一种基于图像序列的废钢斗号码识别方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及目标识别的技术领域,尤其是涉及一种基于图像序列的废钢斗号码识别方法。
背景技术
废钢斗是用来装盛装废钢的设备,其作用是给转炉运输冶炼所需的废钢。为了便于跟踪统计,在每个废钢斗尾部与侧边均印有号码。由于转炉废钢斗上的号码没有固定的字体、大小和位置,而且高温会对号码造成很大的影响,如污浊、损毁,再者天车吊着废钢斗行进过程中会出现废钢斗倾斜的情况,这些都会给识别带来一定的困难,而且,当废钢斗距离较远,号码较小且与颜色与背景颜色相似时,识别的难度更大。
发明内容
为了有效的对废钢斗上的号码进行准确识别,本发明提供一种基于图像序列的废钢斗号码识别方法。
第一方面,一种基于图像序列的废钢斗号码识别方法,其特征在于:包括如下步骤:
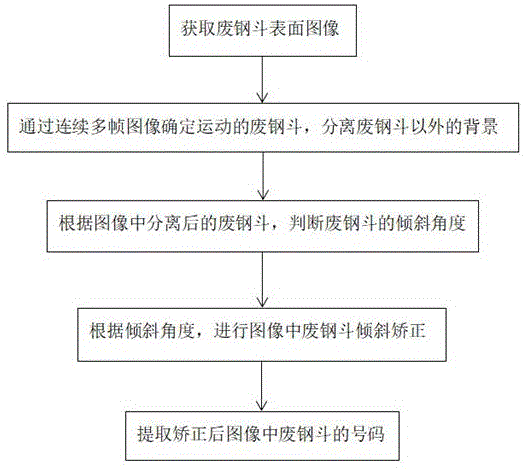
获取废钢斗表面图像;
通过连续多帧图像确定运动的废钢斗,分离废钢斗以外的背景;
根据图像中分离后的废钢斗,判断废钢斗的倾斜角度;
根据倾斜角度,进行图像中废钢斗倾斜矫正;
提取矫正后图像中废钢斗的号码。
进一步的,所述获取废钢斗表面图像采用耐高温的工业2D相机实时记录成像。
进一步的,所述确定运动的废钢斗采用对连续帧图像的差分得到前后帧之间的差异,并对差异图像进行图像增强,利用目标提取找到废钢斗区域。
进一步的,所述分离废钢斗以外的背景,具体为:
使用边缘检测算法来识别图像中的边缘,通过检测边缘可以找到目标物体与背景之间的分界线,对图像进行初步分离;
将初步分离后的图像进行二值化处理,通过连通区域分析算法,将图像中的像素点组成不同的连通区域,根据目标物体的大小以及形状特征进行选择和筛选,得到准确的废钢斗图像区域,则其余的为背景,对背景部分去色。
进一步的,所述判断废钢斗的倾斜角度,具体为:
通过边缘检测算法检测废钢斗的边缘,使用直线拟合算法将废钢斗的边缘线条拟合成边缘直线,设定x轴与y轴为标线,计算拟合出的边缘直线与标线之间的角度,得到第一倾斜角度;
通过角点检测算法,得到废钢斗的角点位置信息,所述角点位置信息为废钢斗的棱角的(x,y)坐标值,根据坐标值连线,设定x轴与y轴为标线,计算坐标值连线与标线之间的角度,得到第二倾斜角度,取第一倾斜角度与第二倾斜角度的中间角度值,得出废钢斗的倾斜角度。
进一步的,所述废钢斗倾斜矫正,具体为:
根据倾斜角度计算旋转矩阵,倾斜角度为θ,旋转矩阵R为:
根据旋转矩阵R,对原始图像进行逆时针旋转,旋转后的图像将使废钢斗与水平对齐。
进一步的,所述提取废钢斗号码采用深度学习模型进行处理,深度学习模型中包括有利用目标检测网络对废钢斗号码检测,利用字符识别网络对废钢斗号码识别,具体为:
构建一个深度学习模型,对模型进行训练,首先将矫正后的图像数据集分为训练集和测试集,在训练集上训练深度学习模型,并通过测试集进行调优;
使用独立的测试集对训练好的模型进行评估,计算识别准确率、召回率的指标;根据指标进行调整网络结构、增加训练数据以及调整超参数的模型优化;
将训练好的模型部署到废钢斗号码识别系统中,通过调用模型对图像序列进行识别,并输出识别结果。
进一步的,所述目标检测网络以及字符识别网络均包括前处理、深度学习网络处理以及后处理三部分,将所述前处理、深度网络学习处理以及后处理均移动至GPU进行运算,在GPU上运算完成后再从GPU内存传输至CPU内存。
进一步的,通过多任务学习或联合训练将目标检测网络以及字符识别网络合二为一,合并后具体为:
调整输入输出层:检测目标检测网络的输出和字符识别网络的输入是否具有相同的维度,如不一致,则调整网络结构或添加转换层来实现相同维度;
融合特征提取层:选择目标检测网络中的特征提取部分作为基础进行融合,提取的特征为已具备对目标进行定位和检测能力的特征;
添加识别层:在融合特征提取层之后添加用于号码识别的字符识别层,字符识别层将对目标检测提取到的感兴趣区域作为输入,输出是字符类别的预测结果,用于字符识别任务;
联合训练层:使用包含目标检测和字符识别标签的数据集进行联合训练,通过定义的损失函数来同时优化目标检测和识别任务;
端到端微调层:完成联合训练后,使用端到端的微调策略进一步优化网络,通过使用包含目标检测和识别任务的综合损失函数进行微调,得到高性能的网络。
第二方面,一种终端设备,包括处理器和计算机可读存储介质,处理器用于实现各指令;计算机可读存储介质用于存储多条指令,所述指令适于由处理器加载并执行所述的一种基于图像序列的废钢斗号码识别方法。
综上所述,本发明具有如下的有益技术效果:
本发明通过分离废钢斗的背景,对废钢斗的图像进行倾斜角度计算,再对废钢斗进行倾斜矫正,可以得到正视的废钢斗的图像,更准确的提取废钢斗中的号码。
该技术方案同时对识别号码的整个过程中采用的目标检测网络以及字符识别网络中的处理移动至GPU,在GPU运行后再传输至CPU,大大加快了处理速度,提升了计算性能;同时对目标检测网络以及字符识别网络进行二合一处理,数据集进行联合训练,合并后加快了运行处理速度。
附图说明
图1是本发明一种基于图像序列的废钢斗号码识别方法的流程图。
图2是本发明一种基于图像序列的废钢斗号码识别方法中合并后的网络构架。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
本发明实施例公开一种基于图像序列的废钢斗号码识别方法。参照图1,
实施例1
本实施例的一种基于图像序列的废钢斗号码识别方法,包括:
获取废钢斗表面图像;
通过连续多帧图像确定运动的废钢斗,分离废钢斗以外的背景;
根据图像中分离后的废钢斗,判断废钢斗的倾斜角度;
根据倾斜角度,进行图像中废钢斗倾斜矫正;
提取矫正后图像中废钢斗的号码。
具体包括以下步骤:
获取废钢斗表面图像采用耐高温的工业2D相机实时记录成像,工业2D相机安装在废钢斗吊起后的必经路线附近。
记录成像处理成连续多帧的图像,通过对连续帧图像的差分得到前后帧之间的差异,对差异图像进行图像增强,再利用目标提取找到废钢斗区域。
目标提取采用目标提取算法,具体为:
采用Bounding box对废钢斗进行最小矩形框选,废钢斗处有多个最小矩形被框选,设置坐标(x,y,w,h),其中(x,y)为图像左下角的坐标值,(w,h)为最小矩形的宽和高;
采用intersection over Union对矩形区域进行重合度计算,计算公式为:
R为一个矩形框,R’为与R有重合部分的矩形框;
对重合的多个矩形框进行计算Iou,将Iou大于0.5的记为TP,Iou小于等于0.5的记为FP,保留TP中矩形框并集的图像,即为废钢斗区域。
确定废钢斗区域后,需要分离废钢斗以外的背景,具体为:
使用边缘检测算法来识别图像中的边缘,通过检测边缘可以找到目标物体与背景之间的分界线,对图像进行初步分离;
将初步分离后的图像进行二值化处理,通过连通区域分析算法,常用连通区域标记以及区域生长标记,将图像中的标记的像素点组成不同的连通区域,根据目标物体的大小以及形状特征进行选择和筛选,得到准确的废钢斗图像区域,则其余的为背景,对背景部分去色。
其中边缘检测算法处理步骤为:
1.对输入图像进行灰度化处理;2.对灰度图像进行高斯滤波以平滑图像;3.计算图像梯度的幅值和方向;4.对梯度幅值进行非极大值抑制,细化边缘;5.使用双阈值算法进行边缘连接和边缘消除;6.通过连接强边缘和与之相连的弱边缘,形成连续的边缘路径。
连通区域分析算法处理步骤为:
1.构建图像的邻接表表示;2.遍历图像中的每个像素,找到与其相邻且灰度值相同的像素;3.将相邻像素合并为一个连通区域;4.标记每个连通区域,统计其大小等属性。
去除背景后,得到废钢斗的图像,再判断废钢斗的倾斜角度,具体为:
通过边缘检测算法检测图像中的边缘,使用直线拟合算法将废钢斗的边缘线条拟合成边缘直线,设定x轴与y轴为标线,计算拟合出的边缘直线与标线之间的角度,得到第一倾斜角度;
通过角点检测算法,得到废钢斗的角点位置信息,所述角点位置信息为废钢斗的棱角的(x,y)坐标值,根据坐标值连线,设定x轴与y轴为标线,计算坐标值连线与标线之间的角度,得到第二倾斜角度,取第一倾斜角度与第二倾斜角度的中间角度值,得出废钢斗的倾斜角度。
其中直线拟合算法采用最小二乘法直线拟合:
1.输入一组点坐标 (x_i, y_i);2.计算点的均值 (x_mean, y_mean);3.计算归一化的离差平方和 S_xx = sum((x_i - x_mean)^2) 和 S_xy = sum((x_i - x_mean) *(y_i - y_mean));4.拟合直线的斜率 k = S_xy / S_xx 和截距 b = y_mean - k * x_mean。
角点检测算法处理步骤为:
1.对输入图像进行灰度化处理;2.计算每个像素点的梯度(水平和垂直方向);3.计算每个像素点的结构相似性度量函数 R = det(M) - k * trace(M)^2,其中 M 是窗口内的自相关矩阵;4.对 R 做阈值处理,得到角点。
根据倾斜角度对废钢斗倾斜矫正,具体为:
根据倾斜角度计算旋转矩阵,倾斜角度为θ,旋转矩阵R为:
根据旋转矩阵R,对原始图像I进行逆时针旋转,对于每个像素坐标(x, y),经过(x’, y’) = R * (x, y),矫正后的像素坐标为(x’, y’),得到矫正后的图像I’,旋转后的图像将使废钢斗与水平对齐。
从矫正后的图像进行废钢斗号码检测和废钢斗号码识别,提取废钢斗号码采用深度学习模型进行处理,深度学习模型中包括有利用目标检测网络对废钢斗号码检测,利用字符识别网络对废钢斗号码识别,具体为:
构建一个深度学习模型,对模型进行训练,首先将矫正后的图像数据集分为训练集和测试集,在训练集上训练深度学习模型,并通过测试集进行调优;
使用独立的测试集对训练好的模型进行评估,计算识别准确率、召回率的指标;根据指标进行调整网络结构、增加训练数据以及调整超参数的模型优化;
将训练好的模型部署到废钢斗号码识别系统中,通过调用模型对图像序列进行识别,并输出识别结果。
其中废钢斗号码检测采用目标检测网络进行处理,具体为:
数据准备:收集和标注包含废钢斗号码的图像数据集,并将其划分为训练集和测试集。对图像进行裁剪和缩放处理,保证图像大小一致。
选择目标检测网络:选择一种适合目标检测任务的网络结构,如基于深度学习的网络,这些网络在目标检测任务上具有较好的性能。
网络训练:使用标注的数据集对目标检测网络进行训练。将图像输入网络,并根据标注信息计算损失函数进行反向传播优化网络参数。训练过程中可以采用一些技术手段,如数据增强、批量归一化等,以提高模型的泛化能力。
模型调优:根据实际情况,对训练得到的模型进行调优。可以根据需求调整网络的超参数,如学习率、迭代次数等,以获得更好的检测性能。
模型测试:使用测试集评估训练得到的目标检测模型的性能。将测试图像输入网络,获取目标的位置信息和类别预测结果。
后处理:根据检测结果进行后处理操作,如非极大值抑制(NMS),去除重叠框和低置信度的检测结果,获得最终的废钢斗号码检测结果。
废钢斗号码识别采用字符识别网络进行处理,具体为:
数据准备:收集和标注包含废钢斗号码的图像数据集,并将其划分为训练集和测试集。对图像进行预处理,如灰度化、二值化、图像增强等操作,以提升字符识别的准确性。
选择字符识别网络:选择一种适合字符识别任务的网络结构,如卷积神经网络等。这些网络在字符识别任务上有一定的应用。
网络训练:使用标注的数据集对字符识别网络进行训练。将图像输入网络,并根据标注信息计算损失函数进行反向传播优化网络参数。可以采用一些技巧,如数据增强、批量归一化等来提高模型的泛化能力。
模型调优:根据实际情况,对训练得到的模型进行调优。可以尝试不同的网络结构、参数配置和训练策略,以获得更好的字符识别性能。
模型测试:使用测试集评估训练得到的字符识别模型的性能。将测试图像输入网络,获取字符的识别结果。
后处理:根据实际需求进行后处理操作,如字符序列的整理、去除错误的识别结果等,获得最终的废钢斗号码识别结果。
目标检测网络以及字符识别网络均包括前处理、深度学习网络处理以及后处理三部分,由于图像众多,处理速度缓慢,所以将前处理、深度网络学习处理以及后处理均移动至GPU进行运算,在GPU上运算完成后再从GPU传输至CPU。
准备数据:需要将待处理的图像数据加载到GPU内存中,以便后续在GPU上进行处理。
前处理移动至GPU:将原本在CPU上执行的前处理操作(如图像预处理、尺寸调整等)移动到GPU上。这可以通过使用GPU加速的图像处理库(如CUDA、OpenCL)来实现。将图像数据从主机内存传输到GPU内存,并在GPU上执行相应的前处理操作。
深度学习网络处理:将深度学习网络模型移动到GPU上,使用GPU加速进行推理或训练。在GPU上执行前向传播和反向传播等深度学习计算任务,以获得更快的处理速度和更高的计算性能。
后处理移动至GPU:将原本在CPU上执行的后处理操作(如边界框筛选、结果解码等)移动到GPU上。类似于前处理,可以使用GPU加速的库来实现这些操作,并在GPU上对深度学习网络的输出结果进行处理。
获取结果:将处理后的结果从GPU内存传输回主机内存,以便进一步分析或输出。
通过将前处理和后处理与深度学习网络处理步骤结合在一起,并在GPU上执行,可以减少数据在主机内存和GPU内存之间的数据传输时间,从而提高整体处理速度。这种合成的处理框架能够充分利用GPU的并行计算能力,加快处理过程,适用于需要处理大量数据和复杂计算的任务。
由于数据庞大,且处理的视频图像以及后续的图像都非常多,所有处理过程中会对CPU产生负荷,运行速度降低,所以将部分处理移至GPU上,处理后在传给CPU,大大加快了处理速度,且给CPU减轻了计算量,提高了整体的计算速度。
参照图2,为了加快处理速度,除了将目标检测网络以及字符识别网络的处理移动至GPU上,还采用多任务学习或联合训练将目标检测网络以及字符识别网络合二为一,合并后具体为:
通过使用多任务学习(multi-task learning)或联合训练(joint training),合并后的网络可以被看作是一个多功能的综合网络,既可以进行目标检测,又可以进行字符识别。
合并后的网络通常由以下几个部分组成:
调整输入输出层:确保目标检测网络的输出和字符识别网络的输入具有相同的维度。如果不一致,可以通过调整网络结构或添加适当的转换层来实现匹配。
融合特征提取层:选择目标检测网络中的特征提取部分作为融合的基础。这些特征已经具备了对目标进行定位和检测的能力。
添加识别层:在融合特征提取层之后添加用于号码识别的字符识别层,字符识别层将对目标检测提取到的感兴趣区域作为输入,输出是字符类别的预测结果,用于字符识别任务。
联合训练层:使用包含目标检测和字符识别标签的数据集进行联合训练。可以定义适当的损失函数来同时优化目标检测和识别任务。例如,目标检测部分可以使用目标位置的回归损失,而识别部分可以使用交叉熵损失。
端到端微调层:在联合训练完成后,可以使用端到端的微调策略进一步优化网络。通过使用包含目标检测和识别任务的综合损失函数进行微调,可以提高网络的整体性能。
合并后的网络的运行逻辑如下:
将待处理的图像作为网络的输入到输入输出层。
在融合特征提取层中使用卷积、池化等操作提取图像的共享特征部分,在共享卷积层之后,添加目标检测网络的层。
使用经典的目标检测算法制定目标检测架构,也可以使用自定义的目标检测架构,目标检测网络的输出包括目标类别和边界框。
根据目标检测的边界框,从共享卷积层输出中提取感兴趣区域(Region ofInterest, ROI),该区域也叫ROI池化层,ROI池化层可以将不同大小的ROI缩放到固定尺寸,以便进行字符识别。
将ROI池化层的输出作为输入,用于字符识别任务,采用字符识别网络,对提取的ROI进行字符识别,字符识别分支的输出是字符类别的预测结果。
最终输出结果是将目标检测的边界框和字符识别的结果结合起来,形成最终的输出。将目标类别、边界框、字符类别等信息整合在一起。
实施例2
一种终端设备,包括处理器和计算机可读存储介质,处理器用于实现各指令;计算机可读存储介质用于存储多条指令,所述指令适于由处理器加载并执行所述的一种基于图像序列的废钢斗号码识别方法
以上均为本发明的较佳实施例,并非依此限制本发明的保护范围,故:凡依本发明的结构、形状、原理所做的等效变化,均应涵盖于本发明的保护范围之内。