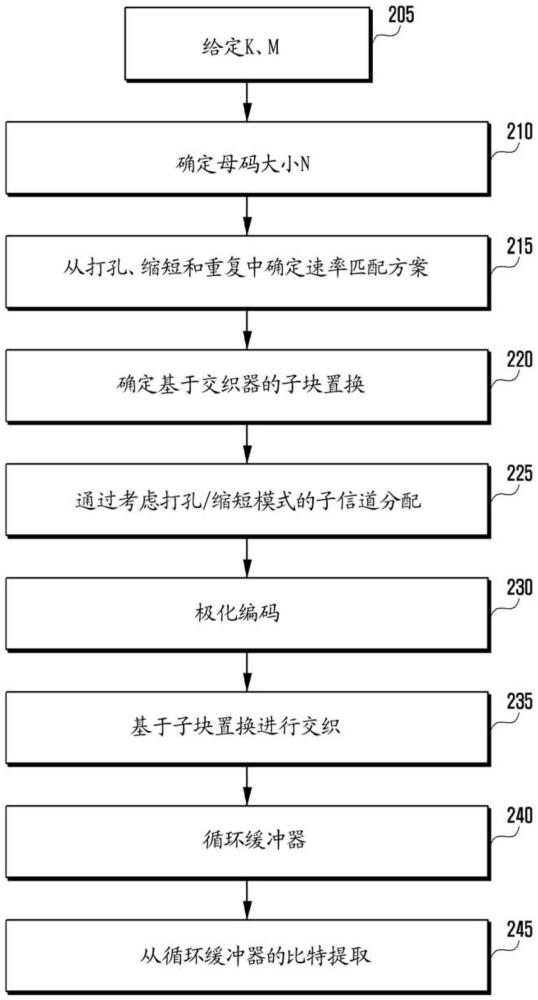
图2概念性地示出了根据本公开实施例的考虑到速率匹配的发送器的操作。类似地,尽管未示出,但是考虑到速率匹配,接收器可以执行相应的操作来配置解码器。
参考图2,公开了根据本公开实施例的考虑到速率匹配的发送器的操作。
首先,在操作205处,给定要发送的比特的长度K和要通过信道发送的码字比特的长度M。
在操作210处,发送器确定要用于极化编码的母码的大小N。
在操作215处,基于以上参数N、K和M以及预定准则,发送器确定将执行打孔、缩短和重复中的哪个速率匹配操作。
如果确定执行打孔或缩短操作,如上所述,发送器在操作220处确定不能从子信道当中被选择用于信息传输的子信道。此时,考虑到随后要执行的交织和速率匹配操作,确定不能被选择的子信道。具体地,在实施例中,考虑到打孔或缩短操作,可以将所有比特分成子块,并且这可以考虑到交织操作来执行。
在操作225处,发送器对要发送的信息比特执行子信道分配。
在操作230处,发送器执行极化编码。
在操作235处,基于预定方案,发送器交织作为编码结果获得的比特序列。
在操作240处,发送器将交织后的比特序列存储在缓冲器中。
在操作245处,发送器从该缓冲器加载要通过信道发送的M个比特。此后,在执行信道交织、调制等之后,这些比特通过该信道发送。在下文中,将分别描述这些操作。
图3示出了根据本公开实施例的从给定参数K和M获得极化码的母码大小N的过程。
参考图3,示出了基于给定参数K和M确定母码大小N的方法。
在操作305处,给定要发送的比特的长度K和要通过信道发送的码字比特的长度M。
在操作310处,计算N
在操作315处,基于上述计算的值,将关于K和M的、要用于编码和解码的极化码的母码大小N确定为N
图4示出了根据本公开的实施例基于上述参数K和M以及通过上述过程获得的母码大小N,确定将执行打孔、缩短和重复操作当中的哪个操作的过程。
参考图4,基于K、M和N,可以确定将使用打孔、缩短和重复当中的哪一个操作来发送数据。
在操作405处,给定要发送的比特的长度K和要通过信道发送的码字比特的长度M。
在操作410处,可以确定M是否大于N。
如果M大于N,则在操作415处确定在编码之后重复M-N个比特。在这种情况下,因为通过编码生成的所有比特都被发送,所以没有通过打孔强制冻结的子信道。因此,可以省略相关的计算过程。
另一方面,如果M小于M,则将执行打孔或缩短操作。
在操作420处,可以确定码率K/M是否等于或低于预定参考码率R
如果码率K/M等于或低于预定参考码率R
如果码率K/M大于预定参考码率R
如上所述,如果M小于N,则可以基于码率来确定是执行缩短还是打孔。
图5和图6是示出根据本公开实施例的用于速率匹配的基于子块置换的交织器操作的图。
参考图5和图6,示出了根据本公开各种实施例的用于速率匹配的基于子块置换的交织器操作。
通过在操作505处用具有大小为N的母码的极化码编码获得的x向量在操作510处被划分成T个子块,然后基于该子块执行交织。本文中,T是2的幂,其小于N,并且是相对小的值。通常,T被确定为8、16或32,并且可以被设置为更大的值。因此,每个子块包含N/T比特。各个子块按照预定次序(即交织器模式)P
Q
Q
Q
22,25,26,28,15,23,27,29,30,31}...等式5
在操作510处,通过使用被确定为P
通过在操作605处用具有大小为N的母码的极化码编码而获得的x向量在操作610处被划分成T个子块,然后基于子块执行交织。具体地,在操作610处,通过使用被确定为P
在各种实施例中,指示交织器模式的P
图7示出了根据本公开实施例的基于P
参考图7,公开了其中考虑到速率匹配,对极化编码后的比特进行交织,然后将其存储在缓冲器中的实施例的技术特征。尽管为了简单起见,假设以基于P
通过在操作705处用具有大小为N的母码的极化码编码而获得的x向量在操作710处被划分成T个子块,然后基于子块执行交织。在操作715处,以子块为单位被交织的比特序列被存储在缓冲器中,然后从缓冲器加载M个比特,并将其传送到诸如信道交织器或调制器的过程。在本公开的各种实施例中,如图7所示,考虑了通用通信系统中使用的循环缓冲器的操作。以下实施例涉及循环缓冲器关于重复、打孔和缩短的操作。
图8是示出根据本公开第一实施例的在基于块置换的交织器操作之后提取存储在循环缓冲器中的比特的次序的图。
参考图8,示出了从循环缓冲器加载和提取交织后的比特序列的方法。
通过在操作805处用具有大小为N的母码的极化码编码获得的x向量在操作810处被划分成T个子块,然后基于子块执行交织。在操作815处,存储在循环缓冲器中的比特可以被顺序加载,而不管打孔、缩短和重复操作。也就是说,首先,顺序加载第0子块中的比特,然后顺序加载第一子块中的比特。这样的比特不以子块为单位加载。因此,在打孔或缩短的情况下,存储在缓冲器后面部分的N-M个比特被打孔或缩短。并且,在重复的情况下,存储在缓冲器的前面部分中的M-N个比特被重复。
图9是示出根据本公开第一实施例的当打孔发生于在基于块置换的交织器操作之后用于提取比特的速率匹配操作时,在编码过程中确定强制冻结子信道的过程的图。
参考图9,示出了用于在编码过程中确定冻结子信道以便执行打孔的方法。
在打孔的情况下,在操作910处,存储在缓冲器后面部分的N-M个比特被打孔。因为存储在缓冲器中的比特通过子块置换进行交织,所以极化码的编码图中的被打孔的比特以交织的相反过程所定义的模式进行交织。在根据第一实施例提取比特的情况下,在操作905处,子信道在编码端按照打孔模式的相反次序被强制冻结。也就是说,如果在操作910处第七子块的后十个比特被打孔,则在操作905处第0子块的前十个比特的子信道被强制冻结。这与打孔模式的二元性(duality)有关,并且如果打孔模式设计良好,则可以按照打孔的相反次序进行强制冻结。编码是通过用发送器和接收器承诺的值(诸如,零)代替强制冻结位置来执行的。
图10是示出根据本公开第一实施例的当缩短发生于在基于块置换的交织器操作之后用于提取比特的速率匹配操作时,在编码过程中确定强制冻结子信道的过程的图。
参考图10,示出了用于在编码过程中确定冻结子信道以便执行缩短的方法。
在缩短的情况下,在操作1010处,存储在缓冲器的后面部分中的N-M个比特被缩短。因为存储在缓冲器中的比特通过子块置换进行交织,所以极化码的编码图中的被缩短的比特以交织的相反过程所定义的模式进行交织。在根据第一实施例提取比特的情况下,在操作1005处,子信道在编码端以与缩短模式相同的次序被强制冻结。编码是通过用发送器和接收器承诺的值来代替强制冻结的位置来执行的。在实施例中,该承诺的值可以是但不限于零。
图11是示出根据本公开的第二实施例在基于块置换的交织器操作之后提取存储在循环缓冲器中的比特的次序的图。
参考图11,示出了从循环缓冲器加载和提取交织比特序列的方法。
通过在操作1105处编码成具有确定的大小为N的母码的极化码而获得的x向量在操作1110处被划分成T个子块,然后基于子块执行交织。在操作1115处,在缩短或重复操作的情况下,存储在循环缓冲器中的比特可以被前向顺序加载,而在打孔操作的情况下,可以反向顺序加载。也就是说,在缩短或重复的情况下,首先顺序加载第0子块中的比特,然后顺序加载第一子块中的比特。另一方面,在打孔的情况下,首先反向加载第七子块中的比特,然后反向加载第六子块中的比特。这样的比特不以子块为单位进行加载。因此,在缩短的情况下,存储在缓冲器后面部分的N-M个比特被缩短。此外,在打孔的情况下,存储在缓冲器的前面部分的N-M个比特被打孔。并且,在重复的情况下,存储在缓冲器的前面部分的M-N个比特被重复。对通过缩短在编码端被强制冻结的子信道的确定遵循图10的上述实施例。
图12是示出根据本公开第二实施例的当打孔发生于在基于块置换的交织器操作之后用于提取比特的速率匹配操作时,在编码过程中确定强制冻结子信道的过程的图。
参考图12,示出了用于在编码过程中确定冻结子信道以便执行打孔的方法。
在打孔的情况下,在操作1210处,存储在缓冲器的前面部分中的N-M个比特被打孔。因为存储在缓冲器中的比特通过子块置换进行交织,所以极化码的编码图中的被打孔的比特以交织的相反过程所定义的模式进行交织。在根据第二实施例提取比特的情况下,在操作1205处,子信道在编码端以打孔模式的相反次序被强制冻结。编码是通过用发送器和接收器承诺的值来代替强制冻结的位置来执行的。
图13是示出根据本公开第三实施例的在基于块置换的交织器操作之后提取存储在循环缓冲器中的比特的次序的图。
参考图13,示出了从循环缓冲器加载和提取交织的比特序列的方法。
通过在操作1305处编码成具有确定的大小为N的母码的极化码而获得的x向量在操作1310处被分成T个子块,然后基于子块执行交织。在操作1315处,在缩短操作的情况下,存储在循环缓冲器中的比特可以前向顺序加载,而在打孔或重复操作的情况下,可以反向顺序加载。也就是说,在缩短的情况下,首先顺序加载第0子块中的比特,然后顺序加载第一子块中的比特。另一方面,在打孔或重复的情况下,首先反向加载第七子块中的比特,然后反向加载第六子块中的比特。这样的比特不以子块为单位加载。因此,在缩短的情况下,存储在缓冲器的后面部分的N-M个比特被缩短。并且,在打孔的情况下,存储在缓冲器的前面部分中的N-M个比特被打孔。并且,在重复的情况下,存储在缓冲器的后面部分中的M-N个比特被重复。对通过打孔在编码端强制冻结的子信道的确定遵循图12的上述实施例,并且对通过缩短在编码端强制冻结的子信道的确定遵循图10的上述实施例。
图14是示出根据本公开第四实施例的在基于交叉的交织器操作之后提取存储在循环缓冲器中的比特的次序的图。
参考图14,示出了在基于交叉的交织器操作之后存储在缓冲器中的比特的次序。
在操作1405处被编码成极化码的输出比特序列在操作1410处在基于交叉的交织器中被划分成四个子块{0,1,2,3}。然后,在操作1415处,子块1和2的比特被交织。对于这样的交织方案,已经使用了如图13所示的从缓冲器中提取比特的方法。在本公开的实施例中考虑的是一种即使在基于交叉的交织器操作之后,不管是打孔、缩短和重复,也能顺序且同等地加载比特的方法。这是一种使用在编码输入处被强制冻结的子信道和在编码输出处被打孔的比特之间的二元关系的传输方法。通过同等地加载比特,可以实现相同的缓冲器管理。
图15是示出根据本公开第四实施例的当打孔发生于在基于块置换的交织器操作之后用于提取比特的速率匹配操作时,在编码过程中确定强制冻结子信道的过程的图。
参考图15,示出了用于在编码过程中确定冻结子信道以执行打孔的方法。如上所述,在该实施例中,强制冻结子信道也以打孔模式的相反次序确定。在打孔的情况下,在操作1510处,存储在缓冲器的前面部分中的N-M个比特可以被打孔,并且在根据第二实施例提取比特的情况下,在操作1505处,子信道在编码端以打孔模式的次序被强制冻结。
同时,在该实施例中,基于块置换的交织器操作中使用的子块的大小和数量可以取决于母码的大小而变化。确定用于各个母码大小的子块的数量的实施例如下。
1)用于在固定子块的大小的同时确定用于各个母码大小的子块的数量的方法:例如,如果在基于块置换的交织器中使用的子块大小被固定为8,则当母码大小为64、128、256、512或1024时使用的子块的数量被确定为8、16、32、64或128。类似地,如果子块的大小是16,则在母码大小是64、128、256、512或1024的情况下,子块的数量被确定为4、8、16、32或64。在其他子块大小的情况下,子块的数量可以以相同的方式确定。这种方法在硬件实施方式中可以是有利的,因为即使母码大小改变,子块的大小也保持不变。
2)用于独立确定用于各个母码大小的子块的数量的方法:考虑每个母码大小的性能和实施方式复杂度,确定子块的最优数量。在这种情况下,当母码大小为256时使用的子块的数量与当母码大小为512时使用的子块的数量无关。子块的数量可以通过对每个母码大小执行优化操作来确定。
3)用于维持用于各个母码大小的子块的数量的方法:即使母码大小变化到64、128、256、512、1024等,交织器中使用的子块的数量也维持一致。
此外,交织器操作中子块的交织次序P
1)用于根据使用的子块的数量来确定P
2)用于根据母码的大小确定P
交织次序P
在该实施例中,偏序是两个整数之间的关系。在两个整数a和b的二进制表示中,1存在于其中的位置集是子集a可以大于或等于b,并且可以基于每个子块索引的二进制表示来确定,如参考上述实施例所述。例如,小的索引可以位于序列的前面。
上述实施例之一如下。以下是简单示例性的(并不限于此),并且每个母码使用的子块的数量和交织次序可以基于上述方法中的至少一种来确定。
1.当母码大小为64时
-子块的数量:4
-P
2.当母码大小为128时
-子块的数量:8
-P
3.当母码大小为256时
-子块的数量:16
-P
4.当母码大小为512时
-子块的数量:32
-P
上述交织次序P
P
这里,P
此外,其长度A
例如,当A为32且A
{8,16,9,17,10,18,11,19,12,20,13,21,14,22,15,23}。
并且,当A为32且A
P
23,24,25,26,28,27,29,30,31}。
作为交织次序P
满足偏序的P
示例1)A=32,A
P
P
P
PT={0,1,2,4,3,5,6,7,8,16,9,17,10,18,11,19,12,20,13,21,14,22,15,23,24,25,26,28,27,29,30,31}
示例2)A=32,A
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
p
P
P
P
P
示例3)A=32,A
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
图16是示出根据本公开实施例的上述发送器操作的一部分的图。
参考图16,示出了确定图2等中描述的交织的详细过程。
基于块置换的交织器操作可以与以下附加操作结合使用。
首先,在操作1605处,给定要发送的比特的长度K和要通过信道发送的码字比特的长度M。
在操作1610处,基于上述参数K和M,发送器确定要用于极化编码的母码的大小N。
在操作1615处,发送器可以根据母码的大小来确定子块的大小。确定子块大小可以使用本公开各种实施例中描述的方法之一。
在操作1620处,发送器可以识别子块的交织模式。此外,执行交织的方法可以包括以下操作之一。
[操作1]可以执行子信道分配调整。具体而言,对于信息比特的传输,通常根据极化码序列来执行子信道分配。子信道分配调整包括考虑速率匹配操作的子信道分配操作。详细地,通过在打孔、缩短或重复的速率匹配操作中反映子信道的互信息(mutualinformation)或错误概率的变化,可以包括调整信息比特被分配到的子信道的次序的操作。这意味着除了由上述速率匹配操作生成的无用子信道之外,还要考虑对剩余子信道的影响。用于简化子信道分配调整的一种方法是基于索引将极化码的所有子信道分成两部分,以及通过考虑打孔、缩短和重复来调整分配给每个部分的信息比特的数量。
[操作2]子块中的比特置换:这意味着除了本公开所考虑的上述块置换操作之外,还对包括在子块中的混合比特进行比特置换操作。当混合子块中的比特时,所有子块可以以相同的模式或不同的模式混合。
图17是示出根据本公开实施例的编码和速率匹配过程的流程图,该编码和速率匹配过程包括如上所述的子信道分配调整操作和子块中的比特置换操作。
参考图17,公开了根据本公开实施例的考虑速率匹配的发送器的操作。
首先,在操作1705处,给定要发送的比特的长度K和要通过信道发送的码字比特的长度M。
在操作1710处,发送器确定要用于极化编码的母码的大小N。
在操作1715处,基于上述参数N、K和M以及预定准则,发送器确定将执行打孔、缩短和重复当中的哪个速率匹配操作。
如果确定执行打孔或缩短操作,发送器在操作1720处确定不能如上所述从子信道当中被选择用于信息传输的子信道。此时,考虑到随后要执行的交织和速率匹配操作,确定不能被选择的子信道。具体地,在一个实施例中,考虑到打孔或缩短操作,可以将所有比特分成子块,并且这可以考虑到交织操作来执行。
在操作1725处,发送器对要发送的信息比特执行子信道分配。
在操作1730处,发送器可以执行子信道分配调整。
在操作1735处,发送器可以执行极化编码。
在操作1740处,基于预定方案,发送器交织作为编码结果获得的比特序列。
在操作1745处,发送器可以交织子块内的比特。
在操作1750处,发送器将交织后的比特序列存储在缓冲器中。
在操作1755处,发送器从该缓冲器加载要通过信道发送的M个比特。此后,在执行信道交织、调制等之后,这些比特通过信道发送。
取决于各种实施例,可以选择性地执行或省略操作1730的子信道分配调整和操作1745的子块内的比特交织。
图18是示出根据本公开实施例的发送器的框图。
参考图18,发送器可以包括收发器1805、控制器1810和储存器1815。在本公开中,控制器1810可以被定义为电路、专用集成电路(application-specific integratedcircuit,ASIC)或至少一个处理器。
收发器1805可以与其他设备发送和接收信号。当发送器在终端中实施时,收发器1805可以例如从基站接收系统信息和同步信号或参考信号,并且还向基站发送比特序列。
根据本公开的各种实施例,控制器1810可以控制发送器的整体操作。例如,控制器1810可以控制各个块之间的信号流,以执行上述操作。具体而言,控制器1810可以控制发送器如以上在各种实施例中所述对信息比特进行编码。
储存器1815可以存储通过收发器1805发送或接收的信息和通过控制器1810生成的信息中的至少一个。
图19是示出根据本公开实施例的接收器的框图。
参考图19,接收器可以包括收发器1905、控制器1910和储存器1915。在本公开中,控制器1910可以被定义为电路、专用集成电路(ASIC)或至少一个处理器。
收发器1905可以与其他设备发送和接收信号。当接收器在终端中实施时,收发器1905可以例如从基站接收编码后的比特序列。
根据本公开的各种实施例,控制器1910可以控制接收器的整体操作。例如,控制器1910可以控制各个块之间的信号流,以执行上述操作。具体而言,控制器1910可以控制接收器如上文在各种实施例中所述解码编码后的信息比特。
储存器1915可以存储通过收发器1905发送或接收的信息和通过控制器1910生成的信息中的至少一个。
根据本公开的实施例,一种基于极化码的用于通信系统的编码和速率匹配方法可以包括以下操作:根据码字比特数和码率,确定要用于编码和解码极化码的母码的大小;当信息比特被分配给子信道时,识别指示子信道优先级的极化码序列;根据码字比特数、码率和所确定的母码大小来确定打孔、缩短和重复操作之一;根据母码大小,确定用于速率匹配的基于块置换的交织器;基于交织器通过打孔/缩短来确定一部分冻结比特的位置;根据所确定的冻结比特模式和极化码序列或极化信道的可靠性来对比特进行编码;通过使用所确定的交织器来交织编码后的比特;以及基于所确定的缩短、打孔和重复操作之一来确定交织后的比特的传输次序。
可以仅考虑母码的大小而不管打孔、缩短和重复操作来确定基于块置换的交织器。此外,基于块置换的交织器可以基于子块的数量和子块的交织次序来确定。交织次序可以是按照具有与子块的数量相同长度的极化码序列的次序来交织子块,或者按照满足偏序的任意次序来交织子块。在缩短的情况下,编码的输入比特当中被强制冻结的比特的模式可以与编码的输出比特当中被缩短的比特的模式相同。在打孔的情况下,编码的输入比特当中强制冻结的比特的模式可以与编码的输出比特当中被打孔的比特的模式相同或具有相反的次序。交织后的比特的传输次序可以取决于打孔、缩短和重复操作而不同地确定,或者不管打孔、缩短和重复操作而同等地确定。
基于块置换的交织器的子块的数量可以在固定子块的大小的同时根据母码的大小来确定,根据每个母码的大小来确定,或者不管母码的大小而确定为常数。在子块置换中,交织次序可以根据子块的数量或母码的大小来确定。基于块置换的交织器可以仅执行子块置换操作,或者与子信道分配调整操作和子块内的比特交织操作中的至少一个一起执行子块置换操作。
虽然已经参考本公开的各种实施例示出和描述了本公开,但是本领域技术人员将理解,在不脱离由所附权利要求及其等同物限定的本公开的精神和范围的情况下,可以在形式和细节上进行各种改变。
- 适用于多个共乘模型的驾驶员-乘车者匹配的系统、方法和装置
- 用于图片匹配定位的神经网络系统,方法及装置
- 用于快速通信的SCADA系统的装置连接的方法以及系统
- 用于通信和广播系统的速率匹配的方法和装置
- 一种速率匹配和解速率匹配方法、装置和通信系统