基于深度元学习的无参考光场图像质量评估方法及系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及图像处理技术领域,具体地,涉及一种基于深度元学习的无参考光场图像质量评估方法及系统,同时提供了一种相应的计算机终端及计算机可读存储介质。
背景技术
随着沉浸式多媒体技术和虚拟现实技术的发展,光场技术已经成为计算视觉领域的一个研究热点,近年来吸引了许多相关研究人员的关注。由于光场是空间中的光的集合,通过获取和显示光场图像可以直观地再现三维(3D)世界。由于其丰富的空间和角度信息,光场被广泛用于图像应用中,包括深度估计、重新聚焦、三维重建等。但是,在光场处理的每个环节中,失真效应是不可避免的,这导致了光场内容感知质量的下降。为了指导和监督光场图像(LFI)的获取、处理和应用,设计一个符合人类视觉系统的光场图像质量评估(LFIQA)模型至关重要。
然而,现有的光场图像质量评估模型大多是基于传统的机器学习来手动提取特征,再通过质量回归模型(比如支持向量机(SVR))来将输入的图像特征映射到其质量分数上。虽然效果很好,但是并没有实现全自动的客观评估,没有带来很多便利。同时,研究发现,使用深度卷积神经网络的图像质量评估已经在低维图像评估模型上得到了很好的效果。不幸的是,LFIQA是一个小样本问题,大多数光场数据集包含的图像内容相对较少。因此,大多数现有的基于深度学习的图像质量评价(IQA)模型不能很好地适应高维的LFIQA模型,导致在评估不同类型的失真时容易出现欠拟合或过拟合问题。而且不少IQA模型没有考虑到光场图像信息极为丰富的特点,没有将其空间信息和角度信息都结合在一起进行评估,导致在评估某些由重建等破坏角度信息的扭曲时,不能达到很好的效果。同时,由于图像质量评估需要依赖于人眼识别,因此模型是否符合人眼视觉特效也特别重要,有些模型并没有很好的结合人眼识别特性进行图片质量评估,因此它们的效果达不到一定的高度。
经过检索发现:
公开号为CN115937064A的中国发明专利申请《一种基于空间和角度测量的光场图像质量评价方法》,包括:采用多频带局部二值模式算法从4维光场图像的子孔径图像阵列中提取光场图像的空间特征;利用基于熵加权局部相位量化的特征提取算法提取4维光场图像的微透镜图像阵列的特征作为光场图像的角度特征;将所述光场图像的空间特征和所述光场图像的角度特征进行特征融合得到一维特征向量;对所述一维特征向量进行支持向量回归池化操作后得到光场图像的质量分数,本发明通过对子孔径图像和宏像素分别进行特征提取以有效地量化光场图像的空间质量和角度一致性,避免了光场图像的质量受空间质量和角度一致性制约的问题。该方法仍然存在如下技术问题:
该方法仍然采用传统的手工提取特征的方法,手动提取特征之后还需要用支持向量回归机等回归手段映射到图像的质量分数上。
该方法对不同扭曲类型图像没有很好的适应性,可能导致在某些扭曲评分上较低。
发明内容
本发明针对现有技术中存在的上述不足,提供了一种基于深度元学习的无参考光场图像质量评估方法及系统。
根据本发明的一个方面,提供了一种基于深度元学习的无参考光场图像质量评估方法,包括:
分别构建包含无参考光场图像质量评估任务的训练集和包含目标评估任务的测试集;
构建包含Swim Transformer网络结构的深度元学习模型;
基于所述训练集,学习失真的先验知识,得到质量先验模型;
在测试集上对所述质量先验模型进行微调,得到最终的光场图像质量评估模型;
利用所述光场图像质量评估模型对待评估光场图像进行光场图像质量评估。
优选地,所述分别构建包含无参考光场图像质量评估任务的训练集和包含目标评估任务的测试集,包括:
将光场图像根据其失真类型划分为多个无参考光场图像质量评估任务,用于构建训练集;其中,在同一个数据集中,具有相同失真类型的光场图像划分成一组,每一组作为一种光场图像质量评估任务;
将未知失真类型的光场图像作为目标评估任务,用于构建测试集;
将作为无参考光场图像质量评估任务的光场图像和作为目标评估任务的光场图像分别转化成MacPI模式,得到无参考光场图像质量评估所需的训练集和测试集。
优选地,所述构建包含Swim Transformer网络结构的深度元学习模型,包括:
构建Swim Transformer网络和全连接层网络;其中:
所述Swim Transformer网络,包括:依次连接的PatchEmbed模块、四个basicLayer模块和一个Linear层;其中,前三个basicLayer模块均包括Swin Transformer block子模块和Patch Merging子模块,第四个basicLayer模块包括Transformer block子模块;最后连入全连接层;
所述PatchEmbed模块用于将维度为H x W x C的输入光场图像分成N个大小为P*P*C的patch,再将其展平,其中
所述Patch Merging子模块用于在每一个所述swin Transformer block子模块后降低图片分辨率,调整通道数,形成层次化的图像;
所述全连接层网络用于将所述Swim Transformer网络输出的图像的特征映射到输出结果,最后输出的值即为光场图像的预测质量分数值。
优选地,前三个所述basicLayer模块中的Swin Transformer block子模块的个数分别为2、2和18。
优选地,第四个所述basicLayer模块中的Transformer block子模块为2个。
优选地,所述全连接层网络包括3层全连接层,所述Swim Transformer网络输出的图像通过3层全连接层将光场图像的特征逐层映射到最终的输出结果中,最后输出的值即为光场图像预测的质量分数值。
优选地,所述基于所述训练集,学习失真的先验知识,包括:
将训练集中的光场图像x作为输入,依次经过Swim Transformer网络和全连接层网络,生成输出值
式中,θ是初始化的模型参数,f
采用平均平方误差(MSE)损失函数
式中,n为每个任务中的输入图像数量,i为当前输入图像;
将光场图像数据集中不同失真类型的无参考光场图像质量评估任务划分为训练集
采用Adam优化器在支持集
当前模型参数θ
式中,θ
式中,β
采用Adam优化器在查询集
将光场图像数据集中K个无参考光场图像质量评估任务的更新梯度进行迭代,获得的最终的模型参数θ为:
θ
优选地,所述在测试集上对质量先验模型进行微调,包括:
从测试集中划分出M个带有质量分数值的光场图像作为训练样本;
采用平均平方误差损失函数最小化光场图像的预测质量分数
采用Adam优化器更新质量先验模型的网络参数,对所述质量先验模型进行微调,得到具有最佳预测质量分数
根据本发明的另一个方面,提供了一种基于深度元学习的无参考光场图像质量评估系统,包括:
数据集构建模块,该模块用于分别构建包含无参考光场图像质量评估任务的训练集和包含目标评估任务的测试集;
模型构建模块,该模块用于构建包含Swim Transformer网络结构的深度元学习模型;
模型元训练模块,该模块基于所述训练集,学习失真的先验知识,得到质量先验模型;
模型微调模块,该模块用于在测试集上对所述质量先验模型进行微调,得到最终的光场图像质量评估模型;
质量评估模块,该模块利用所述光场图像质量评估模型对待评估光场图像进行光场图像质量评估。
根据本发明的第三个方面,提供了一种计算机终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时可用于执行上述中任一项所述的方法,或,运行上述中任一项所述的系统。
根据本发明的第四个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行上述中任一项所述的方法,或,运行上述中任一项所述的系统。
由于采用了上述技术方案,本发明与现有技术相比,具有如下至少一项的有益效果:
本发明告别传统的手动提取图像特征的机器学习方法,采用机器学习领域中的深度学习技术,通过学习样本图像数据的内在规律和表示层次,在学习过程中获得对图像数据的解释信息,像机器人一样能够自主实现所需要的性能。由于采用了深度学习方案,可以实现全自动学习光场图像扭曲的知识,对扭曲图像做评估,解决传统机器学习手工提取特征的不便利性。
本发明采用深度元学习模型,解决光场图像的小样本特性在深度学习中带来的过拟合或者欠拟合问题,同时对不同失真类型的图像有较好的泛化能力。由于采用了元学习,可以实现对光场图像中各种扭曲的质量评估,解决光场数据集小样本特性在深度学习时可能产生的拟合问题,以及对各种不同扭曲的不适应性。
本发明将输入的图像转化成MacPI(宏像素图像)模式,MacPI是固定一个空间信息和角度信息构成的,能很好的结合两者信息,使得信息提取更为全面。由于采用了MacPI模式,可以使得光场图像的空间和角度信息很好的结合起来,解决模型因为忽略了图像角度信息导致在某些角度扭曲的评估过程中达不到很好的效果。
本发明加入Swim Transformer网络结构,其注意力机制特性使得模型符合人眼视觉特性,大大提高了实验效果。由于采用了Swim Transformer网络结构,可以使得评估效果符合人眼视觉特性,解决模型因不符合人眼视觉特性导致结果不符合实际或者性能低。
本发明采用了深度学习方案,可以实现全自动学习光场图像扭曲的知识,对扭曲图像做评估,解决传统机器学习手工提取特征的不便利性。
本发明采用了元学习,可以实现对光场图像中各种扭曲的质量评估,不会产生因为扭曲类型带来的不适应性。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明一优选实施例中基于深度元学习的无参考光场图像质量评估方法的工作流程图。
图2为本发明一优选实施例中基于深度元学习的无参考光场图像质量评估方法的工作原理图。
图3为本发明一优选实施例中Swim Transformer网络的结构示意图。
图4为本发明一实验结果散点图;横坐标为模型预测的质量分数,纵坐标为主观评估值。其中,(a)为Win5-LID数据集的测试结果,(b)为SHU数据集的测试结果,(c)为Win5-LID数据集中不同扭曲类型的测试结果,(d)为SHU数据集中不同扭曲类型的测试结果。
图5为本发明一优选实施例中基于深度元学习的无参考光场图像质量评估系统的组成模块示意图。
具体实施方式
下面对本发明的实施例作详细说明:本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
本发明一实施例提供了一种基于深度元学习的无参考光场图像质量评估(LFIQA)方法,该方法在评估各种失真图像的质量时,参考通过之前的评估任务可以学到失真知识,然后很容易地适应后面的未知失真,该方法通过广泛的实验验证了其在很大程度上优于当前其他先进的LFIQA模型,并对各种扭曲具有良好的泛化能力。
如图1所示,该实施例提供的基于深度元学习的无参考光场图像质量评估方法,可以包括:
S1,分别构建包含无参考光场图像质量评估任务的训练集和包含目标评估任务的测试集;
S2,构建包含Swim Transformer网络结构的深度元学习模型;
S3,基于训练集,学习各种失真的先验知识,得到质量先验模型;
S4,在测试集上对质量先验模型进行微调,得到最终的光场图像质量评估模型;
S5,利用光场图像质量评估模型对待评估光场图像进行光场图像质量评估。
在S1的一优选实施例中,分别构建包含无参考光场图像质量评估任务的训练集和包含目标评估任务的测试集,可以包括:
将光场图像根据其失真类型划分为多个无参考光场图像质量评估任务,用于构建训练集;
将未知失真类型的光场图像作为目标评估任务,用于构建测试集;
将作为无参考光场图像质量评估任务的光场图像和作为目标评估任务的光场图像分别转化成MacPI模式,得到无参考光场图像质量评估所需的训练集和测试集;
其中:
在训练集中,对于同一个数据集中具有相同失真类型的光场图像划分成一组,每一组作为一种光场图像质量评估任务;
在测试集中,数据集中的光场图像实真类型未知。
在该优选实施例中,用于构建训练集和测试集的光场图像数据集,可以包括:
Win5-LID数据集中,扭曲类型有JPEG2000,HEVC,LINEAR,NN以及两种CNN模型,总共六种扭曲。
SHU数据集中,扭曲类型有JPEG2000,JPEG,Gaussian blur,White nosie以及Motion blur,总共五种扭曲。
NBU-LF1.0数据集中,扭曲类型有NNI,BI,EPICNN,Zhang and VDSR,总五种扭曲。
同一数据集中,相同扭曲类型的光场图像划分成一组,每一组作为一种评估任务。模型在其中两个数据集上训练,在另一个数据集中微调测试,例如,在Win5-LID和NBU-LF1.0数据集中训练,在SHU数据集测试;在SHU和NBU-LF1.0数据集中训练,在Win5-LID数据集中测试。作为训练集其任务划分如上述所示;作为测试集,其扭曲类型未知。
在S2的一优选实施例中,构建包含Swim Transformer网络结构的深度元学习模型,包括:
构建Swim Transformer网络和全连接层网络;其中:
Swim Transformer网络,包括:依次连接的PatchEmbed模块、四个basicLayer模块和一个Linear层;其中,前三个basicLayer模块均包括Swin Transformer block子模块和Patch Merging子模块,第四个basicLayer模块包括Transformer block子模块;最后连入Linear层;
PatchEmbed模块用于将维度为H x W x C的输入光场图像分成N个大小为P*P*C的patch,再将其展平,其中
Patch Merging子模块用于在每一个swin Transformer block子模块后降低图片分辨率,调整通道数,形成层次化的图像;
全连接层网络用于将Swim Transformer网络输出的图像特征映射到输出结果,最后输出的值即为光场图像的预测分数值。
进一步地,在一优选实施例中,前三个basicLayer模块中的Swin Transformerblock子模块的个数分别为2、2和18。
进一步地,在一优选实施例中,第四个basicLayer模块中的Transformer block子模块为2个。
进一步地,在一优选实施例中,全连接层网络包括3层全连接层,SwimTransformer网络输出的图像通过3层全连接层将光场图像的特征逐层映射到最终的输出结果中,例如从1000→1024→512→1,最后输出的一个值即为光场图像预测的质量分数值。
在S3的一优选实施例中,基于训练集,学习各种失真的先验知识,包括:
在划分出的无参考光场图像质量评估任务中训练模型,初始化神经网络模型后,通过双层梯度下降法,同时在训练集的支持集和查询集中调整模型参数;具体地:
将训练集中的光场图像x作为输入,经过Swim Transformer网络和全连接层网络以生成输出值
式中,θ是初始化的模型参数,f
采用平均平方误差(MSE)损失函数
式中,n为每个任务中的输入图像数量,i为当前输入图像;
将光场图像数据集中不同失真类型的无参考光场图像质量评估任务划分为训练集
采用Adam优化器在支持集
当前模型参数θ
式中,θ′为更新过后的模型参数的值,α为学习率,∈被设置为10
式中,β
采用Adam优化器在查询集
将光场图像数据集中K个无参考光场图像质量评估任务的更新梯度集合起来,更新最终的模型参数为:
θ
在该优选实施例中,集合起来是指迭代的过程,每一步更新过后的θ用于下一个任务的,然后再更新θ,直到训练完所有任务,最后更新的θ,就是模型最后的参数。
在S4的一优选实施例中,在目标无参考光场图像质量评估任务上对质量先验模型进行微调,包括:
基于得到的质量先验模型,通过在目标无参考光场图像质量评估任务中微调模型,优化参数;具体地:
从目标无参考光场图像质量评估任务中划分出M个带有质量分数的光场图像作为训练样本;其中,质量分数为官方数据集给出的质量分数值;
采用平均平方误差损失函数最小化光场图像的预测质量分数
采用Adam优化器更新质量先验模型的网络参数,对质量先验模型进行微调,得到具有最佳预测质量分数
下面对本发明上述实施例提供的技术方案进行进一步详细说明。
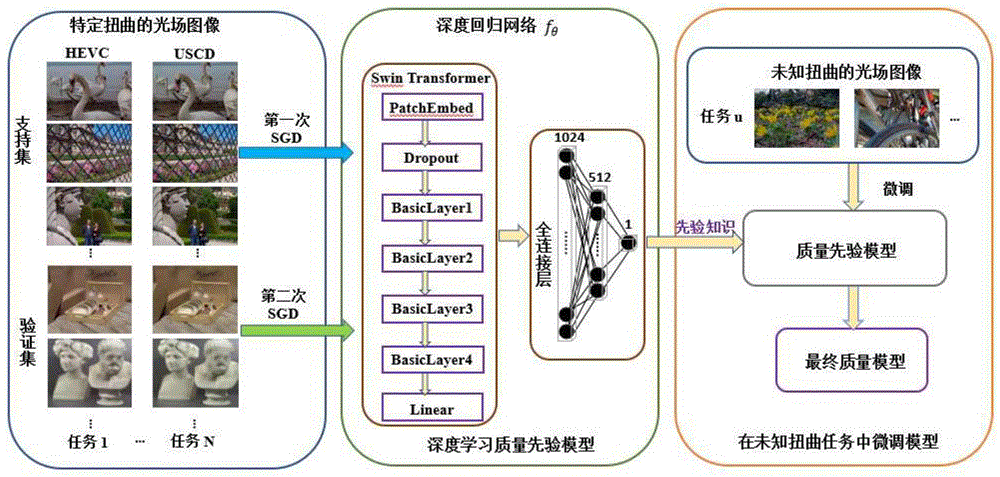
如图2所示,本发明上述实施例首先建立一个能够学习光场图像失真类型的先验知识的模型,然后在一个全新的未知失真类型中微调这个模型,得到最终的光场图像质量评估模型。
模型的网络由两个网络组成:Swin Transformer网络和全连接层。
1)Swin Transformer网络,由四个basicLayer模块和一个linear层组成,前三个basicLayer模块由Swin Transformer block子模块和Patch Merging子模块组成,SwinTransformer block子模块个数分别为2,2,18。第四个basicLayer模块由2个Transformerblock子模块组成,无Patch Merging子模块,最后连入一个Linear层。如图3所示。
输入一张扭曲的光场图像,会经过一个PatchEmbed模块,将图片切成一个个图块,并嵌入向量。送入basicLayer模块中,其中Patch Merging子模块主要在每个swinTransformer block子模块后降低图片分辨率,调整通道数,进而形成层次化的设计,同时也能节省一定运算量。经过swin Transformer网络后,图像的维度从HxW变为1x1000。
2)全连接层,总共有三层,将上一层输出从1000->1024->512->1,最后输出的结果就是光场图像的预测分数值。
模型的训练由两个阶段组成:元训练阶段和微调阶段。
1)元训练阶段,这个阶段将在划分出的NR-IQA训练任务中训练模型,初始化网络模型后,通过双层梯度下降法,同时在训练集的支持集和查询集中调整模型参数。
2)微调阶段,这个阶段在基于之前学习到的先验模型中,通过在目标任务中微调模型,优化参数。
首先在数据预处理阶段,将光场图像转化为由多个子孔径图像组成的子孔图像(SAI)阵列图,并将SAI阵列图转化为宏观像素图像(MacPI)形式,宏像素图像是将相同空间位置的每个SAI的根据其角度位置进行组织而生成的。宏观像素形式可以很好地结合光场图像的空间以及角度信息,以充分利用图像中包含的信息。然后进行深度训练,它包括两个步骤。首先,根据光场数据集中图像的失真类型,将其分为多个任务作为元训练集,这个训练集将被分为支持集和查询集,并通过双级梯度下降法在训练集上训练先验模型。然后,我们在目标NR-IQA任务上对之前训练的模型进行微调,得到最终的质量模型。
1)元学习的训练阶段
这个阶段类似于用深度学习进行图像处理的预训练阶段,首先构建一个初始化的模型,然后对各种不同的LFIQA失真任务进行预训练。训练模型的深度回归网络由一个SwinTransformer网络层和一个全连接层组成。Swin Transformer是一种新的Transformer架构,它采用滑动窗口和分层结构机制,使其成为机器视觉中新的Backbone,在图像分类、目标检测等多种机器视觉任务中达到SOTA水平。而且它的注意机制与图像质量评估过程中的人眼感知特性是一致的。将其加入到本发明的模型中,以增强模型的评估性能。然后,在Transformer层之后添加一个全连接层,生成回归网络的输出,作为光场图像质量得分的值。
具体来说,光场图像x被用作输入,将其送入两个网络以生成输出值
其中,θ是初始化的网络参数,f
首先将光场数据集中不同失真类型的几个NR-LFIQA任务划分为训练集
由于质量评估模型与识别模型相比相对复杂,所以使用随机梯度下降法来优化函数。Adam是一种一阶优化算法,可以取代传统的随机梯度下降过程。它利用一阶矩估计和二阶矩估计的梯度动态地调整训练过程中每个参数的学习率。因此,本发明使用Adam优化器在支持集
其更新公式为:
其中,α是学习率,∈被设置为10
β
在支持集上的对模型参数进行优化之后,为了使得优化后得模型在查询集上也能有较高的性能,本发明在查询集上进行了第二次参数优化。模型的参数θ
然后,每个批次中的K个任务的更新梯度将被集合起来,以更新最终的先验模型,其定义为:
通过上述步骤,本发明在元训练集上迭代采样不同的失真任务来训练深度元回归网络f
2)深度元学习的微调阶段
这个阶段将在一些未知的NR-LFIQA任务中对模型进行微调。在特定的失真任务中训练模型以学习关于失真的各种先验知识,但它也缺乏对目标任务的轻度训练。因此,我们从目标NR-IQA任务中划分出M个带有主观分数值得光场图像用于训练,来微调模型。同样的,MSE损失函数被用来最小化输出值
为了研究本发明提出的方法的性能有效性,在两个公开的数据集中对该方法进行了评估实验,包括Win5-LID,SHU。在该评估实验中,使用斯皮尔曼等级相关系数(SROCC)、线性相关系数(PLCC)和均方根误差(RMSE)作为评价标准,以直观地显示实验性能。表1显示了本发明提出的质量评估方法在Win5-LID以及SHU数据集上的实验表现,以及与其他最先进的IQA方法的比较结果,其中最好的表现用粗体表示,本发明选择了九个具有代表性的最先进的比较指标。从实验结果可以看出,本发明提出的质量评估方法在整体性能上优于几个可比的高级IQA方法。此外,为了验证所提出的元深度学习模型能够适应各种失真类型,在Win5-LID数据集上测试的不同失真类型的SROCC值列于表2中。可以看出,本发明所提出的质量评估方法同样可以在所有类型的失真上保持较高的性能。为了更直接地显示本发明所提出的质量评估方法的实验性能,本发明画出了方法的整体性能和不同失真的散点图,如图4中(a)~(d)所示。基于大量的实验结果,可以得出结论,本发明提出的基于深度元学习的无参考光场图像质量评估方法对于LFI的质量评估具有很强的实用价值。
表1在Win5-LID和SHU数据集上的性能比较
表2Win5-LID数据集上不同失真类型的SROCC性能
为了进一步研究MacPI模式和Swim Transformer网络结构在本发明提出的方法中是否对模型性能有增强作用,本发明进行了两次消融实验。具体来说,首先将网络结构改为MacPI模式下深度学习中最通用的Resnet网络,以验证Swim Transformer网络的有效性。其次,将Swim Transformer网络直接用于原始的SAI阵列图模式,以验证转换到MacPI模式是否对实验结果有增强作用。实验结果见表3。可以看到,加入Swim Transformer网络结构后,在一定程度上使实验效果更好。在Win5-LID数据集中,效果提升比较明显,而在SHU数据集中,只用普通的深度网络已经可以达到很高的效果。一个可能的原因是,SHU数据集的空间失真度更高,因此容易在普通的网络结构中就可以达到更高的性能。同时可以观察到,转换为MacPI模式对两个数据集的实验结果都有明显的增益。因为MacPI的生成需要包括光场图像的空间和角度信息,MacPI模式下的深度学习可以很好地适应光场图像的特点,使实验效果更好。综上,在MacPI模式下对由Swim Transformer组成的网络结构进行深度学习可以大幅提高模型的整体性能。
表3关于MacPI和Swim Transformer对实验性能影响的验证性实验
本发明一实施例提供了一种基于深度元学习的无参考光场图像质量评估系统,如图5所示,该系统可以包括:
数据集构建模块,该模块用于分别构建包含无参考光场图像质量评估任务的训练集和包含目标评估任务的测试集;
模型构建模块,该模块用于构建包含Swim Transformer网络结构的深度元学习模型;
模型元训练模块,该模块基于训练集,学习失真的先验知识,得到质量先验模型;
模型微调模块,该模块用于在测试集上对质量先验模型进行微调,得到最终的光场图像质量评估模型;
质量评估模块,该模块利用光场图像质量评估模型对待评估光场图像进行光场图像质量评估。
需要说明的是,本发明提供的方法中的步骤,可以利用系统中对应的模块、装置、单元等予以实现,本领域技术人员可以参照方法的技术方案实现系统的组成,即,方法中的实施例可理解为构建系统的优选例,在此不予赘述。
本发明一实施例提供了一种计算机终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时可用于执行本发明上述实施例中任一项的方法,或,运行本发明上述实施例中任一项的系统。
可选地,存储器,用于存储程序;存储器,可以包括易失性存储器(英文:volatilememory),例如随机存取存储器(英文:random-access memory,缩写:RAM),如静态随机存取存储器(英文:static random-access memory,缩写:SRAM),双倍数据率同步动态随机存取存储器(英文:Double Data Rate Synchronous Dynamic Random Access Memory,缩写:DDR SDRAM)等;存储器也可以包括非易失性存储器(英文:non-volatile memory),例如快闪存储器(英文:flash memory)。存储器用于存储计算机程序(如实现上述方法的应用程序、功能模块等)、计算机指令等,上述的计算机程序、计算机指令等可以分区存储在一个或多个存储器中。并且上述的计算机程序、计算机指令、数据等可以被处理器调用。
上述的计算机程序、计算机指令等可以分区存储在一个或多个存储器中。并且上述的计算机程序、计算机指令、数据等可以被处理器调用。
处理器,用于执行存储器存储的计算机程序,以实现上述实施例涉及的方法中的各个步骤或系统各种的各个模块。具体可以参见前面方法和系统实施例中的相关描述。
处理器和存储器可以是独立结构,也可以是集成在一起的集成结构。当处理器和存储器是独立结构时,存储器、处理器可以通过总线耦合连接。
本发明一实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行本发明上述实施例中任一项的方法,或,运行本发明上述实施例中任一项的系统。
本发明上述实施例提供的基于深度元学习的无参考光场图像质量评估方法及系统,采用了深度学习、深度元学习、MacPI模式、Swim Transformer网络等技术,使得该光场图像质量评估技术在例如Win5-LID和SHU等数据集上进行质量评估可以达到较高的性能,且适应每一种扭曲类型,与最近的先进LQA模型相比,性能大大增强。本发明上述实施例提供的基于深度元学习的无参考光场图像质量评估方法及系统,克服了现有技术中存在光场图像的空间和角度信息结合不够导致实验结果与真实结果相差较远,以及采用深度学习可能会产生的拟合问题和对各种扭曲的不适应性。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
本发明上述实施例中未尽事宜均为本领域公知技术。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 一种基于深度学习的无参考光场图像质量评价方法及系统
- 基于增量元学习的无参考图像质量评价方法