一种基于改进人工势场的目标优先级匹配方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及人工智能技术领域,具体涉及一种基于改进人工势场的目标优先级匹配方法。
背景技术
强化学习(Reinforcement Learning)是人工智能领域中的一种重要学习方法,让智能体(Agent)根据环境(Environment)反馈的信息做出最佳决策,从而最大化累积奖励。它的主要研究方向是如何让智能体(Agent)根据当前环境(Environment)反馈的信息做出更好的决策。强化学习被认为是真实世界的缩影,并被视为实现通用人工智能目标的最有前途的研究领域之一。强化学习是一种描述智能体为了完成任务而连续做出决策的方法,如图1所示。与监督学习不同,强化学习不需要事先给定先验知识或准确的参考标准,而是通过智能体与环境不断交互来获取当前状态和奖励信息,自主选择动作,最终找到适合当前状态下最优的动作选择策略,并获得整个决策过程的最大累积奖励。
电势场从能量的角度来描述,即电势U。电势是一个标量,只有大小,没有方向。如果用电势去描述电场,则它形成一个标量场,即电势场。对于点电荷产生的电势场中某一点的电势U,其计算公式为:
人工势场是指借鉴电场模型的基本原理,根据战场态势分析的基本要求,把战场中敌我双方的兵力虚拟成电场中的异种电荷,“大量电荷”之间相互作用从而形成的一个人工构造的用来辅助指挥控制Agent分析战场态势的虚拟势场模型。人工势场(artificalpotential field)借鉴电场模型,构建根据战场态势分析敌我双方兵力的虚拟势能场。在人工势场模型中,把代表敌我双方相关Agent的一些属性和战场中其他的一些作战资源虚拟成电场中的电荷。其带电量可以表示为参战Agent的作战能力等。鉴于战场态势一般是红蓝双方兵力部署形成的,因此需要把它分为红蓝双方来分别计算,计算公式为:
其中Q
式中,k
综上,传统的强化学习训练方法中,智能体直接从环境中获取环境状态信息可能会由于信息缺失、环境整体趋势不明确等问题导致训练效果低下,无法从待选目标中选择最正确的目标。人工势场方式考虑的是双方单位力量的势能,而没有体现打击价值与防守力量的综合考虑,并且人工势场方式只是一些基本的战场态势分析,未充分利用人工势场模型的优势进行更细致的分析,人工势场方式仅仅适用于二维平面环境。可见,现有方法不能根据目标优先级为智能体提供选择优先级,影响其决策效果。
发明内容
有鉴于此,本发明提供了一种基于改进人工势场的目标优先级匹配方法,能够有效提高智能体的决策效果。
为实现上述目的,本发明技术方案如下:
一种基于改进人工势场的目标优先级匹配方法,靠环境信息以及奖励进行强化学习,包括:
基于改进后的人工势场模型
其中,人工势场模型
其中,A代表进攻敌方目标胜算,L代表敌方目标的位置价值,V代表敌方目标的价值,
其中,具体实施步骤如下:
获取原始环境状态、奖励以及其他对势场计算有用信息的格式;
从环境状态中提取所有实体位置,并根据环境范围编写位置归一化方法;
根据环境中的信息计算或人为设置实体属性和价值;
确定根据属性和价值计算势能的方法,确定根据势场的多维数组实现环境的观测方法;确定根据可选的实体实现环境中可选的行动方法;
根据训练资源和实际需求选择或编写合适的强化学习算法;
环境接入强化学习算法进行训练,训练过程具体为:
步骤1,初始化环境;
步骤2,从环境中获取原始的状态信息,包含描述环境state、奖励和是否结束;
步骤3,基于改进后的人工势场模型
步骤4,根据得到的观测空间、行动空间以及强化算法学习到的策略得到action;
步骤5,执行action后得到的奖励,由奖励与观测更新策略;
步骤6,判断本局对战是否完成,如果没有达到本局结束条件就回到步骤2继续游戏;否则执行步骤7;
步骤7,判断训练是否完成,如果训练没有完成则回到步骤1进行下一次迭代;否则训练完成,获得训练好的改进人工势场目标优先级匹配方法模型。
其中,所述强化学习算法包括PPO算法和dreamerV3算法。
其中,目标的价值设置为先验知识。
其中,采用拟合价值的方式设置目标的价值。
有益效果:
1、本发明用于强化学习算法中环境信息的提取处理,提高算法对于对方目标与防守力量的综合考虑,由势能场表达公式可以看出,改进的人工势场对于目标的价值与防卫能力做了综合考量,改进后的人工势场得到环境中更细致的情况分析,得到了目标的优先级,在算法选择行动时,每个行动被选取的可能性与目标优先级正相关,有效提高了智能体的决策效果。
2、本发明基于改进后的人工势场模型获得对应环境中实体的完整势能分布空间。经过阈值筛选和可选性筛选确定一个观察空间和行动空间,利用势能值由高到低的排序,实现目标优先级匹配,供指挥控制Agent选择。
3、本发明优选实施方式中,根据目标所在改进人工势场中的位置得到目标优先级,在强化学习中所使用的环境和动作设计方法有效提高了智能体的决策效果。
附图说明
图1为强化学习中智能体与环境交互的示意图。
图2为本发明中核心框架示意图。
图3为本发明基于改进人工势场的目标优先级匹配流程图。
图4为2D敌方20目标+20守卫模拟环境使用本发明方法与不使用本发明方法对比图。
图5为3D敌方20目标+20守卫模拟环境使用本发明方法与不使用本发明方法对比图。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
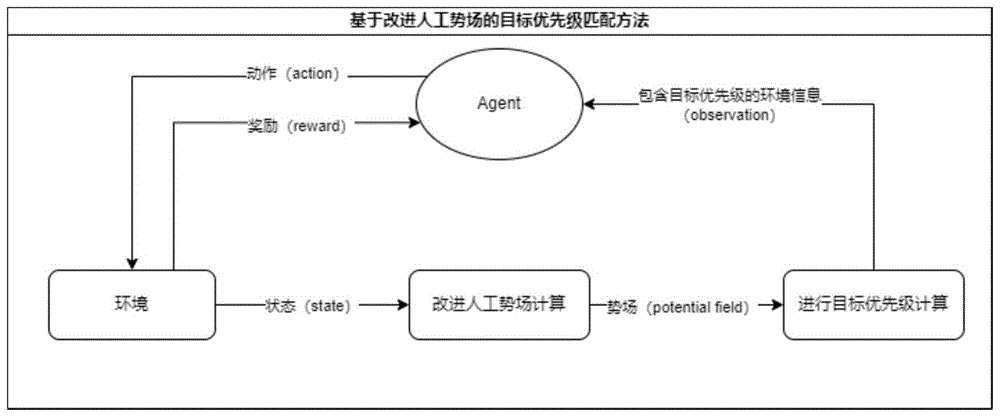
本发明提供了一种基于改进人工势场的目标优先级匹配方法。本发明的核心框架与下图2所示,包括智能体、环境、改进人工势场计算、目标优先级计算。
本发明与传统的强化学习环境最相同之处在于智能体同样是靠环境信息以及奖励进行学习的。本发明不同之处在于环境信息的处理。环境可以提供状态(state)信息,通过这个状态信息可以计算改进人工势场——一个体现敌方目标价值与防御能力的抽象势能地图。
本发明的改进人工势场中单个实体的势能计算方法如下:
A代表进攻敌方目标胜算;V代表敌方目标的价值;L代表敌方目标的位置价值,取决于它所处的地势等环境因素;
因此一点周围受多个不同势场计算方法如下,进行相加运算得出势能:
其中,n代表势场中目标(实体)个数,i表示目标(实体索引)编号,i=1,2,3…n。
改进后的人工势场模型
本发明的流程图如下图3所示,包括方法实现和训练,具体实施步骤如下:
方法实现:
获取原始环境状态、奖励以及其他对势场计算有用信息的格式;
从环境状态中提取所有实体位置,并根据环境范围编写位置归一化方法;
根据环境中的信息计算或人为设置实体属性和价值;
确定根据属性和价值计算势能的方法,确定根据势场的多维数组实现环境的观测方法;确定根据可选的实体实现环境中可选的行动方法。
根据训练资源和实际需求选择或编写合适的强化学习算法,如PPO或dreamerV3等。
环境接入强化学习算法进行训练,训练过程具体为:
步骤1,初始化环境。
步骤2,从环境中获取原始的状态信息,包含了描述环境state、奖励和是否结束等。
步骤3,基于改进后的人工势场模型
其中,行动空间(action space)为智能体可选择的动作集合;观测空间(observation space)为智能体从环境观测到的信息集合;优先级匹配(prioritymatching)表示根据人工势场中目标的势能值,对目标排序,确定先后选择顺序。
本发明中目标优先级匹配中的依据,也就是目标的价值设置为先验知识,但拟合价值等方法同样有效,因此可采用不同的价值设置方法。
步骤4,根据得到的观测空间、行动空间以及强化算法学习到的策略得到action;
步骤5,执行action后得到的奖励,由奖励与观测更新策略。
步骤6,判断本局对战是否完成。如果没有达到本局结束条件就回到步骤2继续游戏;否则执行步骤7;
步骤7,判断训练是否完成。如果训练没有完成则回到步骤1进行下一次迭代;否则训练完成,获得训练好的改进人工势场目标优先级匹配方法模型。
图4为2D敌方20目标+20守卫模拟环境使用本方法与不使用本方法对比图,本发明有效提高了智能体的决策效果。
图5为3D敌方20目标+20守卫模拟环境使用本方法与不使用本方法对比图,三维环境下本发明方法效果同样明显。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。