改进的YOLOv7-tiny模型及基于该模型的人手脸检测方法及系统
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及目标检测技术领域,更具体的,涉及改进的YOLOv7-tiny模型及基于该模型的人手脸检测方法及系统。
背景技术
近年来人机交互技术发展飞速发展,人机交互从传统的鼠标、键盘和遥控器等传统人机交互接口方式转变为更加自然、高效的方式。其中视觉交互就是相对传统人机交互形式典型的新型交互形式,如动作识别和基于视觉的行为分析。在动作识别、行为分析等视觉人机交互任务中,2D人体关键点检测具有广泛的应用,是描述人体姿态,预测人体行为的基础。目前主流的2D人体关键点检测可划分为单人人体关键点检测和多人人体关键点检测两类,多人人体关键点检测又可分为自顶向下和自底向上两类。自顶向下人体关键点检测算法大体分为两个步骤,首先通过目标检测算法将图像中每个单独的人检测出来,其次基于每一个检测到的人体框进行关键点检测。
为了在捕捉人体姿势信息同时捕捉手势和表情的信息,需要细粒度的人体关键点检测,即在全身关键点检测中包含人脸关键点检测和手部关键点检测。在目标检测算法的层面,检测人体位置的同时检测人脸和手部的位置,相比于只检测人体位置,人脸和手部关键点检测更加准确。但检测人体位置的同时检测人脸和手部的位置也会算法的复杂度的提高。
目前公开的数据集,只针对单独的人体检测、人脸检测和手部检测,意味着想同时获得人体、人脸和手部的检测框,需要训练3个单独的目标检测算法,在实际落地的过程中,检测模型总的参数量变为原来的3倍。因此,本发明首先创建同时包含人体、人脸和手部的检测数据集。通过实验得知,人手脸检测数据集训练得到的模型参数量大致是人体检测、人脸检测和手部检测三个单独模型参数量总和的三分之一,且其每一个类的检测mAP值也与单个类检测模型的检测mAP值基本相当。
自顶向下全身关键点检测的准确性和效率很大程度依赖于人体目标检测算法的准确性和效率,在实际落地过程中,通常采用轻量化检测模型,保证检测算法满足实时部署推理的需求。
目前常用的基于卷积的目标检测算法有R-CNN、Faster R-CNN、SSD、YOLOv4、YOLOv5、YOLOv7等,分为一阶段目标检测算法和二阶段目标检测算法。
二阶段目标检测模型以R-CNN系列为代表。R-CNN系列包括:R-CNN,使用选择性搜索(Selective Search)算法来生成图像中可能包含目标的区域候选,并结合卷积神经网络(Convolutional Neural Networks,CNN)和支持向量机(Support Vector Machine,SVM)进行分类和目标定位、Fast R-CNN,使用感兴趣区域池化(Region Of Interest Pooling,ROIPooling)层来获取每个区域候选对应的特征向量,最后使用全连接层和Softmax层来分类和回归目标,提高了计算效率和检测速度、Faster R-CNN,其在Fast R-CNN基础上增加区域候选网络(Region Proposal Network,RPN),使用锚框(Anchor Box)来预测可能包含目标的区域,不再使用选择性搜索算法,进一步提升检测速度和精度。
以YOLO系列为代表的一阶段目标检测算法具有检测速度快的优点,在人机交互这类对实时性要求高的任务场景中更有优势。
YOLO是一种单阶段的目标检测算法,可以直接从图像中预测目标的类别和位置。YOLOv1是YOLO系列的开山之作,它使用GoogleNet作为主干网络,将输入图像划分为7×7的网格,每个网格预测2个边界框和一个类别概率。YOLOv2使用Darknet-19作为主干网络,引入锚框(Anchor Box),直接预测边界框的偏移量,使用passthrough层将高低层特征进行融合,使用多尺度训练提高模型的泛化能力。YOLOv3使用Darknet-53作为主干网络,引入残差结构提高特征提取能力,使用FPN[8]结构在不同尺度上进行预测,增加对小目标的检测能力。它还使用logistic回归代替softmax进行多标签分类。YOLOv4在原来的YOLO目标检测架构的基础上,使用CSPDarknet-53作为主干网络,引入SPP(Spatial Pyramid Pooling)和PANet(Path aggregation network)结构,得到CSPSSP块,增强特征提取和融合能力;使用Mish激活函数代替Leaky ReLU激活函数;使用Mosaic数据增强方法提高模型鲁棒性;使用CIoU loss代替IoU loss优化边界框回归。YOLOv5模型结构与YOLOv4有较大差异,使用Focus层代替passthrough层进行特征融合,并且用C3模块代替残差模块进行特征提取,利用PANet结构进行多尺度预测。YOLOv6基于YOLOv5进行改进,主要是在数据增强和损失函数方面进行了优化。它使用MixUp数据增强方法提高模型鲁棒性,并且用GIoU loss代替IoUloss优化边界框回归。YOLOv7使用EfficientNet作为骨干网络,提高特征提取效率,使用重参数化卷积,在确保模型性能前提下在推理阶段对网络加速。
YOLOv7算法基于YOLOv5算法改进,检测精度和检测速度都有明显的优势。
YOLOv7使用EfficientNet作为骨干网络,提高特征提取效率;骨干网络后连接改进的SPP模块,将并行的池化操作和卷积操作融合,增大感受野,使得算法适应不同分辨率的图像;拓展的高效聚合网络(Extended Efficient Layer Aggregation Networks,E-ELAN)用于加强网络的特征提取能力;MPConv模块在池化的同时上加入并行的卷积操作,通过池化和卷积两种方式的共用,减少下采样过程的信息损失;颈部网络(Neck)使用PANet结构进行多尺度特征融合;在预测头网络(Head)网络使用重参数化REPConv,在训练阶段和推理阶段采用不同的结构,推理阶段将多个计算单元合并减少模型结构的复杂度,提高效率的同时保证模型的检测精度,减少了计算量和内存消耗。但由于YOLOv7网络结构复杂,参数量大,在低算力的终端设备上部署仍存在问题。
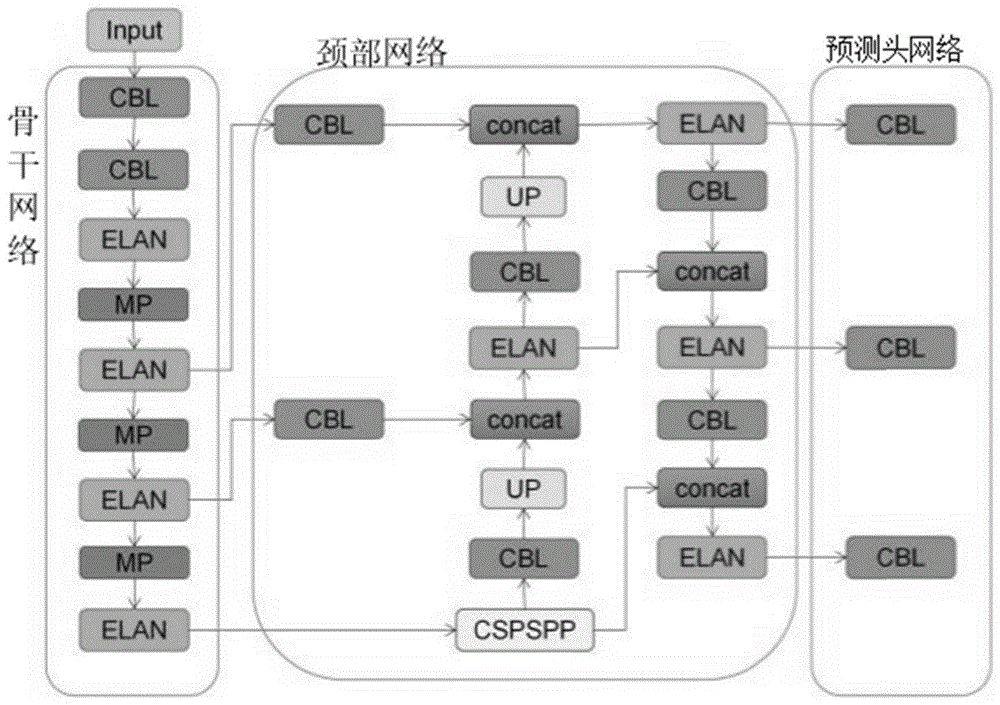
YOLOv7-tiny是YOLOv7模型的简化版本,用于边缘设备的部署,虽然检测精度有一定牺牲,但网络复杂度和参数量相较于YOLOv7都有一定降低,在模型推理速度上更有优势。YOLOv7-tiny同样由骨干网络(Backbone)、颈部网络(Neck)和预测头网络(Head)组成,其网络结构如图1、图2、图3、图4所示。骨干网络部分,YOLOv7-tiny采用更简洁的ELAN代替YOLOv7中的E-ELAN;仅保留MPConv中池化操作进行下采样,取代原本池化操作和卷积操作并行的下采样;颈部网络仍采用PANet结构进行特征聚合;预测头网络网络,采用标准卷积结构代替REPConv,调整输出通道数。
YOLOv7-tiny相较于YOLOv7在轻量化部署和推理速度上具有优势。然而,YOLOv7-tiny仍存在以下不足:
首先,在下采样的过程中,YOLOv7-tiny相对于YOLOv7减少了并行的卷积层,只保留了最大池化层。在下采样中,不同于可学习的卷积操作,池化过程并不是特征提取操作,虽然减少了计算量,但增加了信息丢失。人手脸检测中,如人手、人脸这类尺寸较小的目标,在下采样过程中易丢失主要信息,再加上背景复杂多变以及干扰目标多等问题,产生小目标错检、漏检的情况。
其次,YOLOv7-tiny中默认使用CIoU损失函数,强调宽和高的相对比例,而不是宽和高的值,当预测框的宽和高满足一定的比例时,CIoU中的相对比例惩罚项就不再起作用,影响回归的精度;其次,CIoU忽略了边界框回归中的不平衡问题,大量与目标框重叠度小的锚框占据了回归优化的主导地位,低质量的锚框会造成损失值的剧烈波动,影响YOLOv7-tiny模型的稳定性。
现有技术有一种改进YOLOv4tiny网络的目标检测算法,属于计算机视觉目标检测技术领域,包括以下步骤:骨干结构中卷积模块的激活函数修改为RReLU激活函数;特征融合部分有效特征层传递特征信息阶段改进为双分支结构,残差分支引入膨胀卷积提取浅层特征,与另一分支提取的特征进行特征融合,融合后特征信息与空残差边保留的原特征信息进行特征整合;在特征融合部分中改进的双分支结构的输入阶段和下层有效特征层上采样阶段添加CA注意力机制;改进YOLO Head部分为双分支结构分别分配边界框位置预测及生成和特征分类的任务,并引入全局平均池化协助特征分类任务。
然而现有技术存在对小目标以及运动遮挡情况下的目标检测效果差的问题,因此如何发明一种对小目标检测准确率高的YOLOv7-tiny模型,是本技术领域亟需解决的技术问题。
发明内容
本发明为了解决现有技术对小目标以及运动遮挡情况下的目标检测效果差的问题,提供了改进的YOLOv7-tiny模型及基于该模型的人手脸检测方法及系统,其具有空间信息利用率高的特点。
为实现上述本发明目的,采用的技术方案如下:
改进的YOLOv7-tiny模型,包括骨干网络、颈部网络、预测头网络;所述的骨干网络用于提取数据特征;所述的颈部网络用于检测数据特征;所述的预测头网络用于根据检测得到的特征,输出预测的结果;
所述的骨干网络中,在原YOLOv7-tiny模型的骨干网络的最后额外设有一个CA注意力模块;所述的CA注意力模块用于对骨干网络最后输出的特征进行加权,增强对空间特征的检测;
所述的颈部网络中,在原YOLOv7-tiny模型的3个目标检测层的基础上,额外设有一个小目标检测层;所述的小目标检测层用于提取并检测浅层网络中的小目标特征;
所述的预测头网络中,在原YOLOv7-tiny模型的3个目标预测头的基础上,额外设有1个小目标预测头,并在每个预测头前设置了其对应的递归门控卷积块;所述的递归门控卷积块用于改进对复杂图像的预测效果;小目标预测头用于根据小目标检测层输出的小目标特征输出小目标预测结果;
采用Focal EIOU损失函数代替原YOLOv7-tiny模型的CIoU损失函数,从而更好地反映边界框之间的相似度,提高回归的精度;同时使回归过程专注于高质量的锚框,从而加速收敛并降低方差。
优选的,CA注意力模块的输入端与原YOLOv7-tiny模型的骨干网络的最后1个ELAN块的输出端连接;CA注意力模块的输出端与颈部网络中的CSPSPP块的输入端连接。
进一步的,小目标检测层的输入端与骨干网络的第1个ELAN块连接,小目标检测层的输出端与小目标预测头。
更进一步的,所述的小目标检测层,包括:第1CBL卷积块、第1concat块、UP块、第2CBL块、第1ELAN块、第2ELAN块、第3CBL块、第2concat块;第1ELAN块、第2CBL块、UP块、第1concat块、第2ELAN块、第3CBL块、第2concat块依次连接;第1CBL卷积块的输入端与骨干网络的第1个ELAN块连接;第1CBL卷积块的输出端与第1concat块的输入端连接;第1Elan块的输出端还与第2concat块的输入端连接;第2ELAN块的输出端与小目标预测头通过其对应的递归门控卷积块连接。
基于改进的YOLOv7-tiny模型的人手脸检测方法,包括以下具体步骤:
获取包括人手脸的数据并构建训练数据集;
将训练数据集输入改进的YOLOv7-tiny模型中进行训练:
通过改进的YOLOv7-tiny模型的骨干网络提取训练数据集中数据的特征;提取时,通过CA注意力模块对骨干网络提取的特征进行加权;
通过颈部网络检测人手脸数据集检测提取到的训练数据集中数据的特征;检测时,采用额外的目标预测头提取并检测浅层网络中的小目标特征;
通过预测头网络根据检测得到的特征,输出预测的结果;预测时,通过递归门控卷积块改进对复杂图像的预测效果,通过小目标预测头输出小目标预测结果;
根据预测的结果,通过Focal EIOU损失函数,训练改进的YOLOv7-tiny模型;
获取待检测的包括人手脸的数据并构建待检测数据集;将待检测数据集输入训练好的YOLOv7-tiny模型进行检测。
优选的,通过CA注意力模块对骨干网络提取的特征进行加权,具体步骤为:
设C、H、W分别为骨干网络提取的特征的张量X=[x
将两个方向分别池化得到的特征图在第三个维度进行Concat操作,得到C×1×(W+H)的特征图,同时利用1×1卷积对C×1×(W+H)的特征图执行r倍下采样,结合归一化操作和非线性激活函数,得到了同时包含水平和垂直两个方向信息的C/r×1×(W+H)的特征向量,记为f;
结合Sigmoid函数分别对f
进一步的,通过递归门控卷积块改进对复杂图像的预测效果,具体为:
将道数为C的检测得到的特征,经过线性投影操作将其通道数转为2C,并将通道数为2C的特征向量切分为不同通道数的特征投影块
C
(0≤k≤n-1)
其中
将
p
(k=0,1,…n-1)
其中,f
将最末次递归计算的结果经过投影层
更进一步的,所述的Focal EIOU损失函数,具体为:
L
其中,γ为抑制异常值的超参数,用于对锚框加权,加强高质量锚框对损失值的贡献,同时抑制低质量锚框的影响;L
更进一步的,获取包括人手脸的数据并构建训练数据集,具体为:收集人手脸的数据,通过LabelImg对人手脸的数据进行标注;将标注后的数据按照4:1的比例随机划分为训练集和测试集。
基于改进的YOLOv7-tiny目标检测模型的人手脸检测系统,包括数据处理模块、模型训练模块、人手脸检测模块;
所述的数据处理模块用于获取包括人手脸的数据并构建训练数据集和构建待检测数据集;
所述的模型训练模块用于将训练数据集输入改进的YOLOv7-tiny模型中进行检测;通过改进的YOLOv7-tiny模型的骨干网络提取训练数据集中数据的特征;提取时,通过CA注意力模块对骨干网络提取的特征进行加权;通过颈部网络检测人手脸数据集检测提取到的训练数据集中数据的特征;检测时,采用额外的目标预测头提取并检测浅层网络中的小目标特征;根据预测的结果,通过Focal EIOU损失函数,训练改进的YOLOv7-tiny模型;
所述的人手脸检测模块用于将待检测数据集输入训练好的YOLOv7-tiny模型进行检测。
本发明的有益效果如下:
本发明公开了改进的YOLOv7-tiny模型;在原YOLOv7-tiny模型的骨干网络的额外设一个CA注意力模块,从而弥补下采样过程中小目标因像素压缩导致的信息损失,从而改善YOLOv7-tiny模型对小目标的检测效果;在YOLOv7-tiny骨干网络末端融合CA注意力机制,增强模型学习特征的表达能力,考虑了通道信息和方向相关的位置信息,提高对空间信息利用的同时不增加过多计算量和参数量;在YOLOv7-tiny预测头处加入递归门控卷积gnConv。实现输入自适应、远程和高阶的空间交互,改善遮挡物体或复杂形状的物体的检测效果,提高模型的表达能力和泛化能力;用Focal EIOU代替YOLOv7-tiny默认的CIoU,更好地反映边界框之间的相似度,提高回归的精度;同时使回归过程专注于高质量的锚框,从而加速收敛并降低方差。
附图说明
图1是YOLOv7-tiny模型示意图。
图2是YOLOv7-tiny模型的ELAN块示意图。
图3是YOLOv7-tiny模型的CSPSPP示意图。
图4是YOLOv7-tiny模型的CBL示意图。
图5是本发明改进的YOLOv7-tiny模型示意图。
图6是本发明基于改进的YOLOv7-tiny模型的人手脸检测方法的流程示意图。
图7是本发明基于改进的YOLOv7-tiny模型的人手脸检测方法中CA注意力模块的加权流程示意图。
图8是本发明基于改进的YOLOv7-tiny模型的人手脸检测系统的框图。
具体实施方式
下面结合附图和具体实施方式对本发明做详细描述。
实施例1
如图5所示,改进的YOLOv7-tiny模型,包括骨干网络、颈部网络、预测头网络;所述的骨干网络用于提取数据特征;所述的颈部网络用于检测数据特征;所述的预测头网络用于根据检测得到的特征,输出预测的结果;
所述的骨干网络中,在原YOLOv7-tiny模型的骨干网络的最后额外设有一个CA注意力模块;所述的CA注意力模块用于对骨干网络最后输出的特征进行加权,增强对空间特征的检测;
本实施例中,人手脸检测数据集中,人手、人脸两个类相对与人体尺寸较小,在YOLOv7-tiny网络下采样过程中主要信息易丢失,网络较难提取到手、脸两个小目标类足够的特征信息;针对此问题所述的颈部网络中,在原YOLOv7-tiny模型的3个目标检测层的基础上,额外设有一个小目标检测层;所述的小目标检测层用于提取并检测浅层网络中的小目标特征,从而增加人手、人脸两个小目标类别特征信息的利用;
所述的预测头网络中,在原YOLOv7-tiny模型的3个目标预测头的基础上,额外设有1个小目标预测头,并在每个预测头前设置了其对应的递归门控卷积块;所述的递归门控卷积块用于改进对复杂图像的预测效果;小目标预测头用于根据小目标检测层输出的小目标特征输出小目标预测结果;
采用Focal EIOU损失函数代替原YOLOv7-tiny模型的CIoU损失函数。
在一个具体实施例中,CA注意力模块的输入端与原YOLOv7-tiny模型的骨干网络的最后1个ELAN块的输出端连接;CA注意力模块的输出端与颈部网络中的CSPSPP块的输入端连接。
本实施例中,YOLOv7-tiny的输入首先进入骨干网络,在经过骨干网络的第1个最大池化层之前,仍然保留着原输入的图像分辨率,经过最大池化层后,分辨率会被压缩,小目标的信息会有一定程度的损失;换言之,小目标在YOLOv7-tiny浅层仍保留着较完整的信息。因此,在骨干网络的第一个最大池化层之前的第1个ELAN块增加一个输出,可提取浅层的小目标特征;
在一个具体实施例中,小目标检测层的输入端与骨干网络的第1个ELAN块连接,小目标检测层的输出端与小目标预测头。
在一个具体实施例中,所述的小目标检测层,包括:第1CBL卷积块、第1concat块、UP块、第2CBL块、第1ELAN块、第2ELAN块、第3CBL块、第2concat块;第1ELAN块、第2CBL块、UP块、第1concat块、第2ELAN块、第3CBL块、第2concat块依次连接;第1CBL卷积块的输入端与骨干网络的第1个ELAN块连接;第1CBL卷积块的输出端与第1concat块的输入端连接;第1Elan块的输出端还与第2concat块的输入端连接;第2ELAN块的输出端与小目标预测头通过其对应的递归门控卷积块连接。
本实施例中,同时在颈部网络增加上采样层(Upsample)和卷积层,同时用Concat操作融合前一层上采样得到的特征图和第一个最大池化层前输出的浅层特征;最后在预测头网络处生成一个富含小目标特征信息的小目标检测头,利用更多的小目标特征信息,改善小目标类别的检测效果。
实施例2
如图6所示,基于改进的YOLOv7-tiny模型的人手脸检测方法,包括以下具体步骤:
获取包括人手脸的数据并构建训练数据集;
将训练数据集输入改进的YOLOv7-tiny模型中进行训练:
通过改进的YOLOv7-tiny模型的骨干网络提取训练数据集中数据的特征;提取时,通过CA注意力模块对骨干网络提取的特征进行加权;
通过颈部网络检测人手脸数据集检测提取到的训练数据集中数据的特征;检测时,采用额外的目标预测头提取并检测浅层网络中的小目标特征;
通过预测头网络根据检测得到的特征,输出预测的结果;预测时,通过递归门控卷积(gnConv)块改进对复杂图像的预测效果,通过小目标预测头输出小目标预测结果;
根据预测的结果,通过Focal EIOU损失函数,训练改进的YOLOv7-tiny模型;
获取待检测的包括人手脸的数据并构建待检测数据集;将待检测数据集输入训练好的YOLOv7-tiny模型进行检测。
本实施例中,人类大脑在信息获取和处理过程中,具有对重要信息筛选、重视以及对不重要信息过滤的功能,注意力机制是一种模仿人类视觉和认知系统的技术,可以让神经网络通过反向传播更新权重参数,选择性地关注特征图中对输出贡献较大的部分,同时提高神经网络的性能和泛化能力。
常用的注意力机制包括SE、CBAM、ECA和CA等。其中,CA注意力机制是一种高效的注意力机制,可以有效提高图像分类、目标检测和语义分割等网络模型的性能。它的主要思想是将通道注意力分解为两个一维的特征编码过程,分别沿着水平和垂直方向聚合特征,从而捕获远程依赖关系和精确的位置信息。CA注意力机制关注了通道信息的同时关注了位置和方向信息,可以在不同的空间方向上捕获不同的信息,从而增强关注对象的表示;由于CA注意力机制只使用了一维的编码和线性变换,决定了其可以在仅增加少量计算开销的同时提高网络的性能,从而得以运用在轻量级网络上;CA注意力机制在反向传播的过程中更新参数,学习到每个特征的重要性和权重,根据特征权重即特征对输出的贡献,调整注意力机制的输出,从而使模型可以更加关注重要信息,弱化相对不重要的信息。在YOLOv7-tiny中融合CA注意力机制,使得网络在对目标做检测定位时可以关注到感兴趣的物体的位置。
如图7所示,在一个具体实施例中,通过CA注意力模块对骨干网络提取的特征进行加权,具体步骤为:
设C、H、W分别为骨干网络提取的特征的张量X=[x
将两个方向分别池化得到的特征图在第三个维度进行Concat操作,得到C×1×(W+H)的特征图,同时利用1×1卷积对C×1×(W+H)的特征图执行r倍下采样,结合归一化操作和非线性激活函数,得到了同时包含水平和垂直两个方向信息的C/r×1×(W+H)的特征向量,记为f;
结合Sigmoid函数分别对f
为了探求CA注意力机制与YOLOv7-tiny网络结合的最优方式,本实施例针对YOLOv7-tiny网络引入CA注意力机制的不同位置进行对比试验,分别将CA注意力机制引入YOLOv7-tiny基础模型的骨干网络、颈部网络和预测头网络,对比mAP指标,实验结果如表1所示。从实验结果可见,将CA注意力机制融合到YOLOv7-tiny网络骨干网络的检测效果要优于融合到颈部网络和预测头网络。因此,本发明将CA注意力机制融合至YOLOv7-tiny网络骨干网络末端,有利于网络更加注意待检测图像的关键像素信息,提高对人、手、脸目标的检测识别性能;同时,CA注意力机制具有简单轻巧的特性,可以在近乎不增加额外计算代价的前提下提高YOLOv7-tiny网络的性能。
表1YOLOv7-tiny网络不同位置融合CA注意力机制对比
本实施例中,递归门控卷积(gnConv)由标准卷积、深度可分离卷积(DWConv)、线性投影(Proj)和元素乘法(Mul)组成。递归门控卷积核心思想是在网络多个层次上递归使用门控卷积,能够捕捉图像中的高阶空间互动,实现长距离建模,有利于在物体检测中对遮挡物体或复杂形状的物体有更加良好的检测效果。在人手脸检测过程中,由于人体运动状态的多样性和复杂性导致各种遮挡情况的存在,以及人手在运动过程中手势的复杂多样,故将递归门控卷积引入YOLOv7-tiny网络,用以改善对复杂运动场景下的检测效果
在一个具体实施例中,通过递归门控卷积块改进对复杂图像的预测效果,具体为:
将道数为C的检测得到的特征,经过线性投影操作将其通道数转为2C,并将通道数为2C的特征向量切分为不同通道数的特征投影块
C
(0≤k≤n-1)
其中
将
p
(k=0,1,…n-1)
其中,f
将最末次递归计算的结果经过投影层
本实施例中,YOLOv7-tiny默认使用CIoU损失函数,CIoU考虑了边界框的相交面积、中心点的距离和边界框的长宽比。然而,CIoU使用边界框的长宽比作为边界框回归的衡量标准存在一定问题,当预测框的宽和高比例与真实框的宽和高比例相同时,CIoU中针对宽和高相对比例的惩罚项就会失效。其次,由于人手脸检测中待检测图像背景复杂,前景和背景容易失衡,大量与目标框重叠度小的、低质量的锚框,在回归中占据主导地位,产生较大的梯度,影响模型参数优化的方向。
为了解决以上两个问题,本发明引入了Focal EIoU Loss(Focal and EfficientIoU Loss),替换YOLOv7-tiny默认使用的CIoU损失函数。不同于CIoU Loss针对宽和高相对比例进行惩罚,Focal EIoU Loss将方位损失分解为两个项,即分解为直接对预测框的宽和高回归结果进行惩罚,更好反映预测框和真实框的相似度。其次,参考分类问题中应用的Focal Loss,Focal EIoU Loss提出了针对回归预测问题的FocalL1 Loss,它使YOLOv7-tiny在反向传播过程中更加关注与目标框重叠度高、高质量的锚框,减少低质量锚框所产生梯度的干扰,进而加速YOLOv7-tiny网络模型收敛。
在一个具体实施例中,所述的Focal EIOU损失函数,具体为:
L
其中,γ为抑制异常值的超参数,用于对锚框加权,加强高质量锚框对损失值的贡献,同时抑制低质量锚框的影响;L
在一个具体实施例中,获取包括人手脸的数据并构建训练数据集,具体为:收集人手脸的数据,通过LabelImg对人手脸的数据进行标注;将标注后的数据按照4:1的比例随机划分为训练集和测试集。
本实施例中,图片来源于MS COCO数据集、PASCAL VOC数据集和移动设备拍摄;标注完成后,首先将PASCAL VOC格式的标签文件转化为YOLO格式的标签文件;其次,将数据集按4:1的比例随机划分为训练集10000张,测试集2500张。
目前公开的数据集,仅针对人体、人手、人脸其中之一做标注,因此在实际应用中若需要同时对人体、人手、人脸做检测,则需要部署三个目标检测模型,大大增加了计算资源的消耗。因此,本实施例中建立人手脸检测数据集,通过训练同时检测人体、人手、人脸三个类别的目标检测模型,减少了实际部署场景中检测模型实时推理时对计算资源的占用。对此,本实施例中设计了实验,将人手脸检测数据集分成三个分别只包含人体、人手、人脸标注信息的数据集,用YOLOv7-tiny模型进行训练,对比人手脸检测数据集训练的YOLOv7-tiny模型与三个子数据集训练的YOLOv7-tiny检测模型的性能指标,实验结果如表2所示。
表2YOLOv7-tiny网络在不同数据集训练结果对比
由实验结果可知,人手脸检测数据集训练得到的YOLOv7-tiny模型参数量大致是人体检测、人脸检测和手部检测三个单独的YOLOv7-tiny模型参数量总和的三分之一,且人手脸检测数据集训练得到的检测模型对每一个类检测的精度也与单个类子数据集训练得到的检测模型基本相当。
本实施例中,为了直观对比本发明改进算法和原始YOLOv7-tiny算法检测效果提升,选取人手脸检测数据集测试集的部分图像,分别用本发明改进算法和原始YOLOv7-tiny算法进行检测;
由检测结果可知,本发明改进的YOLOv7-tiny算法相对于原算法检测出了远处尺寸小的人脸,缓解了因待检测目标尺寸小的漏检;在目标人物重叠的时候,本发明改进算法可以检测出更多目标,体现更好的检测效果;再者,检测结果中,原始YOLOv7-tiny算法将远处的物体错误地识别为人,而本发明提出改进算法减少了此类小目标的错检问题。同时也可以看到,改进算法检测的置信度得分相对于原YOLOv7-tiny算法也有提高,整体上提高了检测效果,进一步体现了本发明提出改进模型对于小目标检测的优势。
实施例3
如图8所示,基于改进的YOLOv7-tiny目标检测模型的人手脸检测系统,包括数据处理模块、模型训练模块、人手脸检测模块;
所述的数据处理模块用于获取包括人手脸的数据并构建训练数据集和构建待检测数据集;
所述的模型训练模块用于将训练数据集输入改进的YOLOv7-tiny模型中进行检测;通过改进的YOLOv7-tiny模型的骨干网络提取训练数据集中数据的特征;提取时,通过CA注意力模块对骨干网络提取的特征进行加权;通过颈部网络检测人手脸数据集检测提取到的训练数据集中数据的特征;检测时,采用额外的目标预测头提取并检测浅层网络中的小目标特征;根据预测的结果,通过Focal EIOU损失函数,训练改进的YOLOv7-tiny模型;
所述的人手脸检测模块用于将待检测数据集输入训练好的YOLOv7-tiny模型进行检测。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。