基于改进YOLOV5的交通标志检测算法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于交通标志检测技术领域,主要是对交通检测中的小目标检测进行改进优化。具体是一种基于YOLOV5的交通目标检测算法,可应用于无人驾驶、智能交通等领域。
背景技术
近年来,目标检测技术迅速发展,取得了显著的进步。研究交通标志检测时,可以将其分为传统方法和基于深度学习的方法。传统的目标检测算法包括三个阶段,首先生成目标建议框,接着提取每个建议框中的特征,最后根据特征进行分类,但是传统方法有很多的弊端,例如对图像复杂性较高的场景效果较差和过度依赖人工设计特征等,因此设计了基于深度学习的目标检测方法,其分为一阶段检测(One-Stage)和二阶段检测(Two-Stage)。
到目前为止,已经有很多种检测算法被提出。如R-CNN系列算法,SSD算法,YOLO系列算法等。
一阶段检测主要以YOLO为代表,该算法准确率高,复杂度小,被目标检测领域广泛应用。
发明内容
YOLOv1发布于2015年,是one-stage detection的开山之作,在此之前的目标检测都是采用two-stage的方法,虽然准确率较高,但是运行速度慢。
由于YOLOv1存在定位不准确以及与two-stage方法相比召回率低的缺点,作者于2017年提出了YOLOv2算法。在论文中作者提出了从更准确,更快,更多识别三个角度对YOLOv1算法进行了改进,其中识别更多对象也就是扩展到能检测9000种不同对象,被称为YOLO9000。
2018年YOLO的作者提出了YOLOv3,它是前作的改进,最大的改进特点包括使用了残差模型Darknet-53,以及为了实现多尺度检测采用了FPN架构。
YOLOv4在原来的YOLO目标检测架构的基础上,采用了很多优化策略,在数据处理,主干网络,网络训练,激活函数,损失函数等方面都有不同程度的优化
YOLOv5网络构造主要由以下几部分组成:输入端,Backbone骨干网络,Neck颈部网络和输出端。
该算法的输入端通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作,使用Mosaic数据增强,通过将四张不同的图像拼接在一起,生成一张新的合成图像,作为训练样本输入网络,可以生成具有更多样性和泛化能力的训练样本。
Backbone是主干网络,YOLOV56.0之前第一层主要是Focus层,6.0之后作者换成了一个6x6大小的卷积层,两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。C3模块由一系列的残差块组成,每个残差块包含了多个卷积层和激活函数,C3模块的设计可以减少网络的计算量,并且通过残差连接保留了输入的信息,提高了网络的性能和表达能力。SPPF结构是一种特征融合结构,类似于SPP(Spatial PyramidPooling结构,用于实现不同尺度的特征融合。
颈部的设计是为了更好的利用backbone提取的特征,在不同阶段对backbone提取的特征图进行再加工和合理利用,使不同尺度的特征得以融合,其由FPN(feature pyramidnet-work)、PANet(path aggregation netword)所构成。
YOLOv5使用了一种称为YOLOv5 Loss的损失函数来衡量预测框与真实框之间的差异。YOLOv5Loss综合考虑了位置、尺寸和类别的差异,并通过一些权重参数来平衡它们的重要性。在目标框的预测完成后,YOLOv5使用了非极大值抑制来筛选出最终的目标框。NMS通过比较目标框之间的重叠程度,并根据一定的阈值来剔除冗余的框,保留置信度最高的框作为最终的检测结果。
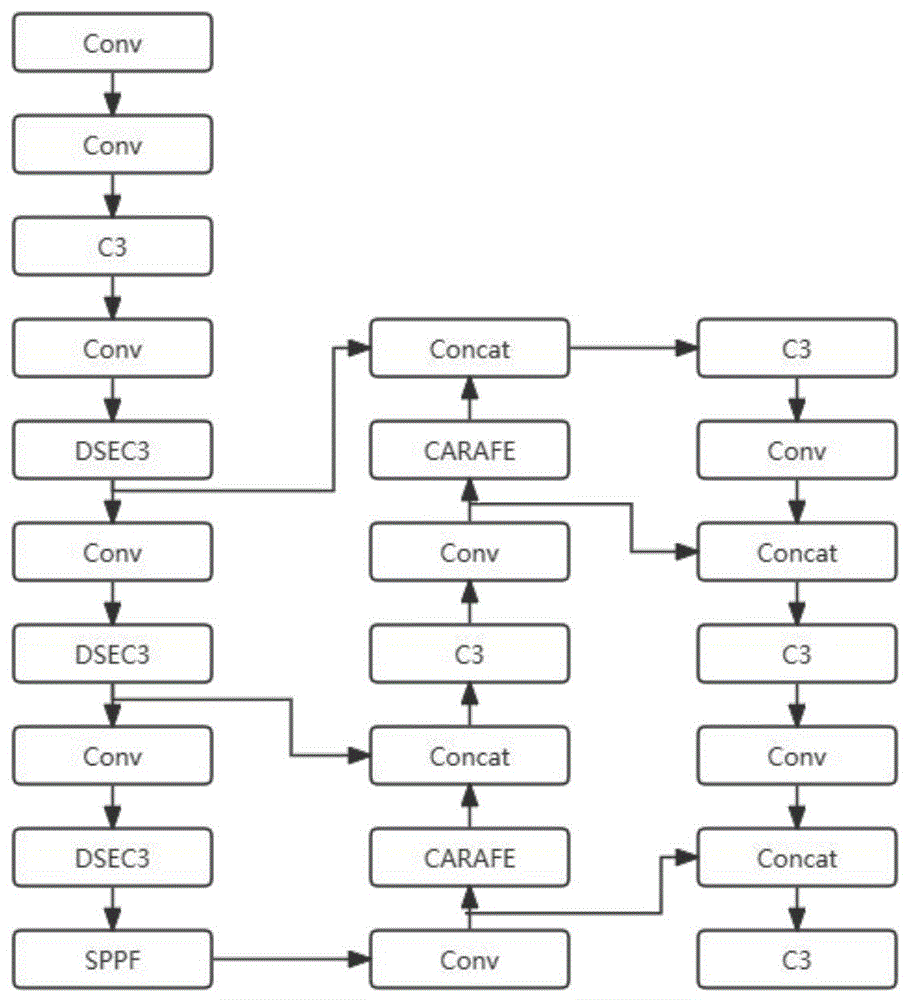
本方案在原有YOLOV56.2的基础上进行改进,为了增加检测精度,减少漏检率,本算法用更小的描框代替原有描框,结合C3、深度可分离卷积,ECA注意力机制生成DSEC3模块,用CARAFE代替原始上采样保留更多特征细节,最后用SIoU损失函数代替原YOLOV5的CIoU损失函数,具体结构如图1所示。
由于交通标志在图片中所占比较小,属于小目标检测范畴,而原本YOLOV5算法在经过多次下采样后会导致图片中信息丢失,使检测出现误检漏检等情况。原YOLOV5的小目标锚框大小为[10,13,16,30,33,23]、中目标描框大小为[30,61,62,45,59,119]、大目标描框大小为[116,90,156,198,373,326]。本文为了提高检测的准确性,根据检测目标的大小和特点通过聚类生成了更适合小目标的描框[5,6,8,12,15,19],中目标描框大小为[10,14,13,23,22,31]、大目标描框大小为[42,57,63,83,106,134]。
小目标往往具有较低的信噪比和较少的可辨识特征,将描框变小可以更好地集中注意力在目标区域,提高检测的准确性。
常规的卷积操作由于运算量大,往往无法满足实际的运行速度要求,所以我们用参数量更少,运算成本更低,运算速度更快的深度可分离卷积(Depthwise SeparableConvolution)来代替传统卷积。
深度可分离卷积是将一个完整的卷积运算分解为两步进行,即Depthwise卷积与Pointwise卷积。Depthwise卷积是对输入的每个通道分别进行卷积操作,即每个通道都有一个对应的卷积核。这样可以在不增加参数量的情况下,对每个通道的特征进行提取和处理。Depthwise卷积只关注输入的空间相关性,而不考虑通道之间的关系。Pointwise卷积是在Depthwise卷积之后,对每个通道的结果进行1x1的卷积操作。这个步骤可以增加通道的数量,从而提取更多的特征。Pointwise卷积主要关注通道之间的关系,通过1x1的卷积核对每个通道的特征进行组合和调整。通过将卷积操作分解为Depthwise卷积和Pointwise卷积两个步骤,深度可分离卷积可以减少参数量和运算成本,提高模型的效率和速度。同时,它还可以保持模型的表达能力,提取有效的特征。
注意力机制可以帮助网络选择最相关的特征来进行目标检测,在图像中存在大量的背景信息,这些信息可能会干扰目标检测的准确性,注意力机制可以帮助网络抑制背景干扰,将注意力集中在目标上,提高目标检测的精度。SE-Net首次提出了一种有效的通道注意学习机制,取得了良好的效果,但是SE-Net的计算量较大,限制了其在实际应用中的使用。
本文采用ECA注意力机制解决上述问题。ECA注意力机制模块直接在全局平均池化层之后使用1D卷积层,去除了SE的全连接层。该模块避免了维度缩减,并有效捕获了跨通道交互,只涉及少数参数就能达到很好的效果。1D卷积用于在通道维度上建立通道之间的关联,卷积核的大小决定了对于每个通道交互的覆盖率,因此表示1D卷积的核大小K就显得非常重要。为了避免通过交叉验证手动调整k,开发了一种自适应方法确定k,其中跨通道交互的覆盖范围与通道维度C成比例且卷积核大小k的选择和输入通道数C之间的关系是非线性的。由于channel数一般都是2的指数,所以有了如下公式:
φ(k)=2
其中γ=2,b=1
本方法最终用深度可分离卷积代替C3中的常规卷积,并且在C3模块中加入ECA模块,形成DSEC3模块,由于C3模块是由两个嵌套的残差模块组成的,本文将ECA模块嵌入到C3模块第二个残差块中,形成特征增强模块。
为了进一步增强对交通标志的识别能力,本方法用CARAFE上采样代替传统上采样。传统上采样通常使用插值或反卷积等技术,这些方法在上采样过程中可能会引入一些伪像或模糊效果。而CARAFE使用了一种自适应卷积的方式进行上采样,可以更好地保留细节信息,减少伪像模糊。同时传统上采样方法通常是固定的,无法根据输入图像的特征动态调整上采样过程。而CARAFE通过自适应卷积的方式,可以根据输入图像的特征动态调整上采样过程,从而更好地适应不同的目标检测任务。传统上采样方法通常会导致计算量的增加,从而影响算法的速度。而CARAFE通过自适应卷积的方式,可以在保持精度的同时减少计算量,提高算法的速度。由此可见CARAFE可以增加算法的精度,减少计算量同时增加计算速度。
CARAFE分为两个主要模块,分别是上采样核预测模块和特征重组模块,上采样核预测模块是CARAFE的第一个主要模块。它负责根据输入的低分辨率特征图,预测出用于上采样的卷积核。这些卷积核将被用于对特征图进行上采样操作,以增加特征图的分辨率。特征重组模块是CARAFE的第二个主要模块。它负责将上采样后的特征图与原始低分辨率特征图进行融合。具体来说,特征重组模块使用预测的卷积核对上采样后的特征图进行插值操作,然后将插值后的特征图与原始低分辨率特征图进行逐元素相加,得到最终的高分辨率特征图。假设上采样倍率为σ,给定一个形状为H×W×C的输入特征图,CARAFE首先利用上采样核预测模块预测上采样核,然后利用特征重组模块完成上采样,得到形状为σH×σW×C的输出特征图。
上采样预测模型一共分为三步,首先将形状为H×W×C的输入特征图通道进行压缩,压缩为H×W×C
在特征重组模块中,对于输出特征图中的每个位置,将其映射回输入特征图,取出以之为中心的K
最后本方法引入SIoU损失函数,SIoU通过引入平滑因子,能够减少损失函数中的尖峰,使得模型更加稳定。SIoU损失函数共有Angle cost、Distance cost、Shape cost和IoU cost四个部分组成,具体公式如下:
其中B为预测框,B
相对于CIoU,SIoU在小目标检测中具有更好的尺寸鲁棒性、均等惩罚项、准确的位置和形状度量以及提高小目标的检测召回率等优势。这些优点可以有效提高小目标检测的性能和准确性。
附图说明
图1为基于YOLOV5的交通目标检测算法的结构图。
具体实施方式
本方法先使用K-means聚类初始化描框,然后使用预训练模型权重进行初始化。
本实验采用TT100K交通标志数据集,包括了100000张高分辨率的交通标志图像。这些图像涵盖了中文、英文、数字等不同类型的交通标志,在不同的环境下拍摄,包括白天、夜晚、晴天、雨天等。数据集中的交通标志涵盖了常见的红绿灯、限速标志、禁止标志、指示标志等。本文选择9467张图片,其中训练集6598张图片,测试集970张图片,验证集1899张图片。
为了客观评价网络性能,本文使用精确率P(Precious)、召回率R(Recall)和平均精确率mAp(mean Average Precision)来评价性能,具体公式如下所示:
其中,TP表示真阳性(True Positives),即模型预测为正例且实际为正例的样本数;FP表示假阳性(False Positives),即模型预测为正例但实际为负例的样本数。
该算法在数据集上具有良好的效果。
综上所述本方法提出了一种基于改进YOLOV5的目标检测算法。将原有的大尺寸描框通过聚类改成更适合交通目标的小尺寸描框,提高检验精度;设计了一种C3、DSP(Depthwise Separable Convolution),ECA注意力机制结合的DSEC3模块提高模型的效率和推理速度;用CARAFE代替原始上采样保留更多特征细节,提高感受野;最后用SIoU代替原始YOLOV5的CIoU使得模型更容易学习到边界框之间的微小差异,进而提高目标检测的准确性和鲁棒性。实验结果表明,改进后的算法的平均准确率均值mAP提升7.8个百分点,满足实验要求。
- 一种基于YOLOv5网络结构的交通标志检测算法
- 一种基于改进YOLOv5s的交通标志检测方法