基于断点剔除的地层超剥点识别方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及勘探地球物理学技术领域,特别是涉及到一种基于断点剔除的地层超剥点识别方法。
背景技术
地层油藏具有含油高度低、平面上呈条带状分布的特点,超剥线边界直接控制含油面积大小,因此超剥点识别对于地层油藏至关重要。
相位属性和波形分类技术是识别地层超剥点的常用方法,它们依托于地震波形形态的变化来判断地层超剥点位置,沿不整合面往上往下开取时窗,提取相位属性或者进行波形分类,可以有效呈现地层超剥线的平面展布规律,是一种识别地层超剥线的有效方法。但是在断层发育区,相位属性和波形分类技术所识别出的超剥点混杂着很多断点,为地层超剥点的识别带来很大困难。
专利技术“基于迭代地震DNA检测的地层超剥线识别方法”,将地震DNA算法首次引入到地层超剥点的识别中,超剥点两侧地震反射结构存在差异,即对应不同字符串(地震DNA)的突变,通过搜索字符串突变点实现超剥点识别。但是地震反射结构的突变,不仅由超剥点引起,断点和岩性尖灭点等等都会引起地震反射结构的突变,因此该方法所识别的地层超剥点仍然混杂着很多断点或岩性尖灭点。
如何从地震资料出发,剔除断点的影响,准确识别地层超剥点,是一个亟需解决的问题。
在申请号:CN201410638655.1的中国专利申请中,涉及到一种基于迭代地震DNA检测的地层超剥线识别方法,该基于迭代地震DNA检测的地层超剥线识别方法包括:步骤1,输入三维地震数据体和不整合面层位数据;步骤2,获取目标地震数据;步骤3,将目标地震数据转换成字符数据;步骤4,设定搜索参数;步骤5,将满足搜索参数的波组特征变化处作为超剥点,并将其记录下来;以及步骤6,输出超剥线,得到地层超剥线在平面上的分布。该基于迭代地震DNA检测的地层超剥线识别方法是基于迭代地震DNA检测的地层超剥线识别方法,可实现准确、高效的检测结果,该方法可以降低地质研究人员的劳动强度,提高勘探部署质量和效益。
在申请号:CN201610727136.1的中国专利申请中,涉及到一种生物启发计算地层圈闭油气藏超剥线识别方法,该生物启发计算地层圈闭油气藏超剥线识别方法包括:步骤1,输入三维地震数据体;步骤2,针对需要识别的地层超剥线大致范围,采用一种边缘检测手段来增强地震数据在空间上的连续性;步骤3,设定搜索参数;步骤4,将满足地层连续性敏感性强的参数运算并形成生物启发计算连续性属性数据体;步骤5,追踪解释具有超剥特征的生物启发计算连续性属性数据体,得出地层超剥线在平面上的分布。该生物启发计算地层圈闭油气藏超剥线识别方法可实现高效的检测结果并准确确定超剥线的位置,可以降低超剥线识别的多解性,提高勘探部署质量和效益。
在申请号:CN201710704161.2的中国专利申请中,涉及到一种层间积分超剥线识别及提取方法,该层间积分超剥线识别及提取方法包括:步骤1,在瞬时相位基础上,实现地震数据布尔值化;步骤2,在地震数据布尔值化后,利用层间积分实现超剥线识别;步骤3,在超剥线识别后,利用差分法实现超剥线提取。该层间积分超剥线识别及提取方法可以利用地震数据,通过瞬时相位全局归一化,实现地震数据布尔值化,在地震数据布尔值化基础上,通过层间积分识别超剥线,在超剥线识别后,通过差分法实现地层超剥线提取。
以上现有技术均与本发明有较大区别,未能解决我们想要解决的技术问题,为此我们发明了一种新的基于断点剔除的地层超剥点识别方法。
发明内容
本发明的目的是提供一种更加准确地识别地层超剥点的基于断点剔除的地层超剥点识别方法。
本发明的目的可通过如下技术措施来实现:基于断点剔除的地层超剥点识别方法,该基于断点剔除的地层超剥点识别方法包括:
步骤1,输入地震数据和不整合面解释成果,并对地震数据进行切割处理;
步骤2,对切割后的地震数据体计算隔道相关系数,并赋值为当前道的相关系数值;
步骤3,使用孤立森林算法,针对每道的相关系数值,查找突变点;
步骤4,根据突变点密集程度,剔除断点,保留超剥点。
本发明的目的还可通过如下技术措施来实现:
在步骤1中,根据不整合类型,是超覆地层还是剥蚀地层,沿不整合面层位往上或往下开取时窗,在该时窗范围内,对三维地震数据进行切割处理。
在步骤2中,针对切割后的三维地震数据,沿主测线方向,计算每道的左右相邻两道的相关系数,并赋值为当前道的相关系数值,同时记录该道的位置信息包括横坐标、纵坐标、时间。
在步骤2中,存在超剥点、断点这些突变点的地方,突变点两侧的地震反射结构差异性较大,突变点两侧的两道地震数据的相关性较小;不存在突变点的地方,两道地震数据的相关性较好;因此由相关性大小可以判断突变点位置,相关性较好为正常点,相关性较差为突变点。
在步骤2中,假设当前道两侧的地震数据分别记为x、y,元素个数都是n,相关性r的计算公式如下:
在步骤3,选择一小部分主测线,将相关系数值作为属性,在0~1之间随机选择一个值,该值能区分地震反射结构的突变点和连续点,完成孤立森林算法的训练过程。
在步骤3,在三维工区范围内,针对每条主测线,用训练好的孤立森林模型完成突变点的预测。
在步骤4,根据突变点密集程度,将密集程度较高的断点剔除掉,其它点保留为超剥点。
在步骤4,以查找出的突变点数据集为输入数据,沿着主测线方向,根据坐标和时间信息,判断这些突变点的密度程度,较为密集的点为断点,较为孤立的点为超剥点。
在步骤4,假设Q是主测线方向突变点的点集,X(x
上述公式中的突变点Y(y
本发明中的基于断点剔除的地层超剥点识别方法,从地震数据出发,沿不整合面开取时窗,采用孤立森林算法识别地震反射结构的突变点,突破了相位属性识别突变点对层位解释结果依赖性较强的难点,该方法对地层突变点的识别更加准确和合面;通过突变点密集度分析技术剔除其中由断点造成的突变点,从而更加准确地识别地层超剥点。在断层发育区识别地层超剥点时,与传统方法相比,该方法适用性更强。
附图说明
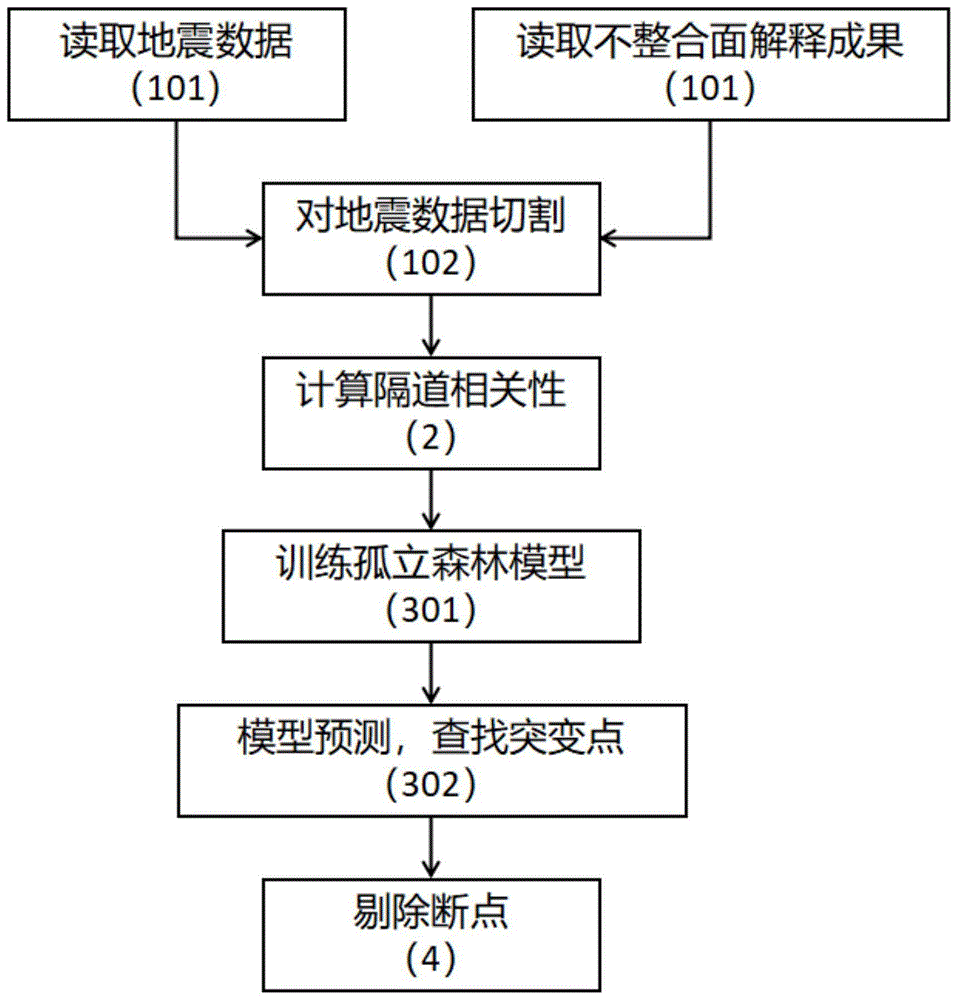
图1为本发明的基于断点剔除的地层超剥点识别方法的一具体实施例的流程图;
图2为本发明的一具体实施例中地震切割前后对比图;
图3为本发明的一具体实施例中孤立森林原理示意图;
图4为本发明的一具体实施例中超剥点和断点地震反射结构差异性示意图;
图5为本发明的一具体实施例中剔除断点前后识别超剥点结果对比分析图。
具体实施方式
应该指出,以下详细说明都是示例性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作和/或它们的组合。
本发明的基于断点剔除的地层超剥点识别方法包括了以下步骤:
步骤1,输入地震数据和不整合面解释成果,并对地震数据进行切割处理;
步骤2,对切割后的地震数据体计算隔道相关系数,并赋值为当前道的相关系数值;
步骤3,使用孤立森林算法,针对每道的相关系数值,查找突变点;
步骤4,根据突变点密集程度,剔除断点,保留超剥点。
以下为应用本发明的几个具体实施例
实施例1
在应用本发明的一具体实施例1中,该基于断点剔除的地层超剥点识别方法包括了以下步骤:
在步骤1中,输入三维工区地震数据,以及不整合面解释成果(层位数据)。
根据不整合类型,是超覆地层还是剥蚀地层,沿不整合面层位往上或往下开取时窗,在该时窗范围内,对三维地震数据进行切割处理。
在步骤2中,针对切割后的三维地震数据,沿主测线方向,计算每道的左右相邻两道的相关系数,并赋值为当前道的相关系数值,同时记录该道的位置信息(包括横坐标、纵坐标、时间)。
在步骤3中,选择一小部分主测线,将相关系数值作为属性,在0~1之间随机选择一个值(该值能区分地震反射结构的突变点和连续点),完成孤立森林算法的训练过程。
在三维工区范围内,针对每条主测线,用训练好的孤立森林模型完成突变点的预测。
在步骤4中,根据突变点密集程度,将密集程度较高的断点剔除掉,其它点保留为超剥点。
实施例2
在应用本发明的一具体实施例2中,如图1所示,图1为本发明的基于断点剔除的地层超剥点识别方法的流程图。该基于断点剔除的地层超剥点识别方法包括了以下步骤:
步骤101,输入三维工区地震数据,以及不整合面解释成果(层位数据)。
步骤102,根据不整合类型,是超覆地层还是剥蚀地层,沿不整合面层位往上或往下开取时窗,在该时窗范围内,对三维地震数据进行切割处理。
步骤2,计算隔道相关性。针对切割后的三维地震数据,沿主测线方向,计算每道的左右相邻两道的相关系数,并赋值为当前道的相关系数值,同时记录该道的位置信息(包括横坐标、纵坐标、时间)。
存在超剥点、断点等突变点的地方,突变点两侧的地震反射结构差异性较大,突变点两侧的两道地震数据的相关性较小;不存在突变点的地方,两道地震数据的相关性较好。因此由相关性大小可以判断突变点位置,相关性较好为正常点,相关性较差为突变点。
假设当前道两侧的地震数据分别记为X、Y,元素个数都是n,相关性的计算公式如下:
步骤301,选择一小部分主测线,将相关系数值作为属性值,在0~1之间随机选择一个值(该值能区分地震反射结构的突变点和连续点),完成孤立森林算法的训练过程。
孤立森林是一种随机二叉树,每个节点要么有两个孩子,要么一个孩子都没有,也就是叶子节点。对于从相关性入手查找突变点来说,孤立森林的每个节点,要么是两个孩子(正常点和异常点),要么是叶子节点(异常点)。通过孤立森林的随机二叉树,可以轻松地将异常点和正常点划分为两类。
步骤302,在三维工区范围内,针对每条主测线,用训练好的孤立森林模型完成突变点的预测。
iTree构建好后,就可以对实际数据进行预测,预测的过程就是把测试记录在iTree上走一遍,看测试记录落在哪个叶子节点。iTree能有效检测异常点(突变点)的前提是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径长度来判断该点是否是异常点。
从步骤301和步骤302中,可以得到突变点的分布位置,记录突变点用三列数据:(横坐标、纵坐标、时间)。
步骤4,根据突变点密集程度,将密集程度较高的断点剔除掉,其它点保留为超剥点。
以查找出的突变点数据集为输入数据,沿着主测线方向,根据坐标和时间信息,判断这些突变点的密度程度,较为密集的点为断点,较为孤立的点为超剥点。设计滑动时窗,往左或往右滑动,断点周围一直存在突变点,断点分布比较密集,超剥点周围不再出现第二个突变点,超剥点分布比较孤立。
假设Q是主测线方向突变点的点集,X(x
上述公式中的突变点Y(y
从实际工区应用情况来看,该方法在查找地层超剥点时,受断点干扰明显减少,专利技术识别结果很好地剔除了断点的影响,从而使得该工区沙四下剥蚀点识别结果更加清晰和明确。
实施例3
在应用本发明的一具体实施例3中,本发明的基于断点剔除的地层超剥点识别方法包括了以下步骤:
步骤101,输入三维工区地震数据,以及不整合面解释成果(层位数据)。
步骤102,根据不整合类型,是超覆地层还是剥蚀地层,沿不整合面层位往上或往下开取时窗,在该时窗范围内,对三维地震数据进行切割处理,如图2所示。图2是地震切割前后对比图;图2(a)是地震切割前的剖面图;图2(b)是地震切割后的剖面图,该地层是剥蚀地层,因此沿不整合面往下开取一定时窗,在该时窗内,将地震数据进行切割处理。
步骤2,计算隔道相关性。针对切割后的三维地震数据,沿主测线方向,计算每道的左右相邻两道的相关系数,并赋值为当前道的相关系数值,同时记录该道的位置信息(包括横坐标、纵坐标、时间)。
存在超剥点、断点等突变点的地方,突变点两侧的地震反射结构差异性较大,突变点两侧的两道地震数据的相关性较小;不存在突变点的地方,两道地震数据的相关性较好。因此由相关性大小可以判断突变点位置,相关性较好为正常点,相关性较差为突变点。
假设当前道两侧的地震数据分别记为X、Y,元素个数都是n,相关性的计算公式如下:
步骤301,选择一小部分主测线,将相关系数值作为属性值,在0~1之间随机选择一个值(该值能区分地震反射结构的突变点和连续点),完成孤立森林算法的训练过程。
孤立森林是一种随机二叉树,每个节点要么有两个孩子,要么一个孩子都没有,也就是叶子节点。对于从相关性入手查找突变点来说,孤立森林的每个节点,要么是两个孩子(正常点和异常点),要么是叶子节点(异常点)。其原理如图3所示,图3是孤立森林原理示意图,灰色的异常点与黑色的正常点之间的属性值差异较大,通过孤立森林的随机二叉树,可以轻松地将异常点和正常点划分为两类。
单棵树的训练过程如下:
输入:某一主测线的相关系数值(向量X),当前树高度(e),树的高度上限(l),任意选定数值p∈(0,1):
输出:iTree
1:在该主测线的相关系数值中任选一数,即任选q∈X;
2、如果q<p,则该数所在的点为异常点;
3:如果q≥p,则该数所在的点为正常点;
4、如果当前树高度超出高度上限,即e≥l,则退出训练过程;
5:遍历向量X中的所有值,找出其中所有的异常点。
假设一棵树认为q是异常点,这一结果未必准确,因为p是(0,1)之间的任意值,q与p存在诸多偶然性;但是如果100棵树进行这样的随机分割,其中80棵树都认为q是异常点,那么这个结果就比较可信了。
步骤302,在三维工区范围内,针对每条主测线,用训练好的孤立森林模型完成突变点的预测。
iTree构建好后,就可以对实际数据进行预测,预测的过程就是把测试记录在iTree上走一遍,看测试记录落在哪个叶子节点。iTree能有效检测异常点(突变点)的前提是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径长度来判断该点是否是异常点。
从步骤301和步骤302中,可以得到突变点的分布位置,记录突变点用三列数据:(横坐标、纵坐标、时间)。
步骤4,根据突变点密集程度,将密集程度较高的断点剔除掉,其它点保留为超剥点。
以查找出的突变点数据集为输入数据,沿着主测线方向,根据坐标和时间信息,判断这些突变点的密度程度,较为密集的点为断点,较为孤立的点为超剥点。如图4所示,图4为超剥点和断点地震反射结构差异性示意图;图4(a)是超剥点地震反射结构示意图,图4(b)是断点地震反射结构示意图。从图中可以看出,超剥点或断点两边,对应不同地震反射结构,超剥点或断点都是突变点。设计滑动时窗,往左或往右滑动,断点周围一直存在突变点,断点分布比较密集,超剥点周围不再出现第二个突变点,超剥点分布比较孤立。
假设Q是主测线方向突变点的点集,X(x
上述公式中的突变点Y(y
从实际工区应用情况来看,该方法在查找地层超剥点时,受断点干扰明显减少,如图5所示。图5为剔除断点前后识别超剥点结果对比分析图;图5(a)是某工区沿t7往下开40ms的超剥点识别结果(传统方法),图5(b)是某工区沿t7往下开40ms的超剥点识别结果(专利技术)。从两图超剥点识别结果对比分析看出,方形所指示的断层发育区,专利技术识别结果很好地剔除了断点的影响,从而使得该工区沙四下剥蚀点识别结果更加清晰和明确。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域技术人员来说,其依然可以对前述实施例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
除说明书所述的技术特征外,均为本专业技术人员的已知技术。
- 基于迭代地震DNA检测的地层超剥线识别方法
- 基于迭代地震DNA检测的地层超剥线识别方法