基于深度学习的超分辨测序方法及装置、测序仪及介质
文献发布时间:2024-04-18 19:58:30
技术领域
本申请涉及基因测序技术领域,尤其涉及一种基于深度学习的超分辨测序方法及装置、基因测序仪及计算机可读存储介质。
背景技术
目前,基因测序技术主要可分为三代,第一代测序技术Sanger法是基于DNA合成反应的测序技术,又称为SBS法、末端终止法,由Sanger1975年提出,并于1977发表第一个完整的生物体基因组序列。第二代测序技术是以Illumina平台为代表的测序,实现了高通量测序,有了革命性进展,使得大规模并行测序成为现实,极大推动了生命科学领域基因组学的发展。第三代测序技术是Nanopore纳米孔测序技术,是单分子实时测序的新一代技术,主要是通过ssDNA或RNA模板分子通过纳米孔而带来的电信号变化推测碱基组成进行实时测序。
第二代基因测序技术中,利用荧光显微镜成像技术,将荧光分子的信号保存到图像中,通过解码图像信号来获得碱基序列。为了实现对不同类型碱基的区分,需要使用滤光片获取测序芯片在不同频率下荧光强度的图像,以获得荧光分子发光的频谱特征。同一场景下需要拍摄多张图像,通过对这些图像进行定位和配准,提取点信号并进行亮度信息分析处理,得到碱基序列。随着二代测序技术的发展,测序仪产品现在都配有实时处理测序数据的软件。不同的测序平台会采用不同的光学系统和荧光染料,因此荧光分子发光的频谱特征会有差异。如果算法无法得到适当的特征或者找到合适的参数以处理这些不同的特征,就可能导致碱基分类出现较大误差,从而影响测序质量。
此外,二代测序技术利用不同的荧光分子具有不同的荧光发射波长,当这些荧光分子受到激光照射时,它们会发出相应波长的荧光信号,如图1。通过在激光照射后使用滤光片来选择性地过滤掉非特定波长的光线,以获取到特定波长的荧光信号,如图2。在DNA测序中,常用的荧光标记为四种,将这四种荧光标记同时加入一个循环(Cycle)中,并拍摄荧光信号的图像。由于每个荧光标记都对应一种特定的波长,因此我们能够在图像中分离出不同荧光标记对应的荧光信号,进而得到对应的荧光图像,如图3。在此过程中,可以对图像拍摄参数设置,以尽量使得采集的灰度荧光图像质量达到最优。然而,在实际应用过程中,荧光图像中碱基簇的密度通常非常高,相邻碱基簇之间会紧挨在一起,容易导致测序失败。
基于此,本申请发明人在研究中发现,通过低分辨率的荧光图像转换为超分辨率图像,可以提高图像细节和质量,改善图像质量,对于区分黏连的碱基簇有较好的效果。然而,传统的超分辨率算法将荧光图像转换为超分辨率图像的过程比较耗时,不能满足基因测序的效率和实时性要求;另一方面,基于已知的基于深度学习的超分辨率图像的转换方法,图像PSNR(峰值信噪比)和SSIM(结构相似性)指标可得以提升,能够提升测序荧光图像质量,然而,经验证明这种图像质量的提升主要针对肉眼识别有效,已知的基于深度学习的超分辨率图像的转换在提升图像分辨率的同时,也改变了图像的原有亮度信息,这对于基于碱基簇亮度信息进行分类预测的碱基识别结果的准确性有极大的影响,严重影响基因测序组的Mapping率,其中Mapping率表示测序数据中成功与参考基因组进行映射的匹配程度。
发明内容
为解决现有存在的技术问题,本申请实施例提供一种能够克服碱基信号采集单元之间黏连、且有效提升Mapping率的基于深度学习的超分辨测序方法及装置、基因测序仪及计算机可读存储介质。
为达到上述目的,本申请实施例的技术方案是这样实现的:
第一方面,本申请实施例提供一种基于深度学习的超分辨测序方法,包括:
获取针对测序芯片的与不同碱基类型的测序信号响应对应的多张待测荧光图像形成的多通道输入图像数据;
通过超分辨率图像模型的超分图像生成网络对所述多通道输入图像数据分别进行特征提取得到对应的特征图,通过亮度线性度矫正网络对所述多通道输入图像数据进行亮度分布特征统计得到亮度信息直方图,所述超分图像生成网络根据所述特征图进行图像重建得到超分重建图像,基于所述亮度信息直方图对所述超分重建图像进行亮度信息矫正,得到与各通道输入图像数据分别对应的超分辨率图像;
基于所述超分辨率图像进行碱基分类预测,得到对应的碱基识别结果。
第二方面,本申请实施例提供一种基于深度学习的超分辨测序装置,包括:
获取模块,用于获取针对测序芯片的与不同碱基类型的测序信号响应对应的多张待测荧光图像形成的多通道输入图像数据;
超分辨率图像模型,用于通过超分图像生成网络对所述多通道输入图像数据分别进行特征提取得到对应的特征图,通过亮度线性度矫正网络对所述多通道输入图像数据进行亮度分布特征统计得到亮度信息直方图,所述超分图像生成网络根据所述特征图进行图像重建得到超分重建图像,基于所述亮度信息直方图对所述超分重建图像进行亮度信息矫正,得到与各通道输入图像数据分别对应的超分辨率图像;
分类预测模块,用于基于所述超分辨率图像进行碱基分类预测,得到对应的碱基识别结果。
第三方面,本申请实施例提供一种基因测序仪,包括处理器及与所述处理器连接的存储器,所述存储器上存储有可被所述处理器执行的计算机程序,所述计算机程序被所述处理器执行时实现如本申请任一实施例所述的基于深度学习的超分辨测序方法。
第四方面,本申请实施例提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现本申请任一实施例所述的基于深度学习的超分辨测序方法。
上述实施例中,超分辨率图像模型的设计,增加了亮度线性度矫正网络以多通道输入图像数据为输入,对输入的多张待测荧光图像进行亮度分析特征统计得到亮度信息直方图,利用所述亮度信息直方图对超分图像生成网络根据多通道输入图像数据进行特征提取、图像重建得到的超分重建图像进行亮度信息矫正,将超分重建图像与输入的多张待测荧光图像的亮度信息拟合到同一个亮度分布,有效地保留了一个多通道输入图像数据中多张待测荧光图像之间的亮度相对关系,如此,超分辨率图像的转换可以提升待测荧光图像的分辨率,可以较好地克服碱基信号采集单元成团或黏连而影响碱基识别准确性,且转换后的超分辨率图像可保留同组输入的多张待测荧光图像之间的亮度相对关系,从而可以有效地提升基于同组图像中碱基信号采集单元的亮度对比信息来进行碱基识别的碱基分类预测准确率,有效提升Mapping率。
上述实施例中,基于深度学习的超分辨测序装置、基因测序仪及计算机可读存储介质与对应的基于深度学习的超分辨测序方法实施例属于同一构思,从而与对应的基于深度学习的超分辨测序方法实施例具有相同的技术效果,在此不再赘述。
附图说明
图1为一实施例中不同荧光分子的荧光信号波长的分布示意图;
图2为一实施例中拍摄装置采集荧光图像,其中,拍摄装置利用滤光片选择性地过滤掉非特定波长的光线,以获得特定波长荧光信号的图像的原理示意图;
图3为一实施例中与A、C、G、T四种碱基类型的测序信号响应对应的四张荧光图像的示意图、以及其中一张荧光图像的局部放大示意图;
图4为一实施例中芯片及芯片上碱基信号采集单元的示意图;
图5为一实施例中基于深度学习的超分辨测序方法的流程图;
图6为一实施例中基于深度学习的超分辨测序方法的应用系统架构图;
图7为一实施例中超分辨率图像模型的训练逻辑示意图;
图8为一可选的具体示例中基于深度学习的超分辨测序方法的流程图;
图9为采用本申请实施例中超分辨率图像模型对图像质量和采用现有的深度学习模型对图像质量的提升效果对比示意图;
图10为一实施例中基于深度学习的超分辨测序装置的结构示意图;
图11为一实施例中基因测序仪的结构示意图。
具体实施方式
以下结合说明书附图及具体实施例对本申请技术方案做进一步的详细阐述。
为了使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请作进一步地详细描述,所描述的实施例不应视为对本申请的限制,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本申请保护的范围。
在以下的描述中,涉及到“一些实施例”的表述,其描述了所有可能实施例的子集,需要说明的是,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。
在以下的描述中,所涉及的术语“第一、第二、第三”仅仅是区别类似的对象,不代表针对对象的特定排序,可以理解地,“第一、第二、第三”在允许的情况下可以互换特定的顺序或先后次序,以使这里描述的本申请实施例能够以除了在这里图示或描述的以外的顺序实施。
第二代基因测序技术,又称下一代测序技术(Next-generation Sequencing,NGS),可以一次对几十万到几百万条DNA分子进行序列测定。已知的二代测序仪普遍是以光学信号记录碱基信息,通过光信号转化为碱基序列,而其中图像处理和荧光定位技术产生的碱基簇位置是后续芯片模板点位置的参考,因此图像处理和荧光定位技术,同碱基序列数据的准确性有直接关系。本申请实施例提供的基于深度学习的超分辨测序方法,是针对基于荧光标记dNTP基因测序中针对测序芯片采集的荧光图像作为输入数据,主要应用于第二代基因测序技术。其中,荧光标记,是一种采用光信号的测量技术,在工业上常用于DNA测序,细胞标记,药物研究等领域。二代测序仪所采用的基因测序光信号法,是利用不同波段荧光标记不同的碱基,通过滤光片过滤,特定碱基连接成功会激发特定波长的光,最后识别为待测DNA碱基序列。这种通过采集光信号生成图像,再转变成碱基序列的技术则为第二代基因测序技术的主要原理。
二代测序仪,以Illumina测序仪为例,其测序流程主要包括样本准备、簇生成、测序及数据分析四个阶段。
样本准备,也就是文库构建,是指将待测基本组DNA打断形成大量DNA片段、将各DNA片段两端加接头(adapter),接头内分别包含测序结合位点、indices(标识DNA段来源的信息)、与测序芯片(Flowcell)上的寡聚核苷酸互补的特定序列。
簇生成,也就是通过把文库种到Flowcell上,利用桥式DNA扩增,一个DNA片段形成一个碱基簇。
测序,是指针对Flowcell上的每个碱基簇进行测序读段,测序加进带有荧光标记dNTP测序引物,dNTP化学式的一个端连接了叠氮集团,可以在测序的链延伸时候阻止聚合,确保一个循环(cycle)只能延长一个碱基,对应生成一个测序读段,也即边合成边测序。一次循环中,针对每一碱基簇通过荧光标记dNTP识别一个碱基,通过特定颜色的荧光信号分别对应不同碱基类型的测序信号响应,通过激光扫描可根据发出的荧光颜色来判断当前循环内针对每一碱基簇对应的是哪个碱基。一次循环中,数以千万的碱基簇在Flowcell被同时测序,一个荧光点代表一个碱基簇发出的荧光,一个碱基簇则对应fastq当中的一条read。在测序阶段,通过红外相机拍摄Flowcell表面的荧光图像,对荧光图像进行图像处理和荧光点位置定位进行碱基簇检测,根据与不同碱基类型的测序信号响应对应的多张荧光图像的碱基簇检测结果进行模板构建,构建出Flowcell上所有碱基簇模板点(cluster)的位置。根据模板,对滤波后图像进行荧光强度的提取,然后对荧光强度进行矫正,最终根据各碱基簇模板点位置的最大强度识别碱基计算得分,输出fastq碱基序列文件。请参阅图4,分别为Flowcell示意图(图4中的(a))、一次循环中针对Flowcell上相应部位拍摄的荧光图像(图4中的(b))、及fastq文件中测序结果显示的示意图(图4中的(c))。
数据分析,通过对代表所有DNA片段的数百万个read进行分析,对应每个样本,来自同一文库的碱基序列,可通过在文库构建过程中引入的接头中独特的index进行聚类,reads被配对生成连续序列,连续序列与参考基因组进行比对用于突变识别。
需要说明的是,上述是以Illumina测序技术作为大规模平行测序技术(MPS)的一种示例对测序流程进行说明,通过将待测DNA分子通过特定的扩增技术进行扩增,针对每一DNA片段(单链文库分子)扩增形成碱基簇,以碱基簇检测结果构建测序芯片上碱基簇的模板点,以便于后续能够根据碱基簇的模板点进行碱基识别等操作,提升碱基识别效率和准确性。可以理解的是,本申请实施例所提供的基于深度学习的超分辨测序方法,是基于测序芯片上单链文库分子扩增后的碱基簇进行定位检测和碱基类型识别,这里,每个碱基簇即指一个碱基信号采集单元,从而其并不受限于针对单链文库分子所采用的哪一种扩增技术,也即,本申请实施例所提供的基于深度学习的超分辨测序方法,同样可以适用于其它大规模平行测序技术中针对测序芯片的碱基信号采集单元的碱基类型识别,比如,碱基信号采集单元可以指Illumina测序技术中利用桥式扩增技术得到的碱基簇,也包括通过滚环扩增技术(RCA, Rolling Circle Amplification)得到的纳米球,等等,本申请对此不作限制。
请参阅图5,为本申请一实施例提供的基于深度学习的超分辨测序方法,包括如下步骤:
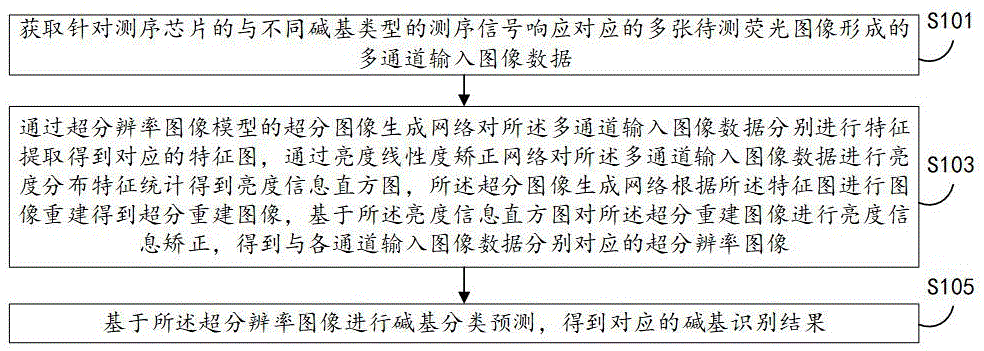
S101,获取针对测序芯片的与不同碱基类型的测序信号响应对应的多张待测荧光图像形成的多通道输入图像数据。
其中,每一待测荧光图像中各荧光点与对应类型的碱基的各碱基信号采集单元一一对应。碱基类型,通常是指A、C、G、T四种碱基类型。由于不同碱基类型是对应不同荧光标记dNTP的荧光信号,不同荧光标记dNTP的碱基信号采集单元之间没有交集,针对每一碱基类型的测序信号响应对应的待测荧光图像,相应包含测序芯片中相应部位处包含的同一种碱基类型的碱基信号采集单元。获取针对测序芯片的目标部位分别与不同碱基类型的测序信号响应对应的多张原始荧光图像,每张荧光图像包括一种碱基类型的碱基信号采集单元的位置信息,根据同一循环中采集的多张荧光图像中各自分别包含的碱基信号采集单元的位置信息,能够得到测序芯片的目标部位处包含的完整的多个类型碱基信号采集单元的位置信息。其中,目标部位可以是指测序芯片表面的某一局部位置,也可以是测序芯片的表面整体,通常与一张荧光图像能够包含的成像区域范围相关。
待测荧光图像,是指测序流程中在测序阶段针对测序芯片表面拍摄的原始的荧光图像。本实施例中,A、C、G、T碱基分别对应4个不同荧光标记dNTP的荧光信号,4个不同荧光标记dNTP的碱基信号采集单元之间理论上没有交集。获取针对测序芯片的分别与不同碱基类型的测序信号响应对应的多张原始图像,是指针对同一测序芯片目标部位分别拍摄4个不同荧光标记dNTP的荧光信号对应的荧光图像,利用A、C、G、T 4种碱基在不同波段的光照射下亮度不同,相应对同一个视场(测序芯片的同一目标部位)采集A、C、G、T 4种碱基被4个不同荧光标记dNTP的荧光信号(4种环境)激发点亮对应的荧光图像(4张原始的荧光图像),作为与不同碱基类型的测序信号响应对应的多张待测荧光图像。
以与不同碱基类型的测序信号响应对应的多张待测荧光图像为一组,沿通道维度堆叠形成一个多通道输入图像数据。如,与A、C、G、T 4种碱基类型的测序信号响应对应的四张待测荧光图像沿通道维度堆叠,形成一个4通道输入图像数据,其维度可表示为(4,H,W),其中,H,W为待测荧光图像的高和宽。
S103,通过超分辨率图像模型的超分图像生成网络对所述多通道输入图像数据分别进行特征提取得到对应的特征图,通过亮度线性度矫正网络对所述多通道输入图像数据进行亮度分布特征统计得到亮度信息直方图,所述超分图像生成网络根据所述特征图进行图像重建得到超分重建图像,基于所述亮度信息直方图对所述超分重建图像进行亮度信息矫正,得到与各通道输入图像数据分别对应的超分辨率图像。
超分辨率图像模型,是指以将输入的低分辨率图像转换为对应的超分辨率图像为图像重建任务,通过对神经网络进行训练后得到的深度学习模型。请参阅图6,超分辨率图像模型包括超分图像生成网络和亮度线性度矫正网络,其中超分图像生成网络和亮度线性度矫正网络分别是以多通道输入图像数据为输入,超分图像生成网络对各待测荧光图像进行特征提取、图像重建以得到超分重建图像,亮度线性度矫正网络对各待测荧光图像进行亮度分布特征统计以得到亮度信息直方图,通过亮度信息直方图保留多张输入图像之间的原始亮度对比信息,以能够对超分重建图像进行亮度信息矫正,将由于图像重建而导致的亮度失真进行补偿。
图像质量指标,主要是指反映图像的逼真度和可读懂性的相关指标,本申请实施例中,超分辨率图像模型对待测荧光图像的图像质量指标的提升,主要是指分辨率,超分图像生成网络通过对同一各通道输入图像数据中各张待测荧光图像进行特征提取,根据提取到的特征图进行图像重建,输出与各通道输入图像数据分别对应的多张超分重建图像。
S105,基于所述超分辨率图像进行碱基分类预测,得到对应的碱基识别结果。
根据超分辨率图像进行碱基分类预测,可以是采用传统的对荧光图像进行图像处理和荧光点位置定位的检测算法,以确定各碱基信号采集单元中心的位置处所属碱基类型;也可以是采用训练后的用于图像识别的神经网络模型对荧光图像进行图像特征提取,以确定各碱基信号采集单元中心的位置处所属碱基类型。基于超分辨率图像进行碱基分类预测,得到根据每一多通道输入图像数据所确定的测序芯片中各碱基信号采集单元位置处的碱基类型,根据测序流程中各循环依序采集到的多通道输入图像数据进行碱基类型识别,以获得碱基识别结果是基因测序中碱基识别任务(Basecall)的关键一环。
以测序流程中各循环采集到的多通道输入图像数据的碱基识别结果得到碱基序列,将所述碱基序列与已知基因库中的标准碱基序列进行比对,确定比对成功的碱基序列,根据比对成功的比例也即Mapping率,来表征碱基分类预测的准确性。
上述实施例中,超分辨率图像模型的设计,增加了亮度线性度矫正网络以多通道输入图像数据为输入,对输入的多张待测荧光图像进行亮度分析特征统计得到亮度信息直方图,利用所述亮度信息直方图对超分图像生成网络根据多通道输入图像数据进行特征提取、图像重建得到的超分重建图像进行亮度信息矫正,将超分重建图像与输入的多张待测荧光图像的亮度信息拟合到同一个亮度分布,有效地保留了一个多通道输入图像数据中多张待测荧光图像之间的亮度相对关系,如此,超分辨率图像的转换可以提升待测荧光图像的分辨率,可以较好地克服碱基信号采集单元成团或黏连而影响碱基识别准确性,且转换后的超分辨率图像可保留同组输入的多张待测荧光图像之间的亮度相对关系,从而可以有效地提升基于同组图像中碱基信号采集单元的亮度对比信息来进行碱基识别的碱基分类预测准确率,有效提升Mapping率。
在一些实施例中,步骤S101,获取针对测序芯片的与不同碱基类型的测序信号响应对应的多张待测荧光图像形成的多通道输入图像数据,包括:
在碱基信号采集单元测序读段中对多个碱基识别的对应多个循环内,分别对测序芯片的目标部位采集与不同碱基类型的测序信号响应对应的多张待测荧光图像;
以每一所述循环中,分别与不同碱基类型的测序信号响应对应的多张待测荧光图像作为一组输入图像;
针对每组所述输入图像,对所述待测荧光图像中像素亮度信息进行标准化处理,得到碱基通道标准化后的多通道输入图像数据。
在碱基信号采集单元测序读段中,一个循环(cycle)对应各碱基信号采集单元的一个碱基识别,由于不同碱基类型分别对应不同荧光标记dNTP的荧光信号,与A、C、G、T四种类型碱基的测序信号响应分别对应的四张待测荧光图像,可以是在一个碱基识别的循环内分别采集4个不同荧光标记dNTP的荧光信号(4种环境)激发点亮对应的荧光图像。一个碱基识别的循环中,分别与A、C、G、T四种类型碱基的测序信号响应对应的每四张原始荧光图像作为一组。
以每一所述循序中,分别与不同碱基类型的测序信号响应对应的每四张原始荧光图像作为一组输入图像。本实施例中,针对每一循环,是利用A、C、G、T 4种碱基类型在不同波段的光照射下亮度不同,相应对同一个视场(相同的芯片目标部位)采集A、C、G、T 4种碱基被4个不同荧光标记dNTP的荧光信号(4种环境)激发点亮对应的荧光图像(4张灰度图像),每4张与A、C、G、T 4种碱基类型对应的荧光图像为一组,作为与一个循环对应的一组待测图像。针对每组输入图像,将其输入到超分辨率图像模型之前,对待测荧光图像中像素亮度信息进行标准化处理,以将同组输入图像中包含的与不同碱基类型对应的多张荧光图像的像素亮度信息转换到同一个量级,将这些指标拉到统一的基线上,以更好的保留同组输入图像中多张荧光图像之间的亮度对比信息。
上述实施例中,以一个循环中分别与不同碱基类型的测序信号响应对应的多张待测荧光图像为一组输入图像,针对同组输入图像中多张待测荧光图像的像素亮度信息进行标准化处理,得到碱基通道标准化后的多通道输入图像数据作为后续超分辨率图像模型的输入,以便于得到同组输入图像中多张待测荧光图像之间在同一量级基础上的亮度对比信息,保留该亮度对比信息,有利于提升后续基于同组图像中碱基信号采集单元的亮度对比信息来进行碱基识别的碱基分类预测准确率。
在一些实施例中,所述针对每组所述输入图像,对所述待测荧光图像中像素亮度信息进行标准化处理,得到碱基通道标准化后的多通道输入图像数据,包括:
针对每组所述输入图像,根据所述待测荧光图像中像素亮度信息分别计算碱基通道标准化均值和碱基通道标准化方差;
根据所述碱基通道标准化均值和所述碱基通道标准化方差,对所述待测荧光图像中像素亮度信息进行标准化处理,得到碱基通道标准化后的多通道输入图像数据。
碱基通道标准化,目的是为了保持不同碱基类型的多张待测荧光图像的相对亮度信息。碱基通道标准化均值,可以表征多张待测荧光图像的像素亮度信息的平均大小。碱基通道标准化方差,可以表征多张待测荧光图像的像素亮度信息的离散程度。根据碱基通道标准化均值和碱基通道标准化方差,对待测荧光图像中像素亮度信息进行标准化处理,获得多张待测荧光图像的像素亮度信息基于同一量级基础的对比信息。
可选的,所述根据所述碱基通道标准化均值和所述碱基通道标准化方差,对所述待测荧光图像中像素亮度信息进行标准化处理,得到碱基通道标准化后的多通道输入图像数据,包括:
根据如下公式(1)计算所述碱基通道标准化均值
;公式(1)
根据如下公式(2)计算所述碱基通道标准化方差
;公式(2)
根据如下公式(3)对所述待测荧光图像中像素亮度信息进行标准化处理:
; 公式(3)
其中,
本实施例中,碱基通道标准化中,每组输入图像中多张待测荧光图像的各点的像素值,可以是指每张荧光图像中全部像素点的像素值,也可以是指每张荧光图像去除背景后的全部像素点的像素值。以每组输入图像中,多张待测荧光图像中各点的像素值共同计算均值和方差,获得同组输入图像基于自身包含的多张待测荧光图像的像素亮度信息基于同一量级基础的对比信息。
在一些实施例中,步骤S103,通过超分辨率图像模型的超分图像生成网络对所述多通道输入图像数据分别进行特征提取得到对应的特征图,通过亮度线性度矫正网络对所述多通道输入图像数据进行亮度分布特征统计得到亮度信息直方图,所述超分图像生成网络根据所述特征图进行图像重建得到超分重建图像,基于所述亮度信息直方图对所述超分重建图像进行亮度信息矫正,得到与各通道输入图像数据分别对应的超分辨率图像,包括:
通过超分辨率图像模型的超分图像生成网络对所述多通道输入图像数据分别进行特征提取得到对应的特征图;
通过所述超分辨率图像模型的亮度线性度矫正网络对所述多通道输入图像数据中各所述待测荧光图像的像素亮度信息进行统计分析,得到各所述待测荧光图像对应的预设统计分析指标的亮度信息直方图;其中,所述预设统计分析指标包括中值、均值和/或方差;
所述超分图像生成网络根据所述特征图进行图像重建得到超分重建图像;
对所述超分重建图像的像素亮度信息进行统计分析,得到各所述超分重建图像的像素亮度信息的所述预设统计分析指标值;
基于各所述待测荧光图像的所述预设统计分析指标的亮度信息直方图相应对各所述超分重建图像进行直方图规定化,将所述超分重建图像的像素亮度信息的所述预设统计分析指标值进行亮度信息矫正,得到与各通道输入图像数据分别对应的超分辨率图像。
在基因测序技术中,对荧光图像进行超分辨率处理,在实现低成本、高通量测序平台和降低全基因组测序费用等方面,均具有重要意义。通过对荧光图像进行超分辨率处理,第一,可以提高样本密度,当前主流的二代测序技术受到光学衍射极限的限制,样本间距一般需要控制在500纳米以上,通过超分辨处理,可以显著提高图像的空间分辨率,允许更密集地放置样本,这意味着在同样的芯片面积上可以容纳更多的样本,从而提高测序平台的样本密度,通过增加样本密度,可以同时处理更多的样本,提高测序的通量和效率。第二,降低测序费用,目前,基因测序费用仍然是制约其广泛应用的一个关键因素,超分辨处理可以在不增加实验成本的情况下,提高测序图像的分辨率和质量,从而提高测序的准确性和可靠性,这有助于降低测序错误率,减少重复测序的需求,进而降低测序费用,通过降低测序费用,可以促进基因测序技术的普及和广泛应用,加速基因组学研究的进展。第三,提高数据质量,超分辨处理可以消除图像中的噪声和模糊,提高图像的清晰度和质量,在基因测序中,高质量的荧光图像有助于更准确地识别和解析碱基序列,提高测序数据的准确性和可靠性,通过提高数据质量,可以减少测序错误和假阳性的发生,从而提高基因组装、变异检测和生物信息学分析的准确性和可信度。第四,推动技术发展和创新:超分辨处理是图像处理和计算机视觉领域的研究热点,借助深度学习和图像重建算法,通过将图像重建任务和碱基识别任务作为联合任务,可以提高图像分辨率和质量,在基因测序领域,对荧光图像进行超分辨处理不仅可以改善测序数据,还促进了相关技术的发展和创新,这有助于不断推动测序设备和分析方法的改进,进一步降低测序成本,提高测序平台的性能和竞争力。
其中,本申请发明人在提出本申请技术方案的研究过程中,对超分辨率图像的技术情况进行了分析,传统的超分辨率图像的获得主要是采用结构化照明显微镜技术(Structured Illumination Microscopy,SIM),通过使用结构化的照明光源模式和图像处理算法,实现超分辨率成像。而在深度学习领域,超分辨率图像的获得可主要包括如下三种方法,1、卷积神经网络(CNN):CNN是深度学习中最常用的模型之一,在图像超分辨处理中,可以设计和训练基于CNN的网络模型,用于将低分辨率图像映射到超分辨率图像,通过多层卷积和池化操作,CNN可以从图像中提取特征并学习图像的高频信息,从而提高图像的分辨率。2、生成对抗网络(GAN):GAN是一种由生成器和判别器组成的对抗性模型,在图像超分辨处理中,生成器网络负责将低分辨率图像转换为超分辨率图像,而判别器网络则尝试区分生成的图像与真实超分辨率图像,通过不断优化生成器和判别器之间的对抗过程,GAN可以生成更加真实和细致的超分辨图像。3、基于残差学习的网络(如SRResNet):这种方法利用残差学习的思想来提高超分辨效果,通过构建深层网络结构,使网络能够学习低频和高频信息之间的残差,从而减少信息丢失。然而,这些传统的深度学习的超分辨率图像的获得方法,虽可以有效提升超分辨率SSIM指标数值与减少MSE指标数值,但二者的优化结果与高通量测序仪的评价指标不一致,高通量测序仪是以Mapping率为评价指标,Mapping率指的是高通量测序仪经过碱基识别到的碱基序列与已知公开基因库的匹配率,如此,基于传统的深度学习方法获得的超分辨率图像用于后续的碱基分类预测,并不能提高Mapping率这一最重要的测序指标。
直方图规定化,是指将图像的直方图调整为规定的形状,如,将一副图像或某一区域的直方图匹配到另一幅图像上,使得两幅图像的预设图像指标保持一致。本实施例中,利用亮度信息直方图对超分图像生成网络进行图像重建得到的超分重建图像进行直方图规定化,以将输入图像的亮度信息直方图匹配到超分重建图像上,使得规定化后得到的超分辨率图像与输入图像的原始像素亮度信息的预设统计分析指标,也即像素亮度信息的中值、均值和/或方差保持一致。
超分辨率图像模型中,亮度线性度矫正网络(LIM)的引入,通过对多通道输入图像数据中各待测荧光图像的像素亮度信息进行统计分析,得到各待测荧光图像对应的预设统计分析指标的亮度信息直方图,利用亮度信息直方图对超分图像生成网络进行图像重建得到的超分重建图像进行直方图规定化,以对超分重建图像的像素亮度信息的预设统计分析指标值进行亮度信息矫正,将最终得到的超分辨图像按照输入图像的预设统计分析指标值拟合至同一亮度分布,以保留原始的输入图像中碱基的亮度真实信息不失真,避免超分重建后导致亮度线性度改变影响Mapping率。
上述实施例中,超分辨率图像模型利用亮度线性度矫正网络,能够有效保证在提升图像质量的情况下同组内多张荧光图像中不同类型碱基的相对亮度关系不失真,在提高图像的结构相似性(Structural Similarity,SSIM)、峰值信噪比(Peak signal-to-noiseratio,PSNR)等质量指标外,还能有效提升基因测序仪最重要的指标Mapping率。
可选的,所述超分图像生成网络根据所述特征图进行图像重建得到超分重建图像之前,还包括:
基于各所述待测荧光图像的所述预设统计分析指标的亮度信息直方图相应对各所述特征图进行直方图规定化,将所述特征图的像素亮度信息的所述预设统计分析指标值进行亮度信息矫正。
直方图规定化,是指将图像的直方图调整为规定的形状,如,将一副图像或某一区域的直方图匹配到另一幅图像上,使得两幅图像的预设图像指标保持一致。本实施例中,利用亮度信息直方图对超分图像生成网络通过特征提取得到的特征图在通过反卷积以进行图像重建之前进行直方图规定化,以将输入图像的亮度信息直方图匹配到特征图上,使得特征图融合输入图像的原始像素亮度信息,提升根据特征图进行图像重建得到超分重建图像的亮度线性度的真实性。其中,超分图像生成网络通过特征提取得到的特征图反映的是输入的待测荧光图像的主要特征信息,相应对背景信息和冗余信息进行抑制,通过利用亮度信息直方图对特征图进行直方图规定化,可对输入的待测荧光图像中的主要特征信息,也即各碱基信号采集单元的位置处的像素亮度信息进行矫正,可以达到针对性矫正和优化待测荧光图像中各碱基信号采集单元的位置处的像素亮度信息的目的。
在一些实施例中,所述超分图像生成网络包括特征提取层、反卷积层和重建卷积层;
所述特征提取层以所述多通道输入图像数据为输入,用于对所述多通道输入图像数据分别进行特征提取得到对应的特征图,所述反卷积层用于将所述特征图进行上采样,将所述特征图进行放大,所述重建卷积层用于将放大后的所述特征图进行图像重建得到超分重建图像;
所述亮度线性度矫正网络以所述多通道输入图像数据为输入,并将对所述多通道输入图像数据进行亮度分布特征统计得到的亮度信息直方图输出至所述特征图和所述超分重建图像。
其中,特征图为特征提取层对多通道输入图像数据进行特征提取得到,请再次参阅图6,特征提取层主要包括与输入连接的卷积模块,反卷积层主要包括上采样模块,重建卷积层主要包括与上采样模块连接的卷积模块。超分图像生成网络中,反卷积层中可设置反卷积核的大小、步长和扩充(padding)值,以将特征图放大指定倍数,并通过设置反卷积核的数量,确定与多通道输入图像数据对应的输出通道数量。在一个示例中,反卷积核的大小为4x4,步长为2,padding为1,以将特征图的宽高放大2倍。重建卷积层中,可以设置卷积核的大小、步长和padding值,将特征提取层进行特征提取得到的特征图进行转换得到所需的超分辨率图像,并通过设置卷积核的数量,确定输出通道数量。在一个示例中,卷积核的大小为4x4,步长为1,padding为1,以输出与4通道输入图像数据对应的4张超分重建图像,图像的长宽为输入图像的2倍,像素数为4倍。亮度线性度矫正网络以多通道输入图像数据为输入,对所述多通道输入图像数据进行亮度分布特征统计得到的亮度信息直方图,分别输出至超分图像生成网络的反卷积层和输出层,实现通过亮度信息直方图对特征图和超分重建图像进行直方图规定化。
在一些实施例中,超分辨率图像模型的损失函数表示如下公式(4)和(5)所示:
; 公式(4)
; 公式(5)
其中,MCE为碱基分类交叉熵,SSIM结构相似性,MSE为均方差误差。
与/>
可选的,基于超分辨率图像进行碱基分类预测,可通过以超分辨率图像为输入,对图像中碱基信号采集单元进行检测定位和识别的已训练后的神经网络分类模型来完成,MCE Loss可作为分类模型的损失函数,在模型训练过程中以推理各超分辨率图像中各碱基信号采集单元位置处的碱基类型的碱基识别结果与标签的损失值,优化分类模型的模型参数,引入分类损失可以更好地根据不同碱基类型的成功分类结果来调节模型参数。
上述实施例中,超分辨率图像模型使用MCE Loss、SSIM Loss和MSE Loss来设置总的损失函数,通过调整三者的权重,可以将分类损失引入到超分辨图像模型中,更好地调节超分辨率图像模型的优化方向。
可选的,所述基于深度学习的超分辨测序方法,还包括:
获取训练数据集;其中,每一训练样本包括通过低倍镜采集的针对测序芯片的与不同碱基类型的测序信号响应分别对应的多张原始荧光图像、通过高倍镜相应采集的与多张所述原始荧光图像对应超分辨图像作为标签;
构建初始的深度学习模型,所述深度学习模型包括超分图像生成网络和亮度线性度矫正网络,基于所述训练数据集对所述深度学习模型进行训练,直至损失函数收敛以得到训练后的所述超分辨率图像模型。
在训练过程中,深度学习模型以标签为训练目标进行监督学习。获取训练数据集,包括获取样本图像及样本图像对应的标签形成训练样本数据集。样本图像是指通过低倍镜采集的针对测序芯片的与不同碱基类型的测序信号响应分别对应的多张原始荧光图像,样本图像对应的标签是指通过高倍镜相应采集的与多张所述原始荧光图像对应超分辨图像。
在训练阶段,深度学习模型随机从训练数据集中抽取训练样本进行迭代训练,每一次迭代训练中,以训练样本中与不同碱基类型的测序信号响应分别对应的多张原始荧光图像为一个多通道输入,深度学习模型基于当前权重参数计算和预测输入样本的重建图像与对应标签图像之间的误差,判断误差是否小于等于设定值,若误差大于设定值,则根据误差进行反向传播,优化深度学习模型的权重参数;并再重复从训练样本数据集中随机抽取训练样本作为深度学习模型的输入进行下一次迭代训练,迭代往复循环,不断模型的权重参数,直至深度学习模型基于当前权重参数计算预测的输入样本的重建图像与对应的标签图像的之间的差异小于设定值,即深度学习模型以标签图像为训练目标进行监督学习,训练完成而得到超分辨率图像模型。
请参阅图7,为超分辨率图像模型训练的逻辑示意图,以超分辨率图像模型应用于高通量测序仪为例,包括如下步骤:1、初始化高通量测序仪的物镜和激光功率;2、通过高倍镜和低倍镜获得训练数据集;3、碱基标准化处理;4、训练样本输入超分辨率图像模型;5、超分辨率图像模型输出推理图像;6、根据M-Loss计算推理图像与标签的损失值;7、判断损失是否小于设定值;若否,返回4,继续训练;若是,训练完成。
上述实施例中,通过构建包含超分图像生成网络和亮度线性度矫正网络的深度学习模型,使用MCE Loss、SSIM Loss和MSE Loss来设置总的损失函数进行约束与引导,优化深度学习模型内包含的多个卷积模块中的卷积核参数过程,实现利用深度学习模型对输入的低分辨率图像进行模型训练或者模型推理功能。
为了能够对本申请实施例所提供的基于深度学习的超分辨测序方法具有更加整体的理解,请参阅图8,下面以基于深度学习的超分辨测序方法应用于高通量基因测序仪、碱基信号采集单元为Illumina测序技术中的碱基簇为示例进行说明,所述基于深度学习的超分辨测序方法包括超分辨率图像模型训练过程和推理过程:
S91,获取训练数据集。
初始化高通量测序仪的物镜与激光功率参数,将激光功率调整至A、C、G、T四种碱基簇能均匀发光但不过曝,调整物镜位置直到视野中碱基簇均清晰可见,边缘不模糊。低倍镜获得的图像为低分辨率图像,高倍镜获取的图像为超分辨率图像,作为标签,通过高倍镜和低倍镜获得低分辨率图像及其对应的标签形成超分辨数据集,作为深度学习模型的输入,对深度学习模型进行训练。
S92,对训练数据集中图像进行预处理,预处理包括碱基通道标准化。
碱基通道标准化操作,目的是为了保持A、C、G、T四种碱基的相对亮度关系,防止超分后改变其相对亮度关系而影响Mapping率,碱基通道标准化操作具体可以为前述实施例中公式(1)至(3)所示。其中,预处理还可以包括对训练数据集进行去噪、亮度调节、去背景等。
S93,基于训练数据集对初始构建的深度学习模型进行训练,训练后得到超分辨率图像模型。
初始化深度学习模型的学习率为0.005,优化器可选用随机梯度下降,从训练数据集中选取训练样本,将低分辨率图像输入到深度学习模型,经深度学习模型进行图像重建输出超分辨模型推理结果。此时,将结果与输入相比,长宽变为两倍,像素数为输入4倍。根据损失函数M-Loss,如前述实施例中公式(5)所示。根据M-Loss计算推理图像与标签的损失值,将输入放大到与输出的推理结果相同的大小后,根据M-Loss计算分类与像素值的损失,判断损失是否小于设定值,设定值可以为经验值,若小于,则训练完成,若大于,则模型还未训练完成,模型反向传播,优化本次训练参数,继续下一次训练。通过引入分类损失能够很好根据A、C、G、T四种碱基成功分类的结果来调节模型的优化方向,最终能成功提升Mapping率。
S94,在基因测序流程中,实时采集各循环内A、C、G、T四种碱基对应的待测荧光图像形成多通道输入图像数据。
一个循环对应待测芯片中各碱基簇位置处的一次碱基识别结果,根据依序多个循环的碱基识别结果相应生成当前基因测序流程获得的碱基序列。待测荧光图像为高通量测序仪通过低倍镜采集的低分辨率图像,一个循环内分别采集与A、C、G、T四种碱基类型对应的四张待测荧光图像形成为超分辨率图像模型的一个输入。基因测序仪的图像采集,可包括获取可供深度学习模型处理的待测荧光图像的功能硬件设备采集模块,它包含低倍显微镜、激光、基因样本等。低分辨率显微镜获取低分辨率图像,用与推理与验证。激光在设定特定功率后,照射在含碱基簇的样本上,激发A、C、G、T四种碱基产生不同亮度的荧光,生成可供深度学习超分辨率图像模型处理的碱基簇数字图像。
S95,对多通道输入图像数据进行碱基标准化处理。其中,碱基通道标准化操作具体同样为前述实施例中公式(1)至(3)所示。
S96,将碱基标准化处理后的多通道输入图像数据,输入所述超分辨率图像模型,获得各待测荧光图像对应的超分辨率图像。
超分辨率图像模型,主要实现利用深度学习模型对输入的低分辨率图像进行模型训练或者模型推理功能。模型训练是优化深度学习模型内包含多个卷积模块中的卷积核参数过程,这个过程受损失函数的约束与引导。模型推理即为根据已有的卷积核参数,对低分辨率图像进行超分辨率的过程。超分辨率图像模型包含输入、卷积模块、亮度线性度矫正模块LIM、激活函数、归一化模块、池化模块与输出。输入图像通过卷积模块中的卷积核,进行图像特征的卷积操作,将图像按照不同卷积核提取得到多张特征图。特征图包含输入图像可被深度学习网络可处理的特征,然后通过激活函数进行非线性映射。激活函数为Relu函数。通过激活函数后进行在归一化模块中进行归一化操作,避免处理过程中数值骤升或者骤降。再由池化模块提取主要图像特征,丢弃冗余信息,精简参数量。然后再次通过卷积模块与激活函数进行进一步特征提取。亮度线性度矫正模块LIM,通过计算输入图像的亮度信息,包含中值、均值与方差,然后将卷积后的特征图与输出图像按照输入图像的中值、均值与方差拟合至同一个亮度分布。亮度线性度矫正模块,可以保留原始图像中碱基的亮度真实信息不失真,避免超分后导致亮度线性度改变影响Mapping率。最后生成输出图像,在训练过程中,输出图像将与数据集中的标签进行比较,计算损失。在推理过程中,输出图像即为超分辨率图像模型最终输出的超分辨率图像。
S97,基于与A、C、G、T四种碱基对应的待测荧光图像经超分辨率图像模型处理后输出的超分辨率图像,根据多张超分辨率图像中各碱基信号采集单元处的相对亮度信息,对各碱基信号采集单元的碱基类型进行分类预测,得到对应的碱基识别结果。
根据多个循环对应的碱基识别结果,可以得到当前测序流程获得的碱基序列,通常,碱基序列包括100个A、C、G、T碱基形成的序列,将测序获得的碱基序列与标准基因库做Mapping比对,根据成功对比的序列数计算百分比为Mapping率,根据Mapping率是否高于设定值来判断当前测序是否成功,同时Mapping率也可以作为判断超分辨率图像模型的输出结果的依据。若Mapping率高于设定值,可以此结果作为当前测序流程的最终测序数据。若Mapping率低于设定值,需重新调整高通量测序仪的硬件设备参数,重新测序。
本申请实施例中,超分辨率图像模型中,通过加入亮度线性度矫正网络对多张输入图像间的亮度分布特征进行统计,使得对待测荧光图像通过图像重建获得超分重建图像以提升图像质量的同时,可以保留输入图像的亮度信息不失真,保留输入图像之间的亮度对比信息,进而可以提升后续基于超分辨率图像进行碱基分类预测的准确率,提升Mapping率。
将采用本申请实施例中超分辨率图像模型对图像质量和Mapping率提升效果,与采用传统的超分辨率算法、和采用现有的深度学习模型实现超分辨率图像转换的方法对图像质量和Mapping率提升的效果进行对比,如下表一所示:
结合图9所示,为采用本申请实施例中超分辨率图像模型实现超分辨率图像转换的方法对图像质量、和采用现有的深度学习模型实现超分辨率图像转换的方法对图像质量的提升效果的对比示意图,从图示对比可知,采用本申请实施例中超分辨率图像模型获得的超分辨率图像中,黏连的碱基信号采集单元之间可被更加有效分离,各碱基信号采集单元的边界更清晰。其中,图像质量的提升,有利于将高通量测序样本中黏连的碱基信号采集单元有效分开,由于提升图像质量的同时可以保留输入图像之间的亮度对比信息,从而可有效提升基于同组图像中碱基信号采集单元的亮度对比信息来进行碱基分类预测的准确率,提升测序结果的有效性和真实性。而采用现有的深度学习模型实现超分辨率图像转换的方法,虽然对图像质量有明显的提升,有助于黏连的碱基信号采集单元的分开,但超分重建过程中由于改变了图像中原有的亮度信息,Mapping率无法提升,且反而下降。
本申请实施例提供的基于深度学习的超分辨测序方法,至少具备如下特点:
第一、超分辨率图像模型中加入亮度线性度矫正网络的设计,能有效保证在提升图像质量的情况下其A、C、G、T四种碱基的相对亮度关系不失真,有助于对高通道测序图像进行超分转换后再进行碱基分类预测的mapping率提高;进一步结合对输入同组多张待测荧光图像的碱基通道标准化,M-Loss损失函数的设计,可更加可靠地保留原有的碱基亮度真实信息,优化超分辨率图像模型的输出结果。
第二、不仅能够适用于高通量的测序样本,也同时适用于低通量的测序样本,兼容性好,超分辨率图像模型的处理效率主要与测序样本中待测荧光图像尺寸有关,与图像中的通量和碱基信号采集单元数量无关,占用内存和运行时间可控且稳定,运行速度相对于传统超分辨率转换算法可以有效提升。
第三、对于黏连和成团的碱基信号采集单元可以进行有效预测,通过提升分辨率的方式对黏连单元将其拆分开,以提高测序结果的准确性和可信度。
第四、能够便利地与不同基因测序仪的硬件结构结合,超分辨率图像模型可以较好地适用不断增长的数据量和更新的测序要求,适用性和鲁棒性强。
请参阅图10,本申请另一方面,提供一种基于深度学习的超分辨测序装置,所述基于深度学习的超分辨率测序装置的一个可选的具体应用侧为高通量基因测序仪,包括:获取模块21,用于获取针对测序芯片的与不同碱基类型的测序信号响应对应的多张待测荧光图像形成的多通道输入图像数据;超分辨率图像模型22,用于通过超分图像生成网络对所述多通道输入图像数据分别进行特征提取得到对应的特征图,通过亮度线性度矫正网络对所述多通道输入图像数据进行亮度分布特征统计得到亮度信息直方图,所述超分图像生成网络根据所述特征图进行图像重建得到超分重建图像,基于所述亮度信息直方图对所述超分重建图像进行亮度信息矫正,得到与各通道输入图像数据分别对应的超分辨率图像;分类预测模块23,用于基于所述超分辨率图像进行碱基分类预测,得到对应的碱基识别结果。
可选的,所述获取模块21,具体用于在碱基信号采集单元测序读段中对多个碱基识别的对应多个循环内,分别对测序芯片的目标部位采集与不同碱基类型的测序信号响应对应的多张待测荧光图像;以每一所述循环中,分别与不同碱基类型的测序信号响应对应的多张待测荧光图像作为一组输入图像;针对每组所述输入图像,对所述待测荧光图像中像素亮度信息进行标准化处理,得到碱基通道标准化后的多通道输入图像数据。
可选的,所述获取模块21,还用于针对每组所述输入图像,根据所述待测荧光图像中像素亮度信息分别计算碱基通道标准化均值和碱基通道标准化方差;根据所述碱基通道标准化均值和所述碱基通道标准化方差,对所述待测荧光图像中像素亮度信息进行标准化处理,得到碱基通道标准化后的多通道输入图像数据。
可选的,所述获取模块21,还用于根据如下公式计算所述碱基通道标准化均值
可选的,所述超分辨率图像模型22,具体用于通过超分辨率图像模型的超分图像生成网络对所述多通道输入图像数据分别进行特征提取得到对应的特征图;通过所述超分辨率图像模型的亮度线性度矫正网络对所述多通道输入图像数据中各所述待测荧光图像的像素亮度信息进行统计分析,得到各所述待测荧光图像对应的预设统计分析指标的亮度信息直方图; 其中,所述预设统计分析指标包括中值、均值和/或方差;所述超分图像生成网络根据所述特征图进行图像重建得到超分重建图像;对所述超分重建图像的像素亮度信息进行统计分析,得到各所述超分重建图像的像素亮度信息的所述预设统计分析指标值;基于各所述待测荧光图像的所述预设统计分析指标的亮度信息直方图相应对各所述超分重建图像进行直方图规定化,将所述超分重建图像的像素亮度信息的所述预设统计分析指标值进行亮度信息矫正,得到与各通道输入图像数据分别对应的超分辨率图像。
可选的,所述超分辨率图像模型22,还用于基于各所述待测荧光图像的所述预设统计分析指标的亮度信息直方图相应对各所述特征图进行直方图规定化,将所述特征图的像素亮度信息的所述预设统计分析指标值进行亮度信息矫正。
可选的,所述超分辨率图像模型22,还包括训练模块,用于获取训练数据集;其中,每一训练样本包括通过低倍镜针对测序芯片的与不同碱基类型的测序信号响应分别对应的多张原始荧光图像、通过高倍镜相应采集的与多张所述原始荧光图像对应超分辨图像作为标签;构建初始的深度学习模型,所述深度学习模型包括超分图像生成网络和亮度线性度矫正网络,基于所述训练数据集对所述深度学习模型进行训练,直至损失函数收敛以得到训练后的所述超分辨率图像模型。
需要说明的是:上述实施例提供的基于深度学习的超分辨测序装置在实现碱基类型识别的处理过程中,仅以上述各程序模块的划分进行举例说明,在实际应用中,可以根据需要而将上述处理分配由不同的程序模块完成,即可将装置的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分方法步骤。另外,上述实施例提供的基于深度学习的超分辨测序装置与基于深度学习的超分辨测序方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
本申请另一方面,提供一种基因测序仪。请参阅图11,为本申请实施例提供的基因测序仪的一个可选的硬件结构示意图,所述基因测序仪包括处理器111及与所述处理器111连接的存储器112,存储器112内存储有用于实现本申请任一实施例提供的基于深度学习的超分辨测序方法的计算机程序,所述计算机程序被所述处理器执行时,实现本申请任一实施例提供的基于深度学习的超分辨测序方法的步骤,且能达到相同的技术效果,为避免重复,这里不再赘述。
本申请实施例另一方面,还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述基于深度学习的超分辨测序方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。其中,所述的计算机可读存储介质,如只读存储器(Read-OnlyMemory,简称ROM)、随机存取存储器(RandomAccessMemory,简称RAM)、磁碟或者光盘等。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端(可以是手机、计算机,服务器,或网络设备等)执行本发明各个实施例所述的方法。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围之内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
- 超分辨率图像重建方法及装置、电子设备及存储介质
- 一种基于纳米核酸酶的纳米孔测序仪及其测序方法
- 一种基于纳米孔测序仪的细菌测序数据鉴定方法