一种基于深度学习的销售预测方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及后端开发领域,更具体的说是涉及一种基于深度学习的销售预测方法。
背景技术
企业产品销售的预测是制定企业经营决策的重要依据,也是开展好其他各项经营预测的基础。科学准确的销售预测对掌握未来市场动态和发展趋势、合理开展生产安排、提高企业管理效率和生产效益具有一定意义。
随着电子商务的快速发展,销售数据急剧增加。对企业管理而言,科学准确的销售预测具有重要意义,同时对于企业拓展市场发展、合理布局具有决定性作用的因素。充分挖掘海量销售数据中的有用信息,形成趋势对未来进行预测,已成为企业亟待解决的问题。基于大数据环境下,利用监控系统采集到大量的销售数据,销售数据具有周期性等时间特征,也称之为时间序列。如果能挖掘出时间序列中所蕴含的信息,并综合考量其他如假日、消费指数、气温等外部因子的影响,便可实现科学地利用海量信息来预测未来的销售趋势的目的。在辅助人工决策,甚至是自动决策,都会带来事半功倍的效果。运用深度学习方法来预测未来一段时间的销售量对于企业未来的资源规划都有着很重要的意义。
发明内容
本发明的目的在于提供一种基于深度学习的销售预测方法,以期解决背景技术中存在的技术问题。
依据本发明实施例,提供一种基于深度学习的销售预测方法,包括以下步骤:
一种基于深度学习的销售预测方法,包括以下步骤:
实时数据集采集,合并外部数据;
对数据集进行预处理;
对数据集进行特征编码;
对数据集进行归一化特征工程并拆分训练集、测试集;
构建cnn+gru+mlp深度学习组合模型,并添加自适应学习率进行训练,得到输出结果;
根据模型输出结果及模型评价指标评估模型与结果。
在一些实施例中,所述实时数据集采集,合并外部数据,包括:
采集实时销售数据集,包括日期、销售门店、产品类型、产品价格、销售量基本信息;
采集实时外部影响因子数据集,包括油价信息、气温信息、消费指数、节假日信息;
在一些实施例中,所述对数据集进行预处理;包括:
根据日期进行数据集合并后排序,并对数据进行缺失值填充,根据不同字段信息采取不同规则:
1)日期、门店信息、产品类型、产品价格缺失,直接删除该记录;
2)销售量缺失,采取0填充;
3)油价、消费指数、气温信息缺失,采取前向填充策略。
在一些实施例中,所述对数据集进行特征编码;包括:对于销售门店、产品类型、节假日类别信息,进行one-hot编码,并删除日期信息后,对数据集进行归一化处理。
在一些实施例中,所述对数据集进行归一化特征工程并拆分训练集、测试集;包括:对数据集进行拆分,数据集销售量作为预测值y,其余特征作为训练集x;假设预测未来n天销售情况,则最后n天数据为测试集,其余为训练集得到x_train,x_test,y_train,y_test。
在一些实施例中,所述构建cnn+gru+mlp深度学习组合模型,并添加自适应学习率进行训练,得到输出结果;包括:
基于集成学习stacking思想,建立包括CNN、GRU、MLP的组合模型;其中,CNN模型用于提取数据特征的空间信息,GRU模型用于提取数据特征的时间序列信息,MLP模型用于融合特征信息;采用均方误差MSE作为损失函数,对输入处理后的数据集进行训练,获取相应的销售预测值。
本发明的有益效果是:基于历史销售数据和外部影响因子,通过组合深度学习算法模型,实现对未来一段时间销量情况预测的效果。
附图说明
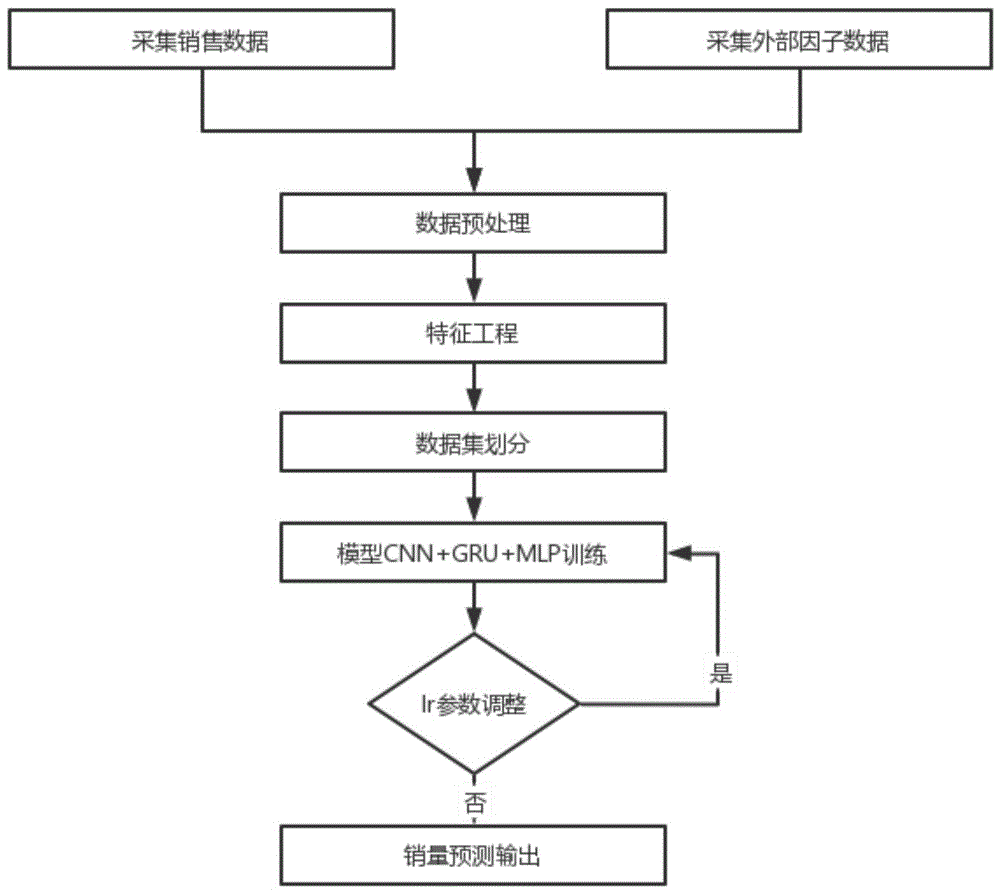
图1为本发明的流程图
图2为本发明中预测模型架构图
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请的优选实施例中的附图,对本申请实施例中的技术方案进行更加详细的描述。在附图中,自始至终相同或类似的标号表示相同或类似的部件或具有相同或类似功能的部件。所描述的实施例是本申请一部分实施例,而不是全部的实施例。下面通过参考附图描述的实施例是示例性的,旨在用于解释本申请,而不能理解为对本申请的限制。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
下面结合附图对本申请的实施例进行详细说明。
在本申请的描述中,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或显示不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或显示固有的其它步骤或单元。
以下将结合图1-2,对本申请实施例进行详细说明。值得注意的是,以下实施例,仅仅用于解释本申请,并不构成对本申请的限定。
深度学习算法利用数据和经验来提升计算机程序在某种任务上的性能,与传统的机器学习算法相比,深度学习技术有两个优点。
首先,深度学习技术可以随着数据规模的增加不断提高其性能,而传统的机器学习算法很难利用海量数据来不断提高其性能。
第二,深度学习技术可以直接从数据中提取特征,减少了为每个问题设计特征提取器的工作量。
其次,深度学习在时序预测、图像分类、语音识别、机器翻译已表现出较高的准确性,且已进入产业化阶段,带动新兴产业的兴起。近年来,随着对深度学习算法的相关研究越来越多,组合模型将各单一模型的优势最大化利用,单一模式相比,预测的效果要好得多。
如图1-2,一种基于深度学习的销售预测方法,包括以下步骤:
(1)采集实时销售数据集,包括日期、销售门店、产品类型、产品价格、销售量等基本信息;
(2)采集实时外部影响因子数据集,包括油价信息、气温信息、消费指数、节假日信息;
(3)根据日期进行数据集合并后排序,并对数据进行缺失值填充,根据不同字段信息采取不同规则:1.日期、门店信息、产品类型、产品价格缺失,直接删除该记录;2.销售量缺失,采取0填充;3.油价、消费指数、气温信息缺失,采取前向填充策略;
(4)对于销售门店、产品类型、节假日等类别信息,进行one-hot编码,并删除日期信息后,对数据集进行归一化处理;
(5)对数据集进行拆分,数据集销售量作为预测值y,其余特征作为训练集x;假设预测未来15天销售情况,则最后15天数据为测试集,其余为训练集得到x_train,x_test,y_train,y_test;
(6)基于集成学习stacking思想,建立包括CNN、GRU、MLP的组合模型。其中,CNN模型用于提取数据特征的空间信息,GRU模型用于提取数据特征的时间序列信息,MLP模型用于融合特征信息。采用均方误差MSE(MSE-Mean Square Error)作为损失函数,对输入处理后的数据集进行训练,获取相应的销售预测值;
(7)用训练好的模型对测试集数据进行预测,得到相应的销售预测结果。最后通过评估指标对模型进行评估和优化,以提高预测准确率;
所述步骤(3)中,根据不同字段信息采取不同规则填充空值:1.日期、门店信息、产品类型、产品价格缺失,直接删除该记录;2.销售量缺失,采取0填充;3.油价、消费指数、气温信息缺失,采取前向填充策略;
所述步骤(4)中,归一化(Min-Max scaling)方法又称为最大最小标准化,其中,该方法实现对原始数据的等比例缩放,将原始数据线性化的方法转换到[0,1]的范围,加速模型收敛。
其中,其中x为原始数据,x
one-hot即独热编码又称为“一位有效编码”,通过one-hot可以将类别变量的每一个类型对应一个寄存器的位,且对于每一个样本其仅仅只有一位寄存器是有效位,是特征编码的常用方式,但是要注意当类别特征过多时候,会造成矩阵稀疏和维度灾难。
所述步骤(6)中,CNN采用Conv1D层,Conv1D是对一维数据进行卷积,常用于处理序列数据,如文本、音频和时间序列。它的输入是一个二维张量,第一维表示时间步数,第二维表示每个时间步的特征维度。激活函数使用Relu:
f(x)=max(0,x)
学习率使用如下自适应学习率进行更新:
其中,lr为当前学习率;init_lr为初始学习率;iter为当前迭代次数,N为第iter步为分割前iter使用固定学习率,后iter步使用自适应学习率;
梯度下降使用Adam,是一种可以替代传统随机梯度下降(SGD)过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重,具有梯度滑动平均和偏差纠正的优点。
损失函数采用均方误差MSE,MSE越小,说明预测情况越接近真实情况。
其中,n为神经元个数,y为真实销售量,
经过每个层后,通过dropout随机舍弃部分神经元,避免出现过拟合。
所述步骤(7)中,模型输出结果需要使用反归一化对数据进行放大,方可得到归一化前的销售量数据,便于与测试集中真实数据比较。其中,销售预测准确率采用如下方式统计:
其中,actual为真实销售数据,pred为经过模型得到的预测值。
以上技术特征的组合和实现,可以有效解决现有销售预测方法中存在的问题,提高销售预测的准确性和实用性,具有较高的实用价值和经济效益。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于深度学习的猪肉专卖网点销售量的预测方法
- 基于深度学习的零售商品销售预测方法