一种基于“表格-图”两阶段的面向文档级别实体关系联合抽取方法及装置
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及自然语言处理领域,具体为一种使用神经网络模型在文档级别的长文本中联合抽取实体和关系的方法及装置。
背景技术
目前,随着互联网时代信息的爆炸性增长,出现了海量的文本数据。如何从这些大量的原始文本数据中,自动提取出有价值的结构化数据,是数据分析和信息抽取的重要课题。而其中,如何从长文本中高质量的抽取信息,也相较于短文本的设置更贴近现实场景,也更具挑战。
在文档级别的长文本中,实体往往存在多个指代,因此,端到端的实体关系联合抽取往往可以分为三个子技术:指代抽取,即从文本中识别实体对应的文本;共指消解,即对于抽取的指代建立共指关系,形成实体集合;关系抽取,对于实体集合中的实体对,判断他们之间存在的关系。之前的技术方案主要以神经网络和预训练语言模型作为基础的特征提取器,并按照上述划分,以流水线的形式分别训练并预测各个子任务,抽取实体和关系。为了共用不同子任务之间的有益信息,也有技术方案提出使用多任务模型联合建模,在各个子任务之间共用基础特征提取器(Markus Eberts and Adrian Ulges.2021.An end-to-end model for entity-level relation extraction using multi-instancelearning.In Proceedings of the 16th Conference of the European Chapter of theAssociation for Computational Linguistics:Main Volume,pages3650–3660,Online.Association for Computational Linguistics.)。但是,上述方案仍然不能克服流水线模式的错误累积(error propagation)问题,在解码过程中,之前子任务的错误会引发后续的级联错误,从而极大程度上影响模型的精度。
发明内容
为了克服现有的技术方案中的错误累积问题,本发明提供一种面向文档级别实体关系联合抽取的“表格-图”两阶段生成方法及装置,可以在长文本中有效地抽取包括实体和关系在内的结构化信息。
本发明采用的技术方案如下:
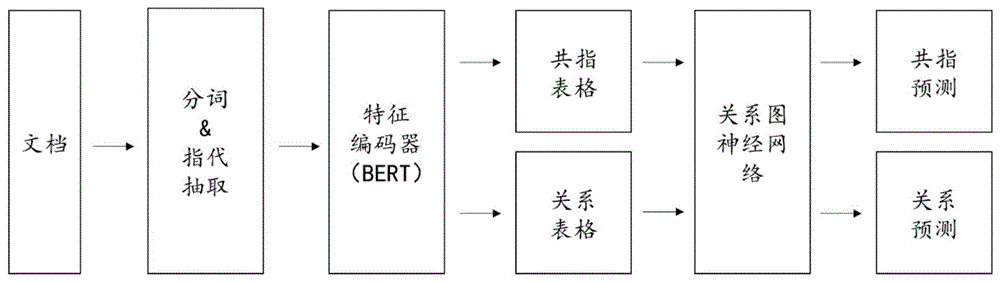
一种基于“表格-图”两阶段的面向文档级别实体关系联合抽取方法,包括编码阶段和解码阶段;
所述编码阶段包括:
对待处理文本进行分词后,输入训练完成的序列标注模型,进行指代抽取;
将指代输入训练完成的“表格-图”两阶段模型,预测得到共指分数和关系分数;
所述解码阶段包括:
利用共指分数和关系分数,使用层次聚类方法进行共指消解解码;
对于层次聚类方法得到的实体簇,使用众数投票方法进行关系抽取解码。
进一步地,所述序列标注模型用于指代抽取子任务,按照BIO的标注格式进行训练,以预测文本的BIO类别。
进一步地,所述“表格-图”两阶段模型用于共指消解子任务和关系抽取子任务,将指代看作结点,所述共指消解子任务在指代对之间预测指代是否指向相同实体,即0/1分数;所述关系抽取子任务在指代对之间预测指代对应的实体之间的关系,即多分类任务。
进一步地,所述“表格-图”两阶段模型包括:
在表格阶段,首先使用BERT模型对原始文本进行特征提取,得到指代对应的表示,然后使用双仿射变换对每一个指代对预测共指分数和关系分数:
在图阶段,将共指分数和关系分数作为以指代为结点的动态图上的边权重,构建对应的共指边和关系边;针对指代之间的语法结构,再静态构造语法边;对于得到的三种边和指代的原始表示,使用关系图神经网络R-GCN编码结点表示;
利用关系图神经网络R-GCN得到的结点表示,再次使用双仿射变换预测最终的共指分数和关系分数。
进一步地,所述层次聚类方法在计算不同簇之间的距离时,考虑两部分:一部分是在编码阶段最终预测的共指分数,一部分是以关系分数计算得到的惩罚项;将该两部分的加权和作为簇间距离。
进一步地,使用指代的关系向量之间的汉明距离作为所述惩罚项。
进一步地,所述使用众数投票方法进行关系抽取解码,包括:给定目标实体对,检查实体对之间所有的指代对的关系预测结果,并将投票超过半数的关系作为实体对之间的预测关系。
一种基于“表格-图”两阶段的面向文档级别实体关系联合抽取系统,包括编码模块和解码模块;
所述编码模块对待处理文本进行分词后,输入训练完成的序列标注模型,进行指代抽取,并将指代输入训练完成的“表格-图”两阶段模型,预测得到共指分数和关系分数;
所述解码阶段利用共指分数和关系分数,使用层次聚类方法进行共指消解解码,并对于层次聚类方法得到的实体簇,使用众数投票方法进行关系抽取解码。
本发明的有益效果如下:
本发明在编码和解码两方面的针对性设计(“表格-图”两阶段模型和层次聚类方法)可以有效缓解共指消解和关系抽取这两个子任务之间的错误累积问题,并促进不同子任务之间的语义交换,从而改善信息抽取表现。
附图说明
图1是本发明的任务说明图,文档级别关系抽取需要从长文本中抽取指代、实体和关系。
图2是本发明的编码部分流程图,主要展示“表格-图”模型的编码流程。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施例和附图,对本发明做进一步详细说明。
本发明方法主要可以分编码和解码两阶段。编码阶段的主要步骤包括:
(1)使用分词器(tokenizer)对文本进行分词,转化为字典中的字符;
(2)单独针对指代抽取子任务构建序列标注模型,并按照B(begin,开始),I(inside,内部),O(outside,非实体)的标注格式训练序列标注模型。序列标注模型使用BERT作为特征提取器,使用线性层预测字符的序列类别(即BIO序列)。其中,指代表示指代具体的实体概念的连续文本段;根据BIO序列可以得到指代,例如从每个B标签位置开始,将形如(B-I-…-I)-O部分作为解码得到的连续文本段,即为指代。
(3)共同建模共指消解子任务和关系抽取子任务:将指代看作结点,共指消解子任务需要在指代对之间预测它们是否指向相同实体,即0/1分数;在指代级别考虑关系抽取,则关系抽取子任务可以看作在指代对之间预测它们对应的实体之间的关系,即多分类任务。所以,在这个统一建模下,可以使用相同的“表格-图”两阶段模型编码这两个任务的嵌入表示。
(4)在表格阶段,针对两个子任务都预测0/1分数。首先使用BERT模型对原始文本进行特征提取,得到指代对应的表示。再使用双仿射变换对每一个指代对(mi,mj)预测共指分数和关系分数。
共指分数的计算公式:
关系分数的计算公式:
其中,
将得到的n*n个共指分数作为共指表格,将得到的n*n个关系分数作为关系表格。其中表格是指n*n的矩阵,可以看作以指代作为结点的图所对应的邻接矩阵。
(5)在图阶段,将第(4)步得到的共指(coreference)分数和关系(relation)分数作为以指代作为结点的动态图上的边权重,构建对应的共指边和关系边。此外,针对指代之间的语法结构,再静态地(在指代确定后即固定不变)构造语法(syntax)边。具体规则为:如果两个指代出现在同一个句子中,则它们间的边权为1,否则为0。对于得到的三种边和指代的原始表示,使用关系图神经网络(relational graph convolutional network,R-GCN)编码结点表示。
(6)最后,利用关系图神经网络R-GCN得到的结点表示,替换计算公式中的z,再次使用双仿射变换预测最终的共指分数和关系分数,完成编码。
在解码阶段,主要步骤包括:
(1)指代抽取:将序列标注模型输出的BIO序列,还原成预测的指代。
(2)共指消解:利用编码阶段预测的共指分数和关系分数,使用层次聚类方法(hierarchical agglomerative clustering,HAC)进行共指消解解码。
在计算不同簇(cluster)之间的距离时,考虑两部分:一部分是在编码阶段最终预测的共指分数,一部分是以关系分数计算得到的惩罚项。考虑到在训练过程中,指向相同实体的指代对之间有着相同的关系标签,因此使用指代的关系向量之间的汉明距离作为额外惩罚项,计算如下:
其中,|C
指代(节点)的关系向量构造如下:若预测得到的指代mi和mj之间存在关系r,则
最后使用这两部分的加权和作为簇间距离。
(3)关系抽取:使用众数投票(majority voting)机制进行关系抽取解码。给定目标实体对,检查实体对之间所有的指代对的关系预测结果,并将投票超过半数的关系作为实体对之间的预测关系。
该方法的应用有两个步骤:第一步是使用已标注的文本数据集训练编码模型,并在验证集上调整解码超参数;第二步是使用训练得到的编码模型和解码算法来识别目标文本中的实体和关系。第一步与第二步不需要连续进行,可单独进行第一步得到预训练模型之后,再在新的文本上进行第二步识别。
本发明可以应用于任意类型的关系和实体抽取。下面提供一个具体实施例。该实施例为一种面向文档级别实体关系联合抽取的“表格-图”两阶段生成方法,以百科文本中的信息抽取为例,希望在文本数据中自动抽取实体和实体间的关系,如图1所示。
训练阶段的主要步骤如下:
(1)首先需要构建训练模型所需的训练数据。训练数据需要标注指代的起止范围、共指关系,和实体之间的关系。
(2)对训练数据中的文本数据进行分词。本实施例使用与BERT模型对应的分词器实现分词。
(3)训练指代抽取子模块。对应的模型为BERT作为特征提取器,通过一层线性层输出BIO类别。
(4)使用训练数据标注的指代、共指和关系,构造标签,训练共指消解子模块和关系抽取子模块,即“表格-图”两阶段模型;
(5)最后,模型可以输出所有指代对之间共指消解的0/1分数,和每个类别的关系分数。
测试阶段的主要步骤如下:
(1)对文本数据分词;
(2)使用训练的指代抽取子模块预测文本的BIO类别,并解码成指代范围;
(3)将预测的指代输入“表格-图”两阶段模型,预测得到共指分数和关系分数;
(4)使用层次聚类方法进行共指消解解码;
(5)对于解码得到的实体簇,使用众数投票方法进行关系抽取解码。
在维基百科文本构造的DocRED数据集上,使用3053篇文档进行训练,1000篇文档进行测试,取得的结果如表1所示。
表1
本实例的实验结果表明了本专利的方法是能带来有效的效果提升,与现在普遍使用的模型相比,能够更好地联合提取实体和关系。
本发明的另一实施例提供一种基于“表格-图”两阶段的面向文档级别实体关系联合抽取系统,包括编码模块和解码模块:
所述编码模块对待处理文本进行分词后,输入训练完成的序列标注模型,进行指代抽取,并将指代输入训练完成的“表格-图”两阶段模型,预测得到共指分数和关系分数;
所述解码阶段利用共指分数和关系分数,使用层次聚类方法进行共指消解解码,并对于层次聚类方法得到的实体簇,使用众数投票方法进行关系抽取解码。
其中各模块的具体实施过程参见前文对本发明方法的描述。
本发明的另一实施例提供一种计算机设备(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
本发明的另一实施例提供一种计算机可读存储介质(如ROM/RAM、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
以上公开的本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例所公开的内容,本发明的保护范围以权利要求书界定的范围为准。
- 一种基于实体关系联合抽取模型的多三元组抽取方法
- 基于增强序列标注策略的单阶段联合实体关系抽取方法及系统
- 一种基于概率图的实体联合标注关系抽取方法和系统