一种面向空间机器人辅助操作的快速前向搜索任务规划方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于任务规划领域,涉及一种典型面向空间机器人辅助操作任务下的任务规划方法。
背景技术
目前在空间机器人辅助操作领域的常用任务规划算法包括规划图算法和分层网络算法。规划图算法由于包含大量互斥动作和互斥命题的判定导致该算法的计算效率地下,针对某一具体的空间辅助操作任务,往往需要消耗大量时间计算。分层网络算法需要提前提供专家知识,并且规划的过程需要提供分解方式,自主程度不够。
快速前向搜索规划方法是一种高效的启发式搜索规划方法,其高效性主要基于以下几项关键技术:1)构建放宽的规划图,用于计算状态的启发式估值;2)采用增强型爬山算法,作为快速前向启发式搜索算法;3)定义有利动作,作为有效的剪枝策略。该规划方法在国际智能规划大赛中获得了最佳性能奖,基于放宽规划启发式和前向局部搜索的思想已经被广泛用到求解各类复杂规划问题。
空间机器人在辅助完成空间操作任务的过程中,需要大量的移动、抓取和释放动作。例如,美国的RRM3项目中需要空间机器人辅助完成空间加注任务,这时需要空间机器人先打开保护罩,然后拧开盖子并进入输送阀门加注燃料。在这一过程中存在多个动作以及对应工具的切换。
为了自主地生成空间机器人辅助操作任务的动作序列,本发明采用了高效的快速前向搜索规划方法。在将该规划方法应用到空间机器人加注领域后发现,空间机器人辅助操作任务关注更多的是在某一状态下动作的选择,算法以往针对状态的深度优先搜索针对性不强、并且动作间的前提条件状态可能重合,所以本发明考虑将面向空间机器人辅助操作任务的快速前向搜索规划方法中的搜索方法由状态搜索改为动作搜索。由此产生的动作选择的问题,不能采用之前有利动作的方法解决。因为以往采用有利动作的方法并没有考虑空间机器人执行有利动作时的执行代价。
发明内容
本发明所要解决的技术问题是:
为了避免现有技术的不足之处,本发明提供一种面向空间机器人辅助操作的快速前向搜索任务规划方法,通过修改剪枝和扩展策略,将动作操作难度作为代价引入到针对某一任务的动作序列求解之中,使整个方法能够得到一组满足操作难度最小约束最优的动作执行序列。
为了解决上述技术问题,本发明采用的技术方案为:
因为快速前向搜索算法在智能规划领域高效的表现,所以本发明打算采用快速前向搜索算法对空间辅助操作任务中的任务规划问题进行求解。然而空间机器人辅助操作任务更关注动作间的转换并且在动作转换期间要保证空间机器人的位姿扰动最小,基于快速前向搜索规划方法针对状态的搜索不满足空间辅助操作任务的需求,因而本发明面向空间辅助操作任务的动作序列求解需求,将状态搜索改为了动作搜索,采用动作搜索带来的动作选择问题,本发明设计相应的代价函数评价动作的操作难度并选择操作难度最小的动作,最终求解得到满足空间辅助操作任务约束条件的动作序列。
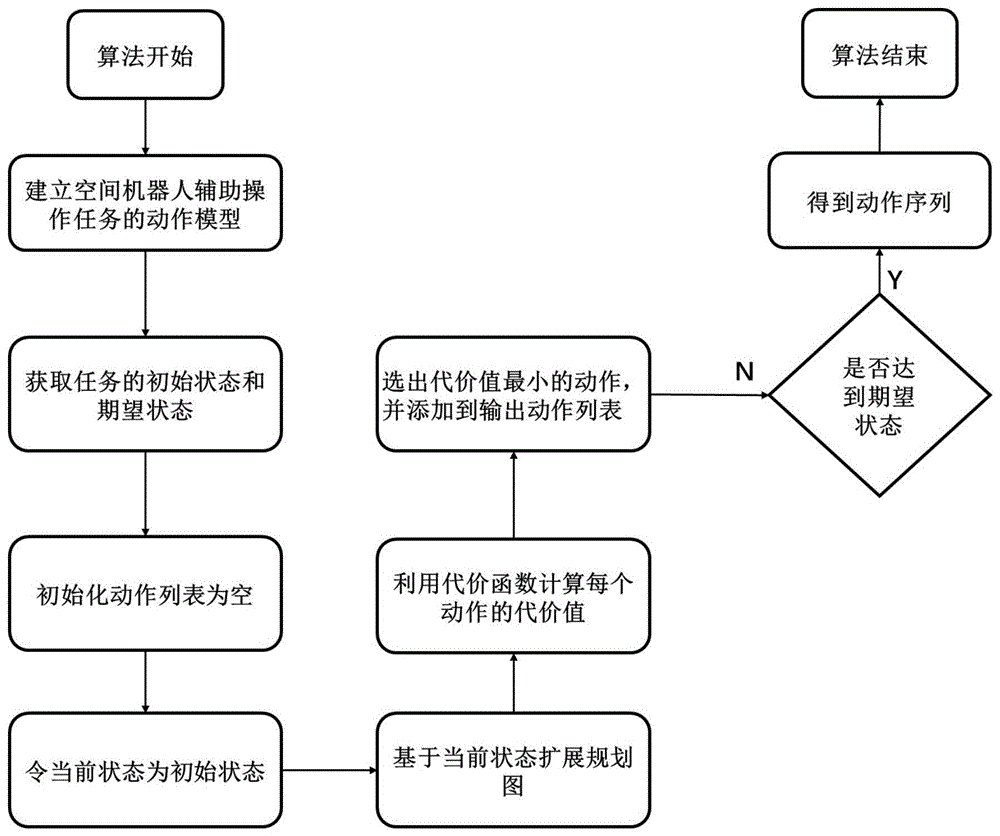
一种面向空间机器人辅助操作的快速前向搜索任务规划方法,其特征在于步骤如下:
步骤1:建立空间辅助操作任务的数学模型,设定每个动作的前提条件和作用效果以及空间辅助操作任务的期望状态s
a=[name(a) precondition(a) effect(a)](1)
γ(s a)=(s-effect
其中,a表示动作,name表示动作a的名称,precondition表示动作a的前提条件,effect表示动作a的效果,动作a的效果可分别表示为添加效果effect
步骤2:设计操作难度的代价函数:
f(a)=g(a)+h(a)(3)
其中,f(a)表示制定动作a的总代价;g(a)表示从当前状态s执行动作a的代价,包括机器人从当前状态前往工具箱更换工具的代价和沿途的位姿扰动代价,该式表示任务总是先完成当前工具所能完成的所有任务;h(a)表示从动作a到期望状态的代价,该代价由松弛的规划图算法计算得到,具体表现为松弛规划图算法求解得的动作数目m,该式表示总是得到与期望状态最近的动作;
步骤3:扩展规划图
根据步骤1中建立的动作模型,利用规划图算法从初始状态开始向期望状态扩展,得到前提条件属于当前状态的可用动作A(s
步骤4:选择代价最小的动作a
针对步骤3得到的可用动作集合A(s
步骤5:利用动作a
步骤6:重复步骤3~5,直至新的世界状态s
一种计算机系统,其特征在于包括:一个或多个处理器,计算机可读存储介质,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述的方法。
一种计算机可读存储介质,其特征在于存储有计算机可执行指令,所述指令在被执行时用于实现上述的方法。
本发明的有益效果在于:
本发明提供的一种面向空间辅助操作任务的快速前向搜索任务规划方法,通过修改剪枝和扩展策略,将快速前向搜索任务规划方法引入到了空间辅助操作任务领域之中。针对操作动作为主的空间辅助操作任务,本发明将状态搜索更改为动作搜索,通过引入操作代价的方法对动作搜索过程中的动作进行了排序,选择得到操作代价最小的动作序列。本发明与初版快速前向搜索规划方法相比,结合了所要研究的领域并引入了从当前状态到可用动作A(s
附图说明
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
图1面向空间辅助操作任务的快速前向搜索任务规划方法流程图;
图2基于快速前向搜索任务规划方法得到的复杂动作序列;
图3基于快速前向搜索任务规划方法得到的完整动作序列;
图4基于改进快速前向搜索任务规划方法得到的完整动作序列;
图5基于PDDL描述的空间辅助操作任务动作列表。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明是一种面向空间辅助操作任务的快速前向搜索任务规划方法,基于快速前向搜索规划方法,面向空间辅助操作任务进行了改进。包括:通过更换状态搜索为动作搜索和引入操作难度代价选择动作,得到了能够应用在空间机器人辅助操作领域的规划方法。通过仿真验证了该方法可以快速高效的得到空间辅助操作任务的动作序列,具体实施方式如下:
一种面向空间辅助操作任务的快速前向搜索任务规划方法,包括:
步骤1:建立空间辅助操作任务的数学模型
本发明采用了PDDL(Planning Domain Definition Language)对空间辅助操作任务中的动作进行建模,并设定每个动作的前提条件和作用效果以及空间辅助操作任务的期望状态s
a=[name(a) precondition(a) effect(a)](1)
γ(s a)=(s-effect
其中,a表示动作,name表示动作a的名称,precondition表示动作a的前提条件,effect表示动作a的效果,动作a的效果可分别表示为添加效果effect
步骤2:设计操作难度的代价函数。为了方便的衡量每个动作的操作难度,本发明将动作分为了两种,分别是复杂动作(例如,拆卸、加注等)和普通动作(例如,移动、抓取和释放)。在快速前向搜索规划方法中,一个动作的操作难度用如式(3)的代价函数描述:
f(a)=g(a)+h(a) (3)
其中,f(a)表示制定动作a的总代价;g(a)表示从当前状态s执行动作a的代价,包括机器人从当前状态前往工具箱更换工具的代价和沿途的位姿扰动代价,该式表示任务总是先完成当前工具所能完成的所有任务;h(a)表示从动作a到期望状态的代价,该代价由松弛的规划图算法计算得到,具体表现为松弛规划图算法求解得的动作数目m,该式表示总是得到与期望状态最近的动作;
步骤3:扩展规划图。根据步骤1中建立的动作模型,利用规划图算法从初始状态开始向期望状态扩展,得到前提条件属于当前状态的可用动作A(s
步骤4:选择代价最小的动作a
步骤5:利用动作a
步骤6:重复步骤3~5,直至新的世界状态s
实施例1:
步骤1:建立空间辅助操作任务的数学模型。具体实施过程中,针对美国的RRM3(Robotic Refueling Mission3)项目,设计了的空间辅助操作任务背景:在卫星离开地面之前,技术人员通过一个阀门将油箱加满,然后将阀门三重密封并盖在保护装置上。因而具体实施时,针对性的设置了以下四种复杂动作:拧开(screw)、开盖(uncover)、插入(insert)和输入燃料(refuel),并采用简单动作移动来连接以上复杂动作,后续通过分解移动动作得到具体的移动、抓取和释放序列。根据公式(1)和公式(2)定义动作模型,动作模型的定义方式如式(4)所示:
动作模型主要包括四个部分,actionName表示动作的名称;parameters表示与动作有关的所有参数,?v
采用PDDL描述以上动作的领域(domain)文件和问题(problem)文件,文件中设计的动作模型如图5所示。
步骤2:构建启发式函数。针对步骤1中建立的动作模型,构建启发式函数计算每个动作模型的代价值。对于上述空间辅助操作任务来说,涉及多个动作且动作之间的工具各不相同,因而在任务规划过程中需要考虑移动代价和工具切换代价g(a),该代价的计算方式分别为:空间机器人移动带来的卫星位姿扰动以及每切换一次工具就会多代价c。此外,在任务规划过程中,还考虑了各个动作与期望状态间的距离h(a),该距离由松弛的规划图算法计算得到,具体表现为从当前动作到期望状态多需要的动作数目,如式(6)所示,目的为选取从当前动作到期望状态动作总数最少的动作。综上所述,最终的代价函数构建为如式(5)所示:
f(a)=g(a)+h(a)(5)
其中,
其中,α β γ分别表示空间机器人末端的俯仰、偏航和滚转角度,angle
步骤3:扩展松弛的规划图。相较于规划图算法,松弛的规划图算法忽略了动作间的互斥关系,从初始状态开始,通过前向搜索的方式逐层扩展,并得到每一层的状态s
A(s
步骤4:选择代价最小的动作a
步骤5:利用动作a
步骤6:重复步骤3~步骤5,直至新的世界状态s
最后通过仿真验证了本发明所提出面向空间辅助操作任务的快速前向搜索任务规划的方法。针对空间辅助操作中的空间加注任务进行了仿真,经过仿真可以得到操作难度最小的动作序列,得到的复杂动作序列如图2所示。此外,基于分层的思想,利用基础快速前向搜索算法最终分解得到的动作序列如图3所示,对于无顺序要求的动作。例如butt1和butt2,没有代价函数评价时会导致任务规划得到的动作序列随机,不满足空间机器人辅助操作过程中能量最小的约束。利用改进快速前向搜索算法最终分解得到的动作序列如图4所示,可以看到得到的动作序列满足能量最小的约束,部分序动作的顺序根据代价值的大小而确定。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。
- 面向人机协作搜索识别多目标任务的机器人运动规划方法
- 面向人机协作搜索识别多目标任务的机器人运动规划方法