基于协同过滤和概率语言术语集的新闻推荐方法及系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及信息推荐技术领域,尤其涉及基于协同过滤和概率语言术语集的新闻推荐方法及系统。
背景技术
近年来,随着互联网的发展和普及,越来越多的信息被制造和传播,每天都有大量的新闻文章被创建和发布,用户需要花费越来越多的时间和经理去筛选和整理这些新闻,才能找到自己真正感兴趣或对自己有利的内容。这就是信息爆炸和信息过载的影响,给用户带来了很大的信息负担,也影响了信息的利用效率和效果。为了能帮助用户能够更快、更准确的找到所感兴趣的新闻,降低信息的利用门槛,提高信息的利用效率和效果,新闻推荐算法应运而生。新闻推荐算法是一种根据用户的兴趣和行为,通过分析、筛选和排序新闻内容,为用户提供个性化的新闻推荐服务的算法。其目的是根据用户的喜好和需求,将最相关、最有价值的新闻推荐给用户,提高用户的阅读体验。
但现有的技术对用户所需的应用进行排名预测时,会有推荐内容过于单一、对新用户和新新闻的推荐效果不佳、数据存在稀疏性和为充分利用等问题,因此会导致很难在复杂的应用环境进行建模,很多算法难以投入实际使用。而基于深度学习的推荐算法因其能够处理大规模数据集、具有较强的泛化能力、能够处理复杂的非线性关系等优点被各大专家青睐,但也存在对于数据的要求较高,需要有足够的训练数据和计算资源、参数调整困难等问题。
发明内容
为了解决上述技术问题,本发明提出基于协同过滤和概率语言术语集的新闻推荐方法及系统。在所述方法及系统中,通过基于嵌入表示和单词嵌入技术的协同过滤算法,将用户和新闻文章同时嵌入潜在空间,利用它们之间的新闻文章相似性来预测用户感兴趣的内容,解决了在处理稀疏数据和冷启动问题时的限制;使用在线评论与概率语言术语集相结合的推荐算法,解决新用户和新投稿的新闻文章的推荐效果不佳的问题;最后让两种推荐算法通过排名排序的方法相融合,可以有效解决推荐系统覆盖率和多样性低、推荐内容过于单一等问题。
为了达到上述目的,本发明的技术方案如下:
基于协同过滤和概率语言术语集的新闻推荐方法,包括如下步骤:
采集数据并进行预处理,所述数据包括用户id、新闻文章id和每个用户交互过的所有新闻文章的id;
将用户id和每个用户交互过的所有新闻文章的id同时输入至UI2vec模型,输出每个用户对所有新闻文章的推荐概率值,通过softmax函数对每条新闻文章进行排序,获得概率值排序结果并将概率值排序结果发送至用户;
用户针对排序结果所对应的新闻文章进行在线评价,若评价满足,则完成新闻推荐任务,退出自动推荐功能;若评价不满意,则进入下一步;
读取每条新闻文章的评论内容以及针对推荐排序的在线评价内容,基于评价内容分析得到新闻文章之间的相似度,根据相似度大小确定相似度排序结果;
将概率值排序结果和相似度排序结果进行融合,获得融合排序结果并将融合排序结果发送至用户再次进行在线评价,直至用户满意推荐的新闻文章为止。
优选地,所述获得概率值排序结果,具体包括如下步骤:
将用户id和每个用户交互过的所有新闻文章的id同时作为输入,假设用户y
式中,W
隐藏层将d维隐藏层向量转换为大小与新闻数相同的向量,从隐藏层到输出层的转换矩阵为
输出层通过softmax函数获得每条新闻的相应概率值,针对第t条新闻文章,概率值o
其中
优选地,所述读取每条新闻文章的评论内容以及针对推荐排序的在线评价内容,基于评价内容分析得到新闻文章之间的相似度,根据相似度大小确定相似度排序结果,具体包括如下步骤:
读取每条新闻文章的评论内容以及针对推荐排序的在线评价内容并进行预处理;
将预处理后评价内容转换为概率语言术语集,构建评估矩阵;
通过最大偏差法确定属性权重;
基于评估矩阵中相同属性下的两条新闻文章之间的余弦相似性以及属性权重,获得两条新闻文章之间的加权相似度;
构建相似度矩阵,根据加权相似度大小确定相似度排序结果。
优选地,所述预处理包括通过Jieba中文分词工具将预处理后的评价内容切分成独立的词语,并手动去除罕见单词或语义模糊性的语句;去掉停止词。
优选地,所述通过最大偏差法确定属性权重,具体包括如下步骤:
设w={w
其中,#L
在评估矩阵P中,属性之间的总偏差程度为:
构建最大偏差优化模型:
使用拉格朗日函数求解模型:
其中n为属性词类型总数,m为新闻文章总数,λ是拉格朗日乘子,λ>0表示约束条件对目标函数有一定的约束力;
计算获得归一化的属性权重:
优选地,所述基于评估矩阵中相同属性下的两条新闻文章之间的余弦相似性以及属性权重,获得两条新闻文章之间的加权相似度,具体包括如下步骤:
计算概率语言术语集之间的余弦相似性确定相同属性下的两条新闻文章之间的相似性,其中#L
根据属性权重,得到两条新闻文章之间的加权相似度:
优选地,所述构建相似度矩阵,根据加权相似度大小确定相似度排序结果,具体包括如下步骤:
预设推荐阈值ξ,当两条新闻文章之间的加权相似度S(x
根据相似矩阵M,对到达推荐阈值的新闻文章进行推荐排名。
优选地,所述将概率值排序结果和相似度排序结果,获得融合排序结果,具体包括如下步骤:
计算每条新闻文章分别在概率值排序结果和相似度排序结果中的位置;
使用加权求和得到每条新闻文章的最终权重;
按照每条新闻文章的最终权重对所有新闻文章进行推荐排序。
基于上述内容,本发明还公开了基于排序融合协同过滤和概率语言术语集的新闻推荐系统,包括数据收集和处理模块、模型训练和推荐模块和反馈优化模块,其中,
所述数据收集和处理模块,用于采集数据并进行预处理,所述数据包括用户id、新闻文章id和每个用户交互过的所有新闻文章的id;
所述模型训练和推荐模块,用于将用户id和每个用户交互过的所有新闻文章的id同时输入至UI2vec模型,输出每个用户对所有新闻文章的推荐概率值,通过softmax函数对每条新闻文章进行排序,获得概率值排序结果并将概率值排序结果发送至用户;
所述反馈优化模块,用于接收用户针对排序结果所对应的新闻文章的在线评价,若评价满足,则完成新闻推荐任务,退出自动推荐功能;若评价不满意,则读取每条新闻文章的评论内容以及针对推荐排序的在线评价内容,基于评价内容分析得到新闻文章之间的相似度,根据相似度大小确定相似度排序结果;将概率值排序结果和相似度排序结果进行融合,获得融合排序结果并将融合排序结果发送至用户再次进行在线评价,直至用户满意推荐的新闻文章为止。
优选地,还包括评估模块,用于采用精确性、召回率和F1分数作为评价指标,基于评价指标评估新闻推荐系统的性能。
基于上述技术方案,本发明的有益效果是:本发明首先获得用户历史交互序列中的用户id和新闻文章id以及每个用户交互过的所有新闻文章的id,通过计算得到每个用户对所有新闻文章的推荐概率值,通过softmax函数对每条新闻文章进行排序,根据最终排序得到新闻文章的导引推荐。最后用户对推荐推荐系统进行选择评价反馈,推荐系统会抓取用户的在线评论进行分析,根据评论分析用户的需求来推荐新闻文章,再通过排名排序融合对两次推荐排序进行融合得到最终的新闻文章推荐排序。用户会再次评价,直到用户反馈满意最终的推荐导引新闻文章。本发明通过嵌入表示和单词嵌入技术的协同过滤算法,将用户和新闻文章同时嵌入潜在空间,利用它们之间的新闻文章相似性来预测用户感兴趣的内容,解决了在处理稀疏数据和冷启动问题时的限制;通过在线评论与概率语言术语集的推荐算法计算得到新闻文章之间的相似度,解决新用户和新新闻文章的推荐效果不佳的问题,使新用户也能有和老用户一样类似的推荐;通过排名排序融合将两种推荐算法推荐排序相融合,可以有效推荐内容过于单一等问题。能够极大提高了推荐覆盖率,使最终推荐排序富有多样选择性的同时提高推荐精确度。
附图说明
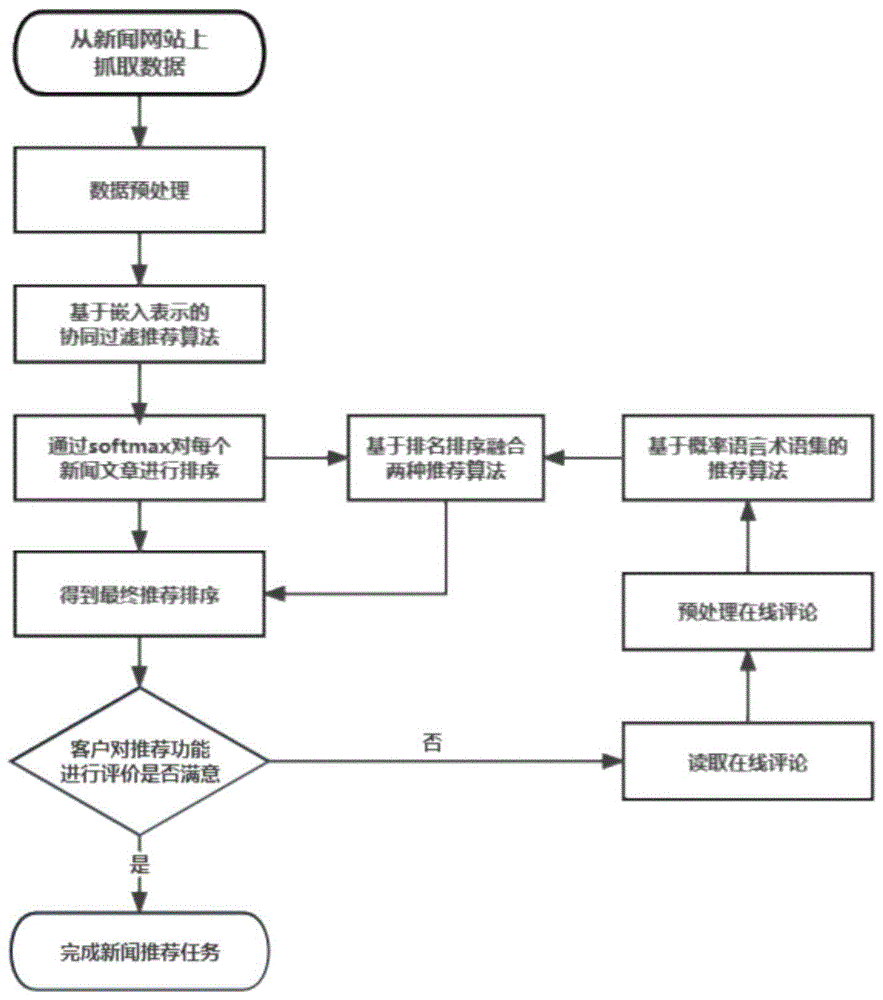
图1是一个实施例中基于协同过滤和概率语言术语集的新闻推荐方法流程图;
图2是一个实施例中基于协同过滤和概率语言术语集的新闻推荐方法中UI2vec模型图;
图3是一个实施例中基于协同过滤和概率语言术语集的新闻推荐方法中相似度排序推荐流程图;
图4是一个实施例中基于协同过滤和概率语言术语集的新闻推荐方法的架构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
如图1至4所示,本实施例提供一种基于协同过滤和概率语言术语集的新闻推荐方法,具体包括如下步骤:
步骤1:通过Python抓取腾讯新闻网站最新投稿新闻的id,该新闻相关评论者的id以及他们对该新闻具体的评论内容,通过数据预处理整理出符合模型运算的用户历史交互序列中用户id、新闻文章id、每个用户交互过的所有新闻文章的id以及每个参与评论用户的具体评论内容。
步骤2:将用户历史交互序列中的用户id和新闻文章id映射到一个热代码,融合通过线性变换获得用户和新闻文章的嵌入表示。最终得到每个用户对所有新闻文章的推荐概率值。如图2所示,具体包括以下步骤:
步骤2-1:将用户历史交互序列中的用户id和新闻文章id映射到一个热代码,然后通过线性变换获得用户和新闻文章的嵌入表示。用户和新闻文章的转换矩阵不共享,新闻文章之间的转换矩阵是共享的;
步骤2-2:假设用户y
式中,W
步骤2-3:隐藏层将d维隐藏层向量转换为大小与新闻数相同的向量。从隐藏层到输出层的转换矩阵为
步骤2-4:输出层通过softmax函数获得每条新闻的相应概率值o
结合等式(3)和(4)得出:
其中
步骤3:用户对推荐推荐系统进行评价。若用户满意此次推荐,那么推荐系统完成任务,退出自动推荐功能;反之,当用户不满足此次推荐,用户可以通过分析评价来反馈此次推荐过程中的不足,从而改变推荐排序,根据客户的评论重新推荐导引用户。
步骤4:如果用户对此次导引不满意并给出评论,推荐系统会将读取此次在线评论,读取所有新闻文章的评论信息,再对所有读取的数据进行预处理。具体包括如下步骤:
步骤4-1:读取用户此次的在线评论,同时也会进入应用网站更新最新在线评论,使用Python软件抓取所有|V|条新闻文章的信息,并为每条新闻文章选择q条评论。为了控制时间变量,我们获得了同一时期内每条新闻文章的审查数据,并将获得的数据存储在csv文件中。
步骤4-2:预处理在线评论,通过Jieba中文分词工具将中文文本切分成一个个独立的词语,并使用手动方法来处理具有罕见单词或语义模糊性的语句。去掉停止词,即缺乏实际意义或对陈述贡献不大的词后,设
步骤4-3:分析属性词,在诸多评论中词语分为三大类:首先是属性词,如“功能性”,“服务”等;其次是感情词,如“好用”,“方便”等;最后是情绪强度词,如“极端”,“很”,“非常”等。在分析属性词时,预设新闻文章的标准属性词
步骤4-4:通过知网感情词典,采用五粒度的语言术语来表达评论信息,即S={S
步骤4-5:在评论信息进行预处理后,概率语言术语集(Probabilistic LanguageTerm Set,PLTS)作为一种信息表达工具,用于统计描述评论信息。新闻文章的所有属性信息和评审术语的出现次数都由PLTS表示。具体流程如下:
步骤4-5-1:对于第i条新闻文章第t条评论,分析每个评论集
步骤4-5-2:统计每个评论词在每个属性词
步骤4-5-3:属性词的概率p(α)有以下公式计算:
其中,α是语言术语S
步骤5:构造基于概率语言术语集的新闻文章推荐算法,如图3所示,具体包括如下步骤:
步骤5-1:通过PLTS构建新闻文章评估矩阵P;
其中,L
步骤5-2:采用最大偏差发来确定属性权重。对于一个属性,方案之间的偏差越大,该属性的辨别能力就越强,因此分配的属性权重应该越多。设w={w
其中,#L
在评估矩阵P中,属性之间的总偏差程度为:
构建最大偏差优化模型:
使用拉格朗日函数求解模型:
其中n为属性词类型总数,m为新闻文章总数,λ是拉格朗日乘子,λ>0表示约束条件对目标函数有一定的约束力。较大的λ值会更强调约束条件,可能导致结果更接近约束条件的解。
通过以下等式获得归一化的属性权重:
步骤5-3:采用加权相似性的计算方法,计算所有新闻文章之间的相似性。首先通过计算PLTS之间的余弦相似性计算相同属性下的两条新闻文章之间的相似性,如下所示,其中#L
其次根据属性权重,得到两条新闻文章之间的加权相似度,如下所示:
最后构建新闻文章的相似度矩阵M,如下所示:
在相似度矩阵M中,对角线上的元素等于1,上三角形中的元素和下三角形中的元件相应地相等。在相似度矩阵M中,可以直接看到两条新闻文章之间的相似性。
步骤5-4:预设推荐阈值ξ,根据用户的真实需求,当S(x
步骤6:利用排名排序融合的方法将两种推荐排名融合,计算每条新闻文章在两个排名列表中的位置,然后使用加权求和的方法得到最终权重,最后按照权重大小对所有新闻文章进行推荐排序。最终权重大小通过以下公式得出:
R
在得到最终推荐排序之后,回到步骤3,让用户重新对推荐推荐系统进行评价,反复步骤3-6直至用户满意此次导引,退出自动导引功能,完成导引任务。
应该理解的是,虽然上述流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,上述流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
仿真算例:
为了验证本实例所提出算法的有效性,选择了2023年7月21日15:30腾讯新闻网网址上最新投稿并更新的87条新闻,引申出的13962名用户对应的16721条交互信息以及评论,并通过上述所有用户此前一周内与所有参与评论过的11598条新闻文章,引申出的211512名用户对应的460097条交互信息以及评论,分别将两组数据存储在news_data和news_con_data中,如表1所示。
表1网址抓取数据
使用Top-k推荐中常用的指标,分别是精确性、召回率和F1分数。计算上述指标首先要统计出预测答案正确的个数(TP),错将其他类预测为本类的个数(FP)以及本类标签预测为其他类标的个数(FN)。以下为计算各指标的公式:
将融合时的权重定w
表2模型对比试验结果
从表2中可以看出在数据量比较少时,本发明的UI2vec_PLTS推荐算法效果不明显,甚至低于两种推荐算法分别的推荐正确率,但随着数据量的增多,UI2vec_PLTS推荐算法在推荐精确率结果上有着优异的表现。
在一个实施例中,针对推荐系统中推荐覆盖率和准确率低的问题,提供了一种基于协同过滤和概率语言术语集的新闻推荐系统包括:数据收集和处理模块、模型训练和推荐模块和反馈优化模块,其中,
数据收集和处理模块,用于通过Python抓取腾讯新闻网站最新投稿新闻的所有相关数据以及对应新闻的评论者和他们的评论内容,通过数据预处理获得用户历史交互序列中的用户id和新闻文章id以及每个用户交互过的所有新闻文章的id。
模型训练和推荐模块,用于获得用户历史交互序列中的用户id和新闻文章id以及每个用户交互过的所有新闻文章的id之后,输入至UI2vec模型中进行训练,模型将用户和新闻文章同时嵌入潜在空间,利用它们之间的新闻文章相似性来预测用户感兴趣的内容,最终通过计算得到每个用户对所有新闻文章的推荐概率值,通过softmax函数对每条新闻文章进行排序,确保每个元素都在0到1之间,根据最终排序得到新闻文章的推荐排名。
反馈优化模块,用于当得到UI2vec模型的最终推荐排序后,接收用户对推荐推荐系统进行的选择评价。若用户满意此次推荐,那么推荐系统完成任务,退出自动推荐功能,反之,当用户不满足此次推荐,用户可以通过评价此次推荐,推荐系统会抓取用户的在线评论,首先预处理用户的在线评论构建评估矩阵,通过最大偏差法确定属性权重,再通过加权相似性构建相似度矩阵,最后通过相似度矩阵得到新闻文章之间的相似度,分析用户的评价以推荐与用户评价功能相似的应用,并根据相似度大小进行推荐排名。为了能让用户有更多的推荐选择,在模块最后对两种推荐算法的排名排序融合,得到新闻文章排序。用户再次评价,直到用户反馈满意最终的推荐新闻文章。
在一个实施例的基于协同过滤和概率语言术语集的新闻推荐系统中,还包括评估模块,用于采用精确性、召回率和F1分数作为评价指标,基于评价指标评估新闻推荐系统的性能。
以上所述仅为本发明所公开的基于协同过滤和概率语言术语集的新闻推荐方法及系统的优选实施方式,并非用于限定本说明书实施例的保护范围。凡在本说明书实施例的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本说明书实施例的保护范围之内。
- 基于云模型下的概率语言术语集VIKOR理论的性能优选分析方法
- 一种基于概率语言术语集的PM2.5排放权分配方法