基于深度可分离卷积和金字塔池化的视频语义分割方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于计算机视觉技术领域,涉及图像处理技术,特别地涉及一种基于深度可分离卷积和金字塔池化模块的街景视频语义分割方法。
背景技术
视频语义分割算法某种意义上是对图像语义分割的更进一步研究,起初视频语义分割的研究者们对视频中的每一帧单独应用图像语义分割算法进行分割,显然这种方式并没有利用到视频帧之间的时序信息。由于视频语义分割标注数据稀缺等原因,目前尚未有有效的视频语义分割方法。
现有的视频语义分割技术中,Netwarp利用相邻帧的光流结合CNN结构来提高分割精度。光流法是计算机视觉早期的常用方法,它是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法,总而言之光流能够在视频帧之间建立时间上的联系。在视频语义分割技术领域中,还有诸多借助光流进行分割预测的算法。例如,GRFP(GatedRecurrent Flow Propagation,门控循环流传播)提出了一种深度的、端到端可训练的视频语义分割方法,该方法能够利用未标记数据中的信息来提高语义估计,结合了卷积架构和空间转换器循环层,能够通过光流的方式在时间上传播标记信息,根据其局部估计的不确定性自适应控制。EFC(Every Frame Counts,每帧计数)提出了一种联合视频语义分割和光流估计的新框架。这种框架能够同时保证光流估计的稳定性和分割的时间一致性,充分利用语义信息和邻近帧信息,一定程度上提高了分割的精度。但光流有难以避免的缺点,一是分割结果过于依赖光流预测的质量;二是光流的引入在增加模型复杂度的同时增加了计算负载,给原本就复杂的视频语义分割模型带来了沉重的负担。TMANet(Temporal MemoryAttention Network,时序记忆注意力网络)通过时间注意力编码结构构建长期时间上下文信息,提升模型的精度。但这些模型较少考虑到模型效率和全局信息特征提取的问题。因此,现有的视频语义分割技术存在分割精度不足和模型运算量大的问题。
发明内容
为了克服上述现有技术存在的不足,本发明提供一种基于深度可分离卷积和金字塔池化的视频语义分割方法,构建街景视频语义分割深层神经网络模型,使该网络模型在分割街景视频时在保证提取到时序信息的同时关注到每帧图像的上下文关系和全局特征,并减少一定的计算量,从而解决了街景视频语义分割时分割精度不足和模型运算量大的问题,使街景视频处理精度更高,提升视频语义分割效果。
本发明为解决上述技术问题采用以下技术方案:
一种基于深度可分离卷积和金字塔池化模块的街景视频语义分割方法,通过对时序记忆注意力网络TMANet的结构进行改进,构建基于深度可分离卷积和金字塔池化模块的街景视频语义分割模型,采用深度可分离卷积网络结构,且在模型的分割头之前加入了金字塔池化模块,即在TMANet的编码层加入深度可分离卷积和分割头之前添加金字塔池化模块,实现视频语义分割,包括训练阶段和测试阶段两个过程。包括如下步骤:
1)数据集制作:
视频语义分割模型需要原始图片和带有标签的图像作为输入进行模型的训练。由于原始数据集不满足模型输入的要求,本方法要先进行数据集的制作。主要分为视频分帧和标注图片的制作两步:
1_1)视频分帧
通过AR,PE等视频处理软件可以进行视频分帧,但其分帧速度过慢,本发明具体实施时,采用ffmpeg视频处理工具进行视频分帧。原始视频的帧率为60帧每秒(fps=60),帧率越高,所提取的时间信息越细致,但同时也意味着数据量的成倍增大,权衡设备限制与效果后,本发明采取四种分帧帧率,分别为:1帧/s、2帧/s、3帧/s、4帧/s。
1_2)标注图像的制作
视频语义分割模型会需要大量的图片,而对每一张图片都进行标注,会费时费力,目前视频语义分割的主流做法是采取固定间隔标注的方法。参考公共数据集cityscapes的视频数据制作标准,对自制数据集每隔三十帧标注一帧。
在标注类别的选择上,本发明以城市街景为切入点,将建筑物、植被、道路、天空、车辆五类作为标注对象用来进行视频语义分割。详细标注过程为:首先用labelme生成json格式的标签数据,然后生成相应的mask掩码,再转换成灰度图用来训练。
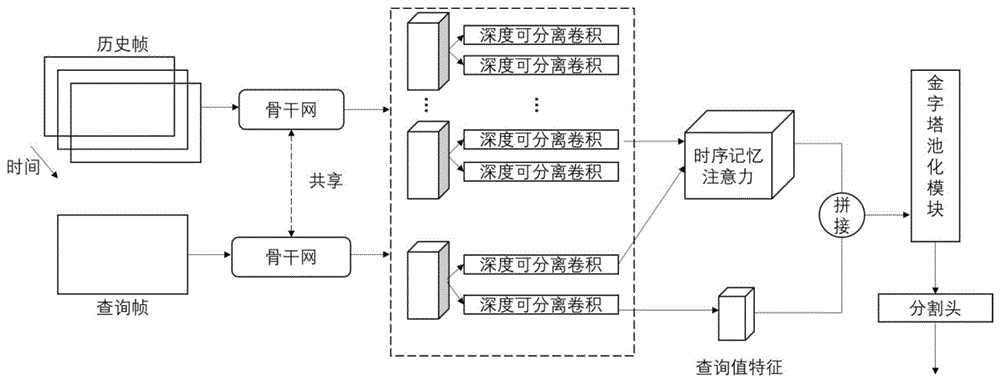
2)基于TMANet网络构建街景视频语义分割模型;包括:共享主干网、编码层、时序记忆注意力模块、金字塔池化模块;模型还包括深度可分离卷积和分割头;其中,共享主干网用于提取街景视频语义特征;编码层用于对提取的街景视频语义特征进行通道缩减和特征提取;时序记忆注意力模块用于构建长时间上下文信息;金字塔池化模块用于进一步提取图像上下文特征和全局特征;
步骤1、将N个历史帧(待分割视频帧的前几帧,或称内存帧)与查询帧(待分割视频帧)输入到所构建街景视频语义分割模型的共享主干网中提取得到视频帧(历史帧和查询帧)特征;
步骤2、编码层编码。由于共享主干网的输出特征维度较高,会使模型参数量倍增对后续模型计算产生不利影响,所以接着将提取到的视频帧特征送入编码层(EncodingLayers)进行通道缩减和特征提取,可得到视频帧(历史帧和查询帧)的值特征和键特征。
步骤3、时序记忆注意力模块(Temporal Memory Attention,TMA)。
通过编码层对历史帧和查询帧通过共享主干网得到的视频帧特征的不同表示进行编码,然后通过时序记忆注意力模块构建长时间上下文信息;同时将通过编码层得到的查询帧的值特征与长时间上下文信息相聚合,增强查询帧的表示性。步骤4、将聚合后的特征,经过金字塔池化模块(Pyramid Pooling Module,PPM)进一步提取得到街景视频图像上下文特征和全局特征,最后1x1卷积的分割头输出当前帧的最终分割结果。
进一步的,所述步骤1中的共享主干网提取特征的具体步骤如下:
给定一个包含T帧的历史帧序列和一个包含单个帧X∈R
Stage1:对输入数据进行预处理。首先经过共享主干网的卷积操作,卷积核大小为7x7,卷积核数量为64,步长stride为2;然后,通过共享主干网的BN(Batch Normalization,批处理归一化)层进行批处理归一化;最后,通过共享主干网的R
Stage2:通过叠加3个共享主干网的Bottleneck layer(瓶颈层)结构进行特征提取。此阶段的Bottleneck layer结构进行特征提取的过程为:首先使用64个1x1卷积对数据进行降维;然后,使用64个3x3的常规卷积进行卷积;最后用256个1x1卷积对数据进行升维。
Stage3:通过叠加4个Bottleneck layer结构进行特征提取。此阶段的Bottlenecklayer结构进行特征提取的过程为:首先使用128个1x1卷积对数据进行降维;然后,使用128个3x3的常规卷积进行卷积;最后用512个1x1卷积对数据进行升维。
Stage4:通过叠加6个Bottleneck layer结构进行特征提取。此阶段的Bottlenecklayer结构进行特征提取的过程为:首先使用256个1x1卷积对数据进行降维;然后,使用256个3x 3的常规卷积进行卷积;最后用1024个1x1卷积对数据进行升维。
Stage5:通过叠加3个Bottleneck layer结构进行特征提取。此阶段的Bottlenecklayer结构进行特征提取的过程为:首先使用512个1x1卷积对数据进行降维;然后,使用512个3x 3的常规卷积进行卷积;最后用2048个1x1卷积对数据进行升维。
进一步的,所述步骤2中的编码层编码的具体步骤如下:
编码层采用深度可分离卷积结构。深度可分离卷积(Depthwise separableconvolution,DSC)将标准卷积分解为深度卷积(Depthwise Convolution)和称为点卷积(Pointwise Convolution)的1×1卷积,常规卷积在卷积过程中对应图像区域中的所有通道均被同时考虑。而深度可分离卷积打破了这层瓶颈,将通道和空间区域分开考虑,对不同的输入通道采取不同的卷积核进行卷积,它将普通的卷积操作分解为两个过程,目的是希望能用较少的参数学习更丰富的特征表示。其具体流程及其运算量计算如下:
Step1:深度卷积,不同于原始卷积,深度卷积是一个卷积核负责一个通道,独立地在每个通道上进行空间卷积。深度卷积产生与输入特征图数量相等的输出特征图。
假设输入的特征图尺寸为D
C
Step2:点卷积:由于一个特征图仅被一个滤波器卷积,无法有效的利用不同通道在相同空间位置上的特征信息,由此加入了点卷积。点卷积主要是要1×1卷积构成,负责将深度卷积的输出按通道投影到一个新的特征图上。新的特征图包括历史帧和查询帧的键特征和值特征。
深度可分离卷积第二步点卷积的计算量C
C
深度可分离卷积的总计算量A
A
进一步的,所述步骤3中的时序记忆注意力模块的具体流程如下:
时序记忆记忆力模块获得T个通过编码层编码的历史帧的键特征和值特征,将T个历史帧在时间维度上拼接生成一个四维的矩阵。对历史帧的键特征,通过排列和重塑得到
进一步的,所述步骤4中的金字塔池化模块的具体流程如下:
金字塔池化模块融合了四个不同金字塔尺度(层次)下的特征。下面的金字塔层将特征图划分为不同的子区域,并为不同的子区域位置形成池化表示。为了保持全局特征的权重,当金字塔的级别大小为N时,本发明在每个金字塔层后使用1×1卷积层将上下文表示的维数降为原始特征图的1/N。对不同子区域的不同大小的特征图进行上采样,然后通过双线性差值得到与原始特征图相同大小的特征。最后,将不同层次的特征串联起来,形成最终的金字塔汇集全局特征。总之,金字塔池化模块是通过不同的感受野形成四个不同的金字塔尺度特征,然后进行双线性插值上采样与原特征拼接,形成最终的全局特征。
3)街景视频语义分割模型的训练;
3_1)将训练集中原始的街景视频帧{Q
3_2)计算训练集中的每幅原始的街景图像对应的语义分割预测图构成的集合
具体实施时,采用分类交叉熵获得
3_3)重复执行步骤31)和步骤32)共L次,得到深度神经网络分类训练模型,并共得到L×N个损失函数值;然后从L×N个损失函数值中找出值最小的损失函数值;接着将值最小的损失函数值对应的权值矢量和偏置项作为深层神经网络分类训练模型对应的最优权值矢量和最优偏置项,对应记为W
4)测试模型:将测试集输入到已训练好的模型中进行测试
4_1)令
4_2)将
通过上述步骤,即可实现基于深度可分离卷积和金字塔池化模块的街景视频语义分割。
与现有技术相比,本发明的有益效果在于:
第一,本发明构建街景视频语义分割网络模型采用深度可分离卷积结构(去掉原网络模型中的1x1卷积和3x3卷积组合)。
假设输入的特征图尺寸为D
A
则由式(3)和式(4)可知,深度可分离卷积与常规卷积计算量之比为式(5):
通过计算可以看出深度可分离卷积大大降低了计算量,减少模型参数;同时,也不像1x1卷积那样损失空间信息。
第二,构建街景视频语义分割网络模型时,在分割头之前加入了金字塔池化模块。金字塔池化模块可以弥补一般的视频语义分割模型在对每帧图片分割时上下文信息和不同感受野的全局信息捕获不足的问题,本发明方法构建的深层神经网络融入的金字塔池化模块,使网络模型在特征提取的过程中拥有更好全局信息获取能力,使模型的准确率更高。
附图说明
图1为本发明方法的流程框图。
图2为本发明方法构建的街景视频语义分割模型的组成结构框图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于深度可分离卷积和金字塔池化模块的街景视频语义分割方法,构建街景视频语义分割深层神经网络模型,使该网络模型在街景视频语义分割时具有更强的全局特征获取能力和更少的模型计算量,模型整体的鲁棒性更好,提升图像分割效果。
本发明提出的一种基于深度可分离卷积和金字塔池化模块的街景视频语义分割方法总体流程框图如图1所示,其包括训练阶段和测试阶段两个过程。
图2为本发明方法构建的街景语义分割神经网络模型的组成结构图。利用本发明方法实现基于深度可分离卷积和金字塔池化模块的街景视频语义分割主要包括以下步骤:
1)首先对视频分帧生成的图像,对当前要进行分割的帧和选取的T帧记忆帧序列(memory sequence)同时输入到共享的骨干网络(Backbone)中进行初步的特征提取;
2)经过1)骨干网的特征提取后,将提取的特征输入到编码层(Encoding Layers)进行通道缩减和进一步的特征提取,获取更深层次的特征;
3)将记忆帧的key特征和value特征与当前帧的关key特征输入到时序记忆注意力模块构建长时间上下文信息;
4)将通过时序记忆力模块构建得到的具有长时间上下文信息的特征与当前帧的
5)将4)拼接后的特征输入到金字塔池化模块进一步进行全局信息的提取
6)添加一个由1x1卷积实现的分割头(Segmentation Head)来生成预测的分割图像
具体实施时,本发明方法的街景视频语义分割神经网络模型训练阶段过程的具体步骤为:
1.构建图像训练集:选取N幅原始的街景视频帧图像及对应的语义分割标签灰度图,并构成训练集,将训练集中的第n幅原始的街景图像记为Q
2.构建深层神经网络:深层神经网络包括输入层、隐藏层和输出层;隐藏层由四部分组成:骨干网络Backbone、编码层Encoding Layers、时序记忆注意力模块TMA、金字塔池化模块PPM。
2_1对于输入层,输入层的输入端接收一副原始输入图像的R、G、B三通道分量,输入层的输出端输出原始输入图像的R通道分量、G通道分量和B通道分量给隐藏层;其中,要求输入层的输入端接收的原始输入图像的宽度为W,高度为H;
22隐藏层的第一部分为骨干网络Resnet50。Resnet50的核心结构为跳跃连接(skip connection)。跳跃连接在第二层激活函数之前添加了一个连接,使激活函数的输入就由原来的输出H(x)=F(x)变为了H(x)=F(x)+x。通过这种方式,实现输出等于输入恒等映射操作。
2_3隐藏层的第二部分为编码层。编码层采用深度可分离卷积结构,深度可分离卷积由深度卷积和点卷积两层组成。
使用深度卷积对每个输入通道应用单个滤波器。然后使用点卷积(1×1卷积)来创建深度层输出的线性组合。
每个输入通道有一个滤波器的深度卷积的输出特征图
其中,
经过深度卷积过滤输入通道之后,需要组合每个通道的特征。因此,为了生成这些新特征,通过第二层点卷积计算深度卷积输出的线性组合。
2_4隐藏层的第三部分为时序记忆注意力模块。时序记忆记忆力模块获得T个通过编码层编码的内存帧的键特征和值特征,将T个内存帧在时间维度上拼接生成一个四维的矩阵。对内存帧的键特征,通过排列和重塑得到
其中S
2_5隐藏层的第四部分为金字塔池化模块。金字塔池化模块可以通过捕获不同尺度上的空间相信减少上下文信息的损失。金字塔池化模块在四个不同的金字塔尺度下融合了特征。为了保持全局特征的权重,在每个金字塔层之后使用1×1的卷积层。如果金字塔的层数为N,将上下文表征的维度降低到原来的1/N。然后,我们直接对低维特征图进行上采样,通过双线性插值得到与原始特征图相同大小的特征。最后,不同级别的特征图被拼接起来作为最终的金字塔池化全局特征。在金字塔池化模块中,金字塔层数的数量和每个级别的尺寸都可以修改。它们与输入金字塔的特征图的大小有关。该结构通过采用不同大小的池化核来提取出不同的子区域。因此,不同的池化核应该保持合理的梯度间距。将四级的金字塔池化模块四个池化核大小分别设为1×1、2×2、3×3和6×6。
2_6对于输出层,其由1个卷积层组成,输出层的输入端接收经过金字塔池化模块输出的特征图,输出层的输出端输出与原始输入图像对应的语义分割预测图;其中,每帧语义分割预测图的宽度为W、高度为H。
2_7将训练集中原始的街景图像和对应的语义分割标签灰度图像作为原始输入图像,输入到深层神经网络中进行训练,得到训练集中的每帧原始的街景图像对应的语义分割预测图,将每帧原始的街景图片{Q
2_8计算训练集中的每帧原始的街景图像对应的语义分割预测图构成的集合与对应的真实语义分割图像处理成的独热编码图像集合之间的损失函数值,将与之间的损失函数值记为采用分类交叉熵(categoricalcrossentropy)获得。
2_9重复执行步骤2_7和步骤2_8共L次,得到深度神经网络分类训练模型,并共得到L×N个损失函数值;然后从L×N个损失函数值中找出值最小的损失函数值;接着将值最小的损失函数值对应的权值矢量和偏置项作为深层神经网络分类训练模型对应的最优权值矢量和最优偏置项,对应记为W
3测试模型:将测试集输入到已训练好的模型中进行测试。所述的测试阶段过程的具体步骤为:
3_1令
3_2将
通过上述步骤,即可实现一种基于深度可分离卷积和金字塔池化模块的街景视频语义分割模型。
- 一种基于空间金字塔掩盖池化的弱监督图像语义分割方法
- 一种基于扩张点卷积空间金字塔池化的点云语义分割方法
- 基于多分支深度可分离空洞卷积的实时语义分割方法