对用于个性化癌症疫苗的新抗原进行排序
文献发布时间:2024-04-18 19:58:26
背景技术
本申请要求2021年2月5日提交的美国临时申请号63/146,392的权益,所述临时申请的全部内容以引用方式并入本文。
序列表的引用
本申请含有计算机可读形式的序列表。所述计算机可读形式以引用方式并入本文。所述ASCII副本创建于2022年2月3日,命名为146401_091686_SL.txt,并且大小为14,005字节。
背景技术
癌症是全球主要死亡原因,占所有死亡人数的四分之一。Siegel等人,CA:ACancer Journal for Clinicians,68:7-30(2018)。2018年新增1810万癌症病例和960万癌症相关死亡人数。Bray等人,CA:A Cancer Journal for Clinicians,68(6):394-424。存在许多现有的护理标准癌症疗法,包括消融技术(例如,外科手术和放射)和化学技术(例如,化疗剂)。遗憾的是,此类疗法常常与严重的风险、毒副作用和极高成本以及不确定的功效相关。
癌症免疫疗法(例如,癌症疫苗)已成为一种有前景的癌症治疗模式。癌症免疫疗法的目标是利用免疫系统来选择性消灭癌症,同时保持正常组织不受伤害。传统的癌症疫苗通常靶向肿瘤相关抗原。肿瘤相关抗原通常存在于正常组织中,但在癌症中过表达。然而,因为这些抗原通常存在于正常组织中,所以免疫耐受会防止免疫激活。针对肿瘤相关抗原的若干临床试验未能证明与护理标准治疗相比具有持久的有益效果。Li等人,AnnOncol.,28(增刊12):xii11–xii17(2017)。
新抗原代表癌症免疫疗法的一个有吸引力的靶点。新抗原是具有个体特异性的非自体蛋白质。新抗原来源于肿瘤细胞基因组中的随机体细胞突变,并且不在正常细胞的表面上表达。同上。由于新抗原仅在肿瘤细胞上表达,并且因此不会诱导中枢免疫耐受,因而靶向癌症新抗原的癌症疫苗具有潜在的优势,包括降低中枢免疫耐受和提高安全性。同上。
癌症的突变情况复杂,并且每个个别受试者的肿瘤突变通常都是独特的。通过测序检测的大多数体细胞突变不会产生有效的新抗原。肿瘤DNA或肿瘤细胞中只有一小部分突变被转录、翻译并加工成具有足以设计出可能有效的疫苗的准确性的肿瘤特异性新抗原。此外,并非所有新抗原都具有免疫原性。事实上,T细胞自发识别内源性新抗原的比例为约1%至2%。参见Karpanen等人,Front Immunol,8:1718(2017)。此外,与新抗原疫苗的制造相关的成本和时间是巨大的。
因此,高效且准确地预测、优先化和选择用于免疫原性组合物的新抗原候选物仍是挑战。因此,对于表征肿瘤基因组物质以鉴定新抗原、鉴定哪些新抗原是免疫系统所靶向的,并选择哪些新抗原可能适于有效的免疫原性组合物的集成方法存在显著未满足的需求。
发明内容
本公开涉及一种用于对来自受试者肿瘤的用于个性化(即受试者特异性)免疫原性组合物的一种或多种合适的肿瘤特异性新抗原进行排序的新方法。本公开还涉及通过施用包含使用对肿瘤特异性新抗原进行排序的新方法选择的肿瘤特异性新抗原的免疫原性组合物在有需要的受试者体内治疗癌症以及配制包含基于本排序技术选择的肿瘤特异性新抗原的免疫原性组合物的方法。合适的肿瘤特异性新抗原是可能呈递在肿瘤的细胞表面上、可能是免疫原性的、预测会以足以在受试者体内引发免疫应答的量表达、任选地代表整个所述肿瘤的足够多样性,并且具有相对高的制造可行性的新抗原。本发明的方法采用一组新抗原(肽疫苗候选物)并以使得一组排序靠前的新抗原同时促进MHC I类和II类分子的重要新抗原在细胞表面呈递的方式对新抗原进行排序。然后可根据可制造性和/或其他标准进一步缩小排序靠前的新抗原的组。
所述方法开始于从肿瘤获得序列数据。序列数据用于获得代表一种或多种肿瘤特异性新抗原的多肽序列的数据。序列数据可以是核苷酸序列数据、多肽序列数据、外显子组序列数据、转录组序列数据或全基因组核苷酸序列数据。合适的肿瘤特异性新抗原是可能呈递在肿瘤的细胞表面上、可能是免疫原性的、预测会以足以在受试者体内引发免疫应答的量表达、任选地代表整个所述肿瘤的足够多样性,并且具有相对高的制造可行性的新抗原。本发明的方法采用一组新抗原(肽疫苗候选物)并以使得一组排序靠前的新抗原同时促进MHC I类和II类分子的重要新抗原在细胞表面呈递的方式对新抗原进行排序。然后可根据可制造性和/或其他标准进一步缩小排序靠前的新抗原的组。如下文将进一步详细描述的,排序主要基于新抗原的计算免疫原性。对于短新抗原,短新抗原的免疫原性至少部分地基于受试者的多个HLA I类等位基因中的至少一个等位基因呈递短新抗原并且不呈递所述短新抗原的种系同胞的概率来确定。类似地,对于长新抗原,长新抗原的免疫原性至少部分地基于受试者的多个HLA II类等位基因中的至少一个等位基因呈递长新抗原并且不呈递所述长新抗原的种系同胞的概率来确定。这些概率是使用一个或多个机器学习平台/模型提供的输出来确定的,其中所述机器学习平台/模型被训练为确定给定等位基因呈递某种抗原的概率。
至少部分地基于本技术配制的免疫原性组合物可包含至少约10种肿瘤特异性新抗原或至少约20种肿瘤特异性新抗原。肿瘤特异性新抗原可由短多肽或长多肽编码。免疫原性组合物可包含核苷酸序列、多肽序列、RNA、DNA、细胞、质粒、载体、树突状细胞或合成的长肽。免疫原性组合物还可包含佐剂。
本公开还涉及在有需要的受试者体内治疗癌症的方法,其包括施用包含使用本文所述的方法选择的一种或多种肿瘤特异性新抗原的个性化免疫原性组合物。本文所公开的方法可适于治疗任何数目的癌症。肿瘤可来自黑色素瘤、乳腺癌、卵巢癌、前列腺癌、肾癌、胃癌、结肠癌、睾丸癌、头颈癌、胰腺癌、脑癌、B细胞淋巴瘤、急性髓性白血病、慢性髓性白血病、慢性淋巴细胞白血病、T细胞淋巴细胞白血病、膀胱癌或肺癌。优选地,癌症是黑素瘤、乳腺癌、肺癌和膀胱癌。
附图说明
将参考附图描述根据本公开的各种实施方案,在附图中:
图1示出了根据一些实施方案的实例提供商网络(或“服务提供商系统”)环境。
图2是根据一些实施方案的向客户提供存储服务和硬件虚拟化服务的实例提供商网络的框图。
图3示出了根据一些实施方案的实施本文所述的技术的一部分或全部的系统。
图4示出了根据示例性实施方案的用于对来自受试者肿瘤的用于受试者特异性免疫原性组合物的肿瘤特异性新抗原进行排序的方法。
具体实施方式
本公开涉及用于对供包括在有效个性化癌症免疫原性组合物(例如,受试者特异性免疫原性组合物)中的肿瘤特异性新抗原进行排序的新方法。本公开还涉及通过施用包含使用对肿瘤特异性新抗原进行排序的新方法形成的肿瘤特异性新抗原的免疫原性组合物在有需要的受试者体内治疗癌症以及配制包含所选择的肿瘤特异性新抗原的免疫原性组合物的方法。
在本公开中引用的所有出版物和专利以引用方式整体并入本文。如果以引用方式并入的材料与本说明书相矛盾或不一致,则本说明书将取代任何此材料。本文中任何参考文献的引用并不承认此类参考文献是本公开的现有技术。当表达值的范围时,其包括使用所述范围内的任何特定值的实施方案。此外,对范围中陈述的值的引用包括所述范围内的每个且每一个值。所有范围均包括其端值并且可组合。当通过使用先行词“约”将值表示为近似值时,应了解具体值形成另一个实施方案。除非上下文另有明确指示,否则对特定数值的引用至少包括所述特定值。除非其使用的具体上下文另有指示,否则“或”的使用将意指“和/或”。
整个说明书和权利要求书中使用了与本说明书的各方面相关的各种术语。除非另外指定,否则此类术语应具有其在本领域中的普通含义。其他具体定义的术语将以与本文提供的定义一致的方式解释。本领域技术人员一般能充分理解本文中所描述或引用的技术和工序,并通常可使用常规方法对其进行利用,诸如例如,在Sambrook等人,MolecularCloning:A Laboratory Manual第4版(2012)Cold Spring Harbor Laboratory Press,Cold Spring Harbor,NY中描述的广泛使用的分子克隆方法。适当时,通常根据制造商规定的方案和条件来实施包括使用可商购获得的试剂盒和试剂的工序,除非另外说明。
除非上下文另外明确指定,否则如本文所用,单数形式“一个(种)”和“所述”包括多个指示物。术语“包括”、“诸如”等意图表达包含而不是限制,除非另外具体指定。
除非另外指定,否则一系列要素或范围之前的术语“至少”、“小于”和“大约”或类似术语应理解为指代所述系列或范围中的每个要素。本领域技术人员仅仅使用常规试验将认识到或者能够确定本文所描述的发明的具体实施方案的很多等效方案。此类等效物意图由以下权利要求涵盖。
术语“癌症”是指受试者的生理条件,在所述受试者体内,细胞群的特征在于不受控制的增殖、永生性、转移潜力、快速生长和增殖速率和/或某些形态学特征。通常,癌症可呈肿瘤或肿块的形式,但可单独存在于受试者体内,或者可作为独立细胞(诸如白血病或淋巴瘤细胞)在血流中循环。术语癌症包括所有类型的癌症和转移瘤,包括血液恶性肿瘤、实体肿瘤、肉瘤、癌瘤和其他实体和非实体肿瘤。癌症的实例包括但不限于癌瘤、淋巴瘤、母细胞瘤、肉瘤和白血病。此类癌症的更具体实例包括鳞状细胞癌、小细胞肺癌、非小细胞肺癌、肺腺癌、肺鳞状癌、腹膜癌、肝细胞癌、胃肠癌、胰腺癌、神经胶质瘤、宫颈癌、卵巢癌、肝癌、膀胱癌、肝细胞瘤、乳腺癌(例如,三阴性乳腺癌、激素受体阳性乳腺癌)、骨肉瘤、黑色素瘤、结肠癌、结直肠癌、子宫内膜癌(例如,浆液性)或子宫癌、唾液腺癌、肾癌、肝癌、前列腺癌、外阴癌、甲状腺癌、肝癌以及各种类型的头颈癌。三阴性乳腺癌是指雌激素受体(ER)、孕激素受体(PR)和Her2/neu基因表达呈阴性的乳腺癌。激素受体阳性乳腺癌是指以下至少一项呈阳性:ER或PR呈阳性,并且Her2/neu(HER2)呈阴性的乳腺癌。
如本文所用的术语“新抗原”是指具有至少一种变化的抗原,所述变化例如经由肿瘤细胞中的突变或对肿瘤细胞具有特异性的翻译后修饰使所述抗原不同于对应亲本抗原。突变可包括移码、插入缺失、错义或无义取代、剪接位点变化、基因组重排或基因融合,或产生新抗原的任何基因组表达变化。突变可包括剪接突变。对肿瘤细胞具有特异性的翻译后修饰可包括异常磷酸化。对肿瘤细胞具有特异性的翻译后修饰还可包括蛋白酶体产生的剪接抗原。参见Lipe等人,Science,354(6310):354:358(2016)。一般来讲,点突变约占肿瘤突变95%,并且其余的则为插入缺失和移码突变。参见Snyder等人,N Engl J Med.,371:2189–2199(2014)。
如本文所用,术语“肿瘤特异性新抗原”是存在于受试者肿瘤细胞或组织中但不存在于受试者正常细胞或组织中的新抗原。
如本文所用的术语“种系同胞”是指代表对应新抗原的未突变肽等效物的种系抗原。
如本文所用的术语“下一代测序”或“NGS”是指与传统方法(例如,桑格测序)相比具有增大通量的测序技术,具有一次生成数十万个序列读数的能力。
如本文所用的术语“神经网络”是指用于分类或回归的机器学习模型,所述机器学习模型由多层线性变换接着是通常经由随机梯度递减和反向传播训练的元素非线性组成。
如本文所用的术语“受试者”是指任何动物,诸如任何哺乳动物,包括但不限于人、非人灵长类动物、啮齿类动物等。在一些实施方案中,哺乳动物是小鼠。在一些实施方案中,哺乳动物是人。
如本文所用的术语“肿瘤细胞”是指作为癌细胞或来源于自癌细胞的任何细胞。术语“肿瘤细胞”还可指表现出癌症样特性的细胞,所述特性例如无法控制的繁殖、对抗生长信号的抗性、转移能力以及丧失经历程序性细胞死亡的能力。
本文提供了方法的附加描述和对方法实践的指导。
I.用于对肿瘤特异性新抗原进行排序的方法
本文公开了用于对来自受试者的肿瘤的适于受试者特异性免疫原性组合物的肿瘤特异性新抗原进行排序的方法。合适的肿瘤特异性新抗原是可能呈递在肿瘤的细胞表面上、可能是免疫原性的、预测会以足以在受试者体内引发免疫应答的量表达、任选地代表整个所述肿瘤的足够多样性,并且具有相对高的制造可行性的肿瘤特异性新抗原。本发明的方法采用一组新抗原(肽疫苗候选物)并以使得一组排序靠前的新抗原同时促进MHC I类和II类分子的重要新抗原在细胞表面呈递的方式对新抗原进行排序。然后可根据可制造性和/或其他标准进一步缩小排序靠前的新抗原的组。
利用肿瘤和受试者的序列数据对来自所述受试者肿瘤的肿瘤特异性新抗原进行排序。肿瘤的序列数据用于获得代表一种或多种肿瘤特异性新抗原的多肽序列的数据。一般来讲,代表一种或多种肿瘤特异性新抗原的多肽序列的序列数据通过对肿瘤样本进行序列分析来确定。在一些实施方案中,获得序列数据包括接收或访问来自先前执行的测序的存储数据。序列数据可以是例如外显子组序列数据、转录组序列数据、全基因组核苷酸序列数据、核苷酸序列数据或多肽序列数据。获得肿瘤和受试者的序列数据的各种方法可用于本文所述的方法中。下文进一步详细描述一些示例性测序方法。
一旦获得代表一种或多种肿瘤特异性新抗原的多肽序列的序列数据,就可与受试者的MHC分子配合分析所述序列数据,以鉴定供包括在针对受试者的免疫原性组合物中的新抗原候选物并对其进行排序。
在一个实施方案中,给定受试者的HLA I和HLA II等位基因组和肿瘤的体细胞突变列表,鉴定排序靠前的一组约30个长肽候选物和约15个短肽候选物并进行可制造性分析。使用跨越每个体细胞突变的滑动窗口来鉴定起始肽组。使用下文描述的MHC I类和II类机器学习模型对它们进行评分。15个短肽和30个长肽含有至少1个MHC I类表位,并且长肽还可含有1个或多个MHC II类表位。然后,基于可制造性选择30种长肽候选物中的9种和15种短肽候选物中的10种以包括在免疫原性组合物中。在其他实施方案中,可提供不同数目的排序靠前的长肽候选物和/或短肽候选物用于可制造性分析。在一些实施方案中,可提供20-100(例如,20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100)种候选物。在其他实施方案中,可提供更多或更少的排序靠前的候选物以用于可制造性分析。
类似地,最终可选择不同数目的长肽候选物和/或短肽候选物以包括在免疫原性组合物中。较长新抗原通常具有比短新抗原多的制造约束,因此激发了对更多数目的长新抗原的需求。在一些实施方案中,具有约15-30个氨基酸(例如,15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个氨基酸)的新抗原被认为是长新抗原,并且具有约8-11个氨基酸(例如,8、9、10或11个氨基酸)的新抗原被认为是短新抗原。本技术的不同实施方案/实施方式可定义具有不同氨基酸数目的长和短新抗原。
图4示出了用于对来自受试者肿瘤的用于受试者特异性免疫原性组合物的肿瘤特异性新抗原进行排序的实例方法400。首先,鉴定肿瘤中存在的多个体细胞突变(410)。然后,对于个别体细胞突变,鉴定或以其他方式获得与体细胞突变相关的初始多种短新抗原和初始多种长新抗原(420)。初始多种短新抗原可包含短多肽,所述短多肽包括与受试者相关的至少一个MHC I类表位。初始多种长新抗原可包含长多肽,所述长多肽包括与受试者相关的至少一个MHC I类表位和至少一个MHC II类表位。
可选择或确定初始多种短新抗原中具有最高免疫原性评分的短新抗原(430),并且将其添加到短新抗原候选物列表中(440)。这种选择的短新抗原也可称为相对于特定体细胞突变的最佳短新抗原。类似地,可选择或确定初始多种长新抗原中具有最高免疫原性评分的长新抗原(460),并且将其添加到长新抗原候选物列表中(470)。这种选择的长新抗原也可称为针对特定体细胞突变的最佳长新抗原。免疫原性评分可以是任何形式的评级或值,数值或非数值,用于表示新抗原相对于一项或多项标准并且基于一条或多条数据的质量。新抗原的免疫原性评分可根据下文详细描述的技术来确定。可对多个体细胞突变中的每个体细胞突变执行选择最佳短新抗原和最佳长新抗原的步骤,使得短新抗原候选物列表在完成时包括所有体细胞突变的相应最佳短新抗原,并且其中长新抗原候选物列表在完成时包括所有体细胞突变的相应最佳长新抗原。换句话讲,短新抗原候选物列表中的每个短新抗原可以是针对多个鉴定的体细胞突变中的独特体细胞突变的最佳短新抗原。类似地,长新抗原候选物列表中的每个长新抗原可以是针对多个已鉴定的体细胞突变中的独特体细胞突变的最佳长新抗原。针对每个体细胞突变鉴定出最佳短新抗原和最佳长新抗原。然后将短新抗原候选物列表和长新抗原候选物列表各自分选并且按递减的免疫原性评分进行排序(450、480)。
在一些实施方案中,然后将长新抗原候选物的分选列表修整成预定数目的排序靠前的长新抗原候选物。例如,列表可被修整为前30个长新抗原候选物。换句话讲,选择分选列表中预定数目的排序靠前的长新抗原用于可制造性分析或确定。在一些实施方案中,长新抗原候选物的修整列表(即,预定数目的排序靠前的长新抗原)被提供给制造商以判断可制造性。某种新抗原的可制造性可表示为数值或非数值的评分、值、分类等。可制造性可基于可以各种方式计算、加权或以其他方式处理的一个或多个标准或数据。可制造性确定可基于对实际新抗原执行的分析或基于参考材料。然后制造商基于可制造性(即排序靠前的可制造性评分)从长新抗原候选物的修整列表选择长新抗原候选物子组。例如,所述子组可包括具有最高可制造性评分的前9个长新抗原。如本文所用的“制造商”描述了进行可制造性分析和选择子组的任何实体,并且可以是执行技术的其余部分的同一实体或第三方。
一旦获得基于可制造性的长新抗原候选物子组,则从短新抗原候选物列表去除短新抗原候选列表中的包括在长新抗原子组中的任何新抗原中的任何新抗原,以去除重复项。换句话讲,对于长新抗原候选物子组中的每个长新抗原,鉴定其中的突变,并且从短新抗原列表去除任何对应短新抗原。然后基于免疫原性评分将短新抗原列表中其余短新抗原修整至预定数目。例如,所述列表可缩减至约15种新抗原。然后对这些短候选物进行可制造性确定,以获得根据其可制造性选择的短新抗原候选物子组。短新抗原候选物子组和长新抗原候选物子组用于形成或产生可施用于受试者的受试者特异性免疫原性组合物。
获得初始多种短新抗原:
为了获得个别体细胞突变的初始定义的多个短新抗原,首先,鉴定包括突变氨基酸的最长新抗原序列neoT。还鉴定此新抗原的种系同胞基因neoG。然后,使用跨越最长新抗原序列的滑动窗口来鉴定包括具有介于最小(例如,8)数目与最大(例如,11)数目之间的氨基酸的突变的所有新抗原序列。这产生了初始多种短新抗原,neoT_1。例如,在一个实施方案中,其中氨基酸的最小数目为8并且氨基酸的最大数目为11,最长新抗原neoT内的包括突变并且长度为8、9、10,或11个氨基酸的所有新抗原序列被鉴定并指定为初始多种短新抗原neoT_1的成员。在一些实施方案中,对于受试者的多个HLA I类等位基因a1中的个别等位基因a1
其中:
i是新抗原的索引,
j是等位基因的索引,neoT_1
在一些实施方案中,此概率可至少部分地基于来自MHC I类机器学习模型的数据来确定,所述MHC I类机器学习模型被训练为确定多个HLA I类等位基因中的给定等位基因呈递某种抗原的概率。
进一步过滤初始多种短新抗原,使得其不包括嵌套在初始多种短新抗原的另一种新抗原中或嵌套所述另一种新抗原的任何新抗原。这种过滤可通过鉴定新抗原对来完成,其中所述对中的一个序列嵌套在另一个序列内,并且保留来自所述对的具有较高概率评分P1
获得初始多种长新抗原:
一旦定义了初始多种短新抗原,就从最长新抗原序列neoT鉴定短子序列T1。短子序列T1被鉴定为最长新抗原序列neoT的最短子序列,所述最短子序列包括初始多种短新抗原neoT_1中的所有新抗原。如上所述,过滤的初始多种短新抗原neoT_1_filt不具有包括在初始多种短新抗原中的另一种新抗原中或包括所述另一种新抗原的新抗原。然后可鉴定扩展的序列T1_long。扩展的序列T1_long是根据最长的新抗原neoT通过在短子序列T1的两侧添加氨基酸而获得的,使得突变氨基酸的每一侧都侧接有第一最大数目的氨基酸。例如,第一最大数目可为29。在一些实施方案中,氨基酸的第二最大数目可为9-50(例如,9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50)。因此,在此实施方案中,扩展的序列T1_long包括短子序列T1和侧接在突变氨基酸每一侧的29个氨基酸。
来自介于短子序列的长度[长度(T1)]与氨基酸的第二最大数目之间的长度范围的长子序列的所有可能子序列可被鉴定并指定为初始多种长新抗原neoT_2。例如,第二最大数目可为30。在一些实施方案中,氨基酸的第二最大数目可为9-50(例如,9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50)。在一些实施方案中,初始多种长新抗原可基于一种或多种可制造性条件来过滤。
获得新抗原免疫原性评分:
个别短新抗原的用于选择和排序(即,分选)短新抗原的免疫原性评分可至少部分地基于受试者的多个HLA I类等位基因中的至少一个等位基因呈递个别短新抗原并且不呈递所述个别短新抗原的种系同胞的概率来确定。此概率可表示为:
在一些实施方案中,上述计算值还可称为在过滤嵌套对之前初始多种短新抗原中的每个短新抗原的泛HLA I等位基因评分。P1
另外,在一些实施方案中,包括突变氨基酸和个别MHC I类等位基因的MHC I类表位的肽序列的等位基因评分可基于个别等位基因呈递初始多种短新抗原中的已过滤嵌套对之后的至少一种新抗原并且不呈递所述至少一种新抗原的种系同胞的概率来确定。这可表示为:
P1
在一些实施方案中,泛等位基因HLA I类评分可至少部分地基于受试者的多个HLAI类等位基因中的至少一个等位基因呈递短新抗原组中的至少一种新抗原并且不呈递所述至少一种新抗原的种系同胞的概率来确定。这可表示为:
个别长新抗原的用于选择和排序(即,分选)长新抗原的免疫原性评分可至少部分地基于受试者的多个HLA II等位基因中的至少一个等位基因呈递个别新抗原并且不呈递所述个别新抗原的种系同胞的概率来确定。在初始多种长新抗原neoT_2中,每种新抗原neoT_2
P2
其中:neoT_2
因此,受试者的多个HLA II等位基因中的至少一个等位基因呈递个别新抗原并且不呈递所述个别新抗原的种系同胞的概率可表示为:
所述概率至少部分地基于来自MHC II类机器学习模型的数据来确定,所述MHC II类机器学习模型被训练为确定多个HLA II等位基因中的给定等位基因呈递某种抗原的概率。
突变肽序列将对一个或多个HLA I类等位基因产生免疫应答的概率可表示为:
S=Φ[1Π
或同等地,
S=Φ[1-Π
其中:
S是总体交叉等位基因、每肽的评分,
i∈{0,1}是等位基因特异性CD8+T细胞免疫原性的二元指标,
M是突变肽序列,
G是种系同胞肽序列,根据一个实例,所述种系同胞肽序列可被定义为种系基因组中与肿瘤基因组中突变序列的位置相对应的位置,
A
Φ是突变的估计细胞流行率,
P(I|M,G,A
与在整个肿瘤中更均匀分布的突变相对应的肽可比被认为对于肿瘤罕见的突变接收更高的评分。
短肽可直接包括到疫苗中,并且预期与内源性表达的肽竞争与MHC-I的结合。因此,对于这些肽,可调节评分S以还包括肽与给定MHC-I分子的预测结合概率。短肽的修改评分可表示为:
S=Φ[1-Π
其中:
P(I|M,G,A
P(bind|M,A
在校准结合亲和力数据之后,此评分可由I类机器学习模型提供。
等位基因特异性CD8+免疫原性可表示为:
P(I|M,G,Ai)=P(I|M,Ai)f(DM,G)h(t){1-P(p|Ai,G)[1-P(not at anchor)]}等式(10)
其中:
P(I|M,A
D
DistToSelf可表示为:
其中:
L是种系或突变序列的长度,取其较长者,
对非N末端和C末端锚定位置的所有索引i进行求和,也排除某些HLA I类等位基因的任何中间锚定位置及其邻居,
G
b(A,B)是对应于氨基酸A和B的矩阵项。
为了抑制(suppress)更接近种系肽的突变肽的免疫原性概率,可使用以下函数:
f(D
其中:
其中:
α、β、γ和δ是确定的,假设在给定整数值D
在一些实施方案中,用于对来自受试者肿瘤的用于受试者特异性免疫原性组合物的肿瘤特异性新抗原进行排序的方法包括鉴定肿瘤中存在的多个体细胞突变,并且对于所述多个体细胞突变中的每个体细胞突变:至少部分地基于最佳短新抗原的质量评分从初始多种短新抗原确定最佳短新抗原,并且至少部分基于最佳长新抗原的质量评分从初始多种长新抗原确定最佳长新抗原。每个体细胞突变的最佳短新抗原被添加到短新抗原候选物列表,并且每个体细胞突变的最佳长新抗原被添加到长新抗原候选物列表。然后,所述列表各自按递减的质量评分进行排序。在一些实施方案中,质量评分至少部分地基于预测呈递概率、预测结合亲和力和预测免疫原性应答中的至少一者。在一些实施方案中,质量评分至少部分地基于预测呈递概率。在一些实施方案中,质量评分至少部分地基于预测结合亲和力。在一些实施方案中,预测结合亲和力至少部分地基于来自MHC II类学习模型的数据来确定,所述MHC II类学习模型被训练为确定II类等位基因与给定肽之间的结合亲和力。在一些实施方案中,质量评分至少部分地基于预测免疫原性应答。在一些实施方案中,质量评分至少部分地基于预测呈递概率、预测结合亲和力和预测呈递概率的组合。在一些实施方案中,预测呈递概率、预测结合亲和力和预测呈递概率由一种或多种机器学习模型确定。
在一些实施方案中,肽可基于以下标准的任何子组过滤以供考虑或包括在最终受试者特异性免疫原性组合物中:1)体细胞突变所属基因的RNA丰度(以每百万转录物即TPM为单位测量)。例如,RNA丰度可通过将变体所属基因的RNA TPM值乘以重叠含有变体等位基因的变体位点的读数数目与(a)重叠含有所述变体等位基因的变体位点的读数数目和(b)重叠所述变体位点的读数数目的总数目之和的比率来确定。2)体细胞突变是在必需基因还是驱动基因中。驱动基因是其突变可导致肿瘤生长的基因。必需基因是对生物体生存至关重要的基因。3)预计肽是否会通过合成性和溶解性的质量控制阈值。4)突变肽与对应种系肽的异质性(即不同)程度。在一些实施方案中,要考虑或包括的肽可能需要最小数目的突变氨基酸,并且可优先考虑高度外来的肽而不是较少外来的肽。5)特定受试者体内存在特定突变置信度。例如,罕见的体细胞突变相比更频繁发生的突变被给定更低置信度评分。6)肽候选物是否包括某些氨基酸,诸如半胱氨酸。
体细胞变体可使零个、一个或多个氨基酸突变。例如,沉默突变使零个氨基酸突变,单核苷酸变体通常使一个氨基酸突变,并且移码或终止缺失突变可使多个氨基酸突变。如果发现RNA超读数在变体位点上游组装,则将组装与突变氨基酸重叠的最长共有mRNA序列。如果RNA读取覆盖结束或发现新终止密码子,则mRNA序列组装将停止。如果没有发现RNA超读数,当没有发现超过所要求的蛋白质序列长度的突变氨基酸时,mRNA序列组装将停止。
预测呈递数据可能完全由“正”样本组成,这些样本可呈递在细胞表面上。因此,为了训练这种预测器,其可能需要不能在细胞表面上呈递的“负”样本,可在训练期间采用一种或多种概率负挖掘策略。此类过程可包括HLA等位基因改组,其中当给定阳性样本(例如,肽和对应HLA等位基因)时,可通过随机采样不属于阳性等位基因超型的不同等位基因来替换给定等位基因。每个HLA等位基因可被分类为一种或多种HLA超型,直到只剩下未分类的HLA等位基因。未分类的HLA等位基因可被映射到一个或多个“未分类的”超型分类,并且这些组可与分类的超型分类类似地处理。
另外,肽改组可用于训练预测器,其中给定由肽和对应HLA等位基因组成的阳性样本,将给定肽替换为来自肽源蛋白的相同长度的随机采样氨基酸子序列。
还可生成随机肽,以帮助训练预测器。根据此实例,可生成从氨基酸数据分布采样的随机肽,其中定性亲和力目标低于确定阈值和阴性呈递目标。可确定随机肽的长度,使得对于每个等位基因,每个肽长度存在相等数目的非结合数据点。可对阴性呈递样本与阳性呈递样本之间的确定比率(例如,10:1)进行采样,并且可将样本权重应用于阴性样本以平衡损失。对于每个阴性样本,可均匀分布地随机选择采样方法。
测序方法
各种测序方法是本领域众所周知的,并且包括但不限于基于PCR的方法,其包括实时PC、全外显子组测序、深度测序、高通量测序或其组合。在一些实施方案中,前述技术和程序根据例如Sambrook等人,Molecular Cloning:A Laboratory Manual第四版(2012)ColdSpring Harbor Laboratory Press,Cold Spring Harbor,NY中描述的方法执行。另请参见Austell等人,Current Protocols in Molecular Biology,编辑,Greene Publishing andWiley-Interscience New York(1992)(定期更新)。
测序方法还可包括但不限于:高通量测序、单细胞RNA序列、RNA测序、焦磷酸测序、边合成边测序(sequencing-by synthesis)、单分子测序、纳米孔测序、半导体测序、边合成边测序(sequencing-by-synthesis)、边连接边测序、边杂交边测序、RNA-Sew(Illumina)、数字基因表达(Helicos)、下一代测序、合成单分子测序(SMSS)(Helicos)、大规模并行测序、克隆单分子阵列(Solexa)、鸟枪法测序、Maxam-Hilbery或Sanger测序、全基因组测序、全外显子组测序、引物步移、使用PacBio、SOLid、Ion Torrent或Nanopore平台测序以及本领域已知的任何其他测序方法。本文所采用的用于获得序列数据的测序方法优选为高通量测序。高通量测序技术能够并行对多个核酸分子进行测序,从而能够一次对数百万个核酸分子进行测序。参见Churko等人,Circ.Res.112(12):1613-1623(2013)。
在某些情况下,高通量测序可以是下一代测序。有许多不同的下一代平台使用不同的测序技术(例如,使用可从Illumina(San Diego,California)获得的HiSeq或MiSeq仪器)。这些平台中的任一个平台都可用于对本文公开的遗传物质进行测序。下一代测序基于对大量独立读数进行测序,每个读数表示介于10至1000个之间的碱基的核酸。合成测序是下一代测序中常用的技术。一般来讲,测序涉及将引物与模板杂交以形成模板/引物双链,从而在允许聚合酶以模板依赖的方式将核苷酸添加到引物的条件下,在可检测标签的核苷酸存在的情况下使双链与聚合酶接触。然后使用来自可检测标签的信号来鉴定掺入的碱基,并且依次重复这些步骤以便确定模板中核苷酸的线性顺序。示例性可检测标签包括放射性标签、荧光标签、酶标签等。已知有许多技术用于检测序列,诸如通过循环端测序的Illumina NextSeq平台。
机器学习模型
一旦获得表示一种或多种肿瘤特异性新抗原的多肽序列的序列数据,则可将序列数据与受试者的MHC分子一起输入到机器学习平台(即模型)中。机器学习平台可生成预测一种或多种肿瘤特异性新抗原是否具有免疫原性(例如,将在受试者体内引发免疫应答)的一个或多个数值概率评分。
MHC分子在细胞表面上运输和呈递肽。MHC分子被分类为I类和II类MHC分子。MHC I类存在于身体几乎所有细胞,包括大多数肿瘤细胞的表面。MHC I类蛋白质负载有抗原,这些抗原通常源自内源性蛋白质或细胞内存在的病原体并且然后被呈递到细胞毒性T淋巴细胞(即CD8+)。MHC I类分子可包括HLA-A、HLA-B或HLA-C。II类MHC分子仅存在于树突状细胞、B淋巴细胞、巨噬细胞和其他抗原呈递细胞上。它们呈递的主要是肽,这些肽是从外部抗原来源(即细胞外)加工到辅助性T(Th)细胞(即CD4+)的。MHC II类分子可包括HLA-DPA1、HLA-DPB1、HLA-DQA1、HLA-DQB1、HLA-DRA和HLA-DRB1。在某些情况下,MHC II类分子也可在癌细胞上表达。
MHC I类分子和/或MHC II类分子可被输入到机器学习平台中。通常,MHC I类分子或MHC II类分子被输入到机器学习平台中。在一些实施方案中,MHC I类分子被输入到机器学习平台中。在其他实施方案中,MHC II类分子被输入到机器学习平台中。在一些实施方案中,MHC I类机器学习平台可关于MHC I类训练数据进行训练。在一些实施方案中,MHC II类机器学习平台可关于MHC II类训练数据进行训练。在一些实施方案中,相同的机器学习平台可关于MHC I类训练数据和MHC II类训练数据两者进行训练。在一些实施方案中,机器学习平台可包括MHC I类模型和MHC II类模型。
MHC I类分子与短肽结合。MHC I类分子可适应长度通常为约8个氨基酸至约10个氨基酸的肽。在实施方案中,编码一种或多种肿瘤特异性新抗原的序列数据是长度为约8个氨基酸至约10个氨基酸的短肽。MHC II类分子与长度较长的肽结合。MHC II类可适应长度通常为约13个氨基酸至约25个氨基酸的肽。在实施方案中,编码一种或多种肿瘤特异性新抗原的序列数据是长度为约13至约25个氨基酸的长肽。
编码一种或多种肿瘤特异性新抗原的序列数据可为约5个氨基酸的长度、约6个氨基酸的长度、约7个氨基酸的长度、约8个氨基酸的长度、约9个氨基酸的长度、约10个氨基酸、约11个氨基酸的长度、约12个氨基酸的长度、约13个氨基酸的长度、约14个氨基酸的长度、约15个氨基酸的长度、约16个氨基酸的长度、约17个氨基酸的长度、约18个氨基酸的长度、约19个氨基酸的长度、约20个氨基酸的长度、约21个氨基酸的长度、约22个氨基酸的长度、约23个氨基酸的长度、约24个氨基酸的长度、约25个氨基酸的长度、约26个氨基酸的长度、约27个氨基酸的长度、约28个氨基酸的长度、约29个氨基酸的长度或约30个氨基酸的长度。
机器学习平台可预测一种或多种肿瘤特异性新抗原具有免疫原性(例如,将引发免疫应答)的可能性。
免疫原性肿瘤特异性新抗原在正常组织中不表达。它们可由抗原呈递细胞呈递到CD4+和CD8+T细胞以产生免疫应答。在实施方案中,由一种或多种肿瘤特异性新抗原在受试者体内引发的免疫应答包括将一种或多种肿瘤特异性新抗原呈递到肿瘤细胞表面。更具体地,由一种或多种肿瘤特异性新抗原在受试者体内引发的免疫应答包括由肿瘤细胞上的一种或多种MHC分子呈递一种或多种肿瘤特异性新抗原。预期由一种或多种肿瘤特异性新抗原引发的免疫应答是T细胞介导的应答。由一种或多种肿瘤特异性新抗原在受试者体内引发的免疫应答可涉及能够由抗原呈递细胞诸如树突状细胞呈递到T细胞的一种或多种肿瘤特异性新抗原。优选地,一种或多种肿瘤特异性新抗原能够激活CD8+T细胞和/或CD4+T细胞。
在一些实施方案中,机器学习平台可预测一种或多种肿瘤特异性新抗原将激活CD8+T细胞的可能性。在实施方案中,机器学习平台可预测一种或多种肿瘤特异性新抗原将激活CD4+T细胞的可能性。在一些情况下,机器学习平台可预测一种或多种肿瘤特异性新抗原可引发的抗体滴度。在其他情况下,机器学习平台可预测由一种或多种肿瘤特异性新抗原激活CD8+的频率。
机器学习平台可包括关于训练数据训练的模型。训练数据可获自一系列不同的受试者。训练数据可包括来源于健康受试者以及患有癌症受试者的数据。训练数据可包括可用于生成概率评分的各种数据,所述概率评分指示一种或多种肿瘤特异性新抗原是否将在受试者体内引发免疫应答。示例性训练数据可包括代表来源于正常组织和/或细胞的核苷酸或多肽序列的数据、代表来源于肿瘤组织的核苷酸或多肽序列的数据、代表来自正常组织和肿瘤组织的MHC肽组序列的数据、肽-MHC结合亲和力测量结果或其组合。参考数据还可包括质谱数据、DNA测序数据、RNA测序数据、来自健康受试者和患有癌症受试者的临床数据、细胞因子谱分析数据、T细胞毒性测定数据、肽-MHC单体或多聚体数据以及单等位基因细胞系的蛋白质组学数据,所述单等位基因细胞系被工程化为表达预定的MHC等位基因,随后暴露于合成蛋白、正常和肿瘤人细胞系、新鲜和冷冻初级样本以及T细胞测定。
在一些实例实施方案中,各种样本的结合亲和力预测可被提取并添加到结合亲和力训练数据集,所述训练数据集包括具有未知结合亲和力预测的样本的对应“弱”标签。其中结合亲和力预测超过确定阈值的样本可被过滤掉,留下蒸馏数据集以用于进一步的训练过程。
机器学习平台可以是监督学习平台、无监督学习平台或半监督学习平台。机器学习平台可使用基于序列的方法来生成一种或多种肿瘤特异性新抗原可引发免疫应答(例如,将诱导高或低抗体应答或CD8+应答)的数值概率。基于序列的预测可包括监督机器学习模块,所述监督机器学习模块包括人工神经网络(例如,深度人工神经网络或其他形式)、支持向量机、K最近邻、逻辑多重网络约束回归(LogMiNeR)、回归树、随机森林、adaboost、XGBoost或隐马尔可夫模型。这些平台需要包括已知MHC结合肽的训练数据集。
根据一些实施方案,掩蔽语言建模可在预训练阶段实施,使得肽序列的确定子组可经由标记化过程被掩蔽。然后,分类器可基于未被掩蔽的现有标记来预测原始标记值。
根据另一个实例,序列中的下一个肽可根据预训练过程来确定,其中输入序列可以是两个肽序列的级联,而不是主训练阶段中的肽和等位基因序列。两个肽序列可使用特殊的分离标记来分离,并且每个片段可具有不同的片段索引和嵌入。片段序列可作为输入提供给网络,从而指示每个标记是否属于第一序列、第二序列或者是特殊标记。分类器可被训练为使用标记来预测第二个肽是否是蛋白质中下一个出现的肽。肽可由来自人蛋白质的两个连续的、相同长度的肽提供,或者可从不同的蛋白质随机取样。
许多预测程序已被用于预测肿瘤特异性新抗原是否可在MHC分子上呈递并且引发免疫应答。示例性预测程序例如包括:HLAminer(Warren等人,Genome Med,4:95(2012);HLAtype predicted by orienting the assembly of shotgun sequence data andcomparing it with the reference allele sequence database);VariantEffectPredictor Tool(McLaren等人,Genome Biol,17:122(2016));NetMHCpan(Andreatta等人,Bioinformatics,32:511–517(2016);sequence comparison method based onartificial neural network,and predict the affinity of peptide-MHC-I typemolecular);UCSC浏览器(Kent等人,Genome Res,12:996–1006(2002));CloudNeopipeline(Bais等人,Bioinformatics,33:3110–2(2017));OptiType(Szolek等人,Bioinformatics,30:3310–316(2014));ATHLATES(Liu C等人,Nucleic Acids Res 41:e142(2013));pVAC-Seq(Hundal等人,Genome Med 8:11(2016));MuPeXI(Bjerregaard等人,Cancer Immunol Immunother,66:1123–30(2017));Strelka(Saunders等人,Bioinformatics 28:1811–7(2012));Strelka2(Kim等人,Nat Methods 2018;15:591–4);VarScan2(Koboldt等人,Genome Res,22:568–76(2012));Somaticseq(Fang L等人,GenomeBiol,16:197(2015));SMMPMBEC(Kim等人,BMC Bioinformatics,10:394(2009));NeoPredPipe(Schenck RO,BMC Bioinformatics,20:264(2019));Weka(Witten等人,Datamining:practical machine-learning tools and techniques.第4版,Elsevier,ISBN:97801280435578(eBook)(2017));或Orange(Demsar等人,Orange:Data Mining Toolboxin Python,J Mach Learn Res,14:2349-2353(2013))。任何已知的预测程序都可用作机器学习平台,以生成指示新抗原是否会引发免疫应答的数值概率评分。
根据所使用的机器学习平台,可应用附加过滤器来优先化肿瘤特异性新抗原候选物,包括:消除假设的(Riken)蛋白质;使用抗原加工算法来消除不可能由组成型或免疫型蛋白酶体蛋白水解产生的表位并且优先化新抗原,其中新抗原具有比对应野生型序列更高的预测结合亲和力。
数值概率评分可以是介于0与1之间的数值。在实施方案中,数值概率评分可以是数值0、0.0001、0.0002、0.0003、0.0004、0.0005、0.0006、0.0007、0.0008、0.0009、0.001、0.002、0.003、0.004、0.005、0.006、0.007、0.008、0.009、0.01、0.02、0.03、0.04、0.05、0.06、0.07、0.08、0.09、0.10、0.20、0.30、0.40、0.50、0.60、0.70、0.80、0.90或1。相对于较低数值概率评分,具有较高数值概率评分的肿瘤特异性新抗原指示所述肿瘤特异性新抗原将在受试者体内引发更强的免疫应答,并且因此可能是用于免疫原性组合物的合适候选物。例如,数值概率评分为1的肿瘤特异性新抗原可能比数值概率评分为0.05的肿瘤特异性新抗原在受试者体内引发更强的免疫应答。类似地,数值概率评分为0.5的肿瘤特异性新抗原可能比数值概率评分为0.1的肿瘤特异性新抗原在受试者体内引发更强的免疫应答。
相对于较低数值概率评分,较高数值概率评分是优选的。优选地,具有至少0.8、0.81、0.82、0.83、0.84、0.85、0.86、0.87、0.88、0.89、0.9、0.95、0.96、0.97、0.98、0.99或1的数值概率评分的肿瘤特异性新抗原指示可能将在受试者体内引发免疫应答。
虽然较高数值概率评分是优选的,但较低数值概率评分仍可指示肿瘤特异性新抗原能够引发足够的免疫应答,使得肿瘤特异性新抗原可能是合适候选物。
在实例中,本文所述的机器学习平台还可预测一种或多种肿瘤特异性新抗原将由肿瘤细胞上的MHC分子呈递的可能性。机器学习平台可预测MHC I类分子或MHC II类分子呈递一种或多种肿瘤特异性新抗原的可能性。
用于选择一种或多种肿瘤特异性新抗原的方法还可包括在电子计算机中测量一种或多种肿瘤特异性新抗原与受试者体内的MHC分子结合的亲和力的步骤。与MHC分子的结合亲和力小于约1000nM的肿瘤特异性新抗原指示一种或多种肿瘤特异性新抗原可能适于免疫原性组合物。与MHC分子的结合亲和力小于约500nM、小于约400nM、小于约300nM、小于约200nM、小于约100nM、小于约50nM的肿瘤特异性新抗原可指示一种或多种肿瘤特异性新抗原可能适于免疫原性组合物。与受试者体内的MHC分子结合的一种或多种肿瘤特异性新抗原的亲和力可预测肿瘤特异性新抗原的免疫原性。替代地,中值亲和力可以是预测肿瘤特异性新抗原免疫原性的有效方式。中值亲和力可使用表位预测算法诸如NetMHCpan、ANN、SMM和SMMPMBEC来计算。
还对一种或多种肿瘤特异性新抗原的RNA表达进行量化。对一种或多种肿瘤特异性新抗原的RNA表达进行量化,以鉴定将在受试者体内引发免疫应答的一种或多种新抗原。存在多种用于测量RNA表达的方法。可测量RNA表达的已知技术包括RNA-seq和原位杂交(例如,FISH)、Northern印迹、DNA微阵列、Tiling阵列和定量聚合酶链式反应(qPCR)。本领域的其他已知技术可用于量化RNA表达。RNA可以是信使RNA(mRNA)、短干扰RNA(siRNA)、微小RNA(miRNA)、环状RNA(circRNA)、转移RNA(tRNA)、核糖体RNA(rRNA)、小核仁RNA(snRNA)、Piwi相互作用RNA(piRNA)、长非编码RNA(长ncRNA)、亚基因组RNA(sgRNA)、来自整合或非整合病毒的RNA或任何其他RNA。优选地,测量mRNA表达。
本技术可进一步降低选择可能在正常组织中诱导自身免疫应答的肿瘤特异性新抗原的可能性。预期与正常抗原具有相似序列的肿瘤特异性新抗原可在正常组织中诱导自身免疫应答。例如,与正常抗原至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%相似的肿瘤特异性新抗原可诱导自身免疫应答。预计诱导自身免疫应答的肿瘤特异性新抗原不优先用于免疫原性组合物。预计诱导自身免疫应答的肿瘤特异性新抗原通常不被选择用于免疫原性组合物。所述方法还可包括测量一种或多种肿瘤特异性新抗原激起免疫耐受的能力。预计激起免疫耐受的肿瘤特异性新抗原不优先用于免疫原性组合物。预计激起免疫耐受的肿瘤特异性新抗原不优先用于免疫原性组合物。
最后,基于肿瘤特异性评分的一种或多种肿瘤特异性新抗原被选择用于配制受试者特异性免疫原性组合物。在实施方案中,至少约1、至少约2、至少约3、至少约4、至少约5、至少约6、至少约7、至少约8、至少约9、至少约10、至少约11、至少约12、至少约13、至少约14、至少约15、至少约16、至少约17、至少约18、至少约19、至少选择约20、至少约25、至少约30、至少约35、至少约40、至少约50或更多种肿瘤特异性新抗原被选择用于免疫原性组合物。通常,至少约10种肿瘤特异性新抗原被选择。在其他情况下,至少约20种肿瘤特异性新抗原被选择。
II.治疗方法
本公开还涉及在有需要的受试者体内治疗癌症的方法,其包括施用包含使用本文所述的方法选择的一种或多种肿瘤特异性新抗原的个性化免疫原性组合物。
癌症可以是任何实体肿瘤或任何血液肿瘤。本文所公开的方法优选地适用于实体肿瘤。肿瘤可以是原发性肿瘤(例如,位于肿瘤首次出现的原始部位的肿瘤)。实体肿瘤可包括但不限于乳腺癌肿瘤、卵巢癌肿瘤、前列腺癌肿瘤、肺癌肿瘤、肾癌肿瘤、胃癌肿瘤、睾丸癌肿瘤、头颈癌肿瘤、胰腺癌肿瘤、脑癌肿瘤和黑色素瘤。血液肿瘤可包括但不限于来自淋巴瘤(例如,B细胞淋巴瘤)和白血病(例如,急性髓细胞性白血病、慢性髓细胞性白血病、慢性淋巴细胞性白血病和T细胞淋巴细胞性白血病)的肿瘤。
本文所公开的方法可用于任何合适的癌性肿瘤,包括血液恶性肿瘤、实体肿瘤、肉瘤、癌以及其他实体和非实体肿瘤。例示性的合适癌症包括例如急性淋巴细胞白血病(ALL)、急性髓系白血病(AML)、肾上腺皮质癌、肛门癌、阑尾癌、星形细胞瘤、基底细胞癌、脑肿瘤、胆管癌、膀胱癌、骨癌、乳腺癌、支气管肿瘤、原发性不明癌、心脏肿瘤、宫颈癌、脊索瘤、结肠癌、结直肠癌、颅咽管瘤、导管癌、胚胎肿瘤、子宫内膜癌、室管膜瘤、食道癌、感觉神经母细胞瘤、纤维组织细胞瘤、尤文肉瘤(Ewing sarcoma)、眼癌、生殖细胞肿瘤、胆囊癌、胃癌、胃肠道类癌肿瘤、胃肠道间质瘤、妊娠滋养细胞疾病、神经胶质瘤、头颈癌、肝细胞癌、组织细胞增多症、霍奇金淋巴瘤(Hodgkin lymphoma)、下咽癌、眼内黑色素瘤、胰岛细胞瘤、卡波西肉瘤(Kaposi sarcoma)、肾癌、朗格汉斯细胞组织细胞增多症(Langerhans cellhistiocytosis)、喉癌、唇癌和口腔癌、肝癌、小叶原位癌、肺癌、巨球蛋白血症、恶性纤维组织细胞瘤、黑色素瘤、默克尔细胞癌(Merkel cell carcinoma)、间皮瘤、隐匿性原发性转移鳞状颈癌、牵涉NUT基因的中线道癌、口腔癌、多发性内分泌肿瘤综合征、多发性骨髓瘤、蕈样肉芽肿、骨髓增生异常综合征、骨髓增生异常/骨髓增生性肿瘤、鼻腔和鼻旁窦癌、鼻咽癌、神经母细胞瘤、非小细胞肺癌、口咽癌、骨肉瘤、卵巢癌、胰腺癌、乳头状瘤、副神经节瘤、甲状旁腺癌、阴茎癌、咽癌、嗜铬细胞瘤、垂体瘤、胸膜肺母细胞瘤、原发性中枢神经系统淋巴瘤、前列腺癌、直肠癌、肾细胞癌、肾盂和输尿管癌、视网膜母细胞瘤、横纹肌样瘤、唾液腺癌、塞扎里综合征(Sezary syndrome)、皮肤癌、小细胞肺癌、小肠癌、软组织肉瘤、脊髓肿瘤、胃癌、T细胞淋巴瘤、畸胎瘤、睾丸癌、喉癌、胸腺瘤和胸腺癌、甲状腺癌、尿道癌、子宫癌、阴道癌、外阴癌和维尔姆斯瘤(Wilms tumor)。优选地,癌症是黑色素瘤、乳腺癌、卵巢癌、前列腺癌、肾癌、胃癌、结肠癌、睾丸癌、头颈癌、胰腺癌、脑癌、B细胞淋巴瘤、急性髓细胞性白血病、慢性髓细胞性白血病、慢性淋巴细胞性白血病、T细胞淋巴细胞性白血病、膀胱癌或肺癌。黑色素瘤受到特别关注。乳腺癌、肺癌和膀胱癌也受到特别关注。
免疫原性组合物刺激受试者免疫系统,尤其是特定CD8+T细胞或CD4+T细胞的应答。由CD8+和T辅助CD4+细胞产生的干扰素γ调节PD-L1的表达。当受到T细胞攻击时,肿瘤细胞中的PD-L1表达上调。因此,肿瘤疫苗可能诱导特异性T细胞的产生并且同时上调PD-L1的表达,这可能限制免疫原性组合物的功效。另外,当免疫系统被激活时,T细胞表面报告子CTLA-4的表达也对应地增加,与抗原呈递细胞上的配体B7-1/B7-2结合并且发挥免疫抑制效果。因此,在一些情况下,可进一步向受试者施用抗免疫抑制剂或免疫刺激剂,诸如检查点抑制剂。检查点抑制剂可包括但不限于抗CTL4-A抗体、抗PD-1抗体和抗PD-L1抗体。这些检查点抑制剂与T细胞的免疫检查点蛋白结合,以去除肿瘤细胞对T细胞功能的抑制。通过抗体阻断CTLA-4或PD-L1可增强患者对癌细胞的免疫应答。CTLA-4已被证明在遵循疫苗接种方案时是有效的。
包含一种或多种肿瘤特异性新抗原的免疫原性组合物可施用于已被诊断患有癌症、已经罹患癌症、患有再发癌症(即,复发症)或处于发展出癌症风险中的受试者。包含一种或多种肿瘤特异性新抗原的免疫原性组合物可施用于对其他形式的癌症治疗(例如,化疗、免疫疗法或放射)具有抗性的受试者。包含一种或多种肿瘤特异性新抗原的免疫原性组合物可在其他护理标准癌症疗法(例如,化疗、免疫疗法或放射)之前施用于受试者。包含一种或多种肿瘤特异性新抗原的免疫原性组合物可与其他护理标准癌症疗法(例如,化疗、免疫疗法或放射)同时、在其之后或与之组合施用于受试者。
受试者可以是人、狗、猫、马或需要肿瘤特异性应答的任何动物。
以足以引发对肿瘤特异性新抗原的免疫应答并且破坏或至少部分阻止症状和/或并发症的量将免疫原性组合物施用于受试者。在实施方案中,免疫原性组合物可提供持久的免疫应答。可通过向受试者施用加强剂量的免疫原性组合物来建立持久的免疫应答。可通过向受试者施用加强剂量来延长对免疫原性组合物的免疫应答。在实施方案中,可施用至少一个、至少两个、至少三个或更多个加强剂量以减轻癌症。第一加强剂量可使免疫应答增加至少50%、至少100%、至少200%、至少300%、至少400%、至少500%或至少1000%。第二加强剂量可使免疫应答增加至少50%、至少100%、至少200%、至少300%、至少400%、至少500%或至少1000%。第三加强剂量可使免疫应答增加至少50%、至少100%、至少200%、至少300%、至少400%、至少500%或至少1000%。
足以引发免疫应答的量被定义为“治疗有效剂量”。对此用途有效的量将取决于例如组合物、施用方式、正在治疗的疾病的阶段和严重程度、患者的体重和一般健康状况以及处方医师的判断。应记住,免疫原性组合物通常可用于严重疾病状态,即危及生命或潜在危及生命的情况,尤其是当癌症已经转移时。在此类情况下,鉴于外来物质的最小化和新抗原的相对无毒性质,治疗医师可能并且可感觉到需要施用明显过量的这些免疫原性组合物。
包含一种或多种肿瘤特异性新抗原的免疫原性组合物可单独地或与其他治疗剂组合施用于受试者。治疗剂可以是例如化疗剂、放射或免疫疗法。可针对特定癌症施用任何合适的治疗性治疗。示例性化疗剂包括但不限于:阿地白介素、六甲蜜胺、氨磷汀、天冬酰胺酶、博来霉素、卡培他滨、卡铂、卡莫司汀、克拉屈滨、西沙必利、顺铂、环磷酰胺、阿糖胞苷、达卡巴嗪(DTIC)、更生霉素、多西他赛、阿霉素、屈大麻酚、依泊汀α、依托泊苷、非格司亭、氟达拉滨、氟尿嘧啶、吉西他滨、格拉司琼、羟基脲、伊达比星、异环磷酰胺、干扰素α、伊立替康、兰索拉唑、左旋咪唑、亚叶酸、甲地孕酮、美司纳、甲氨蝶呤、甲氧氯普胺、丝裂霉素、米托坦、米托蒽醌、奥美拉唑、昂丹司琼、紫杉醇
III.免疫原性组合物
本发明还涉及个性化的(即,受试者特异性)免疫原性组合物(例如,癌症疫苗),所述免疫原性组合物包含使用本文所述的方法选择的一种或多种肿瘤特异性抗原。此类免疫原性组合物可根据本领域的标准程序来配制。免疫原性组合物能够引起特异性免疫应答。
可配制免疫原性组合物,使得肿瘤特异性新抗原的选择和数目适用于受试者特定癌症。例如,肿瘤特异性新抗原的选择可取决于癌症的具体类型、癌症的状态、受试者的免疫状态和受试者的MHC类型。
免疫原性组合物可包含至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、37、37、38、39、40、41、42、43、44、45、46、47、48、49、50或更多种肿瘤特异性新抗原。免疫原性组合物可含有约10-20种肿瘤特异性新抗原、约10-30种肿瘤特异性新抗原、约10-40种肿瘤特异性新抗原、约10-50种肿瘤特异性新抗原、约10-60种肿瘤特异性新抗原、约10-70种肿瘤特异性新抗原、约10-80种肿瘤特异性新抗原、约10-90种肿瘤特异性新抗原或约10-100种肿瘤特异性新抗原。优选地,免疫原性组合物包含至少约10种肿瘤特异性新抗原。还优选的是包含至少约20种肿瘤特异性新抗原的免疫原性组合物。
免疫原性组合物还可包含天然或合成抗原。天然或合成抗原可增加免疫应答。示例性天然或合成抗原包括但不限于泛DR表位(PADRE)和破伤风毒素抗原。
免疫原性组合物可以是任何形式,例如合成的长肽、RNA、DNA、细胞、树突状细胞、核苷酸序列、多肽序列、质粒或载体。
肿瘤特异性新抗原也可包括在基于病毒载体的疫苗平台中,诸如牛痘、鸡痘、自我复制的甲病毒、马拉巴病毒(marabavirus)、腺病毒(参见例如,Tatsis等人,MolecularTherapy,10:616-629(2004))或慢病毒,包括但不限于第二代、第三代或混合第二代/第三代慢病毒和设计用于靶向特定细胞类型或受体的任何一代的重组慢病毒(参见例如Hu等人,Immunol Rev.,239(1):45-61(2011),Sakma等人,Biochem J.,443(3):603-18(2012))。根据上述基于病毒载体的疫苗平台的包装能力,此方法可递送编码一种或多种肿瘤特异性新抗原肽的一种或多种核苷酸序列。序列可被非突变序列侧接,可被接头分开或者可在前面具有靶向亚细胞区室的一个或多个序列(参见例如Gros等人,Nat Med.,22(4):433-8(2016),Stronen等人,Science,352(6291):1337-1341(2016),Lu等人,Clin Cancer Res,20(13):3401-3410(2014))。在引入宿主后,受感染细胞表达一种或多种肿瘤特异性新抗原,并且从而引发针对一种或多种肿瘤特异性新抗原的宿主免疫(例如,CD8+或CD4+)应答。在免疫方案中有用的牛痘载体和方法描述于例如美国专利号4,722,848中。另一种载体是BCG(卡介苗(Bacille Calmette Guerin))。Stover等人描述了BCG载体(Nature 351:456-460(1991))。还可使用可用于新抗原的治疗性施用或免疫的多种其他疫苗载体,其根据本文的描述对于本领域技术人员将是显而易见的。
根据特定受试者的个人需要,免疫原性组合物可包含个体化组分。
本文所述的免疫原性组合物还可包含佐剂。佐剂是其与免疫原性组合物的混合会增加或以其他方式增强和/或加强对肿瘤特异性新抗原的免疫应答的任何物质,但是当单独施用所述物质时,不产生对肿瘤特异性新抗原的免疫应答。佐剂优选地产生对新抗原的免疫应答并且不产生过敏或其他不良反应。本文设想免疫原性组合物可在施用免疫原性组合物之前、或与其一起、同时或在其之后施用。
佐剂可通过若干种机制,包括例如淋巴细胞募集、B和/或T细胞的刺激以及巨噬细胞的刺激来增强免疫应答。当本发明的免疫原性组合物包含佐剂或与一种或多种佐剂一起施用时,可使用的佐剂包括但不限于矿物盐佐剂或矿物盐凝胶佐剂、颗粒佐剂、微粒佐剂、粘膜佐剂和免疫刺激佐剂。佐剂的实例包括但不限于:铝盐(明矾)(诸如氢氧化铝、磷酸铝和硫酸铝)、3脱-O-酰化单磷酰脂质A(MPL)(参见GB 2220211)、MF59(Novartis)、AS03(Glaxo SmithKline)、AS04(Glaxo SmithKline)、聚山梨醇酯80(Tween 80;ICL Americas,Inc.)、咪唑并吡啶化合物(参见,国际申请号PCT/US2007/064857,作为国际公布号WO2007/109812公布)、咪唑并喹喔啉化合物(参见国际申请号PCT/US2007/064858,作为国际公布号WO2007/109813公布),以及皂苷,诸如QS21(参见Kensil等人,Vaccine Design:TheSubunit and Adjuvant Approach(Powell和Newman编辑,Plenum Press,NY,1995);美国专利号5,057,540)。在一些实施方案中,佐剂是弗氏佐剂(Freund'sadjuvant)(完全或不完全)。其他佐剂是水包油乳液(诸如,角鲨烯或花生油),任选地与免疫刺激剂,诸如单磷酰脂质A组合(参见,Stoute等人,N.Engl.J.Med.336,86-91(1997))。
CpG免疫刺激寡核苷酸也已被报道会增强在疫苗环境中的佐剂效果。也可使用其他TLR结合分子,诸如RNA结合TLR 7、TLR 8和/或TLR 9。
有用佐剂的其他实例包括但不限于:化学修饰的CpG(例如,CpR,Idera)、Poly(I:C)(例如,polyi:CI2U)、poly ICLC、非CpG细菌DNA或RNA以及免疫活性小分子和抗体,诸如环磷酰胺、舒尼替尼(sunitmib)、贝伐单抗、西乐葆(塞来昔布)、NCX-4016、西地那非、他达拉非、伐地那非、索拉非尼、XL-999、CP-547632、帕唑泮(pazopamb)、ZD2171、AZD2171、伊匹单抗、曲美木单抗和SC58175,它们可起到治疗作用和/或充当佐剂。在实施方案中,PolyICLC是优选的佐剂。
免疫原性组合物可单独包含本文所述的一种或多种肿瘤特异性新抗原或与药学上可接受的载剂一起。可使用一种或多种肿瘤特异性新抗原的悬浮液或分散液,尤其是等渗水性悬浮液、分散液或两性溶剂。免疫原性组合物可以是灭菌的和/或可包含赋形剂,例如防腐剂、稳定剂、润湿剂和/或乳化剂、增溶剂、用于调节渗透压的盐和/或缓冲剂,并且以本身已知的方式制备,例如通过常规的分散和悬浮工艺。在某些实施方案中,此类分散体或悬浮液可包含粘度调节剂。将悬浮液或分散体保存在约2℃至8℃的温度下,或者可优先为了长期储存而冷冻并且然后在使用前不久解冻。对于注射,疫苗或免疫原性制备剂可在水溶液中配制,优选在生理相容性缓冲液诸如汉克斯溶液(Hanks’s solution)、林格溶液(Ringer's solution)或生理盐水缓冲液中配制。所述溶液可含有配制剂诸如助悬剂、稳定剂和/或分散剂。
在某些实施方案中,本文所述的组合物另外包含防腐剂,例如汞衍生物硫柳汞。在具体实施方案中,本文所述的药物组合物包含0.001%至0.01%的硫柳汞。在其他实施方案中,本文所述的药物组合物不包含防腐剂。
赋形剂可独立于佐剂而存在。赋形剂的功能可以是例如增加免疫原性组合物的分子量、增加活性或免疫原性、赋予稳定性、增加生物活性或增加血清半衰期。赋形剂也可用于帮助将一种或多种肿瘤特异性新抗原呈递到T细胞(例如,CD 4+或CD8+T细胞)。赋形剂可以是载体蛋白,诸如但不限于:匙孔血蓝蛋白、血清蛋白诸如转铁蛋白、牛血清白蛋白、人血清白蛋白、甲状腺球蛋白或卵清蛋白、免疫球蛋白或激素诸如胰岛素或棕榈酸。对于人的免疫,载剂通常是人可接受的并且安全的生理学上可接受载剂。另选地,载剂可以是葡聚糖,例如琼脂糖凝胶。
细胞毒性T细胞识别与MHC分子结合的呈肽形式的抗原,而不是完整的外来抗原本身。MHC分子本身位于抗原呈递细胞的细胞表面。因此,如果存在肽抗原、MHC分子和抗原呈递细胞(APC)的三聚体复合物,则细胞毒性T细胞的激活是可能的。如果不仅使用一种或多种肿瘤特异性抗原来激活细胞毒性T细胞,而且如果添加具有相应MHC分子的另外的APC,则可能增强免疫应答。因此,在一些实施方案中,免疫原性组合物另外含有至少一种APC。
免疫原性组合物可包含可接受的载剂(例如,水性载剂)。可使用多种含水载剂例如水、缓冲水、0.9%生理盐水、0.3%甘氨酸、透明质酸等。这些组合物可通过常规的、众所周知的灭菌技术进行灭菌,或者可进行无菌过滤。所得水溶液可按原样包装以期使用或冻干,冻干制备剂在施用之前与无菌溶液组合。组合物可视需要含有药学上可接受的辅助物质以接近生理条件,诸如pH调节和缓冲剂、张力调节剂、润湿剂等,例如,乙酸钠、乳酸钠、氯化钠、氯化钾、氯化钙、脱水山梨糖醇单月桂酸酯、油酸三乙醇胺等。
新抗原也可经由脂质体施用,所述脂质体将所述新抗原靶向特定的细胞组织,诸如淋巴系组织。脂质体还可用于增加半衰期。脂质体包括乳液、泡沫、胶束、不溶性单层、液晶、磷脂分散体、片状层等。在这些制备剂中,要递送的新抗原作为脂质体的一部分掺入,单独地或与结合到例如淋巴系细胞中普遍存在的受体的分子(诸如结合到CD45抗原的单克隆抗体)一起,或与其他治疗性或免疫原性组合物一起。因此,填充有期望新抗原的脂质体可被定向到淋巴系细胞的位点,然后脂质体在所述位点递送所选择的免疫原性组合物。脂质体可由标准的囊泡形成脂质形成,其通常包括中性和带负电的磷脂和固醇诸如胆固醇。脂质的选择通常通过考虑例如脂质体大小、酸不稳定性和脂质体在血流中的稳定性来指导。多种方法可用于制备脂质体,如例如Szoka等人,An.Rev.Biophys.Bioeng.9;467(1980),美国专利号4,235,871、4,501,728、4,501,728、4,837,028和5,019,369中所述。
对于靶向免疫细胞,要掺入脂质体中的配体可包括例如对所需免疫系统细胞的细胞表面决定簇具有特异性的抗体或其片段。脂质体悬浮液可以静脉内、局部、外用等方式以尤其根据施用方式、所递送的肽和正在治疗的疾病的阶段而变化的剂量施用。
一种用于靶向免疫细胞的替代方法,可将免疫原性组合物的组分诸如抗原(即,肿瘤特异性新抗原)、配体或佐剂(例如,TLR)掺入聚(乳酸-羟基乙酸共聚物)微球中。聚(乳酸-羟基乙酸共聚物)微球可作为内体递送装置包载免疫原性组合物的组分。
出于治疗或免疫目的,也可将编码本文所述的肿瘤特异性新抗原的核酸施用于患者。可便利地使用多种方法来将核酸递送给患者。例如,核酸可作为“裸DNA”被直接递送。此方法例如描述于Wolff等人的Science 247:1465-1468(1990)以及美国专利号5,580,859和5,589,466中。还可使用如例如美国专利号5,204,253中描述的弹道递送来施用核酸。可施用仅由DNA组成的颗粒。可选地,DNA可附着到颗粒诸如金颗粒上。用于递送核酸序列的方法可包括在有或没有电穿孔的情况下的病毒载体、mRNA载体和DNA载体。核酸还可复合成阳离子化合物诸如阳离子脂质来递送。
本文提所提供的免疫原性组合物可通过包括但不限于口服、皮内、瘤内、肌肉内、腹膜内、静脉内、外用、皮下、经皮、鼻内和吸入途径以及经由刮除(例如,使用分叉针划破皮肤的顶层)施用于受试者。可在肿瘤部位施用免疫原性组合物以诱导对肿瘤的局部免疫应答。
一种或多种肿瘤特异性新抗原的剂量可取决于组合物的类型以及受试者的年龄、体重、体表面积、个体状况、个体药代动力学数据和施用方式。
本文还公开了制造免疫原性组合物的方法,所述免疫原性组合物包含通过执行本文所公开的方法的步骤而选择的一种或多种肿瘤特异性新抗原。如本文所述的免疫原性组合物可使用本领域已知的方法来制造。例如,本文所公开的产生肿瘤特异性新抗原或载体(例如,包含编码一种或多种肿瘤特异性新抗原的至少一种序列的载体)的方法可包括:在适于表达新抗原或载体的条件下培养宿主细胞,其中所述宿主细胞包含编码新抗原或载体的至少一种多核苷酸;以及纯化所述新抗原或载体。标准纯化方法包括色谱技术、电泳法、免疫法、沉淀法、透析法、过滤法、浓缩法和色谱聚焦技术。
宿主细胞可包括中国仓鼠卵巢(CHO)细胞、NS0细胞、酵母或HEK293细胞。宿主细胞可用包含编码本文所公开的一种或多种肿瘤特异性新抗原或载体的至少一种核酸序列的一种或多种多核苷酸转化。在某些实施方案中,分离的多核苷酸可以是cDNA。
IV.样本
本文所公开的方法包括对来源于肿瘤的一种或多种肿瘤特异性新抗原进行排序。对一种或多种肿瘤特异性新抗原进行排序的方法包括获得来源于肿瘤的序列数据。此类序列数据可来源于受试者的肿瘤样本。肿瘤样本可获自肿瘤活检。
肿瘤样本可获自人或非人受试者。优选地,肿瘤样本获自人。肿瘤样本可获自包含癌性肿瘤的多种生物来源。肿瘤可来自肿瘤部位或来自血液的循环肿瘤细胞。示例性样本可包括但不限于体液、组织活检、血液样本、血清血浆、粪便、皮肤样本等。样本的来源可以是实体组织样本,诸如肿瘤组织活检。组织活检样本可以是来自例如肺、前列腺、结肠、皮肤、乳腺组织或淋巴结的活检。样本还可以是例如骨髓样本,包括骨髓抽吸物和骨髓活检。样本还可以是液体活检,例如循环肿瘤细胞、无细胞循环肿瘤DNA或外泌体。血液样本可以是全血、部分纯化的血液,或全血或部分纯化的血液的一部分,诸如外周血单核细胞(PBMC)。
本文所述的肿瘤样本可直接获自受试者、来源于受试者,或来源于从受试者获得的样本,诸如来源于生物流体或组织样本的培养细胞。肿瘤活检可以是新鲜样本。新鲜样本可在从受试者体内取出之后用任何已知的固定剂(例如,福尔马林、岑克尔氏固定剂或B-5固定剂)进行固定。肿瘤活检还可以是直接获自受试者的细胞的或来源于从受试者获得的细胞的细胞的存档样本,诸如冷冻样本、冷藏样本。优选地,获自受试者的肿瘤样本是新鲜的肿瘤活检。
肿瘤样本可通过任何手段获自受试者,所述手段包括但不限于肿瘤活检、针吸、刮擦、手术切除、手术切口、静脉穿刺或本领域已知的其他手段。肿瘤活检是用于获得肿瘤的优选方法。肿瘤活检可获自任何癌性部位,例如原发性肿瘤或继发性肿瘤。来自原发性肿瘤的肿瘤活检通常是优选的。本领域技术人员将认识到用于获得肿瘤样本的其他合适技术。
可在单次手术中从受试者获得肿瘤样本。可在一段时间内从受试者重复获得肿瘤样本。例如,可每天一次、每周一次、每月一次、每半年或每年获得肿瘤样本。在一段时间内获得大量样本可用于鉴定和选择新的肿瘤特异性新抗原。肿瘤样本可获自相同肿瘤或不同肿瘤。
肿瘤样本可获自原发性肿瘤、一个或多个转移瘤和/或肿瘤生长的个别部位(例如,来自不同骨骼部分诸如髋、骨或椎骨的骨髓)。肿瘤样本可获自相同部位或不同部位。
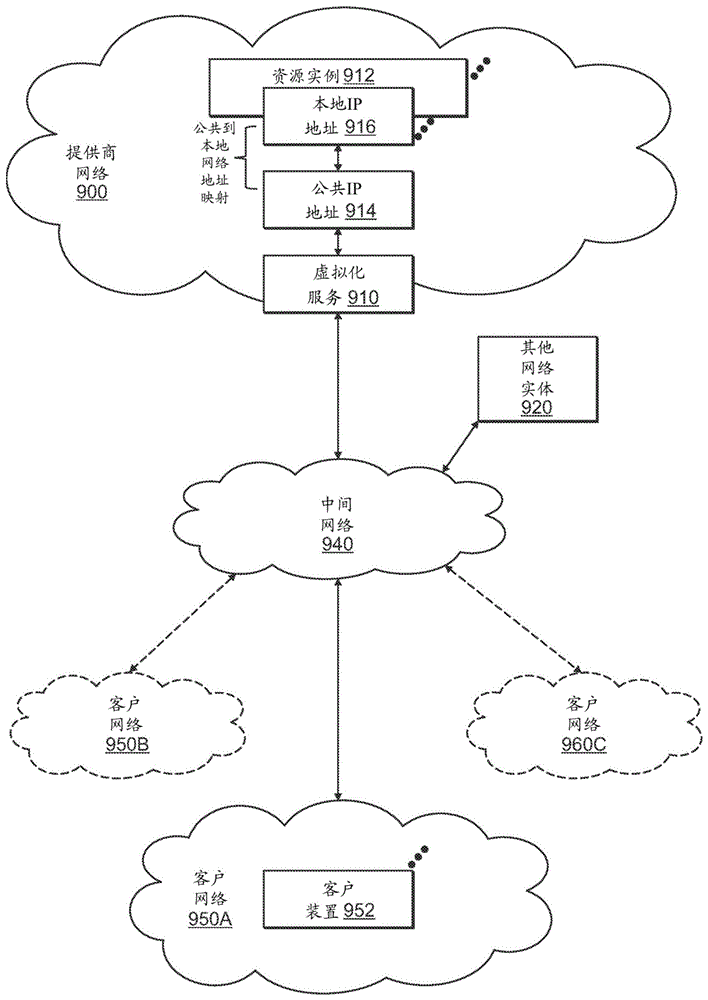
上述的全部或任何部分可在计算环境诸如图1至图3中示出的计算环境上实施。图1示出了根据一些实施方案的实例提供商网络(或“服务提供商系统”)环境。提供商网络900可经由一个或多个虚拟化服务910向客户提供资源虚拟化,所述一个或多个虚拟化服务允许客户购买、租借或以其他方式获得在一个或多个数据中心中的一个或多个提供商网络内的装置上实施的虚拟化资源(包括但不限于计算资源和存储资源)的实例912。本地互联网协议(IP)地址916可与资源实例912相关;本地IP地址是提供商网络900上的资源实例912的内部网络地址。在一些实施方案中,提供商网络900还可提供客户可从提供商900获得的公共IP地址914和/或公共IP地址范围(例如,互联网协议版本4(IPv4)或互联网协议版本6(IPv6)地址)。
常规上,提供商网络900可经由虚拟化服务910来允许服务提供商的客户(例如,操作包括一个或多个客户装置952的一个或多个客户端网络950A至950C的客户)将指派或分配给客户的至少一些公共IP地址914与指派给客户的特定资源实例912动态地相关。提供商网络900还可允许客户将先前映射到分配给客户的一个虚拟化计算资源实例912的公共IP地址914重新映射到也分配给客户的另一虚拟化计算资源实例912。例如,服务提供商(诸如客户网络950A至950C的运营商)的客户可使用由服务提供商提供的虚拟化计算资源实例912和公共IP地址914来实施客户特定的应用程序并且在诸如互联网等中间网络940上呈递客户的应用程序。然后,中间网络940上的其他网络实体920可生成到由客户网络950A至950C发布的目标公共IP地址914的流量;所述流量被路由到服务提供商数据中心,并且在数据中心处经由网络底层路由到虚拟化计算资源实例912的当前映射到目标公共IP地址914的本地IP地址916。类似地,来自虚拟化计算资源实例912的应答流量可经由网络底层路由回到中间网络940上到达源实体920。
如本文所用,本地IP地址是指例如提供商网络中的资源实例的内部或“专用”网络地址。本地IP地址可在互联网工程任务组(IETF)注释请求(RFC)1918保留的地址块内和/或呈由IETF RFC 4193指定的地址格式并且在提供商网络内是可变的。来自提供商网络之外的网络流量并不被直接路由到本地IP地址;而是,流量使用映射到资源实例的本地IP地址的公共IP地址。提供商网络可包括提供网络地址转换(NAT)或类似功能以执行从公共IP地址到本地IP地址以及从本地IP地址到公共IP地址的映射的网络装置或器械。
公共IP地址是由服务提供商或客户指派给资源实例的互联网可变网络地址。例如经由1:1NAT转换路由到公共IP地址的流量,并且将流量转发到资源实例的相应本地IP地址。
一些公共IP地址可由提供商网络基础设施指派给特定资源实例;这些公共IP地址可称为标准公共IP地址或简称为标准IP地址。在一些实施方案中,标准IP地址到资源实例的本地IP地址的映射是所有资源实例类型的默认启动配置。
至少一些公共IP地址可被分配给提供商网络900的客户或由提供商网络的客户获得;然后,客户可将其分配到的公共IP地址指派给分配给客户的特定资源实例。这些公共IP地址可称为客户公共IP地址,或简称为客户IP地址。并不是像在标准IP地址的情形中那样由提供商网络900指派给资源实例,而是客户IP地址可由客户例如经由服务提供商提供的API指派给资源实例。与标准IP地址不同,客户IP地址被分配给客户账户,并且可根据需要或期望由相应客户重新映射到其他资源实例。客户IP地址与客户的账户而非特定资源实例相关,并且客户控制所述IP地址直到客户选择释放IP地址。与常规的静态IP地址不同,客户IP地址允许客户通过将客户的公共IP地址重新映射到与客户的账户相关的任何资源实例来掩蔽资源实例或可用性区域故障。例如,客户IP地址使得客户能够通过将客户IP地址重新映射到替代资源实例来解决客户的资源实例或软件的问题。
图2是根据一些实施方案的向客户提供存储服务和硬件虚拟化服务的实例提供商网络的框图。硬件虚拟化服务1020向客户提供多个计算资源1024(例如,VM)。例如,可将计算资源1024租借或租赁给提供商网络1000的客户(例如,实施客户网络1050的客户)。每个计算资源1024可设置有一个或多个本地IP地址。提供商网络1000可被配置为将分组从计算资源1024的本地IP地址路由到公共互联网目标,以及从公共互联网源路由到计算资源1024的本地IP地址。
提供商网络1000可为例如经由本地网络1056耦合到中间网络1040的客户网络1050提供经由耦合到中间网络1040和提供商网络1000的硬件虚拟化服务1020实施虚拟计算系统1092的能力。在一些实施方案中,硬件虚拟化服务1020可提供一个或多个API 1002(例如,web服务接口),经由所述API,客户网络1050可例如经由控制台1094(例如,基于web的应用程序、独立应用程序、移动应用程序等)访问由硬件虚拟化服务1020提供的功能性。在一些实施方案中,在提供商网络1000处,客户网络1050处的每个虚拟计算系统1092可对应于被租赁、租借或以其他方式提供给客户网络1050的计算资源1024。
客户可例如经由一个或多个API 1002从虚拟计算系统1092和/或另一客户装置1090(例如,经由控制台1094)的实例访问存储服务1010的功能性,以从由提供商网络1000提供的虚拟数据存储区1016(例如,文件夹或“桶”、虚拟化卷、数据库等)的存储资源1018A至1018N中访问数据以及将数据存储到所述存储资源。在一些实施方案中,可在客户网络1050处提供虚拟化数据存储网关(未示出),所述虚拟化数据存储网关可在本地高速缓存至少一些数据(例如,频繁访问的或关键的数据),并且可经由一个或多个通信信道与存储服务1010通信以从本地高速缓存上传新的或修改的数据,使得维护数据的主存储区(虚拟化数据存储区1016)。在一些实施方案中,用户经由虚拟计算系统1092和/或在另一客户装置1090上可经由充当存储虚拟化服务的存储服务1010安装和访问虚拟数据存储区1016卷,并且这些卷在用户看来可以是本地(虚拟化)存储装置1098。
虽然在图2中未示出,但是还可经由API 1002从提供商网络1000内的资源实例访问虚拟化服务。例如,客户、设备服务提供商或其他实体可经由API 1002从提供商网络1000上的相应的虚拟网络内部访问虚拟化服务,以请求在虚拟网络内或另一虚拟网络内分派一个或多个资源实例。
例示性系统
在一些实施方案中,实施本文中所述的技术的一部分或所有的系统可包括通用计算机系统,所述通用计算机系统包括或被配置为访问一个或多个计算机可访问介质,诸如图3中示出的计算机系统1100。在所示实施方案中,计算机系统1100包括经由输入/输出(I/O)接口1130耦合到系统存储器1120的一个或多个处理器1110。计算机系统1100还包括耦合到I/O接口1130的网络接口1140。虽然图3将计算机系统1100示出为单个计算装置,但是在各种实施方案中,计算机系统1100可包括一个计算装置或被配置为作为单个计算机系统1100一起工作的任何数目的计算装置。
在各种实施方案中,计算机系统1100可以是包括一个处理器1110的单处理器系统或者包括若干处理器1110(例如,两个、四个、八个或另一合适数目)的多处理器系统。处理器1110可以是能够执行指令的任何合适的处理器。例如,在各种实施方案中,处理器1110可以是实施多种指令集架构(ISA)中的任一种(诸如x86、ARM、PowerPC、SPARC、或MIPS ISA或任何其他合适的ISA)的通用或嵌入式处理器。在多处理器系统中,每个处理器1110通常可以但不一定实施相同的ISA。
系统存储器1120可存储可由处理器1110访问的指令和数据。在各种实施方案中,可使用任何合适的存储器技术(诸如随机存取存储器(RAM)、静态RAM(SRAM)、同步动态RAM(SDRAM)、非易失性/闪存型存储器或任何其他类型的存储器)来实施系统存储器1120。在所示实施方案中,实施一个或多个期望功能的程序指令和数据(诸如上述那些方法、技术和数据)被示出为作为酶-底物预测器服务代码1125和数据1126存储在系统存储器1120内。
在一个实施方案中,I/O接口1130可被配置为协调装置中的处理器1110、系统存储器1120与任何外围装置(包括网络接口1140或其他外围接口)之间的I/O流量。在一些实施方案中,I/O接口1130可执行任何必要的协议、时序或其他数据变换,以将来自一个组件(例如,系统存储器1120)的数据信号转换成适于由另一部件(例如,处理器1110)使用的格式。在一些实施方案中,I/O接口1130可包括对通过各种类型的外围总线(诸如例如外围部件互连(PCI)总线标准或通用串行总线(USB)标准的变体)附接的装置的支持。在一些实施方案中,I/O接口1130的功能可分裂为两个或更多个分离部件,诸如例如北桥和南桥。此外,在一些实施方案中,I/O接口1130(诸如到系统存储器1120的接口)的功能性中的一些或全部可直接并入处理器1110中。
网络接口1140可被配置为允许数据在计算机系统1100与附接到一个或多个网络1150的其他装置1160之间交换。在各种实施方案中,网络接口1140可支持经由任何合适的有线或无线通用数据网络(例如,诸如多种类型的以太网)进行的通信。另外,网络接口1140可支持经由电信/电话网络(诸如模拟语音网络或数字光纤通信网络)、经由存储局域网(SAN)(诸如光纤通道SAN)或经由I/O任何其他合适类型的网络和/或协议进行的通信。
在一些实施方案中,计算机系统1100包括一个或多个卸载卡1170(包括一个或多个处理器1175,并且可能包括一个或多个网络接口1140),所述一个或多个卸载卡使用I/O接口1130(例如,实施外围部件互连快速(PCI-E)标准的版本或另一互连诸如快速路径互连(QPI)或超路径互连(UPI)的总线)来连接。例如,在一些实施方案中,计算机系统1100可充当托管计算实例的主机电子装置(例如,作为硬件虚拟化服务的一部分进行操作),并且一个或多个卸载卡1170执行可管理在主机电子装置上执行的计算实例的虚拟化管理器。作为一个实例,在一些实施方案中,卸载卡1170可执行计算实例管理操作,诸如暂停和/或取消暂停计算实例、启动和/或终止计算实例、执行存储器传输/复制操作等。在一些实施方案中,这些管理操作可由卸载卡1170与由计算机系统1100的其他处理器1110A至1110N执行的管理程序(例如,根据来自管理程序的请求)协作来执行。然而,在一些实施方案中,由卸载卡1170实施的虚拟化管理器可容纳来自其他实体(例如,来自计算实例本身)的请求,并且可不与任何单独的管理程序协作(或不服务于任何单独的管理程序)。
在一些实施方案中,系统存储器1120可以是被配置为存储如上文所描述的程序指令和数据的计算机可访问介质的一个实施方案。然而,在其他实施方案中,可在不同类型的计算机可访问介质上接收、发送,或存储程序指令和/或数据。一般来讲,计算机可访问介质可包括非暂时性存储介质或存储器介质,诸如磁性或光学介质,例如经由I/O接口1130耦合到计算机系统1100的磁盘或DVD/CD。非暂时性计算机可访问存储介质还可包括任何易失性或非易失性介质,诸如RAM(例如,SDRAM、双倍数据速率(DDR)SDRAM、SRAM等)、只读存储器(ROM)等,所述任何易失性或非易失性介质可作为系统存储器1120或另一种类型的存储器包括在计算机系统1100的一些实施方案中。此外,计算机可访问介质可包括经由通信介质(诸如网络和/或无线链路,诸如可经由网络接口1140实施)传达的传输介质或信号,诸如电信号、电磁信号或数字信号。
本文所讨论或提出的各种实施方案可在多种操作环境中实施,在一些情况下,所述操作环境可包括可用于操作许多应用程序中的任一者的一个或多个用户计算机、计算装置或处理装置。用户装置或客户端装置可包括很多通用个人计算机中的任一者,诸如运行标准操作系统的台式计算机或膝上型计算机以及运行移动软件并且能够支持许多联网和消息传递协议的蜂窝装置、无线装置和手持式装置。这种系统还可包括许多工作站,所述工作站运行各种可商购获得的操作系统和用于诸如开发和数据库管理等目的其他已知应用中的任一者。这些装置还可包括其他电子装置,诸如虚设终端、瘦客户端、游戏系统和/或能够经由网络通信的其他装置。
大多数实施方案利用本领域技术人员将熟悉的至少一种网络来支持使用各种广泛可用协议中的任一者进行通信,所述协议诸如包括传输控制协议/互联网协议(TCP/IP)、文件传送协议(FTP)、通用即插即用(UPnP)、网络文件系统(NFS)、公共互联网文件系统(CIFS)、可扩展消息传递现场协议(XMPP)、AppleTalk等。网络可包括例如局域网(LAN)、广域网(WAN)、虚拟专用网(VPN)、互联网、内联网、外联网、公共电话交换网(PSTN)、红外网络、无线网络及其任何组合。
在使用web服务器的实施方案中,web服务器可运行各种服务器或中间层应用中的任一者,包括HTTP服务器、文件传送协议(FTP)服务器、公共网关接口(CGI)服务器、数据服务器、Java服务器、业务应用服务器等。服务器还能够响应来自用户装置的请求而执行程序或脚本,诸如通过执行可以实施为以任何编程语言(诸如
本文中所公开的环境可包括各种数据存储区以及上文所讨论的其他存储器和存储介质。这些可驻留在各种位置中,诸如驻留在一个或多个计算机本地(和/或驻留在其中)的存储介质上,或驻留在跨网络远离计算机中的任一者或全部的存储介质上。在一组特定实施方案中,信息可驻留在本领域技术人员所熟悉的存储区域网(SAN)中。类似地,执行归属于计算机、服务器或其他网络装置的功能所需的任何文件可视情况存储在本地和/或远程地存储。在系统包括计算机化装置的情况下,每个此种装置可包括可经由总线电耦合的硬件元件,所述元件包括例如至少一个中央处理单元(CPU)、至少一个输入装置(例如,鼠标、键盘、控制器、触摸屏或小键盘)和/或至少一个输出装置(例如,显示装置、打印机或扬声器)。此种系统还可包括一个或多个存储装置,诸如磁盘驱动器、光学存储装置和固态存储装置(诸如随机存取存储器(RAM)或只读存储器(ROM))以及可移除介质装置、存储器卡、快闪卡等。
此种装置还可包括计算机可读存储介质读取器、通信装置(例如,调制解调器、网卡(无线或有线)、红外通信装置等)和上文所述的工作存储器。计算机可读存储介质读取器可与计算机可读存储介质连接或被配置为接收计算机可读存储介质,所述计算机可读存储介质表示用于暂时地和/或更长久地包含、存储、传输和检索计算机可读信息的远程、本地、固定和/或可移除的存储装置以及存储介质。系统和各种装置通常还将包括位于至少一个工作存储器装置内的许多软件应用、模块、服务或其他元件,包括操作系统和应用程序,诸如客户端应用或网页浏览器。应当理解,替代实施方案可具有与上述不同的许多变型。例如,还可使用定制硬件,和/或特定元件可以在硬件、软件(包括可移植软件,诸如小程序)或两者中实施。此外,可采用与其他计算装置(诸如网络输入/输出装置)的连接。
用于含有代码或代码的一些部分的存储介质和计算机可读介质可包括本领域中已知或使用的任何适当的介质,包括存储介质和通信介质,诸如但不限于以任何方法或技术实施以用于存储和/或传输信息(诸如计算机可读指令、数据结构、程序模块或其他数据)的易失性和非易失性介质、可移除和不可移除介质介质,包括RAM、ROM、电可擦除可编程只读存储器(EEPROM)、快闪存储器或其他存储器技术、光盘-只读存储器(CD-ROM)、数字多功能磁盘(DVD)或其他光学存储器件、磁带盒、磁带、磁盘存储器件或其他磁性存储装置或可用于存储所期望信息并且可由系统装置访问的任何其他介质。基于本公开和本文中所提供的教义,本领域的普通技术人员将理解实施各种实施方案的其他方式和/或方法。
在前述说明中,描述各种实施方案。出于解释目的,陈述了具体配置和细节以提供对实施方案的透彻理解。然而,本领域技术人员还将明白,可在没有具体细节的情况下实践实施方案。此外,为了不使所述实施方案变得模糊,可省略或简化众所周知的特征。
本文中使用带有虚线边框(例如,大破折号、小破折号、点破折号和点)的带括号文本和方框来示出向一些实施方案添加额外特征的任选操作。然而,此类表示法不应视为意味着这些是仅有的选项或任选操作,和/或在某些实施方案中,带有实线边界的框不是任选的。
在各种实施方案中,具有后缀字母的附图标记可用于指示所引用的实体的一个或多个实例,并且当存在多个实例时,每个实例不必相同,而是可替代地共享一些一般特征或按惯例行事。此外,除非有相反的明确说明,否则所使用的特定后缀并不意味着暗示存在特定量的实体。因此,在各种实施方案中,使用相同或不同后缀字母的两个实体可具有或可不具有相同数目个实例。
对于“一个实施方案”、“实施方案”、“实例实施方案”等的提及指示所述实施方案可包括特定特征、结构或特性,但每个实施方案均可不必包括所述特定特征、结构或特性。此外,此类短语不一定是指同一实施方案。此外,当结合实施方案来描述特定特征、结构或特性时,应认为,无论是否有明确描述,结合其他实施方案来实施此类特征、结构或特性也在本领域技术人员的知识范围内。
此外,在上文所述的各种实施方案中,除非另有具体说明,否则意图将诸如短语“A、B或C中的至少一者”的析取语言理解为意指A、B或C或其任何组合(例如,A、B和/或C)。因此,析取语言并不意图也不应被理解为暗示给定实施方案要求A中的至少一者、B中的至少一者或C中的至少一者各自均存在。
因此,说明书和图式被视为具有说明意义而非限制意义。然而,将显而易见的是,在不脱离如在权利要求中阐述的本公开的更宽泛精神和范围的情况下,可对其做出各种修改和改变。
等效方案
对于本领域技术人员来说显而易见的是,本文所描述的本发明的方法的其他合适的修改和调整是显而易见的,并且可使用合适的等效物来进行,而不脱离本公开或实施方案的范围。现已详细描述某些组合物和方法,通过参考以下实施例将更清楚地理解它们,介绍所述实施例仅是为了说明而不意图加以限制。
实施例
下列实施例仅出于说明性目的提供,并且不意图以任何方式加以限制。
实施例1:
预测效果
MHC I类疫苗肽候选物
实施例1示出了根据实例实施方案的针对实例变体的短MHC I类疫苗肽候选物和预测突变表位。在此实施例中,加框字母“H”代表疫苗肽序列“FVLQHLVFL”的突变子序列。根据本文其他各处描述的一种或多种方法,可预测一个或多个突变表位,并且可生成免疫原性评分。根据此实施例,免疫原性评分可指示较长肽序列中的至少一个表位对受试者MHC I类等位基因中的至少一个具有免疫原性的概率。MHC I类结合评分可指示肽与受试者MHC I类等位基因中的至少一个结合的概率。另外,长度可指示序列中的氨基酸数目,所述氨基酸数目可用于在短新抗原与长新抗原之间进行区分。MHC I类免疫原性结合评分可通过将MHCI类免疫原性评分乘以MHC I类结合评分来确定。RNA TPM可指示按基因长度和测序深度归一化的RNA读数的数目,以每百万转录物(TPM)为单位。最大编码序列覆盖率可指示覆盖疫苗肽序列的RNA读数的数目。
实施例2:
预测效果
MHC I类疫苗肽候选物
实施例2示出了根据实例实施方案的针对实例变体的另一短MHC I类疫苗肽候选物和预测突变表位。在此实施例中,加框字母“C”代表疫苗肽序列“KACHYHSYNGW”的突变子序列。
实施例3:
预测效果
MHC I类疫苗肽候选物
/>
实施例3示出了针对实例变体的另一短MHC I类疫苗肽候选物和预测突变表位。在此实施例中,加框字母“H”表示疫苗肽序列“REEENHSFL”的突变子序列。
实施例4:
预测效果
MHC I类疫苗肽
/>
/>
/>
/>
/>
在上文的实施例4和5中,实施例1的短序列“FVLQHLVFL”用于产生实施例4中的长MHC I类疫苗肽和实施例5的长MHC II类疫苗肽的序列,两者都在序列的中心包括相同短子序列(例如,加框字母“H”)。如本文其他各处所解释的,根据最长新抗原,可将氨基酸添加到短子序列的两侧,使得突变氨基酸的每一侧都侧接有第一最大数目的氨基酸。可生成或确定MHC I类疫苗肽和MHC II类疫苗肽两者的预测突变表位,以及对应免疫原性评分。MHC I类免疫原性评分可指示较长肽序列中的至少一个表位对受试者MHC I类等位基因中的至少一个具有免疫原性的概率。MHC II类免疫原性评分可指示较长肽序列中的至少一个表位对受试者MHC II类等位基因中的至少一个具有免疫原性的概率。
实施例6:
预测效果
MHC I类疫苗肽
/>
/>
/>
/>
在上文的实施例6和7中,实施例2的短序列“KACHYHSYNGW”用于创建实施例6的长MHC I类疫苗肽和实施例7的长MHC II类疫苗肽的序列,两者都在序列的中心包括如实施例2的相同短子序列(例如,加框字母“C”)。可生成或确定MHC I类疫苗肽和MHC II类疫苗肽两者的预测突变表位,以及对应免疫原性评分。MHC I类免疫原性评分可指示较长肽序列中的至少一个表位对受试者MHC I类等位基因中的至少一个具有免疫原性的概率。MHC II类免疫原性评分可指示较长肽序列中的至少一个表位对受试者MHC II类等位基因中的至少一个具有免疫原性的概率。
实施例8:
预测效果
MHC I类疫苗肽
/>
/>
实施例9:
/>
在上文的实施例8和9中,实施例3的短序列“REEENHSFL”用于创建实施例8的长MHCI类疫苗肽和实施例9的长MHC II类疫苗肽的序列,两者都在序列的中心包括如实施例3的相同短子序列(例如,加框字母“H”)。可生成或确定MHC I类疫苗肽和MHC II类疫苗肽两者的预测突变表位,以及对应免疫原性评分。MHC I类免疫原性评分可指示较长肽序列中的至少一个表位对受试者MHC I类等位基因中的至少一个具有免疫原性的概率。MHC II类免疫原性评分可指示较长肽序列中的至少一个表位对受试者MHC II类等位基因中的至少一个具有免疫原性的概率。
序列表
<110> 亚马逊科技公司(AMAZON TECHNOLOGIES, INC.)
<120> 对用于个性化癌症疫苗的新抗原进行排序
<130> 146401.091686
<140>
<141>
<150> 63/146,392
<151> 2021-02-05
<160> 69
<170> PatentIn version 3.5
<210> 1
<211> 21
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 1
Arg Phe Phe Pro Pro Lys Ser Asn Lys Ala Cys His Tyr His Ser Tyr
1 5 1015
Asn Gly Trp Asn Arg
20
<210> 2
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 2
Phe Pro Pro Lys Ser Asn Lys Ala Cys His Tyr
1 5 10
<210> 3
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 3
Lys Ala Cys His Tyr His Ser Tyr
1 5
<210> 4
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 4
Cys His Tyr His Ser Tyr Asn Gly
1 5
<210> 5
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 5
Ser Asn Lys Ala Cys His Tyr His
1 5
<210> 6
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 6
Phe Phe Pro Pro Lys Ser Asn Lys Ala Cys His
1 5 10
<210> 7
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 7
Lys Ala Cys His Tyr His Ser Tyr Asn Gly Trp
1 5 10
<210> 8
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 8
Arg Phe Phe Pro Pro Lys Ser Asn Lys Ala Cys
1 5 10
<210> 9
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 9
Lys Ser Asn Lys Ala Cys His Tyr His Ser Tyr
1 5 10
<210> 10
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 10
Cys His Tyr His Ser Tyr Asn Gly Trp Asn Arg
1 5 10
<210> 11
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 11
Phe Pro Pro Lys Ser Asn Lys Ala Tyr His Tyr
1 5 10
<210> 12
<211> 8
<212> PRT
<213> 智人(Homo sapiens)
<400> 12
Lys Ala Tyr His Tyr His Ser Tyr
1 5
<210> 13
<211> 8
<212> PRT
<213> 智人(Homo sapiens)
<400> 13
Tyr His Tyr His Ser Tyr Asn Gly
1 5
<210> 14
<211> 8
<212> PRT
<213> 智人(Homo sapiens)
<400> 14
Ser Asn Lys Ala Tyr His Tyr His
1 5
<210> 15
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 15
Phe Phe Pro Pro Lys Ser Asn Lys Ala Tyr His
1 5 10
<210> 16
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 16
Lys Ala Tyr His Tyr His Ser Tyr Asn Gly Trp
1 5 10
<210> 17
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 17
Arg Phe Phe Pro Pro Lys Ser Asn Lys Ala Tyr
1 5 10
<210> 18
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 18
Lys Ser Asn Lys Ala Tyr His Tyr His Ser Tyr
1 5 10
<210> 19
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 19
Tyr His Tyr His Ser Tyr Asn Gly Trp Asn Arg
1 5 10
<210> 20
<211> 21
<212> PRT
<213> 智人(Homo sapiens)
<400> 20
Arg Phe Phe Pro Pro Lys Ser Asn Lys Ala Tyr His Tyr His Ser Tyr
1 5 1015
Asn Gly Trp Asn Arg
20
<210> 21
<211> 19
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 21
His Glu His Trp Arg Phe Val Leu Gln His Leu Val Phe Leu Ala Ala
1 5 1015
Phe Val Val
<210> 22
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 22
Trp Arg Phe Val Leu Gln His Leu Val
1 5
<210> 23
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 23
Val Leu Gln His Leu Val Phe Leu Ala
1 5
<210> 24
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 24
Glu His Trp Arg Phe Val Leu Gln His Leu
1 5 10
<210> 25
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 25
His Leu Val Phe Leu Ala Ala Phe Val
1 5
<210> 26
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 26
Phe Val Leu Gln His Leu Val Phe Leu
1 5
<210> 27
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 27
Trp Arg Phe Val Leu Gln His Leu
1 5
<210> 28
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 28
Glu His Trp Arg Phe Val Leu Gln His
1 5
<210> 29
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 29
His Leu Val Phe Leu Ala Ala Phe Val Val
1 5 10
<210> 30
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 30
Leu Gln His Leu Val Phe Leu Ala Ala
1 5
<210> 31
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 31
Arg Phe Val Leu Gln His Leu Val Phe
1 5
<210> 32
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 32
His Trp Arg Phe Val Leu Gln His Leu
1 5
<210> 33
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 33
Val Leu Gln His Leu Val Phe Leu
1 5
<210> 34
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 34
His Glu His Trp Arg Phe Val Leu Gln His Leu
1 5 10
<210> 35
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 35
Trp Arg Phe Val Leu Gln Arg Leu Val
1 5
<210> 36
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 36
Val Leu Gln Arg Leu Val Phe Leu Ala
1 5
<210> 37
<211> 10
<212> PRT
<213> 智人(Homo sapiens)
<400> 37
Glu His Trp Arg Phe Val Leu Gln Arg Leu
1 5 10
<210> 38
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 38
Arg Leu Val Phe Leu Ala Ala Phe Val
1 5
<210> 39
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 39
Phe Val Leu Gln Arg Leu Val Phe Leu
1 5
<210> 40
<211> 8
<212> PRT
<213> 智人(Homo sapiens)
<400> 40
Trp Arg Phe Val Leu Gln Arg Leu
1 5
<210> 41
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 41
Glu His Trp Arg Phe Val Leu Gln Arg
1 5
<210> 42
<211> 10
<212> PRT
<213> 智人(Homo sapiens)
<400> 42
Arg Leu Val Phe Leu Ala Ala Phe Val Val
1 5 10
<210> 43
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 43
Leu Gln Arg Leu Val Phe Leu Ala Ala
1 5
<210> 44
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 44
Arg Phe Val Leu Gln Arg Leu Val Phe
1 5
<210> 45
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 45
His Trp Arg Phe Val Leu Gln Arg Leu
1 5
<210> 46
<211> 8
<212> PRT
<213> 智人(Homo sapiens)
<400> 46
Val Leu Gln Arg Leu Val Phe Leu
1 5
<210> 47
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 47
His Glu His Trp Arg Phe Val Leu Gln Arg Leu
1 5 10
<210> 48
<211> 19
<212> PRT
<213> 智人(Homo sapiens)
<400> 48
His Glu His Trp Arg Phe Val Leu Gln Arg Leu Val Phe Leu Ala Ala
1 5 1015
Phe Val Val
<210> 49
<211> 18
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 49
Arg Ala Arg Glu Glu Glu Asn His Ser Phe Leu Pro Leu Val His Asn
1 5 1015
Ile Ile
<210> 50
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 50
Arg Glu Glu Glu Asn His Ser Phe Leu
1 5
<210> 51
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 51
Glu Glu Glu Asn His Ser Phe Leu Pro Leu
1 5 10
<210> 52
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 52
His Ser Phe Leu Pro Leu Val His Asn Ile
1 5 10
<210> 53
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 53
Glu Asn His Ser Phe Leu Pro Leu Val
1 5
<210> 54
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 54
His Ser Phe Leu Pro Leu Val His
1 5
<210> 55
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 55
Arg Ala Arg Glu Glu Glu Asn His Ser Phe Leu
1 5 10
<210> 56
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 56
Glu Asn His Ser Phe Leu Pro Leu
1 5
<210> 57
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 57
Arg Ala Arg Glu Glu Glu Asn His Ser Phe
1 5 10
<210> 58
<211> 11
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 58
His Ser Phe Leu Pro Leu Val His Asn Ile Ile
1 5 10
<210> 59
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 59
Arg Glu Glu Glu Asn Tyr Ser Phe Leu
1 5
<210> 60
<211> 10
<212> PRT
<213> 智人(Homo sapiens)
<400> 60
Glu Glu Glu Asn Tyr Ser Phe Leu Pro Leu
1 5 10
<210> 61
<211> 10
<212> PRT
<213> 智人(Homo sapiens)
<400> 61
Tyr Ser Phe Leu Pro Leu Val His Asn Ile
1 5 10
<210> 62
<211> 9
<212> PRT
<213> 智人(Homo sapiens)
<400> 62
Glu Asn Tyr Ser Phe Leu Pro Leu Val
1 5
<210> 63
<211> 8
<212> PRT
<213> 智人(Homo sapiens)
<400> 63
Tyr Ser Phe Leu Pro Leu Val His
1 5
<210> 64
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 64
Arg Ala Arg Glu Glu Glu Asn Tyr Ser Phe Leu
1 5 10
<210> 65
<211> 8
<212> PRT
<213> 智人(Homo sapiens)
<400> 65
Glu Asn Tyr Ser Phe Leu Pro Leu
1 5
<210> 66
<211> 10
<212> PRT
<213> 智人(Homo sapiens)
<400> 66
Arg Ala Arg Glu Glu Glu Asn Tyr Ser Phe
1 5 10
<210> 67
<211> 11
<212> PRT
<213> 智人(Homo sapiens)
<400> 67
Tyr Ser Phe Leu Pro Leu Val His Asn Ile Ile
1 5 10
<210> 68
<211> 22
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人工序列的描述:
合成肽
<400> 68
Gln Ser Pro Ala Arg Ala Arg Glu Glu Glu Asn His Ser Phe Leu Pro
1 5 1015
Leu Val His Asn Ile Ile
20
<210> 69
<211> 22
<212> PRT
<213> 智人(Homo sapiens)
<400> 69
Gln Ser Pro Ala Arg Ala Arg Glu Glu Glu Asn Tyr Ser Phe Leu Pro
1 5 1015
Leu Val His Asn Ile Ile
20
- 癌症新抗原和其在癌症疫苗和基于TCR的癌症免疫疗法中的效用
- 用于治疗癌症的新抗原疫苗组合物