一种异源数据联合查询的处理系统及方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及数据库管理和数据查询领域,尤其涉及一种异源数据联合查询的处理系统及方法。
背景技术
在现代企业和组织中,使用多个不同的数据库引擎和集群来管理和存储数据已成为常态。然而,直接在异源数据上进行联合查询存在一些挑战,需要解决以下现有技术的缺点:
数据复制和数据集成:当前的方法通常涉及将异源数据复制到一个中央数据仓库或数据湖中,然后在该中央存储中执行联合查询,需要大量的数据复制和同步操作,占用存储空间和网络带宽,并且对数据的实时性有一定的限制。
ETL抽取、转换、加载流程:许多组织使用ETL工具来将异源数据抽取到一个统一的格式中,以便进行联合查询,然而,ETL流程复杂且耗时,需要定义和维护数据转换规则和作业流程。此外,ETL流程是批量处理的,无法满足实时查询的需求。
数据库链接和跨引擎查询:某些数据库引擎提供了链接到其他引擎的功能,使得在一个查询中访问多个引擎成为可能,然而,链接通常有限制,仅适用于特定的引擎或有限的数据操作,无法满足复杂的联合查询需求。此外不同引擎之间的查询语法和功能也存在差异,导致查询语句的编写和调试复杂。
数据模型差异:异源数据通常具有不同的数据结构、数据模型和查询语法。例如,关系型数据库和NoSQL数据库之间存在结构化和非结构化数据的差异,导致难以直接进行联合查询。当前的方法通常需要进行数据模型转换和映射,增加了额外的开发和维护成本。
查询性能和优化:异源数据联合查询往往涉及多个数据源和复杂的查询计划,查询性能可能受到数据传输、网络延迟和数据处理的影响,在现有技术中,查询优化常常是针对单个数据源进行的,无法充分利用不同数据源的优势,并且缺乏全局的优化策略。
因此,现有技术在处理基于异源数据联合查询的挑战时存在一些缺点,包括数据复制和集成的复杂性、ETL流程的限制、数据库链接的局限性、数据模型差异的处理以及查询性能的优化等方面。
综上所述,尽管现有的联合查询技术和工具提供了有力的支持,但仍缺少一个帮助用户在异构数据库环境中更高效地进行数据查询和集成,提高数据处理的灵活性和性能的系统。
发明内容
本发明的目的在于,针对解决数据源连接和访问、数据模型和语法差异、查询优化和性能、数据传输和集成、安全和权限控制,以及异常处理和容错机制的技术问题,提出一种异源数据联合查询的处理系统及方法。
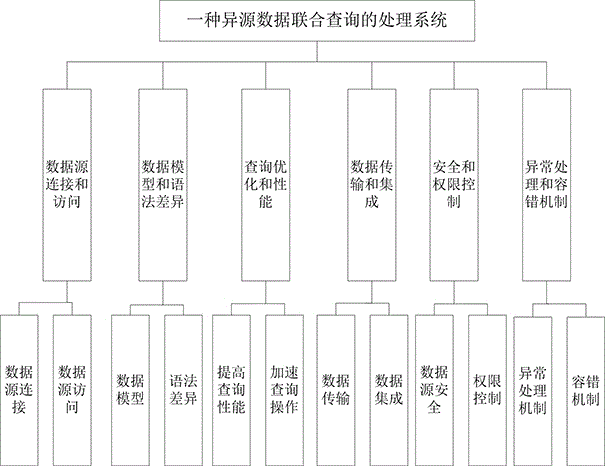
一种异源数据联合查询的处理系统,包括数据源连接和访问模块、数据模型和语法差异模块、查询优化和性能模块、数据传输和集成模块、安全和权限控制模块、异常处理和容错机制模块:
所述数据源连接和访问模块功能为使用数据库连接程序,并为数据库配置参数;
所述数据数据模型和语法差异模块不同数据库引擎和集群使用不同的数据模型和查询语法;
所述查询优化和性能模块功能为使用查询解析和优化技术,分析查询语句并生成查询计划;
所述数据传输和集成模块功能为在不同的数据源之间进行数据传输、合并和集成;
所述安全和权限控制模块功能为在进行跨数据源查询时,确保数据的安全,完善应用各个数据源的权限控制机制;
所述异常处理和容错机制模块功能为实现异常处理和容错机制,确保查询和结果的正确执行。
进一步的,一种异源数据联合查询的处理系统,所述数据源连接和访问模块包括数据源连接子模块、数据源访问子模块;
所述数据源连接子模块功能为使用数据库连接驱动程序或API,支持不同数据库引擎和集群的连接;
所述数据源访问子模块功能为针对每个数据源配置连接参数和权限验证信息,实现安全访问数据。
进一步的,一种异源数据联合查询的处理系统,所述数据模型和语法差异模块包括数据模型子模块、语法差异子模块;
所述数据模型子模块功能为建立统一的数据模型,将不同数据源的数据映射为统一模型,消除数据模型差异;
所述语法差异子模块功能为开发跨数据源的查询语法转换器,将查询语句从一种语法转换为另一种语法,实现不同数据库引擎的要求。
进一步的,一种异源数据联合查询的处理系统,所述查询优化和性能模块包括提高查询性能子模块、加速查询操作子模块;
所述提高查询性能子模块功能为利用每个数据源的特性和索引信息,选择最佳的数据源和查询计划;
所述加速查询操作子模块功能为将查询任务分发到各个数据源并并行执行。
进一步的,一种异源数据联合查询的处理系统,所述数据传输和集成模块包括数据传输子模块、数据集成子模块;
所述数据传输子模块功能为根据查询需求和数据量大小,采用数据传输方式;
所述数据传输方式包括批量传输、流式传输;
所述数据集成子模块功能为使用分布式计算框架或数据处理引擎处理大规模数据集成。
进一步的,一种异源数据联合查询的处理系统,所述安全和权限控制模块包括数据源安全子模块、权限控制子模块;
所述数据源安全子模块功能为对跨数据源的查询进行权限验证和身份验证,确保数据的安全和来源合规;
所述权限控制子模块功能为在查询处理中,遵循各个数据源的安全和权限控制机制,确保用户只能访问有权限的数据。
进一步的,一种异源数据联合查询的处理系统,所述异常处理和容错机制模块包括异常处理机制子模块、容错机制子模块;
所述异常处理机制子模块功能为捕获和处理连接失败、数据不一致的异常情况;
所述容错机制子模块功能为包括重试连接、数据恢复或回滚操作。
一种异源数据联合查询的处理方法,步骤为:
S1:确定联合查询的需求,将多个数据库中的数据合并为一个结果集;
S2:将多个数据库的URL和参数信息存储在一个配置文件中,进行执行联合查询的参数传递;
S3:选取其中一个数据库中执行SQL查询,提取需要的结果集;
S4:将结果集数据导出为Markdown文件,使用在线Markdown解析器解析;
S5:选取另一个数据库中执行相同的SQL查询,读取所需的数据;
S6:将读取的数据与导出的结果集进行合并,更新Markdown文件中的数据;
S7:更新后的Markdown文件上传到服务器,用户通过本地阅读Markdown文件。
本发明的有益效果:通过一种异源数据联合查询的处理系统及方法,通过数据整合、提升查询灵活性、资源优化、统一查询接口、实时查询和分析,以及扩展性和兼容性等方面的优势,提高了数据处理的效率和准确性,为用户提供了更好的数据查询和分析体验。
附图说明
图1是本发明的系统结构图。
图2是本发明的系统业务架构层。
图3是本发明的方法流程图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图说明本发明的具体实施方式。
如附图1所示,一种异源数据联合查询的处理系统,包括数据源连接和访问模块、数据模型和语法差异模块、查询优化和性能模块、数据传输和集成模块、安全和权限控制模块、异常处理和容错机制模块:
所述数据源连接和访问模块功能为使用数据库连接程序,并为数据库配置参数;
所述数据数据模型和语法差异模块不同数据库引擎和集群使用不同的数据模型和查询语法;
所述查询优化和性能模块功能为使用查询解析和优化技术,分析查询语句并生成查询计划;
所述数据传输和集成模块功能为在不同的数据源之间进行数据传输、合并和集成;
所述安全和权限控制模块功能为在进行跨数据源查询时,确保数据的安全,完善应用各个数据源的权限控制机制;
所述异常处理和容错机制模块功能为实现异常处理和容错机制,确保查询和结果的正确执行。
因异源数据通常存储在不同的数据库引擎和集群中,具有不同的连接和访问方式,技术问题是如何建立与异源数据源的连接,并能够有效地获取数据并执行查询操作,因此数据源连接和访问模块包括数据源连接子模块、数据源访问子模块;
所述数据源连接子模块功能为使用数据库连接驱动程序或API,支持不同数据库引擎和集群的连接;
所述数据源访问子模块功能为针对每个数据源配置连接参数和权限验证信息,实现安全访问数据。
因不同数据库引擎和集群具有不同的数据模型和查询语法,技术问题是如何处理和统一不同数据源之间的数据模型和查询语法差异,使得它们可以进行联合查询,数据模型和语法差异模块包括数据模型子模块、语法差异子模块;
所述数据模型子模块功能为建立统一的数据模型,将不同数据源的数据映射为统一模型,消除数据模型差异;
所述语法差异子模块功能为开发跨数据源的查询语法转换器,将查询语句从一种语法转换为另一种语法,实现不同数据库引擎的要求。
因异源数据联合查询可能涉及多个数据源和复杂的查询操作,技术问题是如何进行查询优化,选择合适的查询计划,并利用各个数据源的优势,以提高查询性能和执行效率,查询优化和性能模块包括提高查询性能子模块、加速查询操作子模块;
所述提高查询性能子模块功能为利用每个数据源的特性和索引信息,选择最佳的数据源和查询计划;
所述加速查询操作子模块功能为将查询任务分发到各个数据源并并行执行。
因异源数据联合查询可能需要在不同的数据源之间进行数据传输、合并和集成,技术问题是如何有效地处理数据传输和集成操作,减少网络延迟和数据处理的开销,数据传输和集成模块包括数据传输子模块、数据集成子模块;
所述数据传输子模块功能为根据查询需求和数据量大小,采用数据传输方式;
所述数据传输方式包括批量传输、流式传输;
所述数据集成子模块功能为使用分布式计算框架或数据处理引擎处理大规模数据集成。
因异源数据联合查询可能涉及多个数据源的安全和权限控制,技术问题是如何在进行跨数据源查询时,确保数据的安全性和合规性,并且能够正确地应用各个数据源的权限控制机制,安全和权限控制模块包括数据源安全子模块、权限控制子模块;
所述数据源安全子模块功能为对跨数据源的查询进行权限验证和身份验证,确保数据的安全和来源合规;
所述权限控制子模块功能为在查询处理中,遵循各个数据源的安全和权限控制机制,确保用户只能访问有权限的数据。
因异源数据的复杂性,查询过程中可能会出现各种异常情况,例如连接失败、数据不一致等,技术问题是如何设计和实现异常处理和容错机制,以确保查询的正确执行和结果的准确性,异常处理和容错机制模块包括异常处理机制子模块、容错机制子模块;
所述异常处理机制子模块功能为捕获和处理连接失败、数据不一致的异常情况;
所述容错机制子模块功能为包括重试连接、数据恢复或回滚操作。
如附图2所示,异源数据库查询处理层负责发送查询请求,接收查询请求后,从多个集群中获取数据,并将查询结果合并为最终结果;
查询结果存储层负责将查询结果存储到不同的数据存储中,并使用缓存技术确保查询结果的一致性和可用性;
查询结果查询引擎层负责通过中间件接收查询结果,根据查询结果进行业务逻辑处理,最终输出结果;
最终输出结果层负责使用Markdown解析引擎将结果输出。
如附图3所示, 一种异源数据联合查询的处理方法,步骤为:
S1:确定联合查询的需求,将多个数据库中的数据合并为一个结果集;
S2:将多个数据库的URL和参数信息存储在一个配置文件中,进行执行联合查询的参数传递;
S3:选取其中一个数据库中执行SQL查询,提取需要的结果集;
S4:将结果集数据导出为Markdown文件,使用在线Markdown解析器解析;
S5:选取另一个数据库中执行相同的SQL查询,读取所需的数据;
S6:将读取的数据与导出的结果集进行合并,更新Markdown文件中的数据;
S7:更新后的Markdown文件上传到服务器,用户通过本地阅读Markdown文件。
具体的核心代码为:
public Pair
JdbcBase jdbcBase = dto.getJdbcBase();
JdbcConfig jdbcConfig = jdbcBase.getJdbcConfig();
String sqlContent = dto.getSql();
String key = dto.getKey();
String type = dto.getType();
Integer count = dto.getMaxCount();
FunctionTypeEnum functionType = dto.getFunctionType();
Pair
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;boolean hasResultSet = false;
try {
String[] subSqlArr = sqlContent.split(";");
log.info("JdbcBaseBiz.execute.subSqlArr:{},",
JsonUtils.toJson(subSqlArr));
sqlRunRedisManger.addLog(key, "开始连接数据库……",
SqlLogLevelEnum.WARNING.getCode(), false);
//获取数据源
connection = getConnection(jdbcBase, type);
sqlRunRedisManger.addLog(key, "获取到数据库连接……",
SqlLogLevelEnum.WARNING.getCode(), false);
statement = connection.createStatement();
if (StringUtils.isNotEmpty(jdbcConfig.getSchema())) {
//设置oracle schema
statement.execute(SQL_SENTENCE_JOIN + jdbcConfig.getSchema());
}
statement.setMaxRows(count);
if (statement instanceof HiveStatement) {
sqlStatementMonitor.monitoringStatement(statement, key);
}
for (String sql : subSqlArr) {
if (StringUtils.isNotEmpty(sql.trim())) {
sql = SqlCheckUtil.deleteNote(sql);
if (StringUtils.isEmpty(sql.trim())) {
continue;
}
sqlRunRedisManger.addLog(key, "开始执行sql:" + sql,
SqlLogLevelEnum.INFO.getCode(), false);
hasResultSet =
statement.execute(StringUtils.trimWhitespace(sql));
}
}
if (hasResultSet&&Objects.nonNull(resultSetHandler)) {
resultSet = statement.getResultSet();
//处理结果
columnAndResultPair =
resultSetHandler.handleResultSet(functionType, resultSet, key);
} else {
int updateCount = statement.getUpdateCount();
log.error("JdbcBaseBiz.execute.updateCount 影响行数:{},",
updateCount);
}
} catch (Exception e) {
log.error("JdbcBaseBiz.execute.e", e);
sqlRunRedisManger.addLog(key, "执行出错:" + e.getMessage(),
SqlLogLevelEnum.ERROR.getCode(), true);
buildUpDateHistoryQuery(key,
SqlQueryStatusEnum.EXCEPTION.getCode());
} finally {
sqlRunRedisManger.addLog(key, "执行结束...",
SqlLogLevelEnum.WARNING.getCode(), true, null,System.currentTimeMillis());
close(connection, statement, resultSet, jdbcBase);
}
return columnAndResultPair;
}。
本方案通过一种异源数据联合查询的处理系统及方法,优点为:
(1)数据整合和一致性:通过联合查询不同数据源的数据,实现数据的整合和一致性。组织可以从多个数据源中获取所需的信息,无需复制数据或进行繁琐的数据转换操作,从而减少数据冗余和不一致性的问题;
(2)提升查询灵活性:异源数据联合查询方法允许用户在不同数据库引擎和集群中执行查询操作,提供了更大的灵活性和自由度,用户跨越不同数据源,获得更全面的数据视图,并进行更复杂的查询和分析;
(3)资源优化和性能提升:通过查询优化和并行查询执行技术,异源数据联合查询方法可以最大限度地利用各个数据源的优势,提高查询性能和执行效率,同时避免了数据复制和集成过程的开销,节约了存储空间和网络带宽;
(4)统一的查询接口和语法:异源数据联合查询方法提供了一个统一的查询接口和语法,使用户无需学习和适应多个数据库引擎和查询语法,用户使用熟悉的查询语句,通过一个统一的接口访问和查询异构数据源,简化了开发和查询的复杂性;
(5)实时数据查询和分析:异源数据联合查询方法支持实时查询和分析,不需要进行批量的数据抽取和转换,用户即时获取最新的数据,并进行实时的数据分析和决策,提高了业务响应的速度和准确性;
(6)扩展性和兼容性:异源数据联合查询方法具有良好的扩展性和兼容性,与不同的数据库引擎和集群进行集成,无论是关系型数据库、NoSQL数据库还是其他类型的数据存储系统,都可以通过适当的接口和适配器进行集成。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 一种安全防护设备联动防御策略智能决策方法及系统
- 一种用于安防系统的报警联动方法
- 一种应急单兵系统及其联动方法
- 一种应急救灾单兵联动系统