一种增强词典知识融入的中文命名实体识别方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及自然语言处理技术领域,尤其涉及一种增强词典知识融入的中文命名实体识别方法。
背景技术
命名实体识别(named entity recognition,NER)是自然语言处理(naturallanguage processing,NLP)领域中的一项基础任务,该任务旨在定位句子中的实体并将它们分类为预定义的类别(如人名、地名、组织等)。命名实体识别是信息抽取(informationextraction,IE)任务的第一阶段,并且在信息检索(information retrieval,IR)、智能问答系统(question answering system,QA)以及其它自然语言处理下游任务中发挥重要的作用.在具有天然分隔符的语言中(如英文,其单词以空格符分隔),命名实体识别通常采用序列标注的方式来解决。早期的研究主要采用机器学习的方法,如最大熵模型(maximumentropy model,MEM)、隐马尔可夫模型(hidden markov model,HMM)以及条件随机场(conditional random field,CRF)等。随着深度学习的快速发展,神经网络模型被逐渐应用于命名实体识别任务,如结合长短期记忆(long short-term memory,LSTM)网络和卷积神经(convolutional neural network,CNN)网络模型、基于注意力网络模型。借助于神经网络强大的学习能力,命名实体识别系统的性能得到了进一步的提升。
在中文语言中,句子中的词语之间没有任何的分隔符并且也缺少显式的形态学标记.但是中文语句中的实体就是那些具有特殊意义的词语,因此,缺少词语边界信息这一问题使得中文的命名识别相比于英文命名实体识别是更加困难的.为了使中文命名实体识别模型能够感知词语边界信息,一种常用的方法是首先对中文语句采用分词操作来将其转换为词语序列,之后采用基于词语的序列标注方法来预测每一个词语的实体类别。然而,基于词语的方法会因为分词算法产生的错误而对准确识别实体造成消极的影响,并且分词错误传播也在一定程度上限制了实体标注系统的性能,如图1所示,不同的分词结果会使命名实体识别系统产生不同的实体标注结果,也就是说分词算法的准确与否会直接影响中文命名实体识别系统的性能表现。
为了缓解在基于词语的中文命名实体识别系统中的错误传播问题,一些研究方法开始探索在基于汉字的方法中引入词典信息来解决分词操作产生的问题。基于这一方法,Zhang等人根据中文词典构造了一种词字格作为模型的输入,之后设计了一种新型的格结构长短期记忆网络来处理这一特殊的输入数据。这一方法利用词典中词语的信息辅助基于汉字的中文实体识别模型并且在不同的基准数据集上取得了当时最优的性能。之后,引入词典的方法引起了广泛的关注,一些学者设计了不同的词典融合方法进一步提升了命名实体识别系统的性能。尽管使汉字融合词典知识的方法使中文命名实体识别不再受限于外部操作的结果,但是这种方式由于需要根据汉字在中文词典中的匹配方式将句子中所有潜在的词语全部作为模型的输入,所以对于模型的学习算法提出了非常高的要求。具体来说,一条中文语句中的实体个数是有限的,而与句子匹配的潜在词语是远远多于实体个数的,因此,模型的学习算法需要从所有的潜在词语中选择有用的词语信息并且降低无关词语的影响。现阶段的主流融合词典知识的方式是依据字词之间的匹配关系来选择不同的策略将词语信息融入到汉字表示中,然而,一条中文语句中的一个汉字所能构成的潜在词语可能有多个,而在这些由潜在词语构成的词典中存在与句子语义信息毫不相关的词语,即“歧义”词语。如图2所示,与汉字“市”相关的词语包括“成都市”和“市长”。根据句子的语义信息,词语“成都市”应该被识别为地点实体.因此,词语“市长”对于汉字“市”的标签识别具有干扰作用。如何解决好“歧义”词语问题并且高效地学习有用的词语信息是中文命名实体识别面临的一项困难且具有挑战性的任务。
发明内容
本发明的目的在于提供一种增强词典知识融入的中文命名实体识别方法,解决了使模型更好地利用汉字上下文信息并且保持从词典中高效学习词语信息的能力的问题。
为解决上述技术问题,本发明提供一种增强词典知识融入的中文命名实体识别方法,包括以下步骤:
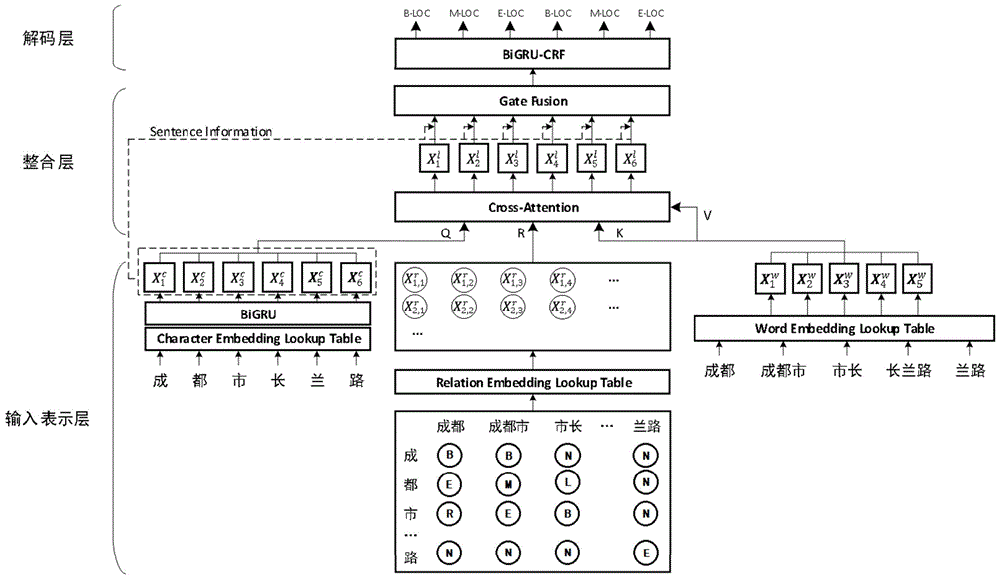
S1、在输入表示层中,首先将汉字、词语以及字词间的关系通过嵌入查找表转换为稠密向量,然后将稠密向量输入到双向门控循环单元中获取汉字的上下文表示;
S2、在整合层中,利用交叉注意力网络获取每一个汉字的词典表示,构造门控网络自适应融合每一个汉字的上下文信息和其词典表示;
S3、在解码层中使用双向门控循环单元结合条件随机场为每一个句子中的汉字分配实体标签。
优选的,步骤S1中,所述汉字、词语以及字词间的关系通过嵌入查找表转换为稠密向量的计算方法分别为:
x
w
c
优选的,所述门控循环单元为:
式中,r
和/>
优选的,步骤S2中,每一个汉字的词典表示采用以下计算公式:
式中,Q
优选的,步骤S2中,所述门控网络为汉字的上下文表示和词典表示分配不同的融合权重,每一个汉字经过门控网络融合后的结果
x
优选的,每一个汉字在整合层的输出
W
优选的,步骤S3中包括以下步骤:
S31、首先将整合层的输出经过双向循环单元处理再输入条件随机场来为预测每一个汉字的实体标签;由前向和后向循环单元的隐藏状态经过连接后的表示
S32、然后使用条件随机场处理上述标签特征,对于输入序列s,标签序列y={y
y’为所有可能的标签序列,
优选的,步骤S32中,使用维特比算法寻找输入序列s的具有最高条件概率的标签序列
与相关技术相比较,本发明具有如下有益效果:
1、本发明利用带有句子语义信息的汉字上下文表示增强模型融入词典知识的能力;
2、本发明通过利用交叉注意力网络和门控融合网络动态地融合每一个汉字的上下文表示和其词典知识表示来增强汉字的表示能力,实验结果说明了在中文命名实体识别任务有巨大优势并且也能够很容易的与BERT等其他自然语言处理的预训练模型相结合来获得更强大的性能。
附图说明
图1为本发明的整体正面立体结构示意图;
图2为本发明的整体各零件爆炸结构示意图;
图3为本发明的组件底板、组件固定板和定位卡台的相互配合结构示意图;
图4为本发明的稳定连接板和定位卡槽的相互配合结构示意图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例;基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
由图1-图4所示,本发明提供一种增强词典知识融入的中文命名实体识别方法,包括以下步骤:
在输入表示层,本发明由句子生成的汉字、词语以及字词关系这些输入数据映射为稠密向量,之后将汉字向量输入到双向门控循环单元中获取汉字的上下文表示。一条输入语句可以被表示为一组连续的汉字构成的序列s=(c
x
其中,e
句子中的所有潜在词语可以表示为{w
w
汉字与词语之间的相关关系是由一张二维表R∈R
表1字词关系表取值详情表
如图4所示,汉字“市”与其他三个词语“市”、“成都市”和“市长”存在组成关系,因此根据汉字“市”在这三个词语中的位置,设置其关系值中分别为“S”、“E”和“B”。此外,汉字“市”与另外两个词语“成都”和“长兰路”存在邻接关系,则关系值分为设置为“R”和“L”。之后,关系表中的每一个元素r
e
利用双向门控循环单元获取汉字的上下文表示,门控循环单元可以表示为:
式中,r
和/>
整合层的具体算法为:
输入:
汉字上下文表示:
词语表示:
字词关系表示:
汉字融合表示:
(1)for i=1 to n do
(2)将
(3)for j=1 to m do
(4)if r
(5)设置
(6)end if
(7)end for
(8)使用softmax函数处理
(9)获得词典表示
(10)end for
(11)连接所有汉字的词典表示
(12)获得句子信息表示x
(13)for i=1 to n do
(14)将x
(15)利用α
(16)end for
(17)连接所有汉字的融合表示
(18)返回x
为使每一个汉字通过其上下文信息自适应地从潜在词语中学习词典知识,交叉注意力网络以汉字的上下文表示、词语表示以及字词关系表示作为输入数据,汉字的词典融合表示作为输出数据,每一个汉字的词典表示采用以下计算公式:
式中,Q
融合更多的词典知识能够使模型更好的感知词语边界信息,或者融合更多的上下文信息使非实体汉字减少与其他汉字的关联程度,所述门控网络为汉字的上下文表示和词典表示分配不同的融合权重,每一个汉字经过门控网络融合后的结果
x
在整合层的输出部分,使用单层全连接神经网络来处理门控网络的输出数据,每一个汉字在整合层的输出
W
在解码层中,首先将整合层的输出经过双向循环单元处理再输入条件随机场来为预测每一个汉字的实体标签;由前向和后向循环单元的隐藏状态经过连接后的表示
然后使用条件随机场处理上述标签特征,对于输入序列s,标签序列y={y
y’为所有可能的标签序列,
步骤S32中,使用维特比算法寻找输入序列s的具有最高条件概率的标签序列
数据对比实验:
本发明在Resume和MSRA两个中文命名实体识别基准数据集进行实验,采用的评价指标分别是准确率(precision,P)、召回率(recall,R)和F1值(F1-score,F1)。实验超参数设置如表2所示:
表2实验超参数设置表
本发明选择以下模型作为基线模型:
(1)Lattice-LSTM:该模型设计了一种基于词字格结构的LSTM网络,通过为词语的结束汉字添加额外的词语单元将整合词典信息整合到汉字表示中;(2)LR-CNN:该模型是一种多层卷积神经网络架构模型,通过反馈高层的特征精炼词语的权重;(3)LGN:该模型使用图神经网络方法来整合词语信息;(4)PLTE:该模型提出了一种格感知的Transformer编码器来捕获词字格中节点的依赖信息;(5)SoftLexicon:该模型根据字词之间的匹配关系将与汉字相关的词语分为4个集合,采用不同的权重来融合4种词语集合的信息;(6)HLEA:该模型将与汉字相关的词语划分为两类,选择不同的融合权重来整合这两类词语信息;(7)LSF-CNER:该模型是一个融合了词汇信息和句法信息的汉字级中文命名实体识别模型;(8)BERT:该模型是一种预训练的语言表示模型,成功地使11个NLP任务取得了极大地提升。
如表3所示,与PLTE相比,本发明在Resume和MSRA数据集上得到的F1值分别提升了0.44%和0.61%。对比其他的序列模型,本发明在Resume数据上取得的F1值分别比SoftLexicon、HLEA和LSF-CNER高了0.35%、0.22%以及0.26%。在MSRA数据集上取得的F1值也分别提升了0.21%、0.28%和0.52%。因此,表3的数据本发明取得了可观的性能提升,在挖掘实体信息方面巨大的优势。
表3模型实验结果对比表
为验证本发明结合高级预训练模型的性能表现,结合BERT的基线模型进行实验对比,得到的实验结果由表4所示:
表4结合BERT的实验结果对比
将BERT模型最后一层输出的汉字隐状态整合到本发明的解码层中,与整合层的输出做连接后再经由解码层处理。对于MSRA数据集,本发明在实验中取得的F1值与PLTE(BERT)和SoftLexicon(BERT)相比分别提升了1.26%和0.37%。对于Resume数据集,本发明相比于SoftLexicon(BERT)提升了0.28%。
为了进一步验证本发明引入的字词关系表示和门控融合模块的性能表现,进行消融实验对比,两组消融实验的设置如下:
(1)-w/o char-word relation:该组消融实验的目的是验证字词关系表示的有效性,基于此,本组消融实验中不会将字词关系表加入交叉注意力网络中;
(2)-w/o gate fusion:该组消融实验是用于验证门控融合模块对模型性能的提升,因此,本组实验删除该模块而采用连接操作。
实验结果如表5所示,
表5消融实验结果
(1)本发明性能的下降证明了这两个部分的有效性;
(2)第一组消融实验中,Resume和MSRA数据集取得的F1值分别比本发明低了0.4%和0.55%,这表明字词关系的引入能够帮助模型更好捕获词典信息;
(3)第二组消融实验中所得到的F1值相比于本发明也分别下降了0.89%和0.09%,这也证明了门控融合模块能够使模型利用汉字之间的关联度来提高模型预测实体的能力。
本发明利用汉字的上下文信息和中文词典信息提高命名实体识别系统的性能。本发明引入了两个重要的模块交叉注意力网络和门控融合网络,用于增强汉字的表示能力。在Resume和MSRA两个中文命名实体识别基准数据集上的实验结果进一步证明了本发明在中文命名实体识别任务有巨大优势并且也能够很容易的与BERT等其他自然语言处理的预训练模型相结合来获得更强大的性能表现。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 基于图网络融入词典的中文命名实体识别方法
- 一种融入词边界信息的中文嵌套命名实体识别方法