一种数据库单表分组扫描方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及数据库技术领域,特别涉及一种数据库单表分组扫描方法。
背景技术
随着大数据时代的到来,存储在数据库中的数据量越来越大,按现有的扫描方式,在表数据达到TB时,至少需要125,000,000个数据页面,假定每个页面存储了20行数据,那么服务器需要顺序迭代125,000,000*20次才能将所有行全部返回,为了能够快速读取数据,通常需要采用并行的方案,但是由于单表数据无法分区获取,只能采用多个Limitoffset的方式进行分批获取,而limit offset在获取后面的数据时,要先按行定位到开始位置需要扫描前面的每个数据页面,产生了大量损耗,影响并行效果。
发明内容
为了解决上述问题,本发明设计了一种数据库单表分组扫描方法,可以对表中数据进行跳跃式的分组访问,为应用并行获取数据库单表数据提供基础支撑。
为实现以上目的,本发明的技术方案为:一种数据库单表分组扫描方法,包括以下步骤:
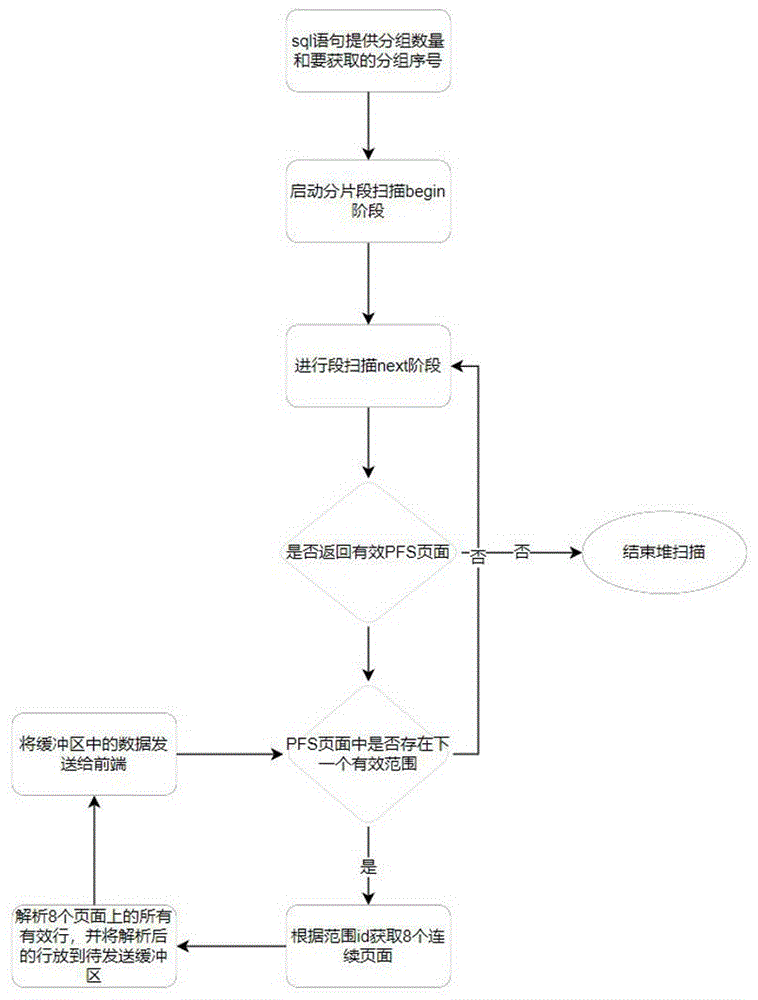
步骤S1:在SQL语句中提供分组数量和当前要获取的分组序号;
步骤S2:启动分组扫描begin阶段,得到当前PI页面;
步骤S3:启动分组扫描next阶段,从分组扫描获取PFS页面;
步骤S4:分组扫描返回有效PFS页面则执行步骤S6,否则执行步骤S5;
步骤S5:分组扫描已经结束,结束堆扫描;
步骤S6:当前PFS页面是否存在下一个有效范围,是则继续,否则继续执行步骤S3;
步骤S7:获取有效范围,解析8个页面上的所有行,并将所有行放到待发送缓冲区;
步骤S8:将缓冲区中的数据发送给前端,并回到步骤S6;
页面(page)是操作系统,数据库存储的最小单位,一个页面为 8 k,每个页面都有唯一的页面号,页面号由文件号以及文件内偏移组成,根据页面号,可以获取指定页面内容,同理获取到页面内容后,也可以获取本页面的页面号,虽然页面固定为8k,但是根据页面用途的不同划分了不同的页面类型,比如存储表中的数据的页面称为数据页面,而管理数据页面的页面是PFS页面,而PI页面可以管理PI页面或者PFS页面,范围(extent)是数据库分配空间的最小单位,一个范围由8个连续的页面组成,段(segment)是逻辑对象的物理载体,每个表对应唯一的段,段由n多个extent组成,堆组织表是一种无序存储数据的多路树结构,树的叶子节点为PFS页面,PFS页面存储200个范围id,也就是1600个数据页面。树的非叶子节点为PI页面,PI页面存储200个子项位置,如果树为一层那么可以管理 200 * 8个数据页面,如果是两层可以管理 200 * 200 * 8 个数据页面(320M)。PFS页面以及PI页面内容中记录了右侧页面的页面号,这样可以方便的查找同一层中的所有页面。数据库中的普通表就是堆组织表,定位到堆的根页面,根据根页面定位到树的最左侧的PFS页面,获取PFS页面中记录的范围,根据范围中记录的页面号获取数据页面并将数据页面返回给堆扫描,通过PFS页面中记录的右侧页面号找到右侧PFS页面,同理可以获取右侧PFS页面中记录的数据页面,直到整个树的最右侧PFS页。此过程为段扫描,段扫描负责收集数据页面,向堆扫描返回数据页面,堆扫描使用段扫描获取一个数据页面,获取数据页面上的有效行,每解析一行后返回给前端,然后继续解析下一行。页面遍历完毕后,继续向段扫描获取下一个数据页面,直到段扫描结束。
优选的:所述SQL语句的语法如下:
DIRECT EXTENT column FROM t GROUP count By n;
其中,DIRECT EXTENT:表示基于EXTENT返回数据,区别于 SELECT 语句,column:表示需要获取的投影列,FROM t:获取t表中的数据,GROUP count: GROUP关键字表示分组,分成count 组,By n:By表示获取第n组,使用PFS页面号与 count取模,如果值等于 n 则说明需要获取该页面,否则不获取本PFS页。
优选的:所述SQL语句语法预期结果为:DIRECT EXTENT column FROM t GROUP 2By 0;
合并上 DIRECT EXTENT column FROM t GROUP 2 By 1;数据结果等于 SELECTCOLUMN from t。
优选的:所述分组扫描begin阶段包括以下步骤:
步骤S21:根据表名字定位到堆根页面,设置根页面为当前页面;
步骤S22:获取当前页面管理的第一个子项页面,判断子项页面类型是否为PFS页面,如果是则执行步骤S24,如果不是则执行步骤S23;
步骤S23:如果不是PFS页面则为PI页面,获取PI页面,并将其设置为当前页面,并跳转到步骤S22;
步骤S24:返回当前页面。
优选的:所述步骤S24中的当前页面是树的倒数第二层。
优选的:分组扫描next阶段包括以下步骤:
步骤S31:获取当前PI页面中记录的下一个PFS页面号;
步骤S32:如果获取成功则执行步骤S35,否则执行步骤S33;
步骤S33:当前PI页面是否存在右侧PI页面,如果存在继续,否则执行步骤S37;
步骤S34:根据页面号,获取右侧PI页面,并将此页面设置成当前页面,到步骤S31;
步骤S35:进行PFS页面号 mod (count) 运算,如果结果等于 n,则继续,否则跳转到步骤S31;
步骤S36:根据PFS页面号获取PFS页面,并将PFS页面返回给堆扫描;
步骤S37:无右侧页面,返回NULL,结束分段扫描。
优选的:DIRECT EXTENT表示基于EXTENT返回数据,区别于 SELECT语句。
优选的:column:表示需要获取的投影列。
优选的:FROM t:获取t表中的数据。
优选的:GROUP count:GROUP关键字表示分组,分成count组,By n:By表示获取第n组,使用PFS页面号与count取模,如果值等于n则说明需要获取该页面,否则不获取本PFS页。
有益效果
1、本发明可以对表中数据进行跳跃式的分组访问,为应用并行获取数据库单表数据提供基础支撑。
2、单表分组扫描方法相对简单直观,易于理解和实现。不需要进行多表关联或连接操作,只需对单个表进行扫描和分组,降低了操作的复杂性,相比于多表连接或关联操作,单表分组扫描通常需要更少的资源和时间。因为只需对单个表进行扫描和聚合操作,减少了数据的传输和处理开销。
3、单表分组扫描方法可以根据具体需求选择合适的分组列,并对数据进行自定义的聚合操作。这种灵活性可以满足不同场景下的分组查询需求,单表分组扫描方法可以使用索引、排序、分区等技术进行优化。通过合理设计索引和使用适当的优化技术,可以提高查询性能和响应时间,单表分组扫描方法适用于各种规模和复杂度的数据表。无论是小型表还是大型表,都可以使用单表分组扫描方法进行数据的分类和聚合。
附图说明
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
图1为本发明的整体流程示意图;
图2为本发明中分组扫描Begin阶段的流程示意图;
图3为本发明中Next阶段的流程示意图;
图4为本发明中假定用户要求分成四组时的PI页面示意图。
具体实施方式
本申请实施例通过提供一种数据库单表分组扫描方法,有效解决了存储在数据库中的数据量越来越大,按现有的扫描方式,在表数据达到TB时,至少需要125,000,000个数据页面,假定每个页面存储了20行数据,那么服务器需要顺序迭代125,000,000*20次才能将所有行全部返回,为了能够快速读取数据,通常需要采用并行的方案,但是由于单表数据无法分区获取,只能采用多个Limit offset的方式进行分批获取,而limit offset在获取后面的数据时,要先按行定位到开始位置需要扫描前面的每个数据页面,产生了大量损耗,影响并行效果的技术问题。
实施例
参见图1,本申请实施例中的技术方案总体思路如下:
针对现有技术中存在的问题,本发明提供一种数据库单表分组扫描方法,包括以下步骤:
步骤S1:在SQL语句中提供分组数量和当前要获取的分组序号;
步骤S2:启动分组扫描begin阶段,得到当前PI页面;
步骤S3:启动分组扫描next阶段,从分组扫描获取PFS页面;
步骤S4:分组扫描返回有效PFS页面则执行步骤S6,否则执行步骤S5;
步骤S5:分组扫描已经结束,结束堆扫描;
步骤S6:当前PFS页面是否存在下一个有效范围,是则继续,否则继续执行步骤S3;
步骤S7:获取有效范围,解析8个页面上的所有行,并将所有行放到待发送缓冲区;
步骤S8:将缓冲区中的数据发送给前端,并回到S6。
页面(page)是操作系统,数据库存储的最小单位,一个页面为 8 k,每个页面都有唯一的页面号,页面号由文件号以及文件内偏移组成,根据页面号,可以获取指定页面内容,同理获取到页面内容后,也可以获取本页面的页面号,虽然页面固定为8k,但是根据页面用途的不同划分了不同的页面类型,比如存储表中的数据的页面称为数据页面,而管理数据页面的页面是PFS页面,而PI页面可以管理PI页面或者PFS页面,范围(extent)是数据库分配空间的最小单位,一个范围由8个连续的页面组成,段(segment)是逻辑对象的物理载体,每个表对应唯一的段,段由n多个extent组成,堆组织表是一种无序存储数据的多路树结构,树的叶子节点为PFS页面,PFS页面存储200个范围id,也就是1600个数据页面。树的非叶子节点为PI页面,PI页面存储200个子项位置,如果树为一层那么可以管理 200 * 8个数据页面,如果是两层可以管理 200 * 200 * 8 个数据页面(320M)。PFS页面以及PI页面内容中记录了右侧页面的页面号,这样可以方便的查找同一层中的所有页面。数据库中的普通表就是堆组织表,定位到堆的根页面,根据根页面定位到树的最左侧的PFS页面,获取PFS页面中记录的范围,根据范围中记录的页面号获取数据页面并将数据页面返回给堆扫描,通过PFS页面中记录的右侧页面号找到右侧PFS页面,同理可以获取右侧PFS页面中记录的数据页面,直到整个树的最右侧PFS页。此过程为段扫描,段扫描负责收集数据页面,向堆扫描返回数据页面,堆扫描使用段扫描获取一个数据页面,获取数据页面上的有效行,每解析一行后返回给前端,然后继续解析下一行。页面遍历完毕后,继续向段扫描获取下一个数据页面,直到段扫描结束。
所述SQL语句的语法如下(大写为关键字,小写为标识符):
DIRECT EXTENT column FROM t GROUP count By n;
其中,DIRECT EXTENT:表示基于EXTENT返回数据,区别于 SELECT 语句,column:表示需要获取的投影列,FROM t:获取t表中的数据,GROUP count: GROUP关键字表示分组,分成count 组,By n:By表示获取第n组,使用PFS页面号与 count取模,如果值等于 n 则说明需要获取该页面,否则不获取本PFS页;
所述SQL语句语法预期结果为:DIRECT EXTENT column FROM t GROUP 2 By 0,合并上 DIRECT EXTENT column FROM t GROUP 2 By 1;数据结果等于 SELECT COLUMN fromt;
在表数据达到TB时,至少需要125,000,000 个数据页面,假定每个页面存储了 20行数据,假定用户从10个客户端分别执行如下10个sql,那么服务器每个sql的处理迭代次数为125,000,000/8/10。
DIRECT EXTENT column FROM t GROUP 10 By 0 ;
DIRECT EXTENT column FROM t GROUP 10 By 1 ;
........
DIRECT EXTENT column FROM t GROUP 10 By 8 ;
DIRECT EXTENT column FROM t GROUP 10 By 9 ;
参见图2,所述分组扫描begin阶段包括以下步骤:
步骤S21:根据表名字定位到堆根页面,设置根页面为当前页面;
步骤S22:获取当前页面管理的第一个子项页面,判断子项页面类型是否为PFS页面,如果是则执行步骤S24,如果不是则执行步骤S23;
步骤S23:如果不是PFS页面则为PI页面,获取PI页面,并将其设置为当前页面,并跳转到步骤S22;
步骤S24:返回当前页面,当前页面是树的倒数第二层。
参见图3,分组扫描next阶段包括以下步骤:
步骤S31:获取当前PI页面中记录的下一个PFS页面号;
步骤S32:如果获取成功则执行步骤S35,否则执行步骤S33;
步骤S33:当前PI页面是否存在右侧PI页面,如果存在继续,否则执行步骤S37;
步骤S34:根据页面号,获取右侧PI页面,并将此页面设置成当前页面,到步骤S31;
步骤S35:进行 (PFS页面号) mod (count) 运算,如果结果等于 n ,则继续,否则跳转到步骤S31;
步骤S36:根据PFS页面号获取PFS页面,并将PFS页面返回给堆扫描;
步骤S37:无右侧页面,返回NULL,结束分段扫描。
DIRECT EXTENT表示基于EXTENT返回数据,区别于 SELECT语句,column表示需要获取的投影列,FROM t获取t表中的数据,GROUP count:GROUP关键字表示分组,分成count组,By n:By表示获取第 n组,使用PFS页面号与count取模,如果值等于n则说明需要获取该页面,否则不获取本PFS页。
如说明书图4,假定用户要求分成四组:
第一组 (group 4 by 0)
第二组 (group 4 by 1)
第三组 (group 4 by 2)
第四组 (group 4 by 3)
每组中负责扫描的PFS进行区分,这样将PFS页面较为平均的分为4组,各组段扫描之间不会重复扫描同一个PFS,也不会漏掉任意一个PFS页面,可以对表中数据进行跳跃式的分组访问,为应用并行获取数据库单表数据提供基础支撑,单表分组扫描方法相对简单直观,易于理解和实现。不需要进行多表关联或连接操作,只需对单个表进行扫描和分组,降低了操作的复杂性,相比于多表连接或关联操作,单表分组扫描通常需要更少的资源和时间。因为只需对单个表进行扫描和聚合操作,减少了数据的传输和处理开销,单表分组扫描方法可以根据具体需求选择合适的分组列,并对数据进行自定义的聚合操作。这种灵活性可以满足不同场景下的分组查询需求,单表分组扫描方法可以使用索引、排序、分区等技术进行优化。通过合理设计索引和使用适当的优化技术,可以提高查询性能和响应时间,单表分组扫描方法适用于各种规模和复杂度的数据表。无论是小型表还是大型表,都可以使用单表分组扫描方法进行数据的分类和聚合。
最后应说明的是:显然,上述实施例仅仅是为清楚地说明本发明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明的保护范围之中。
- 一种RFID单头全向动态扫描系统及快速扫描方法
- 一种基于分组关联表的图数据存取方法和装置
- 一种数据库表扫描方法、装置以及设备
- 一种用于列数据库的单表多列序存储方法