一种多维度信息融合智慧档案管理系统
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及档案管理领域,尤其涉及一种多维度信息融合高校档案智能管理方法。
背景技术
随着信息技术以及信息产业的高速发展,以数字化、网络化、智能化、智慧化为特征的信息化浪潮蓬勃兴起。信息化在社会各个领域中得到了广泛深入应用,档案信息化成为档案管理的必然发展趋势,档案工作逐步从传统管理模式向信息化时代迈进。
高校档案工作经过不断的努力,有了长足进步但在信息化快速发展的社会背景下,以智慧、智能发展为代表的信息化建设驱动社会发展、建设现代化社会目标的今天,国内高校目前的档案工作还存在着明显的技术、方法和管理手段等方面的不足,对于归档的整理与编研,馆藏静态资源转换为动态资源,仍需手动完成。
档案数据存在数据类型多、耦合度不同、语义不一致等特征问题,无法直接建立系统数据之间的关联关系,同时由于数据的组合经常会造成高冲突的情形,因此组合高冲突性的数据,使其修正完成正确融合,是后续智能服务提供数据基础。对现有高校档案管理系统数据进行统一的融合管理,深入挖掘其数据价值,建设数据平台有重要的意义,因此,如何构智能的可调和冲突数据的多维度高校档案管理系统成为亟需待解决的问题。
发明内容
本发明所要解决的技术问题是克服现有档案管理系统对于档案中的数据整合利用不充分的问题,提供一种智能档案管理系统。
多维度信息融合利用是新时代档案发展新方向,信息资源集中于互联网的今天,开辟新的信息获取途径势在必行。结合高校档案管理工作要求,在智慧档案管理系统之上多维度信息融合子系统,利用数据交换服务子系统将内外网档案相关信息进行采集、过滤、融合以及分析,增加档案资源价值,提高利用能力。
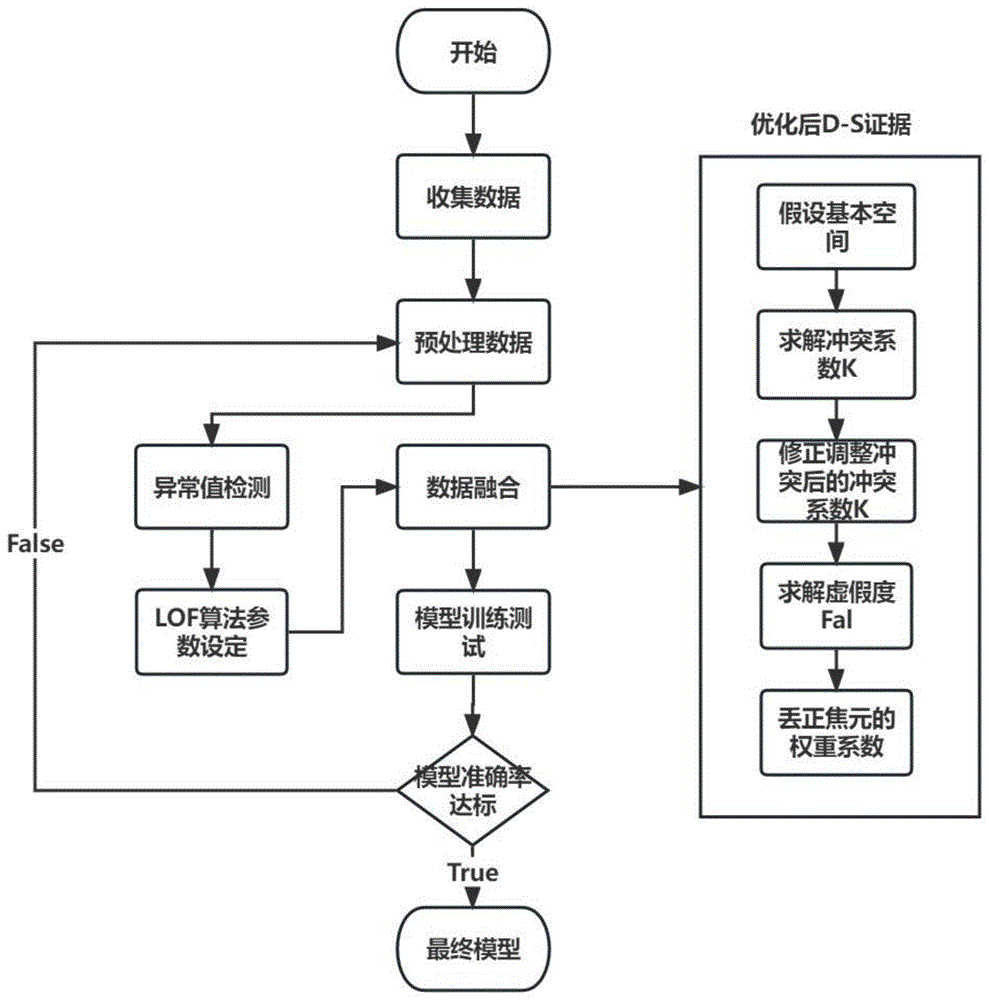
基于D-S证据的多维度高校档案管理方法,包括如下步骤:
步骤1、收集数据:收集高校管理的相关数据,所述相关数据包括高校师生个人信息中的年龄、性别、身份证号码、校园卡ID,个人图书借阅信息中的借阅书目的编码、借阅时间、到期时间,日常办公电子档案中的文件号、经办人校园卡ID号,库房监控视频、电子签章;
步骤2、预处理数据:对步骤1中收集得到的所述相关数据执行数据清洗、自动分类,数据修复,并完成局部数据库基础映射表;
步骤3、数据分类:对档案中已有的数据进行分类模型的构建,对采集到的信息进行分类,并利用异常值检测算法验证分类后的数据是否可以沟通正常,即数据通过异常值检测算法测试后,异常点的比例占比小于等于5%;
步骤4、数据融合:将档案中已有的数据和步骤2预处理得到的数据利用D-S证据方法进行融合处理,其中步骤4包括以下子步骤:
步骤4-a-1、定义基本假设空间X,假设空间X中包含N个完备且互不相容假设命题元素A
步骤4-a-2、利用归一化规则,对分配函数进行修正,满足
步骤4-a-3、对于来自步骤1中的不同数据,冲突系数可以表示为,
去除经过步骤3异常值检测算法判定为异常值的数据后,调整后的冲突系数表示为,
虚假度Fal表示为,其中K
步骤4-a-4、减小证据冲突的影响,对焦元的权重重新进行分配修正,修正后的权重表示为:
步骤4-a-5、将步骤4-a-4修改焦元权重后得到的信任度和虚假度进行排序,并对步骤1中的各项数据进行加权平均,并通过D-S理论证据合成规则完成特征属性的融合;
优选地,所述步骤4后还包括对融合结果的模型进行训练测试,对准确率达到90%的模型可用于后续数据融合,对于准确率不足90%的模型返回步骤2重新对数据进行预处理。
优选地,步骤1-a-5的数据合成规则采用正交和运算
通过归档整理将档案材料保存到档案库中,以及通过网络接口或爬虫技术来收集内网和外网的信息保存到资料库中,然后通过数据清洗、主题提取、关键字提取、分类处理、内容推测等进行信息的融合,保存到融合库中,对于后续融合库中的数据进行数据分析,进行资料查询、趋势分析、指数分析、舆情分析均十分便捷如下:
1)对接单位内网信息系统,收集内网信息资源。
2)通过网络爬虫采集外网指定平台指定内容主题信息。
3)具有信息融合算法模块,对内外网数据与档案数据进行融合处理。
4)创建融合资料库,对库中资料进行管理。
优选地,步骤1中数据采集的来源有内网数据和外网数据,获取的方式为接口调取以及网络爬虫。通过接口调取以及爬取收集到的和系统中原先存在的共计包括1000条数据,按照80%的比例划分,训练集包含800条数据,测试集包含200条数据,通过将训练集数据作为步骤1收集数据的高校管理的相关数据,进而进行模型的训练。
优选地,步骤3中的异常值检测算法为基于密度的离群点检测方法,关键步骤在于给每个数据点都分配一个离散度,其主要思想是:针对给定的数据集,对其中的任意一个数据点,如果在其局部邻域内的点都很密集,那么认为此数据点为正常数据点;而离群点则是距离正常数据点最近邻的点都比较远的数据点。通常有阈值进行界定距离的远近。通过比较每个样本和其邻域样本的分布密度,进而判断异常点。
优选地,步骤2预处理数据过程中合并LDA主题分类模型对主题进行提取,词频统计进行关键词提取。
本发明的有益效果:本发明结合高校档案管理的异构数据组合出现的高冲突的情形,利用主题分类模型结合改进后的D-S证据方法,使其修正完成正确融合,大大减小了冲突发生的概率,是后续智能服务提供数据基础。对现有高校档案管理系统数据进行统一的融合管理,深入挖掘其数据价值,建设数据平台有重要的意义。
表1数据融合测试正确率对比
附图说明
图1是基于D-S证据的多维度高校档案管理整体流程
图2是档案数据融合流程
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
基于D-S证据的多维度高校档案管理方法,其具体实施方式为:
步骤1、收集数据:为保证数据选择的正确性,尽量优选出合适的数据对象来进行数据融合,若数据对象选择错误将直接影响到多维度信息的后期融合效果。数据选择时首先要根据用途来判定需要选择的数据类型,可供选择的数据类型有两种分别是内网数据和外网数据。通过数据交换平台,在预先选好的数据源中通过接口调取或者通过爬虫进行信息获取。收集高校管理的相关数据,所述相关数据包括高校师生个人信息中的年龄、性别、身份证号码、校园卡ID,个人图书借阅信息中的借阅书目的编码、借阅时间、到期时间,日常办公电子档案中的文件号、经办人校园卡ID号,库房监控视频、电子签章;
步骤2、预处理数据:对步骤1中收集得到的所述相关数据执行数据清洗、自动分类,数据修复,并完成局部数据库基础映射表;
其中数据清洗过程包括将高校师生个人信息中的数值型数据,例如高校师生个人、日常办公电子档案、库房监控视频、电子签章的空缺值进行忽略,以及对数据格式不符合的数据重新输入,例如个人身份证号码不匹配的需要重修修正。
步骤3、异常值检测:对档案中已有的数据进行分类模型的构建,对采集到的信息进行分类,并利用异常值检测算法验证,具体操作步骤为:
优选地,步骤3中的异常值检测算法为基于密度的离群点检测方法的LOF算法,其中其参数设置为邻居数量n_neighbors设置为[5,20],距离度量采用欧氏距离,异常值的检测比例contamination设置为0.1,算法搜索采用auto,即algorithm=’auto’,本发明采用的编程语言为python,最终测试结果异常值的比例小于5%即可视作采集到的信息符合要求。
步骤4、数据融合:将档案中已有的数据和步骤2预处理得到的数据利用优化后的D-S证据方法进行融合处理,其中步骤4包括以下子步骤,具体优化后的D-S证据实施方式如下:
步骤4-a-1、定义基本假设空间X,假设空间X中包含N个完备且互不相容假设命题元素A
步骤4-a-2、利用归一化规则,对分配函数进行修正,满足
步骤4-a-3、对于来自步骤1中的不同数据,冲突系数可以表示为,
去除经过步骤3异常值检测算法判定为异常值的数据后,调整后的冲突系数表示为,
虚假度Fal表示为,其中K
步骤4-a-4、减小证据冲突的影响,对焦元的权重重新进行分配修正,修正后的权重表示为:
步骤4-a-5、将步骤4-a-4修改焦元权重后得到的信任度和虚假度进行排序,并对步骤1中的各项数据进行加权平均,并通过D-S理论证据合成规则完成特征属性的融合;
步骤4-a-5、将步骤4-a-4修改焦元权重后得到的信任度和虚假度进行排序,并对步骤1中的各项数据进行加权平均,并通过D-S理论证据合成规则完成特征属性的融合;
其中数据融合过程中还包括属性判断,对于不同类型的数据,例如年龄数值型数据和电子签章图片类型的数据进行关联时,采用拼接的方法,优选地拼接的方法可以利用面向对象变成语言类似Java、C++、python中的类或者结构体
进行数据融合决策时本发明主要考虑正确率,即融合完毕后的数据是否可以被重新识别,进而进行后续的数据查询或者处理。
优选地,通过对完成步骤5融合结果的模型进行训练测试,对准确率达到90%的模型可用于后续数据融合,对于不达标的模型返回步骤2重新对数据进行预处理。
优选地,步骤1-a-5的数据合成规则采用正交和运算
通过归档整理将档案材料保存到档案库中,以及通过网络接口或爬虫技术来收集内网和外网的信息保存到资料库中,然后通过数据清洗、主题提取、关键字提取、分类处理、内容推测等进行信息的融合,保存到融合库中,对于后续融合库中的数据进行数据分析,进行资料查询、趋势分析、指数分析、舆情分析均十分便捷如下:
1)对接单位内网信息系统,收集内网信息资源。
2)通过网络爬虫采集外网指定平台指定内容主题信息。
3)具有信息融合算法模块,对内外网数据与档案数据进行融合处理。
4)创建融合资料库,对库中资料进行管理。
优选地,步骤1中数据采集的来源有内网数据和外网数据,获取的方式为接口调取以及网络爬虫。通过接口调取以及爬取收集到的和系统中原先存在的共计包括1000条数据,按照80%的比例划分,训练集包含800条数据,测试集包含200条数据。
步骤2预处理数据过程中合并LDA主题分类模型对主题进行提取,LDA模型作为经典的语言处理模型其参数包括主题个数,文本向量长度,算法求解的最大迭代次数,其中主题数量的设置采用网格搜索法进行确定,向量的长度等于主题数量,评价的指标采用困惑度,词频统计进行关键词提取,其中词频统计的分词工具采用jieba。
优选地,其中LDA模型中的网格搜索参数的范围为:
文本向量的搜索范围设置为[10,20];
算法的最大迭代次数为[20,50];
求解算法的算法选取的范围是’batch’和’online’
以上参数均可以在python编程语言中直接进行设置。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 一种智慧校园信息管理系统
- 一种基于地理信息系统的智慧点位档案管理系统
- 一种智慧交通档案信息管理系统