基于多分支样本选择的跨被试脑电情绪识别方法及系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于跨被试脑电信号处理技术领域,具体涉及一种基于多分支样本选择的跨被试脑电情绪识别方法及系统。
背景技术
情绪是人们在日常生活和人际交往中受到外界因素作用而产生的一种生理信号,它不仅可以反映人们在当前情景下的心理状态,同时也会左右人们的认知决策和行为表现。人们可以通过自己以往的经验认知来理解其他人的情绪,但是计算机很难同人一样准确地理解情绪。如果计算机也可以和人一样准确地识别情绪,那么其在医疗、教育和人机交互等领域会具有很大的应用价值。目前识别情绪的信号种类繁多,包括面部表情、语音和脑电信号等。相比于面部表情和语音,脑电信号更能客观反映人的情绪状态,而且不容易伪装。因此,基于脑电信号的情绪识别受到越来越多研究者的关注。研究者们也希望借助深度学习等人工智能的方法来辅助计算机理解人们的情绪,这对于各个领域的情绪识别应用具有重要价值。
虽然脑电信号可以准确地、客观地识别人类情绪,但是它的非平稳性导致传统的脑电情绪识别模型不具有良好的普适性。即不同被试之间的脑电数据存在分布差异,导致在某些被试上训练得到的良好的脑电情绪识别模型在新被试脑电数据上的识别准确性较低。现有研究提出了一系列跨被试脑电情绪识别方法来解决该问题,他们将多个被试的有标签样本看作源域,新被试的无标签样本看作目标域,然后引入迁移学习的思想以减小源域和目标域的分布差异,使得在源域上训练得到的模型也适用于目标域。例如,Fahimi等人组合多个被试的有标签脑电数据作为源域,并在源域上训练一个卷积神经网络(Convolution Neural Network,CNN)模型,然后使用目标域的无标签数据对该模型进行微调校准,结果显示该方法有效提升了模型的普适性。李等人提出了一种联合分布对齐方法,通过引入对抗学习策略以同时减少源域和目标域在浅层网络中的边缘分布和这两个域在深层网络中的条件分布差异。李等人在传统的脑电情感识别模型中引入了深度自适应网络(Deep Adaptation Network,DAN),主要通过缩小最大平均差异(Maximum MeanDiscrepancy,MMD)来减小源域和目标域之间的分布差异。
虽然上述脑电情绪识别方法在跨被试场景下都提升了性能,但是这些方法仍然存在一定局限性。他们把多个被试的脑电数据合并成一个大源域,然后进行大源域和目标域之间的情绪知识迁移。这种方式只考虑了源域和目标域之间的数据分布差异,而忽视了大源域中不同被试之间的数据分布差异。然而,考虑不同被试之间的差异是有必要的,因为不同被试对相同情绪的反应不同,甚至会出现截然不同的情绪反应。如果不考虑被试之间的差异而是进行盲目迁移则会导致情绪识别分歧。另外,以往的方法都是笼统地把源中所有样本都用于训练,但没有考虑源域中脑电样本对目标域脑电样本情绪识别的贡献程度不同。
发明内容
本发明的目的在于针对现有技术的不足提出一种基于多分支样本选择的跨被试脑电情绪识别方法及系统。
第一方面,本发明提供一种基于多分支样本选择的跨被试脑电情绪识别方法,其包括以下步骤:
步骤1、脑电信号数据的采集。
采集多个不同的被试者带情绪类别标签的脑电数据;每个被试者的脑电数据及其标签数据作为一个源域。对被情绪识别的对象进行脑电信号采集,得到的脑电数据作为目标域。
步骤2、对源域和目标域的脑电信号进行预处理和特征提取。
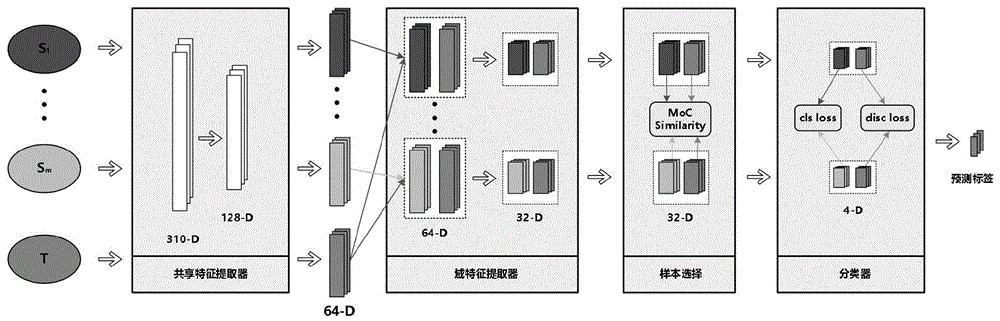
步骤3、构建多分支样本选择的情绪识别模型。情绪识别模型包括共享特征提取模块SFE、域特征提取器DFE、样本选择模块和分类器,且具有m个分支;每个分支均对应一个分类器。m为源域的数量。
步骤3-1.共享特征提取模块SFE提取源域和目标域的低层特征信息。
步骤3-2.目标域与每个源域的低层特征信息均组成一个输入对数据;每个输入对数据均对应情绪识别模型的一个分支;域特征提取器DFE对输入对数据进行提取,得到各输入对数据对应的域特征信息。
步骤3-3.样本选择模块基于各目标域中每个样本与各源域中样本的相似度,获得MoC损失
步骤3-4.利用m个分支对应的分类器对于m个源域分别进行预测,利用各源域对应的预测标签和真实标签,获得分类误差
步骤3-5.建立情绪识别模型的总损失函数
其中,α和β为情绪识别模型的超参数。
步骤3-6.基于总损失函数
步骤4、将目标域分别输入m个分类器,取m个分类器所得识别结果的平均值作为被测对象的情绪类别。
作为优选,所述的情绪类别包括中性、开心、伤心和悲伤。带情绪类别标签的脑电数据的采集过程如下:将向被试者展示具有不同情绪偏向的电影片段,并通过脑电采集设备记录被试的脑电信号,电影片段对应的情绪偏向作为情绪类别标签。
作为优选,步骤2中进行预处理和特征提取的过程为:将脑电数据下采样至200Hz采样率,再使用1Hz至75Hz之间的带通滤波器进行处理。提取所得脑电信号在Delta、Theta、Alpha、Beta、Gamma频段的微分熵特征,作为脑电特征信息。
作为优选,共享特征提取模块SFE由多层线性网络组成,能够将脑电信号特征从310维降到64维。
作为优选,同一输入对数据对应的源域和目标域共用同一个域特征提取器DFE。不同的输入对数据对应的域特征提取器DFE的参数不同。
作为优选,步骤3-3中,样本选择模块针对目标域中每个样本,分别在同一源域中选取出与其相似度最大的样本,由此构建MoC损失
其中,n
作为优选,所述的域特征提取器DFE由两层线性网络组成的,能够将脑电信号特征从64维降到32维。
作为优选,步骤3-4中的分类误差
其中,J(·)表示的是交叉熵函数。
作为优选,步骤3-4中的差异损失
其中,
第二方面,本发明提供一种基于多分支样本选择的跨被试脑电情绪识别系统,其用于执行前述的跨被试脑电情绪识别系统;其包括脑电采集模块和情绪识别模块。脑电采集模块用于进行源域和目标域的脑电信号采集;情绪识别模块包括共享特征提取模块SFE、域特征提取器DFE、样本选择模块和分类器,且具有m个分支;每个分支均对应一个分类器。m为源域的数量。情绪识别模块用于对目标域对应的被测对象的情绪类别进行识别。
本发明具有以下有益效果:
1、本发明提出的基于多分支样本选择的跨被试脑电情绪识别方法为计算机识别人类情绪提供了一种高效的工具。通多构建多分支的网络框架,两两组合源域和目标域,从不同分支中单独学习特定域的特征,充分考虑了不同域之间的差异性,减少了不同被试之间的分布差异,使得模型可以顺利地迁移到新的被试上,更加具有普适性。
2、本发明要解决的是脑电情绪识别领域中比较困难的跨被试脑电情绪识别问题,具体为通过构建多分支的网络结构,从不同源域被试中选择与目标域相似的样本,这样的做法充分利用了域中样本之间信息,选择出来的样本与目标域样本也更加的接近,可以使训练得到的模型更加适用于目标域被试。
附图说明
图1为本发明的系统框架示意图。
具体实施方式
以下结合附图对本发明作进一步的解释说明。
如图1所示,基于多分支样本选择的跨被试脑电情绪识别方法,具体包括以下步骤。
步骤1、脑电信号数据的采集。
通常情况下,人们的情绪并不会表现的特别明显,只有当接受强烈的外界刺激时才会产生明显的情绪。为了使采集到的脑电信号具有明显的情绪偏向,本实施例选择四种具有明显情绪偏向(中性、开心、伤心、悲伤)的电影片段给被试者观看,当被试者在观看电影片段时大脑会产生相应的情绪。此时,通过脑电采集设备记录被试的脑电信号作为原始的脑电情绪数据集。本实施例中分别在三个不同时段进行情绪脑电采集实验,每次数据采集实验都有14名被试参与。本实施例对每个时段采集的脑电数据进行跨被试脑电情绪识别研究。在每个时段中,14名被试者的有标签脑电样本分别作为14个源域,表示为
多个源域的建立,在实际检测前预先完成;并且,各源域适用于不同的被测者;故更换被测者时不需要重新建立源域数据。对需要进行被测者情绪识别的使用者进行脑电数据采集,得到无标签脑电样本组成的目标域,表示为D
步骤2、脑电信号的预处理和特征提取。
由于步骤1采集到的是原始的脑电信号数据,其包含大量的噪声和伪影等无关信息,因此本实施例需要对原始脑电信号里的进行预处理。首先,本实施例将原始脑电信号数据下采样至200Hz采样率。为了滤除噪声并消除伪影,使用1Hz至75Hz之间的带通滤波器进行处理。接着,提取脑电信号的微分熵特征(DE),提取到5个频段的脑电特征信息:Delta(1-4Hz),Theta(4-8Hz),Alpha(8-14Hz),Beta(14-31Hz)和Gamma(31-50Hz)。微分熵公式如下:
其中,x为脑电数据样本;σ为概率密度函数的标准差;μ为概率密度函数的期望。
经过预处理和DE特征提取之后的源域数据和目标域数据分别为
步骤3、基于多分支的网络结构,构建多分支样本选择的情绪识别模型。情绪识别模型包含四个部分,分别为共享特征提取模块SFE、m个域特征提取器DFE、m个样本选择模块和m个分类器C。相互对应的域特征提取器DFE、样本选择模块和分类器C组成情绪识别模型的一个分支;m个分支与m个源域分别对应。
步骤3.1、通过共享特征提取模块SFE提取不同域的低层特征信息,如公式(1)所示。
为第i个源域对应的低层特征信息的第j个元素;/>
共享特征提取模块SFE由三层线性网络组成,用于将脑电信号特征从310维降到64维,从而减少数据维度便于后续学习。需要注意的是,在共享特征提取模块SFE中,里面的参数都是共享的,即所有域不论是有标签的源域还是没有标签的目标域都会经过相同的特征提取模块。
步骤3.2、以一个源域和一个目标域组成一个输入对数据,利用各分支对应的域特征提取器DFE提取对应输入对数据的域特征信息。由于源域不止一个,而目标域只有一个,本实施例把一个源域和一个目标域进行两两组合,m个源域均对应得到m个输入对数据。每个输入对数据对应情绪识别模型的一个分支;本实施例中,m=14;所有输入对数据分别输入到域特征提取器DFE中,得到各源域和目标域的域特征信息,如公式(2)所示。
为第i个输入对数据经过域特征提取器DFE提取出的单独源域特征的第j个元素。/>
本步骤中,借助域特征提取器DFE,从每一个分支中可以学到单独源域的特征,即得到m个分支对应的域特征信息。域特征提取器DFE充分考虑了每一个源域的信息。此外,不同的输入对数据对应的域特征提取器DFE的参数不同,即会有m个不同的域特征提取器DFE;同一输入对数据对应的源域和目标域共用同一个域特征提取器DFE。
需要注意的是,其中域特征提取器DFE由两层线性网络组成的,能够将脑电信号特征从64维降到32维,从而提取更加高维的特征信息。
步骤3.3、构建样本选择模块。样本选择模块利用最大余弦相似度(Maximal ofCosine,MoC)的方法计算目标域中每个样本与同一源域中每个样本的相似度;针对目标域中每个样本,均在同一源域中选取出与其相似度最大的样本,进入下一轮迭代优化;选取出的各源域样本与对应目标域样本计算余弦相似度;取各源域对应的余弦相似度的累加值作为MoC损失
最大余弦相似度函数的作用是衡量源域样本和目标域样本之间的相似度。具体而言,对于每个目标域中的样本,本实施例都利用最大余弦相似度函数从源域中找到与目标域样本最接近的样本。具体的函数定义如公式(4)所示。
其中,||·||
MoC损失
步骤3.4、把从步骤3.2中提取到的源域特征信息分别输入对应的分类器C中。如公式(5)所示。
本步骤中,得到m个分支对应的分类器。由于源域的样本是有标签的,能够计算分类器的分类损失,本实施例中使用交叉熵损失作为所有源域的分类误差
式(5)中,
除此之外,由于有m个分类器,从每个源域得到的分类器都是不完全相同的,每个分类器都具有某个域的相应特征,考虑到不同域之间的差异性,本实施例还引入了不同分支对目标域的预测值之间的差异损失
其中,
通过式(7),本实施例能够使识别结果更加接近,不至于使每个分类器的误差偏移太大。
步骤3.5、综合式(5)、(6)、(7),得到情绪识别模型的总损失函数
式(8)中,α和β为模型的超参数。
重复步骤3.1、3.2、3.3、3.4,不断优化m个分类器C的模型参数。
步骤4、将经过预处理的目标域脑电数据分别输入m个分类器,m个分类器所得识别结果取平均值后作为最终识别出的被测对象的情绪类别如式(9)所示
为证明本实施例的情绪识别效果,将本实施例提供的方法与现有跨被试情绪识别方法进行对比;选择的现有跨被试情绪识别方法为JDA(即joint distributionadaptation)和MS-MDA(即Multisource Marginal Distribution Adaptation);对比结果如下表1所示;
由上述三个表的数据可以看到,本方法的结果与其他的迁移方法相比,识别精度更高。
表1.时段1的跨被试场景下的EEG脑电情绪识别分类准确性(%)
表2.时段2的跨被试场景下的EEG脑电情绪识别分类准确性(%)
表3.时段3的跨被试场景下的EEG脑电情绪识别分类准确性(%)。
- 一种适用于跨被试的脑电情绪识别方法及装置
- 基于半监督领域自适应的跨个体情绪脑电识别方法及系统