图像增强方法、图像处理方法、计算机设备及存储介质
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及图像处理技术领域,具体涉及一种图像增强方法、图像处理方法、计算机设备及存储介质。
背景技术
在对车辆进行自动驾驶控制时通常会通过感知模型感知车辆周围的障碍物等信息,再根据感知的结果规划车辆的行驶路径,控制车辆按照规划好的行驶路径自动驾驶。其中,感知模型可以采用图像训练得到,在训练感知模型之前可以对图像进行数据增强,以扩充图像的数量。
目前,常规的图像增强方法主要是对图像进行水平/垂直翻转、缩放、旋转和变色等或者是对图像进行风格迁移。但是,通过这些方法进行数据增强得到的图像只能包含原来图像所呈现场景中的场景信息,无法包含此场景以外的场景信息。例如,对只包含轿车的图像进行风格迁移形成的增强图像,其场景信息仍然只包含轿车,无法包含卡车等未出现过的场景信息。如果采用上述增加图像训练感知模型,感知模型将无法准确地感知出卡车等未出现过的场景信息,从而降低了感知模型的泛化能力,最终影响车辆自动驾驶的安全性和可靠性。
相应地,本领域需要一种新的技术方案来解决上述问题。
发明内容
为了克服上述缺陷,提出了本发明,以提供解决或至少部分地解决如何丰富图像的场景信息,特别是增加原始图像未出现过的场景信息的技术问题的图像增强方法、图像处理方法、计算机设备及存储介质。
在第一方面,提供一种图像增强方法,所述方法包括:
根据真实场景中静态场景的二维图像,获取所述静态场景的三维重建信息;
根据预设虚拟物体的二维图像,获取所述预设虚拟物体的三维重建信息;
对所述静态场景的三维重建信息与所述预设虚拟物体的三维重建信息进行融合;
将融合的结果渲染成二维图像作为增强图像。
在上述图像增强方法的一个技术方案中,所述获取所述静态场景的三维重建信息,包括:根据所述静态场景的二维图像,获取所述静态场景的第一神经辐射场;
所述获取所述预设虚拟物体的三维重建信息,包括:根据预设虚拟物体的二维图像,获取所述预设虚拟物体的第二神经辐射场。
在上述图像增强方法的一个技术方案中,所述获取所述静态场景的第一神经辐射场,包括:
获取所述静态场景的多视角二维图像;
对所述静态场景的多视角二维图像进行神经辐射场重建,以获取所述静态场景的第一神经辐射场。
在上述图像增强方法的一个技术方案中,所述获取所述预设虚拟物体的第二神经辐射场,包括:
构建所述预设虚拟物体的虚拟模型;
获取所述虚拟模型的多视角二维图像;
对所述虚拟模型的多视角二维图像进行神经辐射场重建,以获取所述虚拟物体的第二神经辐射场。
在上述图像增强方法的一个技术方案中,所述对所述静态场景的三维重建信息与所述预设虚拟物体的三维重建信息进行融合,包括:
将所述第一神经辐射场嵌入到所述第二神经辐射场,以实现融合。
在上述图像增强方法的一个技术方案中,所述将所述第一神经辐射场嵌入到所述第二神经辐射场,包括:
设定所述第一神经辐射场的嵌入位姿;
根据所述嵌入位姿,将所述第一神经辐射场嵌入到所述第二神经辐射场。
在第二方面,提供一种图像处理方法,所述方法包括:
采用第一方面提供的图像增强方法,得到多个不同的增强图像作为图像样本;
采用所述图像样本对图像处理模型进行模型训练;
采用训练好的图像处理模型对输入图像进行图像处理。
在上述图像处理方法的一个技术方案中,所述图像处理模型至少包括物体识别跟踪模型和/或自动驾驶感知模型。
在第三方面,提供一种计算机设备,该计算机设备包括处理器和存储装置,所述存储装置适于存储多条程序代码,所述程序代码适于由所述处理器加载并运行以执行上述图像增强或图像处理方法的技术方案中任一项技术方案所述的方法。
在第四方面,提供一种计算机可读存储介质,该计算机可读存储介质其中存储有多条程序代码,所述程序代码适于由处理器加载并运行以执行上述图像增强或图像处理方法的技术方案中任一项技术方案所述的方法。
本发明上述一个或多个技术方案,至少具有如下一种或多种有益效果:
在实施本发明提供的图像增强方法的技术方案中,可以根据真实场景中静态场景的二维图像获取静态场景的三维重建信息,根据预设虚拟物体的二维图像获取预设虚拟物体的三维重建信息,对静态场景与预设虚拟物体的三维重建信息进行融合,使得融合的结果同时包含这两种三维重建信息,最后将融合的结果渲染成二维图像作为增强图像。通过上述实施方式,可以在真实场景的静态场景中增加未曾出现过的场景信息(即虚拟物体的场景信息),丰富了图像的场景信息。
在实施本发明提供的图像处理方法的技术方案中,可以上述图像增强方法得到多个不同的增强图像作为图像样本,采用这些图像样本对图像处理模型进行模型训练,最后采用训练好的图像处理模型对输入图像进行图像处理。通过上述实施方式,可以提高图像处理模型进行图像处理的泛化能力。
附图说明
参照附图,本发明的公开内容将变得更易理解。本领域技术人员容易理解的是:这些附图仅仅用于说明的目的,而并非意在对本发明的保护范围组成限制。其中:
图1是根据本发明的一个实施例的图像增强方法的主要步骤流程示意图;
图2是根据本发明的一个实施例的获取静态场景的三维重建信息的方法的主要步骤流程示意图;
图3是根据本发明的一个实施例的获取预设虚拟物体的三维重建信息的方法的主要步骤流程示意图;
图4是根据本发明的一个实施例的图像处理方法的主要步骤流程示意图;
图5是根据本发明的一个实施例的计算机设备的主要结构示意图。
具体实施方式
下面参照附图来描述本发明的一些实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
在本发明的描述中,“处理器”可以包括硬件、软件或者两者的组合。处理器可以是中央处理器、微处理器、图像处理器、数字信号处理器或者其他任何合适的处理器。处理器具有数据和/或信号处理功能。处理器可以以软件方式实现、硬件方式实现或者二者结合方式实现。计算机可读存储介质包括任何合适的可存储程序代码的介质,比如磁碟、硬盘、光碟、闪存、只读存储器、随机存取存储器等等。术语“A和/或B”表示所有可能的A与B的组合,比如只是A、只是B或者A和B。
下面对本发明提供的图像增强方法的实施例进行说明。
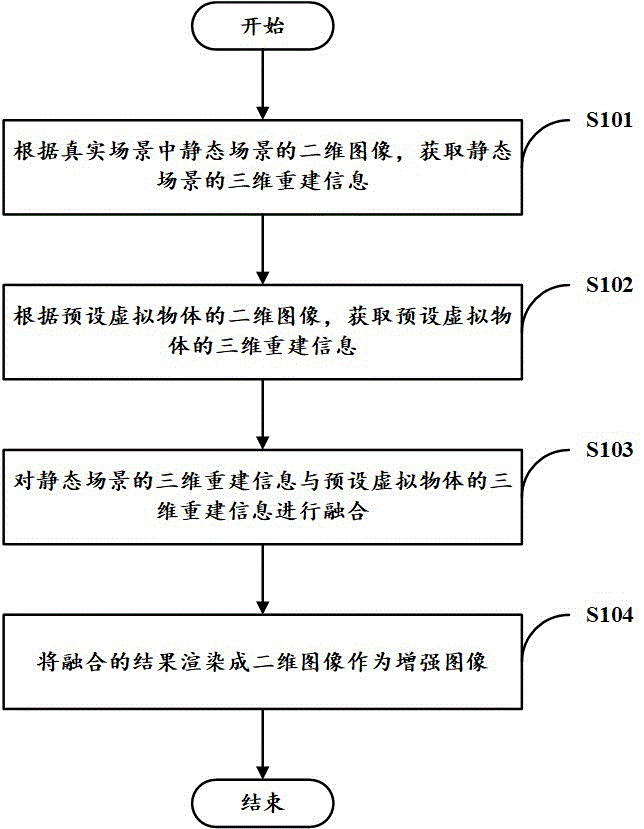
参阅附图1,图1是根据本发明的一个实施例的图像增强方法的主要步骤流程示意图。如图1所示,本发明实施例中的图像增强方法主要包括下列步骤S101至步骤S104。
步骤S101:根据真实场景中静态场景的二维图像,获取静态场景的三维重建信息。
真实场景是物理世界中真实存在的场景,这个真实场景包含了动态场景和静态场景,动态场景是指由动态物体构成的场景,静态场景是指由静态物体构成的场景,可以通过静态物体分割的方式从真实场景中获取静态场景或者也可以通过动态物体分割的方式从真实场景中获取动态场景,再去除这些动态场景,将剩余的场景作为静态场景。例如,真实场景是高速公路,高速公路上的车道、交通标识、车道两侧的树木等静态物体构成静态场景,高速公路上行驶的车辆等动态物体构成动态场景。
在本实施例中可以采用三维重建方法,根据静态场景的二维图像对静态场景进行三维重建,将重建的结果作为三维重建信息。
步骤S102:根据预设虚拟物体的二维图像,获取预设虚拟物体的三维重建信息。
预设虚拟物体不是物理世界中真实存在的物体,但其可以是参照物理世界中真实存在的物体构建出来的。例如,可以参照物理世界中真实存在的一辆卡车,构建一辆虚拟卡车,这辆虚拟卡车与真实存在的卡车的外观可以完全相同。
在本实施例中同样可以采用三维重建方法,根据虚拟物体的二维图像对虚拟物体进行三维重建,将重建的结果作为虚拟物体的三维重建信息。
步骤S103:对静态场景的三维重建信息与预设虚拟物体的三维重建信息进行融合。
通过对静态场景与预设虚拟物体的三维重建信息进行融合,可以使融合的结果同时包含静态场景与预设虚拟物体的三维重建信息,相当于在静态场景中增加了其未曾出现过的新的场景信息,即预设虚拟物体的三维重建信息。
步骤S104:将融合的结果渲染成二维图像作为增强图像。
在本实施例中可以采用能够将三维信息渲染成二维图像的渲染引擎,将三维重建信息的融合结果,渲染成二维图像。
基于上述步骤S101至步骤S104所述的方法,可以使增强图像包含原来的静态场景中未曾出现过的场景信息,丰富了图像的场景信息。例如,对只包含轿车的图像进行风格迁移形成的增强图像,其场景信息不会包含卡车。但是,通过上述方法可以利用这个图像得到包含卡车的增强图像。
下面对上述步骤S101至步骤S103作进一步说明。
一、对步骤S101和步骤S102进行说明。
在上述步骤S101和步骤S102的一些实施方式中,可以根据静态场景的二维图像,获取静态场景的第一神经辐射场。同时,也可以根据预设虚拟物体的二维图像,获取预设虚拟物体的第二神经辐射场。神经辐射场(Neural Radiance Field,NeRF)为计算机视觉技术领域中一种常规的三维重建模型。基于神经辐射场具备的三维重建质量高等优点,可以使第一神经辐射场逼真地呈现出静态场景的各场景信息,同时也可以使第二神经辐射场逼真地呈现出虚拟物体的各物体信息,从而有利于提高增强图像的真实度。
进一步,在上述步骤S101的一些实施方式中,可以通过图2所示的下列步骤S1011至步骤S1012,获取静态场景的第一神经辐射场。
步骤S1011:获取静态场景的多视角二维图像。
在本实施方式中可以采用真实的相机从多个不同的视角,对静态场景进行拍摄,得到在各视角下的二维图像。
步骤S1012:对静态场景的多视角二维图像进行神经辐射场重建,以获取静态场景的第一神经辐射场。
在本实施方式中可以采用常规的神经辐射场的重建方法,对多视角二维图像进行神经辐射场重建。在一些实施方式中,通过重建得到的第一神经辐射场是体素化的神经辐射场。
基于上述步骤S1011至步骤S1012所述的方法,可以利用多个不同视角的静态场景的二维图像,得到更加逼真的第一神经辐射场,从而能够进一步提高增强图像的真实度。
在上述步骤S102的一些实施方式中,可以通过图3所示的下列步骤S1021至步骤S1023,获取预设虚拟物体的第二神经辐射场。
步骤S1021:构建预设虚拟物体的虚拟模型。
在本实施方式中可以采用预设的物体仿真器,构建预设虚拟物体的虚拟模型。其中,预设的物体仿真器为能够基于计算机技术领域中的仿真技术,仿真出物体的仿真器,仿真出的物体可以由三维点云表示。也就是说,预设虚拟物体的虚拟模型是一个三维模型。
在本实施方式中可以采用常规的仿真方法来构建上述预设的物体仿真器,只要其能够实现上述功能即可,本实施方式不对物体仿真器的构建方法作具体限定。此外,在本实施方式中也可以直接采用能够实现上述功能的常规的物体仿真器,本实施方式对此同样不作具体限定。
步骤S1022:获取虚拟模型的多视角二维图像。
在本实施方式中可以采用虚拟的相机从多个不同的视角,对虚拟模型进行拍摄,得到在各视角下的二维图像。
虚拟的相机是基于计算机技术领域中的仿真技术,仿真得到的一个能够拍摄物体的二维图像的相机,相对于真实的相机而言,它不是物理世界中真实存在的相机,它不具有真实相机应该具备的摄像头等硬件结构。
在本实施方式中可以采用常规的仿真方法来构建上述虚拟的相机,只要其能够实现上述功能即可,本实施方式不对虚拟相机的构建方法作具体限定。此外,在本实施方式中也可以直接采用能够实现上述功能的常规的虚拟相机,本实施方式对此同样不作具体限定。
步骤S1023:对虚拟模型的多视角二维图像进行神经辐射场重建,以获取虚拟物体的第二神经辐射场。
在本实施方式中,与步骤S1012类似,也可以采用常规的神经辐射场的重建方法,对多视角二维图像进行神经辐射场重建。在一些实施方式中,通过重建得到的第二神经辐射场是体素化的神经辐射场。
基于上述步骤S1021至步骤S1023所述的方法,可以利用多个不同视角的预设虚拟物体的二维图像,得到更加逼真的第二神经辐射场,从而能够进一步提高增强图像的真实度。
二、对步骤S103进行说明。
在上述步骤S103的一些实施方式中,可以将通过上述实施方式得到的第一神经辐射场嵌入到第二神经辐射场,以实现融合。采用嵌入的方式可以将第一神经辐射场融合到第二神经辐射场里面,也就实现了将预设虚拟物体融合到静态场景中,从而丰富了静态场景的场景信息。
在一些实施方式中,可以设定第一神经辐射场的嵌入位姿,根据嵌入位姿将第一神经辐射场嵌入到第二神经辐射场。其中,嵌入位姿为将第一神经辐射场嵌入到第二神经辐射场之后,第一神经辐射场在第二神经辐射场中的位姿。通过上述方式,可以根据实际需求灵活地调节预设虚拟物体在静态场景中的分布位置,进一步提高了静态场景中场景信息的多样性。
下面对本发明提供的图像处理方法的实施例进行说明。
参阅附图4,图4是根据本发明的一个实施例的图像处理方法的主要步骤流程示意图。如图4所示,本发明实施例中的图像处理方法主要包括下列步骤S201至步骤S203。
步骤S201:采用图像增强方法,得到多个不同的增强图像作为图像样本。此步骤中的图像增强方法可以采用前述方法实施例所述的图像增强方法。
步骤S202:采用图像样本对图像处理模型进行模型训练。
在本实施例中可以采用机器学习技术领域中常规的模型训练方法,对图像处理模型进行模型训练。
在一些实施方式中,图像处理模型至少包括物体识别跟踪模型和/或自动驾驶感知模型。物体识别跟踪模型可以用于从图像中识别物体的信息(包括但不限于物体的类别、尺寸、速度、位置等),并根据该信息对物体进行跟踪。自动驾驶感知模型可以用于从车辆采集的图像中感知车辆周围的障碍物等信息。
步骤S203:采用训练好的图像处理模型对输入图像进行图像处理。例如,若图像处理模型为自动驾驶感知模型,则将车辆采集的图像输入到自动驾驶感知模型中,自动驾驶感知模型可以对输入的图像进行障碍物感知,得到障碍物的类型和位置等信息。
基于上述步骤S201至步骤S203所述的方法,可以通过图像增强方法扩充图像样本中的场景信息,从而提高了训练好的图像处理模型进行图像处理的泛化能力,能够准确且可靠地完成图像处理任务。
需要指出的是,尽管上述实施例中将各个步骤按照特定的先后顺序进行了描述,但是本领域技术人员可以理解,为了实现本发明的效果,不同的步骤之间并非必须按照这样的顺序执行,其可以同时(并行)执行或以其他顺序执行,这些调整之后的方案与本发明中描述的技术方案属于等同技术方案,因此也将落入本发明的保护范围之内。
本领域技术人员能够理解的是,本发明实现上述一实施例的方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读存储介质可以包括:能够携带所述计算机程序代码的任何实体或装置、介质、U盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器、随机存取存储器、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读存储介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读存储介质不包括电载波信号和电信信号。
进一步,本发明还提供了一种计算机设备。
参阅附图5,图5是根据本发明的一个计算机设备实施例的主要结构示意图。如图5所示,本发明实施例中的计算机设备主要包括存储装置和处理器,存储装置可以被配置成存储执行上述方法实施例的图像增强或图像处理方法的程序,处理器可以被配置成用于执行存储装置中的程序,该程序包括但不限于执行上述方法实施例的图像增强或图像处理方法的程序。为了便于说明,仅示出了与本发明实施例相关的部分,具体技术细节未揭示的,请参照本发明实施例方法部分。
在本发明实施例中计算机设备可以是包括各种电子设备形成的控制装置设备。在一些可能的实施方式中,计算机设备可以包括多个存储装置和多个处理器。而执行上述方法实施例的图像增强或图像处理方法的程序可以被分割成多段子程序,每段子程序分别可以由处理器加载并运行以执行上述方法实施例的图像增强或图像处理方法的不同步骤。具体地,每段子程序可以分别存储在不同的存储装置中,每个处理器可以被配置成用于执行一个或多个存储装置中的程序,以共同实现上述方法实施例的图像增强或图像处理方法,即每个处理器分别执行上述方法实施例的图像增强或图像处理方法的不同步骤,来共同实现上述方法实施例的图像增强或图像处理方法。
上述多个处理器可以是部署于同一个设备上的处理器,例如上述计算机设备可以是由多个处理器组成的高性能设备,上述多个处理器可以是该高性能设备上配置的处理器。此外,上述多个处理器也可以是部署于不同设备上的处理器,例如上述计算机设备可以是服务器集群,上述多个处理器可以是服务器集群中不同服务器上的处理器。
进一步,本发明还提供了一种计算机可读存储介质。
在根据本发明的一个计算机可读存储介质的实施例中,计算机可读存储介质可以被配置成存储执行上述方法实施例的图像增强或图像处理方法的程序,该程序可以由处理器加载并运行以实现上述图像增强或图像处理方法。为了便于说明,仅示出了与本发明实施例相关的部分,具体技术细节未揭示的,请参照本发明实施例方法部分。该计算机可读存储介质可以是包括各种电子设备形成的存储装置设备,可选的,本发明实施例中计算机可读存储介质是非暂时性的计算机可读存储介质。
至此,已经结合附图所示的一个实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 图像处理方法、装置、计算机设备及存储介质
- 图像处理方法和装置、电子设备、计算机可读存储介质
- 图像处理方法、装置、电子设备及计算机可读存储介质
- 药丸包衣图像处理方法、装置、计算机设备和存储介质
- 红外图像处理方法、装置、计算机设备和可读存储介质
- 一种图像增强处理方法、设备及计算机可读存储介质
- 图像增强处理方法、装置、计算机设备及存储介质