语音转换方法及语音转换模型的训练方法、电子设备和存储介质
文献发布时间:2024-04-18 19:58:53
技术领域
本申请实施例涉及语音生成任务领域,特别是涉及一种语音转换方法及语音转换模型的训练方法、电子设备和存储介质。
背景技术
相关技术中,Voice Conversion(VC,语音转换)处理的问题是输入一段声音,输出另外一段声音,但这两段声音有些不同,一般希望保留声音的内容,改变说话人的音色。
最早执行Zero-Shot Voice Conversion(零样本语音转换)的工作使用的是Auto-Encoder(自动编码器)架构,通过精心设计的bottleneck(瓶颈层)来分离语音中的内容信息和身份信息,这些相关技术中使用的引用身份信息多是用Speaker Embedding(说话人嵌入)来表示,提取Speaker Embedding有很多方式,包括使用预训练身份编码器和从后验分布中采样,还有许多工作致力于改进提取Speaker Embedding的方法。
另一类分离语音中身份和内容信息的方法是使用Normalizing Flow(标准化流),利用可逆的流来去除身份信息,再在正向解码过程中添加Speaker Embedding得到转换后的语音。
还有一类方法是通过使用自监督语义特征来实现信息分离,如vq-wav2vec和HuBERT特征,很多之前的方案表明这些特征只包含少量的身份信息,相关技术将这些特征引入Auto-Encoder架构,或是用复杂的自回归语言模型,或是使用Vocoder(判别器);提供身份信息同样是依靠Speaker Embedding。
发明人认为,该方案的编码方式是单向的,即无法通过编码后的结果恢复原来的编码,这使得其只能用于语音识别等特定任务中,而无法用于例如语音生成任务中。
发明内容
本发明实施例提供了一种语音转换方法及语音转换模型的训练方法、电子设备和存储介质,用于至少解决上述技术问题之一。
第一方面,本发明实施例提供了一种语音转换方法,包括:使用预训练模型从源语音中提取语义特征;从引用语音中提取梅尔频谱特征,并使用一层卷积神经网络对所述梅尔频谱特征进行编码得到引用特征;将所述语义特征经过两个语义编码器,其中,两个语义编码器之间还包括辅助特征适配器,所述辅助特征适配器用于根据第一个语义编码器的输出进行PPE的预测;利用判别器对第二个语义编码器的输出进行上采样得到最终语音;其中,每个语义编码器均包括两个构词块,每个构词块包括自注意力模块、交叉注意力模块、卷积层和投影层,所述交叉注意力模块用于引入所述引用特征。
第二方面,本发明实施例提供了一种语音转换型的训练方法,其中,所述语音转换模型包括预训练模型,两个语义编码器,辅助特征适配器以及判别器,包括:将同一说话人的单个语音篇章分成第一片段和第二片段,其中,所述第一片段为从随机起点开始剪切的长度在预设长度阈值内随机变化的片段,所述第二片段为所述单个语音篇章中除了所述第一片段后剩余的部分;从所述第一片段中提取用于提供说话人信息的梅尔频谱;将所述第二片段输入至预训练模型以提取语义特征;使用第一个语义编码器的输出预测PPE,将真实PPE添加至所述第一个语义编码器的输出中,以辅助重建波形;计算判别器损耗并利用所述判别器损耗训练所述语音转换模型
第三方面,本发明实施例提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明上述任一项语音转换方法或语音转换模型的训练方法。
第四方面,本发明实施例提供一种存储介质,所述存储介质中存储有一个或多个包括执行指令的程序,所述执行指令能够被电子设备(包括但不限于计算机,服务器,或者网络设备等)读取并执行,以用于执行本发明上述任一项语音转换方法或语音转换模型的训练方法。
第五方面,本发明实施例还提供一种计算机程序产品,所述计算机程序产品包括存储在存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,使所述计算机执行上述任一项语音转换方法或语音转换模型的训练方法。
本申请的方案通过强大的位置无关交叉注意机制从引用语音中学习并纳入说话人音色,然后以非自回归的方式从HuBERT语义特征重建波形,以简洁设计增强了其训练稳定性和语音转换性能。进一步地,本申请地方案在生成高质量语音方面具有优越性,与目标引用语音的相似度更高,即使是非常短的引用语音也不例外。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一实施例提供的一种语音转换方法及语音转换模型的训练方法的流程图;
图2为本发明一实施例提供的SEF-VC的模型架构;
图3为本发明一实施例提供的SEF-VC和其他基线在任意语音到任意语音转换中的性能比较;
图4为本发明一实施例提供的不同长度的引用语音对零样本VC影响的实验;
图5为本发明一实施例提供的不同说话人建模效果的实验;
图6为本发明一实施例提供的电子设备的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
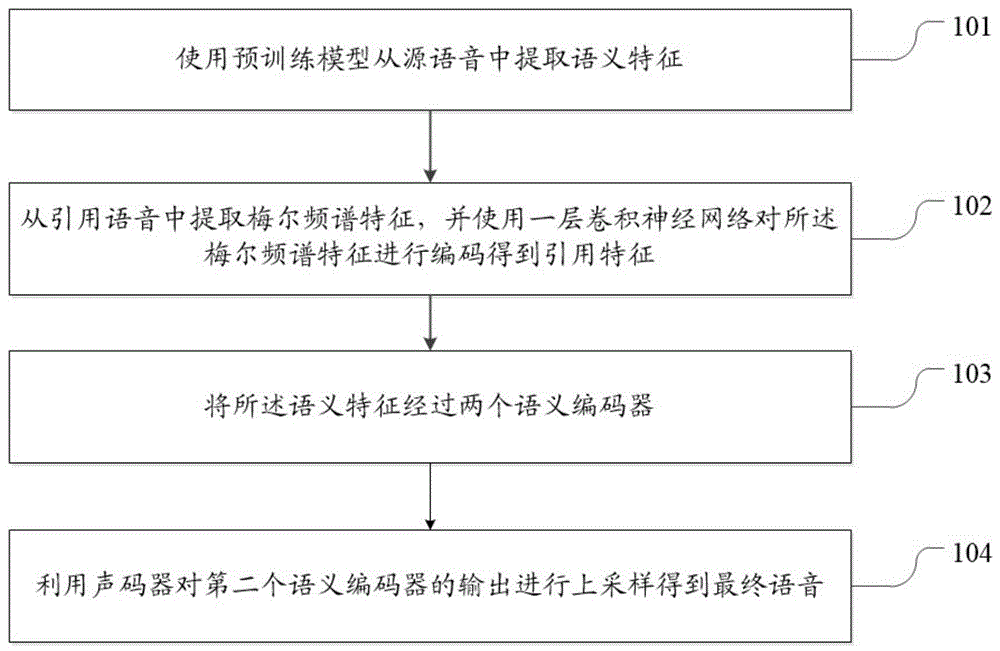
请参考图1,其示出了本发明一实施例提供的一种语音转换方法及语音转换模型的训练方法的流程图。
如图1所示,在步骤101中,使用预训练模型从源语音中提取语义特征;
在步骤102中,从引用语音中提取梅尔频谱特征,并使用一层卷积神经网络对所述梅尔频谱特征进行编码得到引用特征;
在步骤103中,将所述语义特征经过两个语义编码器,其中,两个语义编码器之间还包括辅助特征适配器,所述辅助特征适配器用于根据第一个语义编码器的输出进行PPE的预测;
在步骤104中,利用判别器对第二个语义编码器的输出进行上采样得到最终语音;其中,每个语义编码器均包括两个构词块,每个构词块包括自注意力模块、交叉注意力模块、卷积层和投影层,所述交叉注意力模块用于引入所述引用特征。
本申请实施例的方案本申请的方案通过使用位置无关交叉注意机制从引用语音中学习并纳入说话人音色,然后以非自回归的方式从HuBERT语义特征重建波形,以简洁设计增强了其训练稳定性和语音转换性能。进一步地,本申请地方案在生成高质量语音方面具有优越性,与目标引用语音的相似度更高,即使是非常短的引用语音也不例外。
在一些可选的实施例中,所述预训练模型为HuBERT模型。还可以是其他预训练模型,比如vq-wav2vec等模型。
在一些可选的实施例中,所述判别器为HifiGAN。
在一些可选的实施例中,所述交叉注意力模块为与位置无关的交叉注意力模块。
在另一个实施例中,本申请方案还提供一种语音转换模型的训练方法,其中,所述语音转换模型包括预训练模型,两个语义编码器,辅助特征适配器以及判别器,包括:将同一说话人的单个语音篇章分成第一片段和第二片段,其中,所述第一片段为从随机起点开始剪切的长度在预设长度阈值内随机变化的片段,所述第二片段为所述单个语音篇章中除了所述第一片段后剩余的部分;从所述第一片段中提取用于提供说话人信息的梅尔频谱;将所述第二片段输入至预训练模型以提取语义特征;使用第一个语义编码器的输出预测PPE,将真实PPE添加至所述第一个语义编码器的输出中,以辅助重建波形;计算判别器损耗并利用所述判别器损耗训练所述语音转换模型。
从而以上述方式训练得到的语音转换模型能够实现如前述实施例所述的更好的效果。
在一些可选的实施例中,所述判别器为HifiGAN,所述判别器损耗为真实波形与合成波形之间的重建损耗、HifiGAN的鉴别器中间输出的L1特征匹配损失、第二个语义编码器的输出与目标梅尔频谱图之间的L1距离、以L1形式计算的真实PPE与辅助特征适配器输出的PPE之间的损失以及L2形式的对抗损失的加权和。
发明人在实现本申请的过程中发现,相关技术生成的语音质量差,且目标说话人的声音相似度还不够好。
发明人认为上述缺陷是由于以下原因导致的:一方面,基于Auto-Encoder的方案由于生成的语音极大的依赖隐变量bottleneck,所以生成的语音质量很差;另一方面,这些方案都严重依赖于Speaker Embedding提供身份信息,但Speaker Embedding并不能提供丰富的身份信息,还有一些与身份相关的信息如Pitch就是和时间相关的,同时SpeakerEmbedding对于短语音并不稳定,因此生成的语音在和目标人上相似度还有一定差距。
本领域技术人员在面对上述相关技术的缺陷时,通常会采用提高引用语音长度的方法,很多工作在测试指标时特意挑选长度较长的语音作为引用,从而提高SpeakerEmbedding的稳定性和可靠性。
本申请实施例的方案通过cross-attention(交叉注意力)机制来学习和整合说话人身份信息,与之前的方案不同(Speaker Embedding),本申请实施例采用包含更多细节的声学特征mel-spectrogram(梅尔频谱)来通过cross-attention机制提供身份信息。
请参考图2,其示出了本申请实施例的模型架构图。
首先,从Source Speech中使用预训练的HuBERT模型提取语义特征,即SemanticTokens。
然后,从Reference Speech中提取Mel-Spectrogram,并使用一层卷积神经网络对其编码(引用特征)。
其次,Semantic Tokens经过两个Semantic Encoder,每个Semantic Encoder中都包含了2个Conformer Block,每个Conformer依次包含了self-attention、cross-attention(与2中的引用特征)、卷积层和投影层。在两个Semantic Encoder之间还有一个Auxiliary Feature Adaptor根据第一个Semantic Encoder的输出预测PPE(Pitch,Probability of Voice,Energy)。
最后,HifiGAN将第二个Semantic Encoder的输出上采样得到最终的语音。
发明人进行了实验,发现在3秒的引用片段上,主观和客观评测表明说话人相似度指标(SECS和Sim-MOS)都要比该领域中的Baseline要好,可懂度(Nat-MOS)也有很大的提升。不仅如此,还能支持更短的目标引用语音,即对短的引用片段也有很好的鲁棒性,图4中灰色曲线为我们的方法,黑色曲线为Baseline。更深层的意义是,在某些低资源场景下,如目标人语音很短的情况下,我们的方法能够产生更具有竞争性的结果,同时随着引用语音变长,取得的结果也会越来越好。进一步,cross-attention这种信息整合方式会被应用到其它声学特征上,可能会进一步提高语音转换的结果。
以下通过详细介绍发明人对于本申请实施例的具体实现过程和实验数据,以使本领域技术人员更好地理解本申请的技术方案。
零样本语音转换(Zero-shot voice conversion,VC)的任务是在保留语音内容的前提下,将给定语音从源说话人转换为之前未见过的目标说话人。这主要涉及两个难点:说话人和内容信息的分离以及说话人表征建模。解耦的目的是去除源语音中的说话人信息,而说话人表示建模则是寻求一种更好的方法来表示和纳入说话人身份。
在说话人信息分离方面,人们一直在进行积极的研究。首先开发了基于自动编码器的VC方法,这种方法通过设计语音重构过程中的信息瓶颈来学习有意义的潜在表征。这些瓶颈特征可以在一定程度上分离说话人信息,但通常会牺牲语音质量。归一化流为说话人适应和VC提供了一种更优雅的方法,如YourTTS。最近,一种更流行的说话人分离技术是采用自监督语义特征,如vq-wav2vec和HuBERT。事实证明,这些模型提取的特征能很好地保留语言内容,同时与说话人身份有很少相关。之前的研究将自监督语义特征引入到VC中,但仍然是在传统的自动编码器框架中,或者不是以任意对任意的方式。相关技术提出训练一个从语义特征合成波形的判别器,这也带来了一个更简单的VC框架。
然而,在复制目标语音的过程中,说话人身份的特征建模仍有待研究。大多数VC方法都依赖于全局说话人嵌入,尤其是来自说话人验证网络。一些相关技术采用预训练的说话人编码器。一些相关技术从后验分布中采样说话人嵌入。另一些相关技术引入了一种说话人表示方法,以更好地表示目标说话人的特征。因此,这些方法的VC性能受限于说话人嵌入的表征能力,而且它们对短引用语音(references)也没有鲁棒性。最近的语音语言模型避免了这一问题,它们采用了很有前途的上下文学习策略,能根据语音提示预测目标语音。但由于其自回归性质,它们也存在稳定性问题。
与之前的工作不同,本申请实施例提出了SEF-VC,这是一种无说话人嵌入的零样本VC模型。我们建议使用与位置无关的交叉注意机制作为说话人建模方法。这就用一种新颖、有效和鲁棒的交叉注意机制取代了传统的说话人嵌入方法。然后,SEFVC被设计为通过这种交叉注意机制从引用语音(reference speech)中学习并纳入说话人音色,然后以非自回归的方式从HuBERT语义特征重建波形。利用位置无关的交叉注意力机制,可以更好地模拟说话人信息,并将其纳入语义主干。客观和主观评估结果表明,SEF-VC优于几种强VC基线。消减研究进一步显示了使用交叉注意而非说话人嵌入的优势,以及SEF-VC在不同提示长度下的能力。音频样本请访问https:///junjiell.github.io/SEF-VC/。
图2示出了SEF-VC的模型架构。
非自回归语义主干网(Non-Autoregressive Semantic Backbone)
该模型的结构如图2所示。SEF-VC的主干模型是离散自监督语音表示的标准判别器,如vec2wav和SSR-VC。我们首先通过对预训练的HuBERT模型提取的连续特征进行K-Means量化来获得语义特征。然后,帧级语义特征通过两个语义编码器,再在HifiGAN判别器中上采样为波形。根据vec2wav,在两个语义编码器之间放置了一个辅助特征适配器,通过预测音高、语音概率和能量(PPE:Pitch,Probability of Voice,Energy)来帮助语音韵律特征(speech prosody features)进行建模。
为了提高合成质量,我们还按照判别器的做法采用了对抗训练。这里的判别器包括一个多周期判别器(MPD,Multi-Period Discriminator)和一个多尺度判别器(MSD,Multi-Scale Discriminator),后者是在HifiGAN中提出的,用于区分重建波形和地面真实(ground truth,真实)波形。
与位置无关的交叉注意力机制(Position-Agnostic Cross-AttentionMechanism)
由于自监督语义特征几乎不提供说话人信息,因此音色转换必须依赖于明确引入说话人信息。与以往采用说话人嵌入的工作不同,我们将其表述为不依赖说话人嵌入的交叉注意任务,即语义主干直接从引用语音中学习并纳入说话人音色。为了在引用语音中引入足够的说话人信息,并从中提取梅尔频谱,我们使用了与位置无关的交叉注意机制,将说话人信息纳入语义主干网。
具体来说,在语义主干网中,每个语义编码器都由多个构词块(Conformerblocks)组成。在每个Conformer blocks中,发明人在自注意层和卷积模块之间放置了一个交叉注意层。在交叉注意之前,目标语音的梅尔频谱图会通过一个梅尔编码器输入,该编码器由一维卷积层作为前置网组成。值得注意的是,这种交叉注意机制与输入位置无关,这意味着在根据编码后的梅尔序列计算键和值矩阵时,标准注意机制中的位置编码将被取消。这相当于对已编码的梅尔频谱进行扰乱,由于说话人的音色与时间顺序基本无关,因此打破顺序仍能保留相当数量的说话人信息,但其他信息则无法保留。这有助于交叉注意机制集中学习从引用语音中捕捉说话人的音色。
这种交叉注意机制对短引用和长引用都有好处。对于短引用语音,交叉注意机制仍可直接充分探索和利用梅尔频谱,而不会有通过说话人嵌入对说话人进行不准确建模的风险。对于长引用语音,与位置无关的交叉注意机制还有一个优势,即它能理想地支持任意长度的引用语音。与通过声学提示对语义内容进行前缀并仅通过自注意对整个序列进行建模的自回归语音语言模型相比,SEF-VC也不会因为非自回归方式的位置无关交叉注意方法而出现推理稳定性和速度问题。
训练和推理
如图2所示,发明人使用非并行数据来训练模型。然后,单个语篇(utterance)被分为两个片段(segments)。第一段用于提取提供说话人信息的梅尔频谱,它从一个随机的起点开始剪切,长度在2到3秒之间随机变化。第一段之后的其余语段作为第二段,输入预训练的HuBERT模型以提取语义特征。这种策略可确保两个片段始终属于同一个说话人,而无需使用说话人的Oracle标签。对于辅助特征适配器,在训练过程中,我们使用第一个语义编码器的输出来预测PPE。然后将地面真实(ground truth,真实)PPE添加到第一个语义编码器的输出中,辅助其余模块重建波形。
这种交叉注意机制对短引用和长引用都有好处。对于短引用语音,交叉注意机制仍可直接充分探索和利用梅尔频谱(mel-spectrograms),而不会有通过说话人嵌入对说话人进行不准确建模的风险。对于长引用语音,与位置无关的交叉注意机制还有一个优势,即它能理想地支持任意长度的引用语音。与通过声学提示对语义内容进行前缀并仅通过自注意对整个序列进行建模的自回归语音语言模型相比,SEF-VC也不会因为非自回归方式的位置无关交叉注意方法而出现推理稳定性和速度问题。
训练和推理
如图2所示,我们使用非并行数据来训练模型。然后,单个语篇被分为两个片段。第一段用于提取提供说话人信息的梅尔频谱,它从一个随机的起点开始剪切,长度在2到3秒之间随机变化。第一段之后的其余语段作为第二段,输入预训练的HuBERT模型以提取语义特征。这种策略可确保两个片段始终属于同一个说话人,而无需使用说话人的Oracle标签。对于辅助特征适配器,在训练过程中,我们使用第一个语义编码器的输出来预测PPE。然后将地面真实(ground truth,真实)PPE添加到第一个语义编码器的输出中,辅助其余模块重建波形。
判别器损耗LG是一个加权和,其中L
在语音转换的推理阶段,目标引用语音被用来提取包含说话人信息的梅尔频谱图,而源语音则被用来通过与训练过程相同的预训练HuBERT模型获取语义特征。根据语义信息和引用语音共同预测目标说话人的PPE。
数据和实现细节
本申请实施例的实验是在LibriTTS上进行的,这是一个多人英语数据集,总时长为586小时。发明人将语料的采样率降至16kHz,并排除了过长或过短的训练语料。该数据集共包含2456个说话人,其中训练集2311个,验证集73个,测试集72个。为了评估该模型在零样本语音转换中的性能,我们从LibriTTS的测试清洁集中选取了20个说话人。其中,10位说话人作为源说话人,每位说话人选择2个语段作为源语音。剩下的10个作为目标发言人,每个发言人选取1个长度约为3秒的语段作为引用语音。
发明人从基于60k小时LibriLight训练的预训练HuBERT模型中提取了1024维语义特征。然后通过KMeans聚类对语义特征进行离线量化,聚类中心为2,000个。两个语义编码器都由两个Conformer块组成,其中用于自我注意和交叉注意的多头注意层有2个头,注意维度为184。梅尔编码器包含1层卷积层,内核大小为5,输出维度为184。判别器和鉴别器均由Adam优化,初始学习率为0.0002,β1=0.5,β2=0.9。学习率每200k步下降0.5。各损失系数分别为:λmel=60,λaux=5,λrec=45,λadv=1,λfeat=2。此外,为了更好地捕捉声学细节,尤其是说话人的身份,引用梅尔频谱的帧移为10毫秒,而语义特征的帧移为20毫秒。
基线
发明人将SEF-VC与以下零样本VC方法进行了比较:
-AdaIN-VC,它通过简单地在自动编码器瓶颈处引入实例归一化来分离说话人和内容信息。它依靠说话人嵌入来建立说话人表征模型。
-YourTTS通过对流量进行归一化来执行说话人分离。它通过在反向流过程中分离源说话人信息,并在正向流中插入目标说话人嵌入来进行VC。
-Polyak等人通过对语音内容、前奏和说话人身份信息的分离表示来分离说话人和语义信息。它使用预训练编码器分别提取语义特征、音调特征和目标说话人嵌入,并使用HifiGAN判别器合成波形。为便于表述,我们在下文中将其称为SSR-VC。
为了进行公平比较,发明人在LibriTTS中的SEF-VC与AdaIN-VC、YourTTS和SSR-VC的相同数据分区上进行了训练和测试。
任意语音转换结果
发明人进行了客观和主观评估,以评价SEF-VC在任意语音到任意语音转换中的说话人相似度和语音可懂度。客观评估包括说话人嵌入余弦相似度(SECS)和ASR中的字符错误率(CER)。SECS指标通过使用Resemblyzer提取说话人嵌入并计算余弦相似度来计算。CER是根据[32],在ASR模型转录的合成语篇和真实语篇之间测量的。我们还通过平均意见分(MOS)测试进行了主观评价,以衡量说话人的相似度,要求评分者根据合成语音与引用语音的相似程度进行评分,评分标准为1-5分。此外,还进行了自然度MOS测试,以衡量合成语音的可懂度。SECS(说话人相似度)、CER(字符错误率)、相似度(Similarity)和自然度(Naturalness)MOS(平均选项得分)结果见表1。
结果表明,在任意语音转换中,我们的模型能更好地将语音转换为目标说话人的声音。AdaINVC受限于自动编码器的瓶颈,合成的语音质量较差。YourTTS和SSR-VC都严重依赖全局说话人嵌入,而全局说话人嵌入缺乏足够的目标说话人信息,导致转换性能不理想。全局说话人嵌入的这一缺点也将在前述内容中得到验证。相反,所提出的使用位置无关交叉注意的免说话人嵌入SEF-VC可以更好地捕捉和纳入说话人信息,从而获得更好的说话人相似性。
图3示出了SEF-VC和其他基线在任意语音到任意语音转换中的性能比较。SECS指说话人嵌入余弦相似度。SECS越高表示说话人相似度越高,而CER越低表示可懂度越高。
不同的引用长度
在本部分内容中,发明人考察了SEF-VC和SSR-VC中不同提示长度(包括2秒、3秒、5秒和10秒)的影响。结果见图4。在SSRVC中,提示音的作用是提取说话人的嵌入。结果表明,随着引用语音的长度变长,我们模型的性能也会提高,这得益于我们提出的位置无关交叉注意机制。直观地说,较长的提示音更容易建立说话人信息模型,从而更有助于将语音转换为目标说话人。即使在引用语音长度短至2秒的情况下,SEF-VC的SECS与SSR-VC相比仍然是可以接受的,这表明交叉注意机制比说话人嵌入更稳健。从3秒的引用语音长度开始,SEF-VC已经能在很大程度上捕捉到目标说话人的音色。
交叉注意与说话人嵌入对比
在这一部分,发明人将展示我们提出的交叉注意机制的有效性。为了进行比较,发明人去掉了SEF-VC中的交叉注意模块,并按照YourTTS的方法将说话人嵌入直接添加到HifiGAN判别器中。X-vector被视为Kaldi提取的说话人嵌入。结果如图3所示。由此可见,所采用的交叉注意力机制大大提高了说话人相似度,这意味着它比简单的说话人嵌入添加机制能更好地学习目标说话人信息并将其纳入潜在内容表示。其中一个可能的原因是,全局说话人嵌入无法提供足够的说话人相关信息,如时变音高,而时变音高对说话人相似性也有贡献。
图4示出了不同长度的引用语音对零样本VC影响的实验。
图5示出了不同说话人建模效果的实验。
本申请实施例提出的SEF-VC是一种免说话人嵌入的语音转换模型,它通过位置无关的交叉注意机制从引用语音中学习并纳入说话人的音色,然后以非自回归的方式从HuBERT语义特征重建波形。SEF-VC的简洁设计增强了其训练稳定性和语音转换性能。主观和客观评估结果表明,我们的模型可以生成与目标说话人相似的自然语音。消融研究进一步证明了位置无关交叉注意机制的有效性,该机制允许在短至2秒的引用语音中进行语音转换。
在另一些实施例中,本发明实施例还提供了一种非易失性计算机存储介质,计算机存储介质存储有计算机可执行指令,该计算机可执行指令可执行上述任意方法实施例中的语音转换方法及语音转换模型的训练方法;
作为一种实施方式,本发明的非易失性计算机存储介质存储有计算机可执行指令,计算机可执行指令设置为:
使用预训练模型从源语音中提取语义特征;
从引用语音中提取梅尔频谱特征,并使用一层卷积神经网络对所述梅尔频谱特征进行编码得到引用特征;
将所述语义特征经过两个语义编码器,其中,两个语义编码器之间还包括辅助特征适配器,所述辅助特征适配器用于根据第一个语义编码器的输出进行PPE的预测;
利用判别器对第二个语义编码器的输出进行上采样得到最终语音;
其中,每个语义编码器均包括两个构词块,每个构词块包括自注意力模块、交叉注意力模块、卷积层和投影层,所述交叉注意力模块用于引入所述引用特征。
非易失性计算机可读存储介质可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据语音转换方法及语音转换模型的训练的装置的使用所创建的数据等。此外,非易失性计算机可读存储介质可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,非易失性计算机可读存储介质可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至语音转换方法及语音转换模型的训练的装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
本发明实施例还提供一种计算机程序产品,计算机程序产品包括存储在非易失性计算机可读存储介质上的计算机程序,计算机程序包括程序指令,当程序指令被计算机执行时,使计算机执行上述任一项语音转换方法及语音转换模型的训练方法。
图6是本发明实施例提供的电子设备的结构示意图,如图6所示,该设备包括:一个或多个处理器610以及存储器620,图6中以一个处理器610为例。语音转换方法及语音转换模型的训练方法的设备还可以包括:输入装置630和输出装置640。处理器610、存储器620、输入装置630和输出装置640可以通过总线或者其他方式连接,图6中以通过总线连接为例。存储器620为上述的非易失性计算机可读存储介质。处理器610通过运行存储在存储器620中的非易失性软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例语音转换方法及语音转换模型的训练方法。输入装置630可接收输入的数字或字符信息,以及产生与语音转换方法及语音转换模型的训练的装置的用户设置以及功能控制有关的键信号输入。输出装置640可包括显示屏等显示设备。
上述产品可执行本发明实施例所提供的方法,具备执行方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明实施例所提供的方法。
作为一种实施方式,上述电子设备应用于语音转换方法及语音转换模型的训练的装置中,包括:至少一个处理器;以及,与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够:
使用预训练模型从源语音中提取语义特征;
从引用语音中提取梅尔频谱特征,并使用一层卷积神经网络对所述梅尔频谱特征进行编码得到引用特征;
将所述语义特征经过两个语义编码器,其中,两个语义编码器之间还包括辅助特征适配器,所述辅助特征适配器用于根据第一个语义编码器的输出进行PPE的预测;
利用判别器对第二个语义编码器的输出进行上采样得到最终语音;
其中,每个语义编码器均包括两个构词块,每个构词块包括自注意力模块、交叉注意力模块、卷积层和投影层,所述交叉注意力模块用于引入所述引用特征。
本申请实施例的电子设备以多种形式存在,包括但不限于:
(1)移动通信设备:这类设备的特点是具备移动通信功能,并且以提供话音、数据通信为主要目标。这类终端包括:智能手机(例如iPhone)、多媒体手机、功能性手机,以及低端手机等。
(2)超移动个人计算机设备:这类设备属于个人计算机的范畴,有计算和处理功能,一般也具备移动上网特性。这类终端包括:PDA、MID和UMPC设备等,例如iPad。
(3)便携式娱乐设备:这类设备可以显示和播放多媒体内容。该类设备包括:音频、视频播放器(例如iPod),掌上游戏机,电子书,以及智能玩具和便携式车载导航设备。
(4)服务器:提供计算服务的设备,服务器的构成包括处理器、硬盘、内存、系统总线等,服务器和通用的计算机架构类似,但是由于需要提供高可靠的服务,因此在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面要求较高。
(5)其他具有数据交互功能的电子装置。
以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分的方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 图像转换方法、装置、电子设备及存储介质
- 一种语音信息推送方法、装置、电子设备及存储介质
- 语音处理方法、装置、存储介质及电子设备
- 一种语音交互方法、装置、电子设备及可读存储介质
- 一种语音交互的方法、电子设备及计算机存储介质
- 语音转换模型训练、语音转换方法、装置、电子设备及存储介质
- 语音转换模型训练方法、语音转换方法、装置及介质