一种由油品近红外光谱预测其物性的方法及装置
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及化工领域,具体地涉及一种由油品近红外光谱预测其物性的方法及装置。
背景技术
柴油馏分馏程约150~350℃,族组成主要分为链烷烃、环烷烃、芳烃三大类组分,关于柴油烃族组成,特别是其中芳烃组成的测定目前主要的分析方法有质谱法和超临界流体色谱法。近红外光谱(NIR)分析技术是目前最有前景且应用最广泛的快速分析方法之一,在线近红外技术也是发展最迅速的过程分析技术之一。NIR主要反映含氢基团X-H(X=C、N、O)合频和倍频的振动,具有丰富的组成和结构信息,非常适合于分析含大量有机化合物的石油及产品;且由于仪器构造简单,性能稳定,无预处理,分析速度快而被大量用于过程分析。依托标准方法建立数据库,NIR可将分析时间缩短至几分钟,在提高分析效率的同时还能减低测试费用。
CN102374975A提出了一种新的油品性质预测方法—库光谱拟合方法(LibrarySpectra Fitting Method),这种方法基于油品的近红外光谱库和光谱拟合技术,其基本原理是:光谱相似的样品的性质也相似,通过光谱库中的一个或多个光谱对未知待测样品的光谱进行拟合,然后根据参与拟合光谱的柴油的性质计算出待测样品的性质。上述库光谱拟合方法的化学实质在于未知样品可由一组库样品按一定比例混合而成,因此,未知样品的待测性质可通过库样品的性质按照混合比例计算得出。对于线性加和的性质如组分含量可通过简单的线性组合计算,对于非线性的性质如凝点和粘度等则需要用到调合规则。
上述方法存在的一个显著问题是光谱拟合采用的是光谱吸光度的绝对值,计算耗时较长,且预测结果的准确性也有待提高。
发明内容
本发明实施例的目的是提供一种由油品近红外光谱预测其物性的方法及装置,其通过测定待测油品的近红外光谱,利用差谱分析,可快速、准确地预测待测油品的性质。
为了实现上述目的,本发明实施例提供一种由油品近红外光谱预测其物性的方法,该方法包括:测定待测样品的近红外光谱并进行二阶微分处理,选取特征谱区的吸光度构成光谱矢量;针对待测物性,通过PLS算法求解X=T×P得到所述光谱矢量的得分向量;将所述光谱矢量与所述得分向量进行拼接,以得到待测样品的光谱-得分组合向量k;计算所述待测样品与油品近红外光谱-得分数据库内的每一样品的欧式距离,并选取欧氏距离最小的光谱-得分组合向量,作为与所述待测样品最相近的库样本的光谱-得分组合向量p,该最相近的库样本的物性为h;计算待测样品的光谱-得分组合向量k与所述光谱-得分组合向量p的差谱△k;计算所述数据库中每个库样品的光谱-得分组合向量与所述光谱-得分组合向量p的差谱△v
其中所述油品近红外光谱-得分数据库通过以下操作而被获得:收集一组具有代表性的油品样品,测定每个样品的近红外光谱,并测定每个样品所需要预测的物性,形成矩阵Y;对每个样品的近红外光谱进行二阶微分,将样品的吸光度与其测定的物性对应,选取特征谱区建立近红外光谱数据库;以及利用PLS方法对所述近红外光谱数据库内的光谱矩阵X分别对应Y矩阵的每个物性进行分解,得到得分矩阵T,并按样品顺序将光谱矩阵X与得分矩阵T进行拼接,得到光谱-得分组合矩阵K。
其中,所述欧氏距离通过以下公式而被计算:
式①中,d
其中,利用所述差谱△v
按式⑤表示待测样品的差谱△k,求得参与拟合的库样品的拟合系数:
式中,a
拟合系数a
将上述求得的拟合系数a
式⑥中,g为非零拟合系数所对应的库样本的光谱-得分组合向量的个数。
其中,该方法还包括:
按式⑦计算待测样品的拟合差谱:
按式⑧计算待测样品差谱的拟合度s:
式⑧中,△k
对所述待测样品的所述待测物性进行预测在所述拟合度大于设定的阈值的情况下被执行。
其中,对所述待测样品的所述待测物性进行预测包括:
按式⑩由参与拟合的库样品对应的物性,计算待测样品的物性,
式⑩中,
其中,所述阈值的确定方法为:选取一个样品重复测定三次近红外光谱,对每次测定的光谱进行二阶微分处理后取其吸光度,然后计算每次测定的光谱与平均光谱的差谱,按式⑨计算任意两次测定的差谱之间的伪拟合度(sr)值,取最大的sr值,乘以系数0.75即为阈值,
式⑨中,△x′
其中,所述油品包括柴油、汽油、润滑油、以及渣油。
其中,所述特征谱区为6600~8900cm
其中,测定近红外光谱的光谱范围为10000~4000cm
其中,所述的油品为汽油时,预测的物性为汽油密度、辛烷值、芳烃、烯烃、苯和氧含量中的一种或多种;所述油品为柴油时,预测的物性为柴油十六烷值、密度、冷滤点和多环芳烃含量中的一种或多种;所述油品为原油时,预测的物性为原油密度、残炭、硫、蜡、胶质、沥青质含量和实沸点蒸馏收率中的一种或多种。
另一方面,本发明提供一种由油品近红外光谱预测其物性的装置,该装置包括:存储器;以及处理器,该处理器被配置为利用上述由油品近红外光谱预测其物性的方法。
另一方面,本发明提供一种机器可读存储介质,该机器可读存储介质上存储有指令,其特征在于,该指令在被处理器执行时使得所述处理器被配置成执行上述由油品近红外光谱预测其物性的方法。
主成分分析(PCA)算法是化学计量学领域里的一个经典算法,基本模型是X=T×P,将光谱矩阵X分解为T矩阵(术语:得分矩阵)和P矩阵(术语:载荷矩阵)的乘积。一般来说,主成分分析(PCA)只对X矩阵(光谱矩阵)进行分解,分解为T矩阵(得分矩阵)与P矩阵(载荷矩阵)的乘积,得分矩阵的特点是前几个变量基本涵盖了原矩阵的大部分信息,则所需计算的数据量被大大压缩,因此本案中采用得分替代原光谱矩阵进行计算。但这里的得分与样品的物性、组成(y矩阵)并不能保证有最大的相关性,因此本案采用PLS方法提取主成分,因为PLS分解X矩阵的过程中要考虑与样品的物性、组成保持最大的相关性。那么得到的得分变量就与样品的物性、组成有较大相关性。那么得到的得分变量就与样品的物性、组成有较大相关性,最后得到的拟合结果即对未知样品物性、组成的预测也会更准确。
本发明方法通过已知油品与待测样品光谱-得分组合向量的差谱及物性之间的差,对待测油品的差谱进行拟合,由参与拟合的已知油品的物性预测待测样品,更加突出了油品光谱与物性之间的关系,具有更为准确的预测结果。另外,主成分分析的特点就是可以对数据进行极大的压缩,因此本案还提高了预测速度。
本发明实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本发明实施例的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明实施例,但并不构成对本发明实施例的限制。在附图中:
图1为本发明提供的由油品近红外光谱预测其物性的方法的流程图。
具体实施方式
以下结合附图对本发明实施例的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施例,并不用于限制本发明实施例。
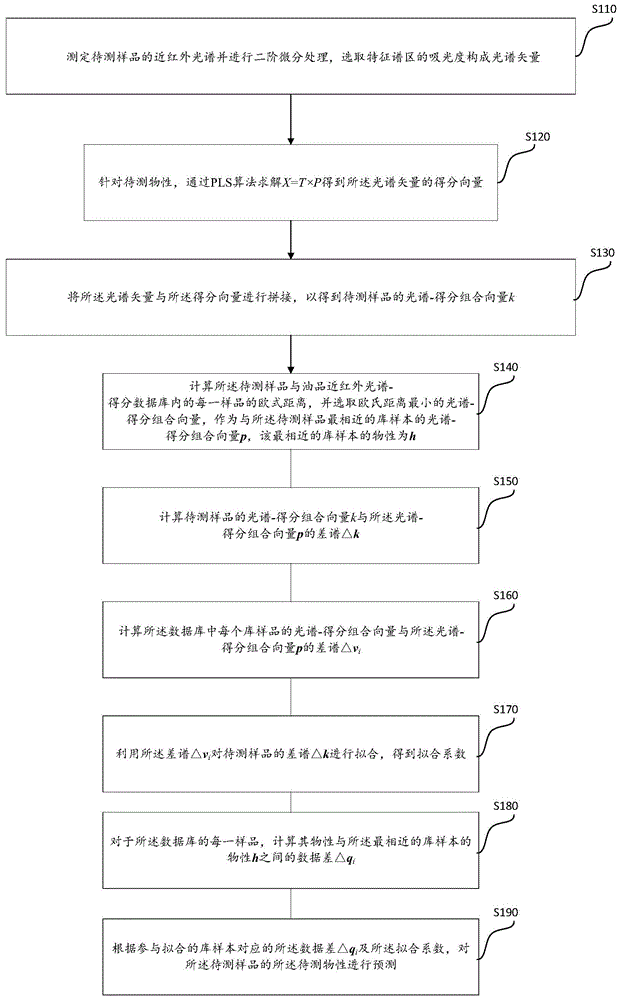
图1是本发明提供的由油品近红外光谱预测其物性的方法的流程图。如图1所示,本发明实施例提供一种由油品近红外光谱预测其物性的方法,包括如下步骤:
S110:测定待测样品的近红外光谱并进行二阶微分处理,选取特征谱区的吸光度构成光谱矢量;
S120:针对待测物性,通过PLS算法求解X=T×P得到所述光谱矢量的得分向量;
这里使用PLS方法计算X=T×P,将光谱矩阵X分解为T矩阵(术语:得分矩阵)和P矩阵(术语:载荷矩阵),分解过程考虑Y是为了保证与Y(物性或组成)有较大相关,这里的P矩阵可以理解为新坐标轴,将待测样品的光谱矢量x直接向得到新坐标轴(P)投影即得到该待测样品的得分向量。
S130:将所述光谱矢量与所述得分向量进行拼接,以得到待测样品的光谱-得分组合向量k;
S140:计算所述待测样品与油品近红外光谱-得分数据库内的每一样品的欧式距离,并选取欧氏距离最小的光谱-得分组合向量,作为与所述待测样品最相近的库样本的光谱-得分组合向量p,该最相近的库样本的物性为h;
S150:计算待测样品的光谱-得分组合向量k与所述光谱-得分组合向量p的差谱△k;
S160:计算所述数据库中每个库样品的光谱-得分组合向量与所述光谱-得分组合向量p的差谱△v
S170:利用所述差谱△v
S180:对于所述数据库的每一样品,计算其物性与所述最相近的库样本的物性h之间的数据差△q
S190:根据参与拟合的库样本对应的所述数据差△q
其中所述油品近红外光谱-得分数据库通过以下操作而被获得:
收集一组具有代表性的油品样品,测定每个样品的近红外光谱,并测定每个样品所需要预测的物性,形成矩阵Y;
对每个样品的近红外光谱进行二阶微分,将样品的吸光度与其测定的物性对应,选取特征谱区建立近红外光谱数据库;以及
利用PLS方法对所述近红外光谱数据库内的光谱矩阵X分别对应Y矩阵的每个物性进行分解,得到得分矩阵T,并按样品顺序将光谱矩阵X与得分矩阵T进行拼接,得到光谱-得分组合矩阵K。
需要说明的是,上述油品近红外光谱-得分数据库可在上述方法被执行之前预先被建立。
下面结合具体的实施情况来对本发明的技术方案进行描述,当然,本发明并不限于这些描述,本领域技术人员在阅读本案申请文件之后可预见的其他实施形式也是可行的。另外,在本申请文件中,“物性”、“性质”、“性质数据”与“组成”可互换使用,“样本”与“样品”可互换使用。
本发明方法利用不同油品光谱之间差异(称为差谱)包含的信息,体现油品之间的性质或组成差异,油品近红外光谱经偏最小二乘(PLS)计算后的得分信息,由已知油品光谱的光谱-得分向量的差谱对待测油品的光谱-得分向量的差谱进行拟合运算,体现了油品光谱与物性之间的关系,也更加突出了油品光谱之间差异,具有更为准确的预测结果。
本发明方法首先利用模式识别方法从已知油品光谱库中选出与待测油品最相似的1个库光谱-得分组合向量,分别将油品库中所有的光谱-得分组合向量都减去这个库光谱-得分组合向量,得到库光谱-得分组合向量差谱,再将待测油品的光谱-得分组合向量减去这个库光谱-得分组合向量,得到待测油品光谱-得分组合向量的差谱,然后用这些差谱对待测油品光谱-得分组合向量的差谱进行拟合运算,由参与拟合的样品的性质预测待测油品的性质。
本发明方法包括以下步骤:
(1)收集一组具有代表性的油品样品,样品数量至少为400个,测定每个样品的近红外光谱,再用标准方法测定每个样品油品需要预测的性质数据,如详细烃组成、十六烷值、密度、冷滤点和烃族组成等,形成矩阵Y,
(2)对每个样品的近红外光谱进行二阶微分,将样品的吸光度与其测定的性质数据对应,选取6600~8900cm
(3)测定待测样品的近红外光谱,并进行二阶微分,取其6600~8900cm
(4)利用PLS方法对油品近红外库光谱矩阵分别对应Y矩阵每个组成或物性进行分解,分别获取前30-100个主成分对应的得分向量,将得分矩阵T按样本顺序将X与T矩阵进行拼接,得到光谱-得分组合矩阵K,矩阵K的个数与组成或物性个数相同;以及同样方法得到待测样本的光谱-得分组合向量k,
(5)按式①计算待测样品与所选近红外光谱-得分数据库中每个样品的欧式距离,选出欧式距离最小的1个库样本p,为与待测样品最相近的库样品,其对应的性质数据为h,
式①中,d
(6)按式②将待测样品光谱-得分组合向量k减去所选数据库中与其最相近样品的光谱-得分组合向量p,得到待测样品的差谱△k,
Δk=k-p ②
(7)对所选数据库中每个样品,按式③计算其与光谱-得分组合向量p的差谱△v
△v
式③中,n为所选近红外光谱-得分组合向量数据库的样品数,v
(8)对所选数据库中的每个样品,按式④计算其性质与最相近样品的性质h的数据差△q
△q
式④中,q
(9)按下述方法用所选库光谱-得分组合向量的差谱对待测样品的差谱△k进行拟合,
a)按式⑤表示待测样品的差谱△k,求得参与拟合的库样品的拟合系数:
式中,a
拟合系数a
非负约束最小二乘法的具体算法参见文献:C.L.Lawson and R.J.Hanson,Solving Least Squares Problems,Prentice-Hall,Englewood Cliffs,NJ(1974);160~165
b)将上述求得的拟合系数a
式⑥中,g为非零拟合系数的库光谱-得分组合向量个数,
c)按式⑦计算待测样品的拟合差谱:
d)按式⑧计算待测样品差谱的拟合度s:
式⑧中,△k
本发明方法中,拟合度s是判断库光谱-得分组合向量对待测样品拟合完全与否的指标,该值越大说明拟合度越高,由拟合样品计算得到的预测性质越准确。如果s小于设定的阈值,说明拟合不完全,即待测样品不能完全由库样品光谱-得分组合向量拟合表示,无法准确对其性质进行预测。
(10)若s大于设定的阈值,按式⑩由参与拟合的库样品对应的性质数据计算待测样品的性质,
式⑩中,
本发明所述拟合度阈值s
式⑨中,△x′
若拟合计算得到的s大于等于设定的阈值,则通过式⑩计算待测样品的性质数据。对于满足线性加合性的性质,可直接用式⑩预测其性质。
下面通过实例进一步详细说明本发明,但本发明并不限于此。
实例1
预测柴油烃族组成。
(1)建立柴油样品的近红外光谱数据库
收集有代表性的柴油样品450个,测定柴油样品的近红外光谱,选取6600~8900cm
用标准方法SH/T 0606测定每个样品的烃族组成。将处理后的近红外光谱与其对应的性质数据建立柴油近红外光谱数据库。
(2)将柴油近红外光谱矩阵X
(3)从柴油近红外光谱-得分组合向量数据库中选取与待测样品最相近的库样品
取待测样品A,按与(1)步相同的方法测定其近红外光谱,取6600~8900cm
(4)构建柴油近红外光谱-得分组合向量的差谱库和性质数据差库
按式③将近红外光谱-得分组合向量数据库中每个库样品的光谱-得分组合向量减去光谱-得分组合向量v,得到每个样品的差谱;再按式④将每个样品的性质数据减去性质数据q,得到每个样品的性质数据差。用所有样品的差谱与对应的性质数据差建立柴油近红外光谱-得分组合向量差谱库和性质数据差库。对柴油拟合数据库矩阵K
(5)对待测样品的光谱-得分组合向量差进行拟合
按式②,将待测样品A的光谱-得分组合向量x减去光谱-得分组合向量v,得到待测样品A的差谱△x。由建立的柴油近红外光谱-得分组合向量差谱库和性质数据差库,按照本发明(9)步a)的方法,按式⑤对差谱△x进行拟合,将计算出的不为零的拟合系数,可以用拟合系数计算待测样品的性质数据,对柴油拟合数据库矩阵K
表1
(6)对待测样品的性质进行预测分析
由对应每一个组成的归一化的拟合系数和参与拟合的库光谱-得分组合向量样品对应的性质数据,由式⑩计算待测样品的下列组成数据:链烷烃、环烷烃、烷基苯、茚满或四氢萘、萘、总单环芳烃、总双环芳烃、总三环芳烃。
表2
对比例1
使用传统偏最小二乘(PLS)方法预测柴油样品A的烃组成,结果见表2。
(1)建立柴油样品的近红外光谱数据库
收集有代表性的柴油样品450个,测定柴油样品的近红外光谱,选取6600~8900cm
对于柴油光谱矩阵X
(2)将矩阵X与矩阵Y用偏最小二乘法(PLS)分别建立烃组成(链烷烃、环烷烃、烷基苯、茚满或四氢萘、萘、总单环芳烃、总双环芳烃、总三环芳烃)校正模型,对未知柴油样本A进行预测,结果见表2。
结果表明本专利方法测试结果优于传统PLS方法。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。存储器是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 一种用于液压缸活塞的组合密封装置及液压缸
- 一种密封间隙可变的液压缸活塞密封装置及液压缸
- 一种基于液压缸恒力控制的地面强度检测装置及方法
- 一种利用小行程液压缸长距离提升重物的装置及方法
- 一种DHA藻油高内相双重乳液凝胶的制备装置及其制备方法
- 一种双重抗冲击的液压缸装置及方法
- 一种减振抗冲击液压缸及其抗冲击方法