基于语义一致性的多无人机协同建图与感知方法及系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于无人机技术领域,涉及一种基于语义一致性的多无人机协同建图与感知方法及系统。
背景技术
建图与感知是无人机技术领域和人工智能领域中的一项重要技术。其通常以即时定位与地图构建(SLAM)技术作为基础,是无人机理解其所在环境的主要技术手段,更是无人机执行包括自主路径规划、飞行控制、行为决策等后续任务的必要前提条件。近年来,随着无人机应用领域的扩展、任务复杂度的增加、及使用场景的扩大,以SVO
多无人机协同建图与感知技术的核心思想是通过无人机群之间的合作与信息共享,实现对目标环境的全面感知和理解。其建图与感知流程如图1所示,每架无人机将搭载诸如激光雷达(LiDAR)、摄像头、深度相机、惯性测量单元(IMU)等各式传感器
多无人机协同建图与感知技术的应用领域十分广泛,适用于一切需要对陌生环境进行探索的任务。以灾害救援
协同SLAM算法在进行整合各无人机所构建的子地图时,需要识别出各个子地图之间重叠的区域,并通过计算重叠区域之间的匹配关系将各个子地图对齐。然而,现有的方法在识别重叠区域时效率十分有限:
文献[8]聚焦在陆地自主机器人协同SLAM。该方法在机器人上装备了二维码以及读取器,当机器人在物理空间相遇时,由二维码读取器检测到了相应二维码作为识别出子地图间重叠区域的信号,并通过机器人相遇时的纹理信息计算子地图之间的相对位姿变换关系。此方法的局限十分明显,得益于陆地机器人场景,其能够保证在大多数情况下两机器人相遇时二维码能够被成功检测出来。然而当无人机群在三维空间中飞行时,由于其运动的自由度相较陆地自主机器人多了一个纬度,故而无法保证每次两无人机相遇时,两机之间的相对位姿关系都处于可以让机身上二维码能够被成功检测到的状态。这样的问题极大的限制了多无人机协同建图与感知的效率。
文献[9]着眼于地空协同感知系统。该方法在三维空间中给不同的位置预先标记具场景识别与位姿估计能力的AprilTag二维码,并给空地无人器上预装相应的识别算法。接着通过无人器检测相同的AprilTag二维码作为识别出子地图间重叠区域的信号,再由该区域的纹理信息计算子地图间的相对位姿变换关系。此方法由于需要预先在三维空间中放置AprilTag二维码,且受限于二维码数量,其能够实际应用的空间十分有限。
文献[10]采用云边协同的方法进行多无人机协同建图与感知。该方法采用ORB-SLAM中二维图像特征点与词袋模型结合的方式对三维空间中的不同位置进行标记,构建三维场景数据库。随后通过将各无人机当前采集的数据与数据库进行对比,判断当前场景与各子地图是否存在重叠,最后通过区域内纹理信息计算相对位姿变换关系,将重叠的子地图进行对齐。该方法虽然摒弃了二维码,但是存在着视角敏感的特性。即,当从不同的角度观测同一个场景时,该方法无法顺利完成检测。因此,该方法在运行时,往往需要多个无人机在相同的一块区域内运行较长的一段距离之后,才能够识别出其对应子地图之间的重叠区域。继而导致大场景中协同感知的效率降低,亦造成计算资源的不必要浪费。
参考文献:
[1]C.Forster,M.Pizzoli and D.Scaramuzza,"SVO:Fast semi-directmonocular visual odometry,"2014IEEE InternationalConference onRoboticsandAutomation(ICRA),HongKong,China,2014,pp.15-22.
[2]M.Sanfourche,B.Le Saux,A.Plyer and G.Le Besnerais,"Environmentmapping&interpretation by drone,"2015 Joint Urban Remote Sensing Event(JURSE),Lausanne,Switzerland,2015,pp.1-4.
[3]J.
[4]P.Schmuck and M.Chli,"Multi-UAV collaborative monocular SLAM,"2017IEEE International Conference on Robotics andAutomation(ICRA),Singapore,2017,pp.3863-3870.
[5]J.Long,E.Shelhamer and T.Darrell,"Fully convolutional networks forsemantic segmentation,"2015IEEE Conference on Computer Vision and PatternRecognition(CVPR),Boston,MA,USA,2015,pp.3431-3440.
[6]K.He,G.Gkioxari,P.Dollár and R.Girshick,"Mask R-CNN,"2017IEEEInternational Conference on ComputerVision(ICCV),Venice,Italy,2017,pp.2980-2988.
[7]S.Lee,D.Har and D.Kum,"Drone-Assisted Disaster Management:FindingVictims via Infrared Camera and Lidar Sensor Fusion,"20163rd Asia-PacificWorld Congress on Computer Science and Engineering(APWC on CSE),Nadi,Fiji,2016,pp.84-89.
[8]M.J.Schuster,C.Brand,H.Hirschmüller,M.Suppa and M.Beetz,"Multi-robot 6Dgraph SLAM connecting decoupled local reference filters,"2015IEEE/RSJInternational Conference on IntelligentRobots and Systems(IROS),Hamburg,Germany,2015,pp.5093-5100.
[9]杨毅,朱敏昭.地空协同感知系统[C]//中国惯性技术学会.2018惯性技术发展动态发展方向研讨会文集.[出版者不详],2018:6.
[10]J.Xu,H.Cao,Z.Yang,L.Shangguan,J.Zhang,X.He andY.Liu,"SwarmMap:Scaling Up Real-time Collaborative Visual SLAM at the Edge,"19th USENIXSymposium on Networked Systems Design and Implementation(NSDI 22),Renton,WA,USA,2022,pp.977-993.
发明内容
本发明的目的是针对现有技术的不足,提出一种基于语义一致性的多无人机协同建图与感知方法及系统,旨在使用环境中的语义物体,利用其所具备的视角一致性提高子地图间重叠区域的检出效率,继而提升协同建图与感知的效率。
本发明为了解决多无人机协同建图与感知技术中,各无人机所构建的子地图在融合时重叠区域检测效率低、检测正确率低的问题,提出了一种基于语义信息一致性的多无人机子地图高效融合方法。
第一方面,本发明提供一种基于语义一致性的多无人机协同建图与感知方法,所述方法包括:
步骤(1)、多模态数据预处理
对无人机机载传感器所采集到的多模态数据进行预处理,转化为统一相机坐标系下的多模态数据;对预处理后的多模态数据进行融合,获得三维感知数据,即彩色三维点云与RGB-D图像;其中所述多模态数据包括三维点云、彩色图像和深度图像;
步骤(2)、单机位姿估计与子地图构建
采用点到面迭代最邻近点的方法实现各无人机的实时位姿估计,并使用该位姿将无人机各个时刻所采集的彩色三维点云放置到统一无人机坐标系下,以彩色三维点云的形式构建子地图;
步骤(3)、单机语义信息提取与语义子地图构建
S3-1采用预训练的深度卷积网络从RGB-D图像中彩色图像提取语义物体信息;
S3-2根据步骤(1)的激光雷达、摄像头与深度相机之间的外参M以及摄像头和深度相机的内参K,从彩色三维点云中标记出与彩色图像检测结果对应的语义物体信息,以给每个三维点添加语义标签的形式构建语义子地图,并根据语义子地图中各语义物体的三维空间位置构建语义拓扑图;
步骤(4)、多机子地图匹配与融合;具体是:利用语义信息的全局一致性特点,通过寻找语义信息间的匹配关系将各个无人机所构建的语义子地图关联起来,融合成为全局语义地图。
步骤(5)、全局语义拓扑图与多机轨迹联合优化,通过全局语义拓扑图上增加无人机位姿节点,构建全局因子图,再使用图优化方法实现联合优化。
作为优选,步骤(1)中,所述预处理采用张正友标定法。所述无人机机载传感器包括激光雷达、摄像头和深度相机。
作为优选,步骤(2)具体是:
S2-1假设无人机i在当前时刻所观测到的彩色三维点云p
其中T表示待优化的无人机位姿,T
在优化时,以无人机i上一时刻估计的位姿T
S2-2使用无人机i的当前位姿T
作为优选,步骤S3-2具体是:
使用预训练好的深度卷积网络从无人机i的当前观测彩色图像中提取语义物体的掩码并识别语义物体的类别,即实例分割;
使用步骤(1)摄像头和深度相机的内参K,通过反向投影技术三维点云与激光雷达的点云融合,获得带有语义标签的分割三维点云;
将各个语义物体视为一个整体,构建语义拓扑图;
作为优选,步骤S3-2中语义拓扑图的构建具体是:
计算各个语义物体实例中的所有点的平均值,并将其作为语义拓扑图的节点;最后,以坐标平均值代表整个语义物体,并计算两两间的欧氏距离作为语义拓扑图的边;
作为优选,步骤(4)具体是:以从语义拓扑图提取到的成对几何位置关系作为依据,搜索当前无人机所观测到的多模态数据与所有无人机的语义子地图之间的匹配关系;当无人机i的当前观测数据与无人机j所构建的子地图之前存在匹配关系时,采用由粗略到精确的配准方法,计算无人机i与j所构建的子地图之间的相对位姿变换,继而将无人机i和j的运行轨迹以及其构建的子地图置于统一坐标系下;最后通过语义物体标签融合,实现两个语义子地图的融合,构建全局语义地图以及全局语义拓扑图;具体是:
S4-1根据语义标签信息,寻找无人机i所构建的语义拓扑图与其他无人机构建的所有语义拓扑图之间的潜在匹配关系,即所有具有相同语义标签的物体均为潜在匹配;
S4-2利用语义拓扑图中的边,计算两个无人机的语义拓扑图中所有成对的语义物体之间的几何位置一致性,继而构建邻接矩阵A:
其中A
S4-3确定匹配关系
通过对邻接矩阵A进行特征值分解,然后对特征值进行判断:当邻接矩阵A主特征值的模小于预设阈值τ时,则认为当前两张语义拓扑图间不存在匹配;反之,则认为当前两张语义拓扑图间存在匹配,并将主特征值所对应的主特征向量作为两张语义拓扑图之间的匹配关系;
S4-4根据语义子地图之间的位姿变换关系构建全局地图
两张语义拓扑图对应的语义子地图之间的位姿变换关系
S4-5根据匹配关系构建全局语义拓扑图
将无人机i与j构建的语义拓扑图中具有匹配关系的节点以对语义物体大小加权平均的方式融合为全局语义拓扑图的单一节点,无人机i构建的语义拓扑图中两个节点间的边与无人机j构建的语义拓扑图中两个节点间的边以对语义物体质心间欧式距离加权平均的方式融合为全局语义拓扑图的单一边,最终得到所需的全局语义拓扑图;
作为优选,步骤(5)具体是:
S5-1通过在全局语义拓扑图上增加各无人机位姿节点;
S5-2构建无人机各时刻的约束关系,包括无人机与语义物体之间的观测约束关系和无人机各时刻之间的位姿约束关系,所述无人机与语义物体之间的观测约束即为无人机i与语义物体l之间的欧式距离;
S5-3将步骤S5-1处理后的所有节点、步骤S5-2构建的无人机各时刻的约束关系、步骤(4)构建的全局语义拓扑图结合,构建完整的因子图;
S5-4使用列文伯格-马夸尔特法对因子图进行全局联合优化。
第二方面,本发明提供实现上述方法的多无人机协同建图与感知,包括:
多模态数据预处理模块,对无人机机载传感器所采集到的多模态数据进行预处理,转化为统一相机坐标系下的多模态数据;对预处理后的多模态数据进行融合,获得三维感知数据,即彩色三维点云与RGB-D图像;其中所述多模态数据包括三维点云、彩色图像和深度图像;
单机位姿估计与子地图构建模块,采用点到面迭代最邻近点的方法实现各无人机的实时位姿估计,并使用该位姿将无人机各个时刻所采集的彩色三维点云放置到统一无人机坐标系下,以彩色三维点云的形式构建子地图;
单机语义信息提取与语义子地图构建模块,采用深度卷积网络从RGB-D图像中彩色图像提取语义物体信息;从彩色三维点云中标记出与彩色图像检测结果对应的语义物体信息,以给每个三维点添加语义标签的形式构建语义子地图,并根据语义子地图中各语义物体的三维空间位置构建语义拓扑图;
多机子地图匹配与融合模块,利用语义信息的全局一致性特点,通过寻找语义信息间的匹配关系将各个无人机所构建的语义子地图关联起来,融合成为全局语义地图;
全局语义拓扑图与多机轨迹联合优化模块,通过全局语义拓扑图上增加无人机位姿节点,构建全局因子图,再使用图优化方法实现联合优化。
第三方面,本发明提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行所述的方法。
第四方面,本发明提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的方法。
相比于现有技术,本发明提出基于语义物体成对几何关系的匹配技术技术,充分利用语义物体跨视角一致性特点,能够实现在有限的观测帧范围内,提升无人机识别出机群内其他无人机已经构建过的地图区域的成功率,避免多架无人机在相同区域重复建图所带来的资源浪费问题,极大的提升了多无人机在陌生环境协同建图与感知的效率。
附图说明
图1.多无人机感知信息处理概图;
图2.基于语义信息一致性的多无人机子地图高效融合方法流程图;
图3.无人机机载传感器标定;
图4.单机SLAM-位姿地图交替更新策略;
图5.单机语义拓扑图构建方法概图;
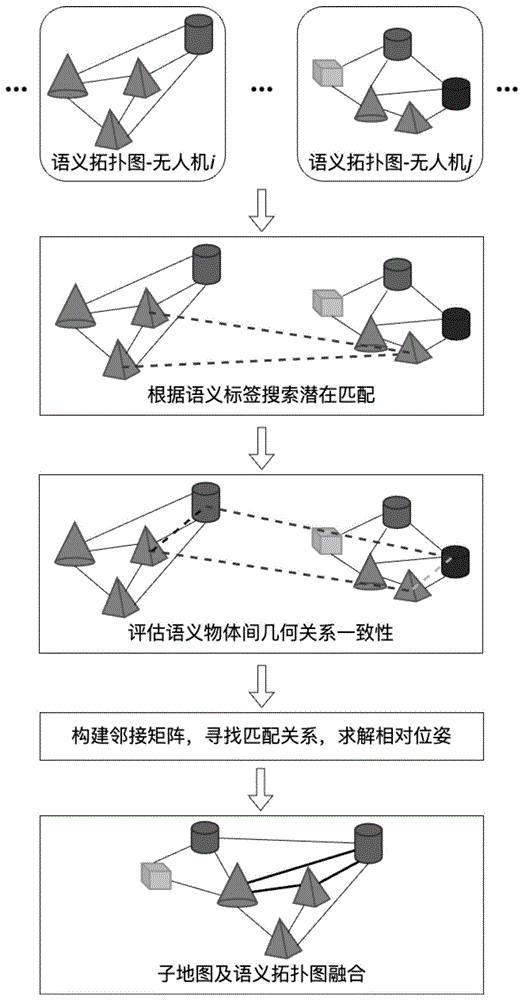
图6.基于语义物体一致性的多机子地图融合方法;
图7.语义物体级别的语义地图与多机轨迹联合优化方法。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行详细描述。当然,此处描述的实施例仅为本发明使用的众多实施方式的其中之一。
本发明一种基于语义一致性的多无人机协同建图与感知方法总共分为5个步骤,如图2所示。其中步骤1、2、3为各无人机独立运行模块;步骤4、5为多无人机间交互运行模块。
1.无人机多模态数据融合
本发明适用于任何配备有激光雷达(LiDAR)、摄像头和深度相机的多旋翼无人机。如图3所示,使用张正友标定法,能够实现激光雷达、摄像头与深度相机之间的外参M校正以及摄像头和深度相机的内参K校正,将多模态数据转化为统一相机坐标系下。继而经由多模态数据融合获得任一时刻无人机载传感器所测量到的三维感知数据,即彩色三维点云与RGB-D图像。
2.单机位姿估计与子地图构建
本发明采用点到面迭代最邻近点(Point-to-Plane ICP)的方法实现各无人机的实时位姿估计,并使用该位姿将无人机各个时刻所采集的三维点云放置到统一无人机坐标系下,以三维点云的形式构建子地图,整体流程如图4所示。
3.单机语义信息提取与语义子地图构建
本发明如图5所示,采用预训练的深度卷积网络(如YOLOv8,Mask R-CNN等)从RGB-D图像的彩色图像中提取语义物体信息,再根据标定好的内参与外参信息从彩色三维点云中标记出与彩色图像检测结果对应的语义物体信息,以给每个三维点添加语义标签的形式构建语义子地图,并根据各语义物体的三维空间位置构建语义拓扑图。
4.多机子地图匹配与融合
如图6所示,本发明以语义物体间的成对几何位置关系作为依据,搜索当前无人机所观测到的数据与所有子地图之间的匹配关系。当无人机i的当前观测数据与无人机j所构建的子地图之前存在匹配关系时,本发明采用由粗略到精确的配准方法,计算无人机i与j所构建的子地图之间的相对位姿变换,继而将无人机i和j的运行轨迹以及其构建的子地图置于统一坐标系下。最后通过语义物体标签融合,实现两个语义子地图的融合,构建全局语义地图以及全局语义拓扑图。
5.全局语义地图与多机轨迹联合优化
如图7所示,本发明在全局语义拓扑图上,将各个被检测出的语义物体是为一个整体,通过语义物体与无人机之间的观测关系、以及无人机各时刻之间的位姿约束关系进行多无人机位姿与语义物体空间位置的联合优化。
结合图3到图7对以下实施例进行说明,一种基于语义一致性的多无人机协同建图与感知技术,具体包括了以下五大模块:1.多模态数据融合、2.单机位姿估计与子地图构建、3.单机语义信息提取与语义子地图构建、4.多机子地图匹配与融合、5.全局语义地图与多机轨迹联合优化。
1.多模态数据融合主要用于对无人机机载传感器所采集到的多模态数据进行预处理,通过如图3所示标定方法将各模态数据置于统一的相机坐标系下,并转化为统一的模态,作为后续模块的输入。首先,针对深度相机,本发明采用张正友标定法,即利用黑白棋盘格标定板,将世界坐标系固定在棋盘格上。由于棋盘格上的每个格子物理尺寸均为已知,可以计算出棋盘格上每个格子的物理尺寸与成像中像素尺寸的关系,继而完成对深度相机内参的标定工作。
此外,通过标准黑白棋盘格上十分明显的角点特征,本发明从激光雷达所观测的三维点云P
其中p
最后使用绝对定向(absolute orientation)方法,对式(2)优化目标函数通过奇异值分解一步求解计算出激光雷达、摄像头与深度相机之间的外参M。
2.单机位姿估计与子地图构建主要通过SLAM技术,通过如图4交替更新的策略完成单一无人机位姿估计与对齐周围环境进行建图的任务。具体来说,以无人机i为例,假设其在当前时刻所观测到的三维点云是p
在优化时,本发明以无人机i上一时刻估计的位姿T
随后,本发明使用无人机i的当前位姿T
3.单机语义信息提取与语义地图构建模块是语义感知的核心模块,它使用深度卷积网络来提取语义信息。此将语义信息不仅可以添加到地图中,由此获得高级别语义地图;还可以为子地图匹配提供信号。如图5所示,本发明首先使用预训练好的深度卷积网络(如YOLOv8,Mask R-CNN等)从无人机i的当前观测彩色图像中提取语义物体的掩码并识别语义物体的类别,即实例分割。随后,使用多模态数据融合模块中计算的摄像头和深度相机的内参K,本发明通过反向投影技术三维点云,通过与激光雷达的点云融合,获得带有语义标签的分割三维点云。最后,将各个语义物体视为一个整体,构建语义拓扑图。具体来说,本发明计算各个语义物体实例中的所有点的平均值,并将其作为语义拓扑图的节点。最后,本发明以坐标平均值代表整个语义物体,并计算两两间的欧氏距离作为语义拓扑图的边。
4.多机子地图匹配与融合模块利用语义信息的全局一致性特点,通过寻找语义信息间的匹配关系将各个无人机所构建的子地图关联起来,融合成为全局语义地图。如图6所示,本发明首先根据语义标签信息,寻找无人机i所构建的语义拓扑图与其他所有无人机构建的语义拓扑图之间的潜在匹配关系(图中仅以无人机j为例),即所有具有相同语义标签的物体均为潜在匹配。
接着,利用语义拓扑图中的边,本发明计算两张语义拓扑图,所有成对的语义物体之间的几何位置一致性,继而构建邻接矩阵A:
其中,邻接矩阵为方阵,它的行数对应了无人机i所构建的语义拓扑图与无人机j所构建的语义拓扑图中中所有的潜在匹配。r,c分别表示邻接矩阵中的行号和列号,同时对应了第r对潜在匹配与第c对潜在匹配。
随后,通过对邻接矩阵A进行特征值分解,本发明首先对特征值进行判断,当邻接矩阵主特征值的模小于预设阈值τ时,则认为当前两张语义拓扑图间不存在匹配;反之则认为当前两张语义拓扑图间存在匹配,并将主特征值所对应的主特征向量作为两张语义拓扑图之间的匹配关系。
最后,两张语义拓扑图对应的子地图之间的位姿变换关系
将无人机i与j构建的语义拓扑图中具有匹配关系的节点融合为全局语义拓扑图的单一节点,无人机i构建的语义拓扑图中两个节点间的边与无人机j构建的语义拓扑图中两个节点间的边融合为全局语义拓扑图的单一边,最终得到所需的全局语义拓扑图;
5.全局语义地图与多机轨迹联合优化主要通过全局语义拓扑图上增加无人机位姿节点,构建全局因子图,再使用图优化方法实现联合优化。如图7所示,通过在全局语义拓扑图的基础上,增加各无人机位姿节点;无人机与语义物体之间的观测约束关系,即无人机i与语义物体l之间的欧式距离;无人机各时刻之间的位姿约束关系;观测约束关系、位姿约束关系结合增加节点后的全局语义拓扑图所有节点,以及全局语义拓扑地图,构建完整的因子图。最后使用列文伯格-马夸尔特法对因子图进行全局联合优化。
- 卫星拒止环境下多无人机分布式协同定位与建图方法
- 卫星拒止环境下多无人机分布式协同定位与建图方法