证件照缺陷检测及提示方法、装置、介质及设备
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及数据处理技术领域,尤其涉及一种基于图文融合的证件照缺陷检测及提示方法、装置、介质及设备。
背景技术
得益于技术发展,现代人的生活越来越便利。比如自助办证设备,可用于拍摄证件照,从而使得用户无需专门寻找照相馆;且自主办证设备即拍即得的功能,避免了用户二次去照相馆取证件照。
证件照通常会对拍摄者有一些合规性的要求。为了得到满足要求的证件照,自助办证设备一般对机器环境或者用户的穿着、拍照姿态、打扮、面部表情有一定的要求。然而,很多用户在使用自助办证设备前并不知道这些拍摄姿态以及穿着和打扮要求,使得拍摄得到证件照有一定的概率无法通过身份证、驾驶证、出入境等规格照片的检测标准。因此,需要对自助办证设备得到的证件照进行缺陷检测及修正或提示。
在使用自助办证设备拍摄证件照时,自助办证设备一般对机器环境或者用户的穿着、拍照姿态、打扮、面部表情有一定的要求,由于很多用户有无法预知的姿态以及穿着和打扮,往往有一定的概率无法通过身份证、驾驶证、出入境等规格照片的检测标准。
在现有的技术中,2020113997343提供了一种证件图像缺陷检测方法及装置。在多种光源下从至少一个角度采集证件图像,按照缺陷类型,并采用与所述缺陷类型相匹配方法检测所述证件图像的缺陷状态。然而,当有多个检测项目时需要对多个缺陷检测功能进行串联,开发成本高,推理耗时长。可见传统的深度学习检测方法的柔性化程度不高,误检测情况时有发生,且需要耗费大量的人工标注海量数据,存在检测效率低、成本高、检测结果生硬的问题。
发明内容
本发明实施例提供了一种基于图文融合的证件照缺陷检测及提示方法、装置、介质及设备,以解决现有技术在检测证件照缺陷时存在的效率和精度低、成本高、检测结果生硬的问题。
一种基于图文融合的证件照缺陷检测及提示方法,所述方法包括:
构建及训练证件照缺陷检测模型,所述证件照缺陷检测模型包括文本编码网络和图像编码网络;
将证件照缺陷及提示语文本信息输入所述文本编码网络得到对应的文本编码信息,构建文本特征数据库;
获取待处理图像,采用所述证件照缺陷检测模型中的图像编码网络对所述待处理图像进行特征编码处理,得到图像编码信息;
从所述文本特征数据库中获取所述图像编码信息对应的文本编码信息;
根据所述文本编码信息获取对应的证件照缺陷及提示语文本信息。
可选地,所述图像编码网络采用具有双串联注意力模块CCA的CLIP架构,所述注意力模块CCA串接在图像编码器的ViT-B/32模型前。
可选地,每一个注意力模块CCA的结构相同;
在所述注意力模块中,先对输入图像按照预设卷积核进行卷积及最大池化处理得到初始特征图;然后采用三个1*1的卷积核对所述初始特征图进行特征提取,分别得到第一特征图、第二特征图、第三特征图;对所述第一特征图和第二特征图进行关联操作后执行归一化处理,得到第四特征图;对所述第三特征图和第四特征图进行聚合操作,得到目标特征图。
可选地,在所述ViT-B/32模型中,先对输入图像添加分类令牌信息,然后进行线性变换,将线性变换后的图像划分为指定大小的若干个图像块;将每一个图像块转换为低维特征向量;采用位置编码器为每一个图像块分配对应的位置嵌入向量并加入至所述低维向量特征,采用多层编码器对每一图像块的低维特征向量和位置嵌入向量进行特征提取,得到图像编码信息。
可选地,所述文本编码网络采用预训练词嵌入模型BERT;
在所述预训练词嵌入模型BERT中,先将证件照缺陷标记映射为高维实数向量,根据所述证件照缺陷标记在文本中的位置生成位置嵌入向量,采用多层编码器对所述高维实数向量及其对应的位置嵌入向量进行特征提取,得到特征编码,将所述特征编码投影到低维空间,得到文本编码信息;所述多层编码器中每五层结构包含自注意力机制和前馈神经网络。
可选地,所述训练证件照缺陷检测模型包括:
获取图像样本,对所述图像样本标注证件照缺陷及提示语文本信息,根据所述图像样本和证件照缺陷及提示语文本信息构建图像文本对;
训练时每次将预设数量的图像文本对作为一个批次输入所述证件照缺陷检测模型进行训练,通过预设的目标优化函数得到图像文本对比损失;
使用SGD优化器对每个批次的证件照缺陷检测模型的目标优化函数进行优化、反向传播,使图像对比损失下降到预设精度时停止迭代。
可选地,所述从所述文本特征数据库中获取所述图像编码信息对应的文本编码信息包括:
遍历所述文本特征数据库中的每一个文本编码信息,计算所述图像编码信息与所述文本编码信息之间的相似度;
获取相似度最大的文本编码信息。
一种基于图文融合的证件照缺陷检测及提示装置,所述装置包括:
模型训练模块,用于构建及训练证件照缺陷检测模型,所述证件照缺陷检测模型包括文本编码网络和图像编码网络;
数据库构建模块,用于将证件照缺陷及提示语文本信息输入所述文本编码网络得到对应的文本编码信息,构建文本特征数据库;
图像编码模块,用于获取待处理图像,采用所述证件照缺陷检测模型中的图像编码网络对所述待处理图像进行特征编码处理,得到图像编码信息;
编码获取模块,用于从所述文本特征数据库中获取所述图像编码信息对应的文本编码信息;
提示语获取模块,用于根据所述文本编码信息获取对应的证件照缺陷及提示语文本信息。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的基于图文融合的证件照缺陷检测及提示方法。
一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的基于图文融合的证件照缺陷检测及提示方法。
本发明实施例所构建及训练证件照缺陷检测模型,包括文本编码网络和图像编码网络;将证件照缺陷及提示语文本信息输入所述文本编码网络得到文本编码信息,构建文本特征数据库;在进行推理时,获取待处理图像,采用所述证件照缺陷检测模型中的图像编码网络对所述待处理图像进行特征编码处理,得到图像编码信息;从所述文本特征数据库中获取所述图像编码信息对应的文本编码信息;根据所述文本编码信息获取对应的证件照缺陷及提示语文本信息。本发明通过图像检测结合文本预测的方式,在不降低证件照拍摄质量前提下,有效地提高了证件照缺陷检测的效率和精度,克服了现有技术存在的检测柔性化程度不高的问题,生成的提示语更加直观地让用户接受,大大提高了用户拍取标准证件照的便捷度。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一实施例提供的基于图文融合的证件照缺陷检测及提示方法的流程图;
图2是本发明一实施例提供证件照缺陷检测模型的结构示意图;
图3是本发明一实施例提供的注意力模块的结构示意图;
图4是本发明一实施例提供的基于图文融合的证件照缺陷检测及提示装置的结构示意图;
图5是本发明一实施例中计算机设备的一示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供的基于图文融合的证件照缺陷检测及提示方法,首先构建及训练证件照缺陷检测模型,然后将证件照缺陷及提示语文本信息经过证件照缺陷检测模型进行编码,存入文本特征数据库中;在证件照缺陷检测的时候输入证件照图像,利用证件照缺陷检测模型对证件照图像进行图像编码,得到图像编码信息;在文本特征数据库中获取与所述图像编码信息对应的文本编码信息,并返回对应的文字形式的证件照缺陷及提示语文本信息,以协助用户调整拍摄。通过图文融合,有效地提高了证件照缺陷检测的效率和精度,克服了现有技术存在的检测柔性化程度不高的问题,生成的提示语更加直观地让用户接受,大大提高了用户拍取标准证件照的便捷度。
以下对本实施例提供的基于图文融合的证件照缺陷检测及提示方法进行详细的描述,如图1所示,所述基于图文融合的证件照缺陷检测及提示方法包括:
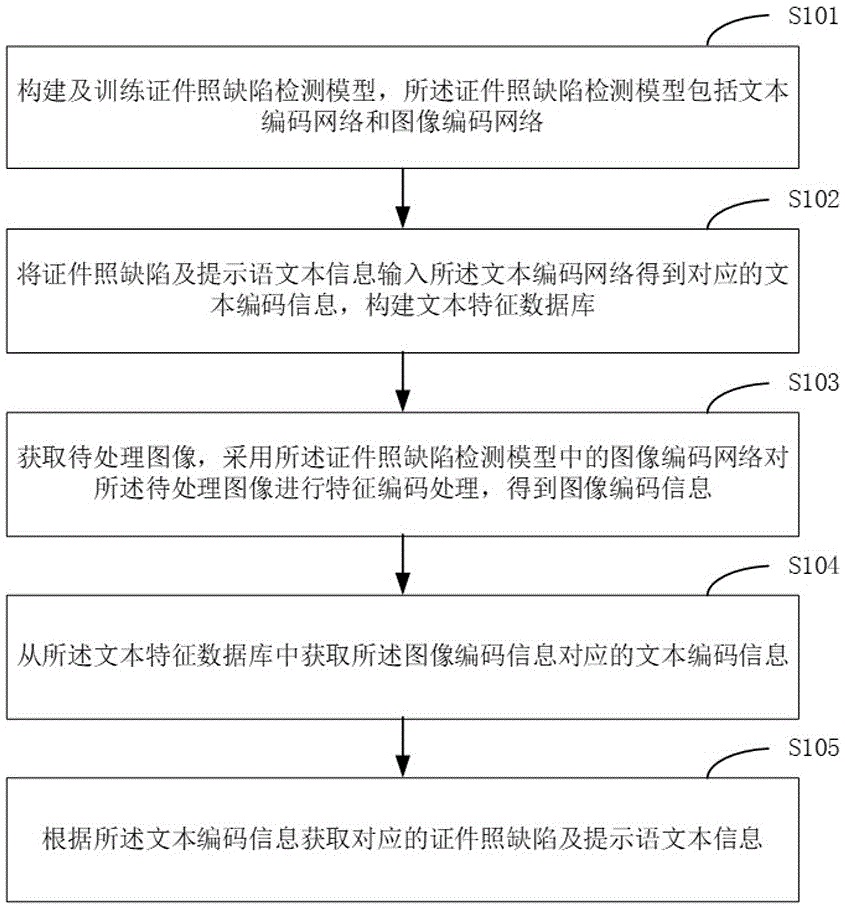
步骤S101,构建及训练证件照缺陷检测模型,所述证件照缺陷检测模型包括文本编码网络和图像编码网络;
步骤S102,将证件照缺陷及提示语文本信息输入所述文本编码网络得到对应的文本编码信息,构建文本特征数据库;
步骤S103,获取待处理图像,采用所述证件照缺陷检测模型中的图像编码网络对所述待处理图像进行特征编码处理,得到图像编码信息;
步骤S104,从所述文本特征数据库中获取所述图像编码信息对应的文本编码信息;
步骤S105,根据所述文本编码信息获取对应的证件照缺陷及提示语文本信息。
其中,所述证件照缺陷检测模型用于对输入图像进行证件照缺陷检测并输出检测结果。所述证件照缺陷是指输入图像所不满足的证件照规则,包括但不限于用户的头发遮住眉毛、头发颜色不合格、戴有美瞳、人脸的旋转角过大、侧转角过大、俯仰角过大、用户的衣服颜色与底色相近、佩戴眼镜、眼镜反光、佩戴项链、头顶距不满足规格、头发遮耳、佩戴徽章等不合格缺陷。
图2为本发明实施例提供的证件照缺陷检测模型的结构示意图。所述证件照缺陷检测模型包括文本编码网络和图像编码网络。所述文本编码网络用于对输入的证件照缺陷及提示语文本信息进行编码,得到对应的文本编码信息。所述图像编码网络用于对输入的图像信息进行证件照缺陷检测并输出对应的图像编码信息。
作为一示例,在步骤S101中,本实施例构建并训练证件照缺陷检测模型。其中,所述图像编码网络采用具有双串联注意力模块CCA的CLIP架构,所述注意力模块CCA串接在图像编码器的ViT-B/32模型前。所述文本编码网络采用预训练词嵌入模型BERT。CLIP(Contrastive Language–Image Pre-training)是由OpenAI开源的基于对比学习的大规模图文预训练模型。ViT,全称为Vision Transformer,是一种基于Transformer架构的视觉处理模型。在训练时,对样本图像添加证件照缺陷及提示语标记,将样本图像、证件照缺陷及提示语标记作为训练样本输入所述证件照缺陷检测模型进行训练。
其中,所述文本特征数据库为证件照缺陷及其提示语文本信息对应的文本编码信息的集合。
作为一示例,在步骤S102中,本实施例在所述证件照缺陷检测模型训练完后,收集相关的证件照缺陷及提示语文本信息,经过所述证件照缺陷检测模型中的文本编码网络进行编码,得到对应的文本编码信息存入所述文本特征数据库。所述文本特征数据库用于后续依据图像编码信息提取文本编码信息,有利于提高从图像提取文本的准确度、可靠性。
其中,所述图像编码信息是经过所述证件照缺陷检测模型中的图像编码网络进行特征编码处理后得到,反映了待处理图像中的证件照缺陷。
作为一示例,在步骤S103中,在利用证件照缺陷检测模型和文本特征数据库进行推理的过程中,先获取待处理图像,输入所述证件照缺陷检测模型。模型中的图像编码网络对所述待处理图像进行特征编码处理后得到图像编码信息。
作为一示例,在步骤S104中,为了避免证件照缺陷检测模型的误检,本实施例进一步根据所述图像编码信息,从所述文本特征数据库中获取对应的文本编码信息。由于所述文本特征数据库中所包含的文本编码信息均与证件照缺陷及其提示语文本信息对应,从而可获得更准确、可靠的编码信息。
作为一示例,在步骤S105中,得到文本编码信息后,本实施例获取对应的证件照缺陷及提示语文本信息,所述证件照缺陷即所述待处理图像作为证件照的不合规信息,同时输出所述证件照缺陷及提示语文本信息,以引导用户进行调整。
综上所述,本实施例提供的基于图文融合的证件照缺陷检测及提示方法,通过构建及训练证件照缺陷检测模型,包括文本编码网络和图像编码网络;以及构建文本特征数据库;在证件照缺陷检测的时候输入证件照图像,利用证件照缺陷检测模型对证件照图像进行图片编码,得到图像编码信息;然后通过文本特征数据库基于图像编码信息获取对应的文本编码信息,并返回对应的文字形式的证件照缺陷及提示语文本信息,以协助用户调整拍摄。通过图文融合,以图像搜索文字的方式,有效地提高了证件照缺陷检测的效率和精度,且克服了现有技术存在的检测柔性化程度不高的问题,生成的提示语更加直观地让用户接受,大大提高了用户拍取标准证件照的便捷度。
可选地,作为一示例,所述证件照缺陷检测模型包括文本编码网络和图像编码网络。所述图像编码网络采用具有双串联注意力模块CCA的CLIP架构,所述注意力模块CCA串接在图像编码器的ViT-B/32模型前。在本实施例中,自助办证设备拍摄的过程中存在很多细微的证件缺陷问题,单个CCA模块较稀疏不能覆盖。鉴于此,本实施例在Clip框架原有的图像编码器Image Encoder前加入Recurrent Criss-Cross Attention Module,构成双串联的注意力模块CCA,有利于提升稠密性,在获得密集的图像上下文信息的同时,摆脱长距离的空间依赖性,还可以将时间复杂度和空间复杂度降低为O((H+W)-1*(H*W))。
可选地,作为一示例,每一个注意力模块CCA的结构相同;在所述注意力模块中,先对输入图像按照预设卷积核进行卷积及最大池化处理得到初始特征图;然后采用三个1*1的卷积核对所述初始特征图进行特征提取,分别得到第一特征图、第二特征图、第三特征图;对所述第一特征图和第二特征图进行关联操作后执行归一化处理,得到第四特征图;对所述第三特征图和第四特征图进行聚合操作,得到目标特征图。
图3为本发明实施例提供的注意力模块的结构示意图。在所述注意力模块中,输入图像的尺寸为448*448*3,预设卷积核为3*3*24。输入图像经过3*3*24的卷积核进行卷积以及最大池化后得到尺寸为224*224*24的初始特征图H,H经过三个1*1的卷积层分别生成第一特征图Q、第二特征图K以及第三特征图V,其中第一特征图Q,第二特征图K的尺寸为224*224*8,第三特征图V的尺寸保持不变与初始特征图H的尺寸一样,仍为224*224*24。对对第一特征图Q和第二特征图K进行关联操作Affinity,也即取第一特征图Q上一个像素点与第二特征图K上位置对应的点及其对应行和对应列中的像素点进行向量相乘得到的第四特征图D,尺寸为224*224*447。第四特征图D经过归一化softmax以后,再与第三特征图V进行聚合操作Aggregation,最后得到尺寸为224*224*24的目标特征图H’。再经过一次串联的注意力模块CCA后送入Clip原有的图像编码器ViT-B/32模型。
可选地,作为一示例,在所述ViT-B/32模型中,先对输入图像添加分类令牌信息,然后进行线性变换,将线性变换后的图像划分为指定大小的若干个图像块;将每一个图像块转换为低维特征向量;采用位置编码器为每一个图像块分配对应的位置嵌入向量并加入至所述低维特征向量,采用多层编码器对每一图像块的低维特征向量和位置嵌入向量进行特征提取,得到图像编码信息。
在本实施例中,所述ViT-B/32模型的输入图像为双串联注意力模块的输出信号。首先ViT-B/32模型在输入图像的开头添加了一个特殊的分类令牌信息CLS token。通过一个线性变换将输入图像的像素值缩放到[-1, 1]的范围内。然后,将变换后的图像划分为指定大小的若干个图像块,比如16x16个固定大小的图像块。每个图像块patch是一个尺寸为32x32像素块,每个图像块展平为一个向量,然后通过线性变换得到一个低维特征向量patch embedding。为了捕捉图像中的位置信息,所述ViT-B/32模型采用了位置编码器。通过位置编码器为每个位置(即每个patch)分配一个位置嵌入向量position embedding。将位置嵌入向量与低维特征向量patch embedding相加,以融合位置信息和视觉特征。在本实施例中,所述ViT-B/32模型使用了多层Transformer编码器来处理低维特征向量和位置嵌入向量。每个Transformer编码器由多个注意力头self-attention heads和前馈神经网络feed-forward neural network组成。注意力头用于捕捉全局和局部之间的关系,前馈神经网络用于提取特征和进行非线性变换。而分类令牌信息CLS token的patch embedding低维特征向量和位置嵌入向量经过Transformer编码器进行处理,用于表示整个图像的语义特征。所述ViT-B/32模型的最后输出是经过Transformer编码器处理后的CLS token的向量表示。
可选地,作为一示例,所述文本编码网络采用预训练词嵌入模型BERT;在所述预训练词嵌入模型BERT中,先将证件照缺陷标记映射为高维实数向量,根据所述证件照缺陷标记在文本中的位置生成位置嵌入向量,采用多层编码器对所述高维实数向量及其对应的位置嵌入向量进行特征提取,得到特征编码,将所述特征编码投影到低维空间,得到文本编码信息;所述多层编码器中每五层结构包含自注意力机制和前馈神经网络。
本实施例采用预训练词嵌入模型BERT来获取文本编码信息,将图像的缺陷标记,包括但不限于用户的头发遮住眉毛、头发颜色、戴美瞳、人脸的旋转角过大、侧转角过大、俯仰角过大、用户的衣服颜色与底色相近、佩戴眼镜、眼镜反光、佩戴项链、头顶距满足规格、头发遮耳、佩戴徽章等不合格缺陷,映射到一个高维的实数向量表示,以捕捉标记的语义信息。为了保留标记在文本中的顺序信息,引入位置嵌入,用于表示每个缺陷标记在文本中的位置,并使用正弦和余弦函数生成对应的位置嵌入向量。设计多层Transformer编码器(Multi-layer Transformer Encoder),每个层由多个相同结构的Transformer编码器层组成,均包含自注意力机制和前馈神经网络。其中,自注意力机制用于在标记序列中建立标记之间的关联性,前馈神经网络用于增强特征表示的非线性能力。然后在最后一个编码器层的输出上,应用一个可训练的投影操作projection,将每个缺陷标记的向量表示映射到一个更低维的空间以进行编码,得到文本编码信息。
可选地,作为一示例,步骤S101所述的训练证件照缺陷检测模型,包括:
步骤S1011,获取图像样本,对所述图像样本标注证件照缺陷及提示语文本信息,根据所述图像样本和证件照缺陷及提示语文本信息构建图像文本对;
步骤S1012,训练时每次将预设数量的图像文本对作为一个批次输入所述证件照缺陷检测模型进行训练,通过预设的目标优化函数得到图像文本对比损失;
步骤S1013,使用SGD优化器对每个批次的证件照缺陷检测模型的目标优化函数进行优化、反向传播,使图像对比损失下降到预设精度时停止迭代。
其中,所述图像文本对用于对证件照缺陷检测模型进行训练,由所述图像样本及其所标注的证件照缺陷及提示语文本信息构成。
作为一示例,在步骤S1011中,本实施例采集自助办证设备所拍摄的多个志愿者的若干张照片,作为图像样本。比如1000个志愿者在不同状态下所拍摄的合格和不合格照片各20张,那么总共有40000张照片,记为[X1,X2,X3,…,Xn]。
对于所采集的图像样本,为图像样本添加相应的证件照缺陷及提示语文本信息,例如用户的头发有遮住眉毛、头发颜色、有戴美瞳、人脸的旋转角过大、侧转角过大、俯仰角过大、用户的衣服颜色与底色相近、有佩戴眼镜、眼镜反光、佩戴项链、头顶距满足规格、头发遮耳等、有佩戴项链、有佩戴徽章等不合格缺陷以及相应的调整方法提示语。一个图像样本对应一组证件照缺陷及提示语文本信息,记为[Y1,Y2,Y3,…,Yn]。
将图像样本[X1,X2,X3,…,Xn]及其对应的证件照缺陷及提示语文本信息[Y1,Y2,Y3,…,Yn]组成图像文本对[X1-Y1,X2-Y2,X3-T3,…,Xn-Yn]。可选地,作为本发明的一个优选示例,将上述图像样本对按照7:2:1的比例划分训练集、验证集、测试集。
其中,一个批次可以选择128个图像文本对。所述图像文本对比损失是指图像样本提取的图像编码信息和证件照缺陷及提示语文本信息提取的文本编码信息之间的余弦相似度。余弦相似度越大,表明图像和文本的对应关系越强,反之越弱。
作为一示例,在步骤S1012中,所述图像文本对输入至所述证件照缺陷检测模型进行训练,图像样本经过图像编码网络提取图像编码信息,证件照缺陷及提示语文本信息经过文本编码网络提取文本编码信息,然后计算图像编码信息和文本编码信息之间的对比损失,也即余弦相似度,最后通过预设的目标优化函数进行优化训练。可选地,所述目标优化函数采用最大化正样本的余弦相似度和最小化负样本的余弦相似度;所述正样本为由图像样本与其对应的证件照缺陷及提示语文本信息构成的图像文本对,所述负样本为由图像样本与非对应的证件照缺陷及提示语文本信息构成的图像文本对。本实施例通过训练文本编码器和图像编码器的参数,最大化N个正样本的余弦相似度和最小化N
其中,
作为一示例,在步骤S1013中,本实施例使用SGD优化器对每个批次的证件照缺陷检测模型的损失函数进行优化并进行反向传播,当证件照缺陷检测模型的损失代价下降到指定精度时停止迭代。在训练每个批次时,以64个图像文本对作为一个批次输入所述证件照缺陷检测模型进行训练测试,以观察试集的准确率和召回率。
可选地,作为一示例,步骤S104,即从所述文本特征数据库中获取所述图像编码信息对应的文本编码信息,包括:
步骤S1041,遍历所述文本特征数据库中的每一个文本编码信息,计算所述图像编码信息与所述文本编码信息之间的相似度;
步骤S1042,获取相似度最大的文本编码信息。
其中,所述相似度为图像编码信息和文本编码信息之间的余弦相似度。为了避免证件照缺陷检测模型的误检,本实施例进一步根据所述图像编码信息,从所述文本特征数据库中获取对应的文本编码信息,达到从图像检测文本的效果。在这里,本实施例遍历文本特征数据库中的每一个文本编码信息,计算图像编码信息与文本编码信息之间的余弦相似度,然后选取相似度最大的文本编码信息,作为所述图像编码信息对应的文本编码信息。由于所述文本特征数据库中所包含的文本编码信息均与证件照缺陷及其提示语文本信息对应,从而可进一步获得更加规范的证件照缺陷检测结果以及提示信息,提高证件照缺陷检测模型的准确度,且克服了现有技术存在的检测柔性化程度不高的问题,生成的提示语更加直观地让用户接受,大大提高了用户拍取标准证件照的便捷度。
应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
在一实施例中,本发明还提供一种基于图文融合的证件照缺陷检测及提示装置,该基于图文融合的证件照缺陷检测及提示装置与上述实施例中基于图文融合的证件照缺陷检测及提示方法一一对应。如图4所示,该基于图文融合的证件照缺陷检测及提示装置包括模型训练模块41、数据库构建模块42、图像编码模块43、编码获取模块44、提示语获取模块45。各功能模块详细说明如下:
模型训练模块41,用于构建及训练证件照缺陷检测模型,所述证件照缺陷检测模型包括文本编码网络和图像编码网络;
数据库构建模块42,用于将证件照缺陷及提示语文本信息输入所述文本编码网络得到对应的文本编码信息,构建文本特征数据库;
图像编码模块43,用于获取待处理图像,采用所述证件照缺陷检测模型中的图像编码网络对所述待处理图像进行特征编码处理,得到图像编码信息;
编码获取模块44,用于从所述文本特征数据库中获取所述图像编码信息对应的文本编码信息;
提示语获取模块45,用于根据所述文本编码信息获取对应的证件照缺陷及提示语文本信息。
可选地,所述图像编码网络采用具有双串联注意力模块CCA的CLIP架构,所述注意力模块CCA串接在图像编码器的ViT-B/32模型前。
可选地,每一个注意力模块CCA的结构相同;
在所述注意力模块中,先对输入图像按照预设卷积核进行卷积及最大池化处理得到初始特征图;然后采用三个1*1的卷积核对所述初始特征图进行特征提取,分别得到第一特征图、第二特征图、第三特征图;对所述第一特征图和第二特征图进行关联操作后执行归一化处理,得到第四特征图;对所述第三特征图和第四特征图进行聚合操作,得到目标特征图。
可选地,在所述ViT-B/32模型中,先对输入图像添加分类令牌信息,然后进行线性变换,将线性变换后的图像划分为指定大小的若干个图像块;将每一个图像块转换为低维特征向量;采用位置编码器为每一个图像块分配对应的位置嵌入向量并加入至所述低维向量特征,采用多层编码器对每一图像块的低维特征向量和位置嵌入向量进行特征提取,得到图像编码信息。
可选地,所述文本编码网络采用预训练词嵌入模型BERT;
在所述预训练词嵌入模型BERT中,先将证件照缺陷标记映射为高维实数向量,根据所述证件照缺陷标记在文本中的位置生成位置嵌入向量,采用多层编码器对所述高维实数向量及其对应的位置嵌入向量进行特征提取,得到特征编码,将所述特征编码投影到低维空间,得到文本编码信息;所述多层编码器中每五层结构包含自注意力机制和前馈神经网络。
可选地,所述模型训练模块41包括:
样本对获取单元,用于获取图像样本,对所述图像样本标注证件照缺陷及提示语文本信息,根据所述图像样本和证件照缺陷及提示语文本信息构建图像文本对;
训练单元,用于训练时每次将预设数量的图像文本对作为一个批次输入所述证件照缺陷检测模型进行训练,通过预设的目标优化函数得到图像文本对比损失;
优化单元,用于使用SGD优化器对每个批次的证件照缺陷检测模型的目标优化函数进行优化、反向传播,使图像对比损失下降到预设精度时停止迭代。
可选地,所述编码获取模块44包括:
计算单元,用于遍历所述文本特征数据库中的每一个文本编码信息,计算所述图像编码信息与所述文本编码信息之间的相似度;
获取单元,用于获取相似度最大的文本编码信息。
关于基于图文融合的证件照缺陷检测及提示装置的具体限定可以参见上文中对于基于图文融合的证件照缺陷检测及提示方法的限定,在此不再赘述。上述基于图文融合的证件照缺陷检测及提示装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于存储器中,以便于处理器调用执行以上各个模块对应的操作。
在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图5所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于图文融合的证件照缺陷检测及提示方法。
在一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现以下步骤:
构建及训练证件照缺陷检测模型,所述证件照缺陷检测模型包括文本编码网络和图像编码网络;
将证件照缺陷及提示语文本信息输入所述文本编码网络得到对应的文本编码信息,构建文本特征数据库;
获取待处理图像,采用所述证件照缺陷检测模型中的图像编码网络对所述待处理图像进行特征编码处理,得到图像编码信息;
从所述文本特征数据库中获取所述图像编码信息对应的文本编码信息;
根据所述文本编码信息获取对应的证件照缺陷及提示语文本信息。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本发明所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink) DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将所述装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。
以上所述实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围,均应包含在本发明的保护范围之内。
- 声音提示方法、声音提示装置、存储介质和电子设备
- 缺陷检测方法、装置、计算机设备及存储介质
- 一种通风故障提示方法、装置、设备以及存储介质
- 游戏角色的位置提示方法、装置、存储介质和电子设备
- 车辆行驶提示方法、装置、计算设备及存储介质
- 证件照的合规检测方法、装置、计算机设备及存储介质
- 证件照检测方法、装置、电子设备以及存储介质