基于HBase的文件检索方法及其系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及计算机系统领域,具体而言,涉及一种基于HBase的文件检索方法及其系统。
背景技术
HBase可用于存储和处理半结构化的数据,且能够将海量数据进行实时的处理,并动态的向用户提供数据的存储及读写服务。但是随着使用的需求越来越多,应用场景日益复杂,用户对查询方式的的要求变得越来复杂。在HBase的设计中只有每行数据的row key作为数据检索的唯一索引,这使得HBase在检索方面有很多的限制,这就要求在设计表结构的时候要根据表的使用场景做额外的考虑,经常会遇到不得不进行全表扫描的查询条件,这对于海量数据的表来说,完全是无法接受的灾难。单一的按row key检索数据的方式,无法再满足更多应用的需求。
随着非结构化数据在近10年内的爆炸式增长,存储组件已经存储了海量的非结构化数据文件。存储组件通过busid实现非结构化数据文件的上传下载功能,非结构化数据文件的文件元数据存储在HBase中,文件本身存储在hadoop集群中,因此如果各业务系统想通过其它结构化数据信息查询时,只能自己搭建一套业务系统,并将busid存储在业务系统中,在搭建的业务系统中通过特定的条件查到对应的busid,再调用存储组件的方法,通过busid下载到对应的非结构化数据文件。但是对于这些来自不同业务系统的非结构化数据文件,仅仅按照业务系统做了区分,带来的后果就是非结构化数据文件在存储端非常的杂乱,难以区分。当业务系统想按照某种条件搜索出对应的非结构化数据文件的时候,比较困难,尤其是搜索不同业务系统的文件,故针对这些难度提出以下解决方案。
发明内容
针对上述背景技术中提出的需求,本发明实施例提供一种基于HBase的文件检索方法及其系统,基于HBase+es的技术方案,利用es的搜索特性能快速且准确的搜索到存储在hadoop集群中的非结构化数据。
一种基于HBase的文件检索方法,具体步骤包括:
步骤一、自定义字段库,具体的将业务系统的数据区分为存量数据和增量数据;
增量数据的自定义字段库包含两部分,一部分是各业务系统自定义的字段库,另一部分是使用算法从非结构文本中抽取出来的字段库;
存量数据的自定义字段库来源于使用算法从非结构文本中抽取出来的字段库;
自定义字段库的意义是后续在es搜索系统中搜索时,可以通过某些条件搜索到对应的非结构化数据文件;
其中增量数据中各业务系统自定义的字段库由各项目组在通过busid上传文件到建行存储系统时一起上传,而使用算法从非结构文本中抽取出来的字段库则通过自然语言处理技术中的bert模型或者chatGLM模型训练出来;
具体的使用算法从非结构文本中抽取出来的字段库,以bert模型训练为例,首先需要对非结构文本段落进行预处理,所述预处理主要是对所述非结构文本段落进行句法分析,补全缺少主语的句子;建立代词消歧词库,利用正则表达式匹配算法,对所述非结构文本段落内的代词进行替换;对所述非结构文本段落进行分句,获得句子集合;
随后基于预先获得的Bert模型构建字段识别模型;将预处理后的非结构文本段落数据输入所述字段识别模型,得到高维特征向量;将所述高维特征向量输入所述chatGLM模型,对字符标签进行结构化预测,获得标签序列概率的对数,并输出得分最高的标签序列,得到字段识别结果;
步骤二、将自定义字段库和非结构化数据文件的元数据信息存储在HBase表中;
步骤三、将HBase表数据通过数据导入脚本导入到es中;
步骤四、根据导入至es中HBase表数据并基于es的搜索系统按照条件搜索并下载非结构化数据文件。
进一步的:将HBase表数据通过数据导入脚本导入到es中的具体步骤包括:先遍历HBase数据库中指定路径下所有的文件,并获取每个文件的绝对路径;根据获取到的文件的绝对路径将每个文件分别解析为预设格式的数据;将预设格式的数据转换为Result格式的数据;构建数据导入脚本,并将所述Result格式的数据通过所述数据导入脚本批量写入es中。
进一步的:非结构文本段落数据包括句子集合中的字符编码、位置编码和句子编码。
进一步的:一种基于HBase的文件检索系统,包括:
预处理模块,用于对非结构文本段落进行预处理;
模型构建模块,用于基于预先获得的Bert模型和chatGLM模型,构建字段识别模型;
字段识别模块,用于将预处理后的非结构文本段落数据输入所述字段识别模型,得到字段识别结果;
存储模块,用于将自定义字段库和非结构化数据文件的元数据信息存储在HBase表中;
数据导入模块,用于将HBase表数据通过数据导入脚本导入到es中。
进一步的:终端设备可以包括:处理器、存储介质和总线,存储介质存储有处理器可执行的机器可读指令,当终端设备运行时,处理器与存储介质之间通过总线通信,处理器执行机器可读指令,以执行时执行如前述实施例中所述的深度学习模型训练方法的步骤。
进一步的:一种存储介质,该存储有计算机程序,所述计算机程序被处理器运行时执行上述的方法的步骤。
进一步的:一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行上述所述的方法。
本发明的有益效果:本发明基于hbase+es的技术方案,利用es的搜索特性能快速且准确的搜索到存储在hadoop集群中的非结构化数据,通过可自定义的条件在存储系统中搜索符合条件的非结构化数据文件,增强存储系统的非结构化数据文件的搜索能力。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1示出了本发明方法的流程图。
图2示出了本发明系统的组成示意图。
图3示出了本发明终端设备的组成示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,应当理解,本发明中附图仅起到说明和描述的目的,并不用于限定本发明的保护范围。另外,应当理解,示意性的附图并未按实物比例绘制。本发明中使用的流程图示出了根据本发明的一些实施例实现的操作。应该理解,流程图的操作可以不按顺序实现,没有逻辑的上下文关系的步骤可以反转顺序或者同时实施。此外,本领域技术人员在本发明内容的指引下,可以向流程图添加一个或多个其他操作,也可以从流程图中移除一个或多个操作。
另外,本发明所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,本发明实施例中将会用到术语“包括”,用于指出其后所声明的特征的存在,但并不排除增加其它的特征。还应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。在本发明的描述中,还需要说明的是,术语“第一”、“第二”、“第三”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
下面结合说明书相关附图来对本案细致描述。
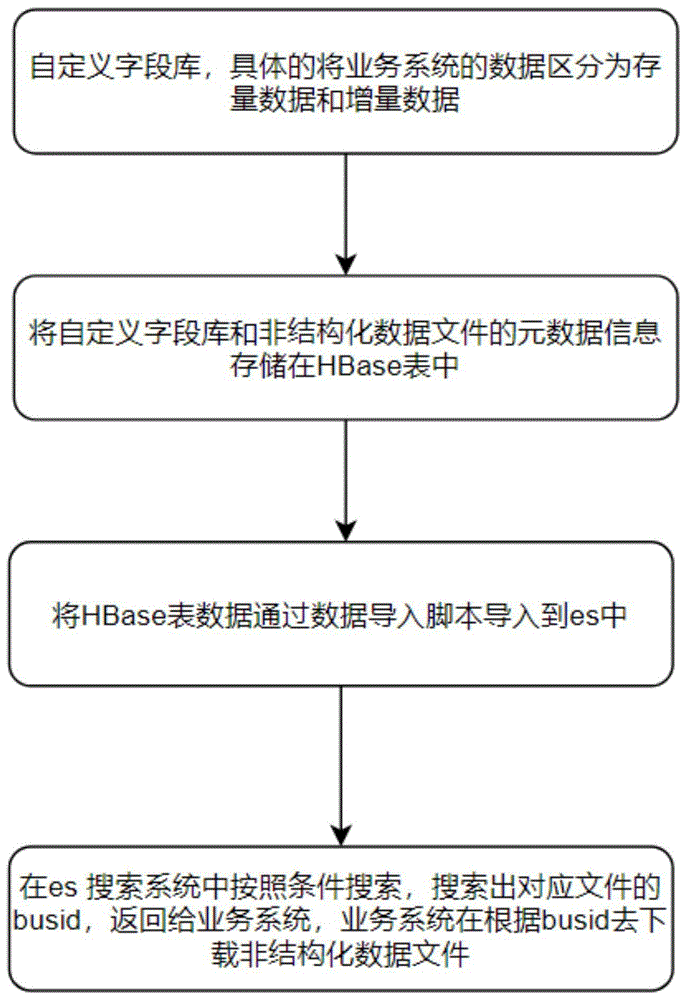
如图1所示,本发明一种基于HBase的文件检索方法,具体步骤包括:
步骤一、自定义字段库,具体的将业务系统的数据区分为存量数据和增量数据;
增量数据的自定义字段库包含两部分,一部分是各业务系统自定义的字段库,另一部分是使用算法从非结构文本中抽取出来的字段库;
存量数据的自定义字段库来源于使用算法从非结构文本中抽取出来的字段库;
自定义字段库的意义是后续在es搜索系统中搜索时,可以通过某些条件搜索到对应的非结构化数据文件;
其中增量数据中各业务系统自定义的字段库由各项目组在通过busid上传文件到建行存储系统时一起上传,而使用算法从非结构文本中抽取出来的字段库则通过自然语言处理技术中的bert模型或者chatGLM模型训练出来;
具体的使用算法从非结构文本中抽取出来的字段库,以bert模型训练为例,首先需要对非结构文本段落进行预处理,所述预处理主要是对所述非结构文本段落进行句法分析,补全缺少主语的句子;建立代词消歧词库,利用正则表达式匹配算法,对所述非结构文本段落内的代词进行替换;对所述非结构文本段落进行分句,获得句子集合;
随后基于预先获得的Bert模型构建字段识别模型;将预处理后的非结构文本段落数据输入所述字段识别模型,得到高维特征向量;将所述高维特征向量输入所述chatGLM模型,对字符标签进行结构化预测,获得标签序列概率的对数,并输出得分最高的标签序列,得到字段识别结果;
上述非结构文本段落数据包括句子集合中的字符编码、位置编码和句子编码;
同时上述步骤中还需构建特定行业领域知识库,本实施例用于银行业,因此构建金融银行相关的知识库,将所述字段识别结果按照所述特定行业领域知识库内的匹配规则进行关系匹配;
步骤二、将自定义字段库和非结构化数据文件的元数据信息存储在HBase表中;
步骤三、将HBase表数据通过数据导入脚本导入到es中;
具体的先遍历HBase数据库中指定路径下所有的文件,并获取每个文件的绝对路径;根据获取到的文件的绝对路径将每个文件分别解析为预设格式的数据;将预设格式的数据转换为Result格式的数据;构建数据导入脚本,并将所述Result格式的数据通过所述数据导入脚本批量写入es中。
步骤四、在es搜索系统中按照条件搜索,搜索出对应文件的busid,返回给业务系统,业务系统在根据busid去下载非结构化数据文件。
如图2所示,本发明一种基于HBase的文件检索系统,包括:
预处理模块,用于对非结构文本段落进行预处理;
模型构建模块,用于基于预先获得的Bert模型和chatGLM模型,构建字段识别模型;
字段识别模块,用于将预处理后的非结构文本段落数据输入所述字段识别模型,得到字段识别结果;
存储模块,用于将自定义字段库和非结构化数据文件的元数据信息存储在HBase表中;
数据导入模块,用于将HBase表数据通过数据导入脚本导入到es中。
如图3所示,该终端设备6可以包括:处理器601、存储介质602和总线603,存储介质602存储有处理器601可执行的机器可读指令,当终端设备运行时,处理器601与存储介质602之间通过总线603通信,处理器601执行机器可读指令,以执行时执行如前述实施例中所述的深度学习模型训练方法的步骤。具体实现方式和技术效果类似,在此不再赘述。
为了便于说明,在上述终端设备中仅描述了一个处理器。然而,应当注意,一些实施例中,本发明中的终端设备还可以包括多个处理器,因此本发明中描述的一个处理器执行的步骤也可以由多个处理器联合执行或单独执行。
以上仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 文件检索装置、文件检索系统、文件检索程序及文件检索方法
- 文件检索装置、文件检索系统、文件检索程序及文件检索方法