一种网络流量入侵检测方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于网络安全领域,具体涉及一种网络流量入侵检测方法。
背景技术
网络入侵检测是指对计算机网络中的异常流量和非法访问行为进行检测和识别的过程。它是保护计算机网络安全的重要手段之一。网络入侵检测系统(NIDS)能够监控和分析网络上传输的流量数据包,识别恶意流量和网络攻击行为。目前的网络入侵检测方法可以分为基于特征的检测方法和基于异常的检测方法。
传统的基于特征检测的入侵检测系统通过定义预先规定的规则或模式,对网络流量进行分类和识别,以判断是否存在异常行为或攻击行为。这种方法的优点是易于理解和解释,但需要人工定义规则,且对新型网络攻击,如0day攻击等检测效果较差。
为了提高对于未知漏洞攻击的检测效果。基于异常的入侵检测算法逐渐成为研究者的关注重点,其主要基于机器学习算法来实现。使用最多的传统机器学习算法有随机森林,SVM等算法。然而,传统机器学习算法同样存在弊端,例如,随机森林训练速度快,对于不平衡的数据集可以平衡误差,但在一些有噪声的分类中会出现过拟合。而支持向量机虽然避免产生局部最优解,但它只解决小样本问题。随着网络攻击的不断多样化,网络数据特征越来越复杂,传统的入侵检测技术无法很好地提取数据特征以获取有效信息,使得入侵检测的检测率下降,误检率上升。
在互联网时代网络流量繁多冗杂的背景下,亟需一种检测速度快,准确率高的轻量级高性能入侵检测方法,以较低的时空代价实现针对网络攻击流量的威胁检测功能。
发明内容
针对现有技术存在的不足,本发明提出了一种网络流量入侵检测方法,该方法包括:
S1:获取训练数据集并将其划分为训练集和测试集;
S2:对训练集进行预处理,得到训练特征向量;
S3:将训练特征向量输入到网络流量入侵检测模型中,并采用粒子群优化算法对网络流量入侵检测模型进行参数调优,得到训练好的网络流量入侵检测模型;
S4:采用训练好的网络流量入侵检测模型对测试集进行处理,得到入侵检测结果。
优选的,对训练集进行预处理的过程包括:
S21:采用二维矩阵存储训练集的特征信息,得到第一特征矩阵;
S22:对第一特征矩阵进行归一化处理,得到第二特征矩阵;
S23:对第二特征矩阵中的字符类特征进行独热编码,得到第一数据特征;
S24:对第二特征矩阵中的数字型特征进行降维处理,得到第二数据特征;
S25:组合第一数据特征和第二数据特征,得到训练特征向量。
优选的,对第二特征矩阵中的数字型特征进行降维处理的过程包括:
将第二特征矩阵中的数字型特征按照标签分布划分为多数类样本S
对组合样本分别使用DBSCAN算法进行密度聚类,得到聚类集合和边界点集合;在每个组合样本中根据边界点集合找到边界点的反向k最近邻样本集合;计算边界点与其反向k最近邻样本之间径向距离;
根据边界点与其反向k最近邻样本之间径向距离计算密度影响阈值d
其中,x
定义临界阈值α表示所有组合样本的d
使用DBSCAN密度算法对集合
采用费舍尔判别分析法计算所有聚类集合以及m个特征子空间中特征的费舍尔值,并按照其费舍尔值进行排序,选取排序前S个特征作为第二数据特征。
优选的,所述网络流量入侵检测模型由输入层、隐藏层、Dropout层和全连接层级联组成。
进一步的,所述输入层为一维卷积,隐藏层包括第一层最大池化、第一批归一化层、第一层BiLSTM、Reshape层、第二最大池化层、第二批归一化层和第二层BiLSTM。
优选的,采用粒子群优化算法对网络流量入侵检测模型进行参数调优的过程包括:
将卷积核数量、第一层BiLSTM神经元数量、Dropout值和学习率表示为粒子,初始化粒子参数;
将模型性能指标作为适应度,更新粒子的速度和坐标;根据粒子的速度和坐标更新适应度值;
当满足迭代次数或两次迭代之间的适应度值最小时,得到优化完成的网络流量入侵检测模型。
进一步的,更新粒子的速度和坐标的公式为:
其中,
进一步的,适应度的计算公式为:
fit=PCB(cn,ls,dr,lr)
其中:fit表示适应度值,PCB()表示粒子群算法的优化函数,cn表示卷积核数量,ls表示第一层BiLSTM神经元数量,dr表示Dropout参数,lr表示学习率。
本发明的有益效果为:
本发明提出了一种高效益的入侵检测模型PCB,在对数据集进行DBIM特征选择的基础上,结合并改进此前研究者提出的CNN-BiLSTM模型,对模型的整体构建和资源配置进行了优化,同时使用粒子群优化算法PSO对模型设计的超参数进行调优,在满足入侵检测模型高准确率、低误报率的基础上最小化时间成本开销。
附图说明
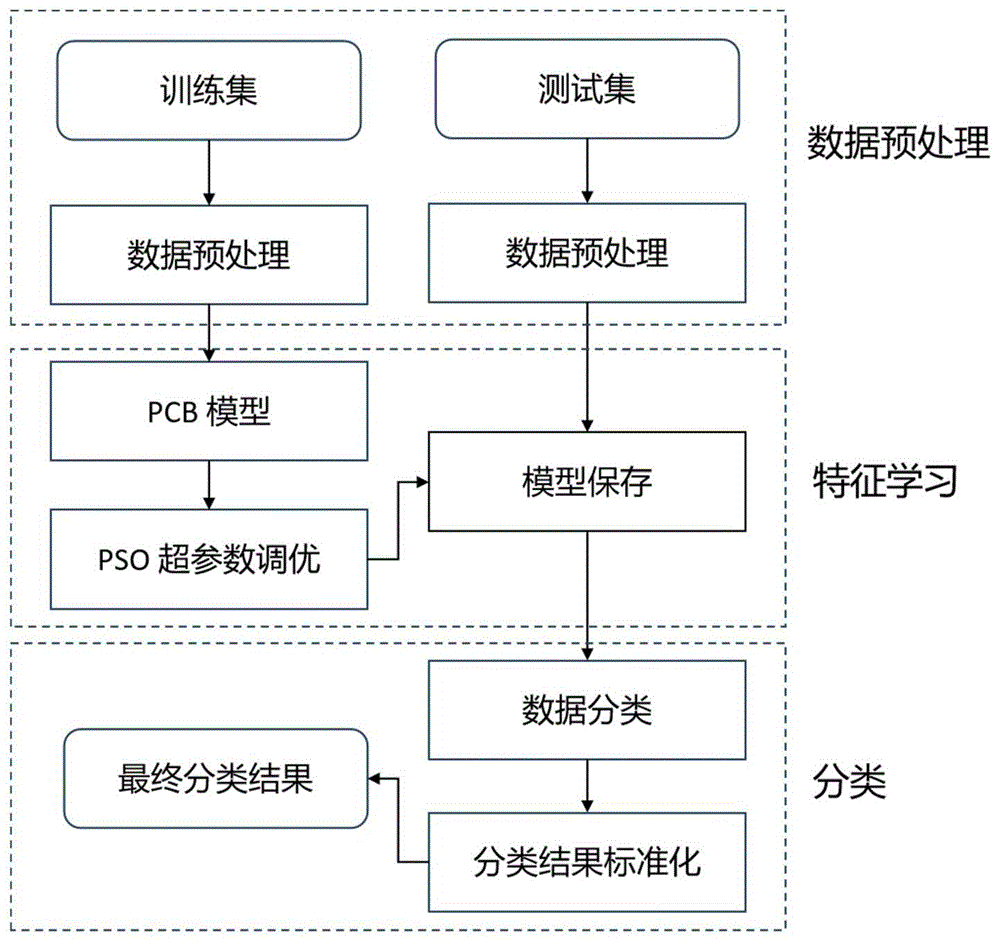
图1为本发明中网络流量入侵检测过程示意图;
图2为DBSCAN密度聚类过程示意图;
图3为本发明中网络流量入侵检测模型层数设置示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提出了一种网络流量入侵检测方法,如图1所示,所述方法包括以下内容:
S1:获取训练数据集并将其划分为训练集和测试集。
优选的,可使用KDDCup99数据集或NSL-KDD数据集作为训练数据集。
S2:对训练集进行预处理,得到训练特征向量。
S21:采用二维矩阵存储训练集的特征信息,得到第一特征矩阵。
在第一特征矩阵中,行表示不同数据流量,列表示每条网络流量的特征信息。
S22:对第一特征矩阵进行归一化处理,得到第二特征矩阵。
归一化的目的是通过降低数据分布的不平衡性来提高模型训练的速度和性能;本发明采用Min-Max方法进行归一化,将数据的范围缩放至[0,1],其计算公式为:
其中,x′表示归一化后的特征,x表示原特征,x
S23:对第二特征矩阵中的字符类特征进行独热编码,得到第一数据特征。
独热编码可以将离散特征转换成连续型特征,使得模型可以更好地处理这些特征。同时,独热编码还可以避免离散特征之间的大小比较和算术运算,从而避免模型对离散特征进行错误的假设。
将第二特征矩阵中的字符类特征protocol_type、service和flag进行独热编码,转化为用于训练模型的特征向量,得到第一数据特征。
S24:对第二特征矩阵中的数字型特征进行降维处理,得到第二数据特征;
优先的,采用特征选择算法DBIM对第二特征矩阵中的数字型特征进行降维处理;特征选择算法DBIM主要包括基于密度聚类的特征集成和基于重要性度量的特征选择两个部分。
在特征集成方面,如图2所示,采用一种优化的DBSCAN算法对数据进行处理。传统的DBSCAN算法流程如下:对于数据集S={x
将第二特征矩阵中的数字型特征根据按照标签分布划分为多数类样本S
对S
计算边界点(x
其中,
定义密度影响阈值d
其中,x
定义临界阈值α表示所有组合样本的d
使用DBSCAN密度算法对集合
特征选择方面,采用费舍尔判别分析(Fisher Discriminant Analysis,FDA)法作为特征评价标准。该方法对于训练数据集X=[x
特征i的费舍尔值为:
其中,n
对于所有通过特征集生成的特征子空间即所有聚类集合以及m个特征子空间,计算其中特征的费舍尔值(根据类间离散度大且类内离散度小这一原则,当特征的费舍尔值越大,代表这一特征具有更高的可分类性),将特征按照其费舍尔值进行组内排序,选取排序前S个特征作为第二数据特征;S可通过划分的聚类簇数量以及模型的分类效果多次实验得到最优的特征选择结果进行合理选取。
本发明利用费舍尔值检验特征与类标签之间的相关性,并依照重要性度量原则,选出对分类器有较大贡献的特征作为数据集降维后的结果。
S25:组合第一数据特征和第二数据特征,得到训练特征向量。
S3:将训练特征向量输入网络流量入侵检测模型中,并采用粒子群优化算法对网络流量入侵检测模型进行参数调优,得到训练好的网络流量入侵检测模型。
如图3所示,网络流量入侵检测模型由输入层、隐藏层、Dropout层和全连接层级联组成;隐藏层包括第一层最大池化、第一批归一化层、第一层BiLSTM、
Reshape层、第二最大池化层、第二批归一化层和第二层BiLSTM。输入数据最终经过全连接层输出分类结果。
向网络中输入训练特征向量,经过模型处理后,可输出入侵检测结果即每个入侵记录的攻击类型。
本发明提出的网络流量入侵检测模型采用一维卷积作为输入层,并在每层BiLSTM之前添加最大池化层和批归一化层。最大池化能有效消除输入数据中不相关的特征,批归一化层用于规范前一个中间层的输出数据以提高性能并减少训练时间。
经过卷积神经网络的数据再经过两层BiLSTM继续进行训练,BiLSTM神经网络在LSTM的基础上增加了一个反向LSTM层,双向网络对序列的起点和终点的隐层状态进行递归响应训练,可以进一步挖掘当前数据与前一刻数据以及未来时刻数据之间的某种关系,从而进一步处理反向信息,优化长期依赖关系,提高模型的预测精度。BiLSTM的输出值由正向隐藏层和反向隐藏层共同决定,其正向隐藏层的输出和反向隐藏层的输出分别为以下公式:
其中,
Dropout可以避免过度拟合并提高基础神经网络的准确性,本发明使用Dropout防止模型过度拟合,并将结果输出到全连接层中,使用softmax获得训练结果,判断网络流量的异常情况与攻击类型。
采用粒子群优化算法对网络流量入侵检测模型进行参数调优的过程包括:
将卷积核数量、第一层BiLSTM神经元数量、Dropout值和学习率表示为粒子,初始化粒子参数;粒子参数包括:粒子群规模N,粒子维度D,迭代次数,惯性权重,学习因子,迭代步长范围,人体历史最优位置,群体历史最优位置,个体历史最优适应度值,群体历史最优适应度值。
粒子的卷积核数量初始化范围为[1,80],第一层BiLSTM神经元数量的初始化范围为[10,100],Dropout值的初始化范围为[0.1,0.8],学习率的初始化范围为[0.0001,0.01]。
种群中任何一个粒子i的状态由2个量来确定,即粒子的位置和速度,分别记为X
将模型性能指标作为适应度,更新粒子的速度和坐标;根据粒子的速度和坐标更新适应度值;优选的,本发明的适应度的计算公式为:
fit=PCB(cn,ls,dr,lr)
其中:fit表示适应度值,PCB()表示粒子群算法的优化函数,cn表示卷积核数量,ls表示第一层BiLSTM神经元数量,dr表示Dropout参数,lr表示学习率。
更新粒子的速度和坐标的公式为:
其中,
适应度值优于个体最佳值,则更新个体最佳值;若得到的粒子适应度值优于群体极值,则更新群体极值。当满足迭代次数或两次迭代之间的适应度值最小时,得到优化完成的网络流量入侵检测模型。
S4:采用训练好的网络流量入侵检测模型对测试集进行处理,得到入侵检测结果。
将测试集输入到训练好的网络流量入侵检测模型中,可得到测试集的入侵检测结果即测试集中每条流量记录的攻击类型。
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种改进的ConvLSTM的网络流量入侵检测方法
- 一种基于大数据的网络流量入侵检测方法