一种多头注意力和图谱嵌入算法融合的类案推荐方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于人工智能技术领域,具体涉及一种多头注意力和图谱嵌入算法融合的类案推荐方法。
背景技术
随着大数据、人工智能等新一代信息技术的发展,海量数据的系统化分析已成为一项重要课题,也是这一领域的未来的发展趋势。
为实现类案类判,就需要计算案件之间的相似度。案件面向的数据量庞大,且案件信息错综复杂,一个案件的案情信息可能贯穿整个案件内容,这就导致案件相似度计算难度加大,传统基于文本内容语义的类案推荐方法难以全面捕捉到整个案件信息特征,公告号为CN113688635A的中国发明专利公开了一种基于语义相似度的类案推荐方法,采用文本分类算法对案件内容进行预定义类别分类,基于Transformer双向编码机制进行预训练语言模型训练,以预处理过的文书为训练数据,学习文本语义特征,将每个案件的相似度表示为所有案件类别相似度得分的平均值。这种基于Transformer双向编码机制主要学习的是文书内容特征,只能捕捉句子中较近距离的文本语义信息,无法获取案件信息中更长更全面的案件特征。特别是,对于复杂文书,案件主客体往往存在于不同段落,甚至首尾段落位置,导致这种基于文本内容语义计算的类案推荐方法很难准确计算输入案件相似度。
知识图谱可以描述海量数据中存在的实体、实体属性及关系,知识图谱将案件相关信息形成具备丰富语义及潜在语义关系的知识网络结构。在公告号为CN111858940A的中国发明专利公开了一种基于多头注意力的法律案例相似度计算方法方法,使用实体识别和关系抽取模型得到案件知识图谱,基于多头注意力机制将案件知识图谱转化为向量表示,通过深度案情感知模型计算输入案件相似度。这种单纯基于多头注意力机制的案件知识表示可以深层次挖掘案件知识特征,但忽略了案件实体与关系中隐藏的语义特征,无法全面表达一个案件知识,从而导致案件相似度计算不够准确。
发明内容
(一)要解决的技术问题
本发明要解决的技术问题是如何提供一种多头注意力和图谱嵌入算法融合的类案推荐方法,以解决传统基于文书词频统计的类案推荐方法存在的问题及现有基于图神经网络的类案推荐存在的问题。
(二)技术方案
为了解决上述技术问题,本发明提出一种多头注意力和图谱嵌入算法融合的类案推荐方法,该方法包括如下步骤:
S1、使用基于双向自编码机制的阅读理解式信息抽取模型抽取案件中所有实体及关系,构建由若干三元组组成的案件知识图谱,将案件知识图谱转换为图结构矩阵;
S2、基于知识图谱嵌入算法对三元组进行处理,同时,根据案件知识图谱和图结构矩阵,获取案件知识嵌入向量,包括:实体嵌入向量及图结构嵌入向量;
S3、基于多头注意力机制对S1中的实体、图结构矩阵进行处理,获取案件上下文特征向量,包括:实体上下文特征向量和图结构上下文特征向量;
S4、融合所述案件知识嵌入向量及案件上下文特征向量,获取案件实体表征向量和图结构表征向量;
S5、基于S1的图结构矩阵、S4获得的实体表征向量和图结构表征向量训练图卷积神经网络模型;
S6、将待查询案件和候选案件输入图卷积神经网络模型,计算查询案件与所有候选案件的相似度得分,输出最高得分对应的案件信息。
(三)有益效果
本发明提出一种多头注意力和图谱嵌入算法融合的类案推荐方法,本发明的优势在于,采用和基于多头注意力机制的上下文特征提取和图谱嵌入算法能够捕捉到文书中案件要素之间全面、复杂且非连续的依赖关系,与图卷积神经网络结合,进一步深层次提取案件知识隐藏的语义信息,最后基于AFM(Attention Factor Machine,AFM)机制添加权重参数组合向量特征,进一步优化模型训练策略,计算案件相似度得分,输出相似度得分最高案件信息。
附图说明
图1为本发明的多头注意力机制和图谱嵌入算法融合的类案推荐方法整体流程图;
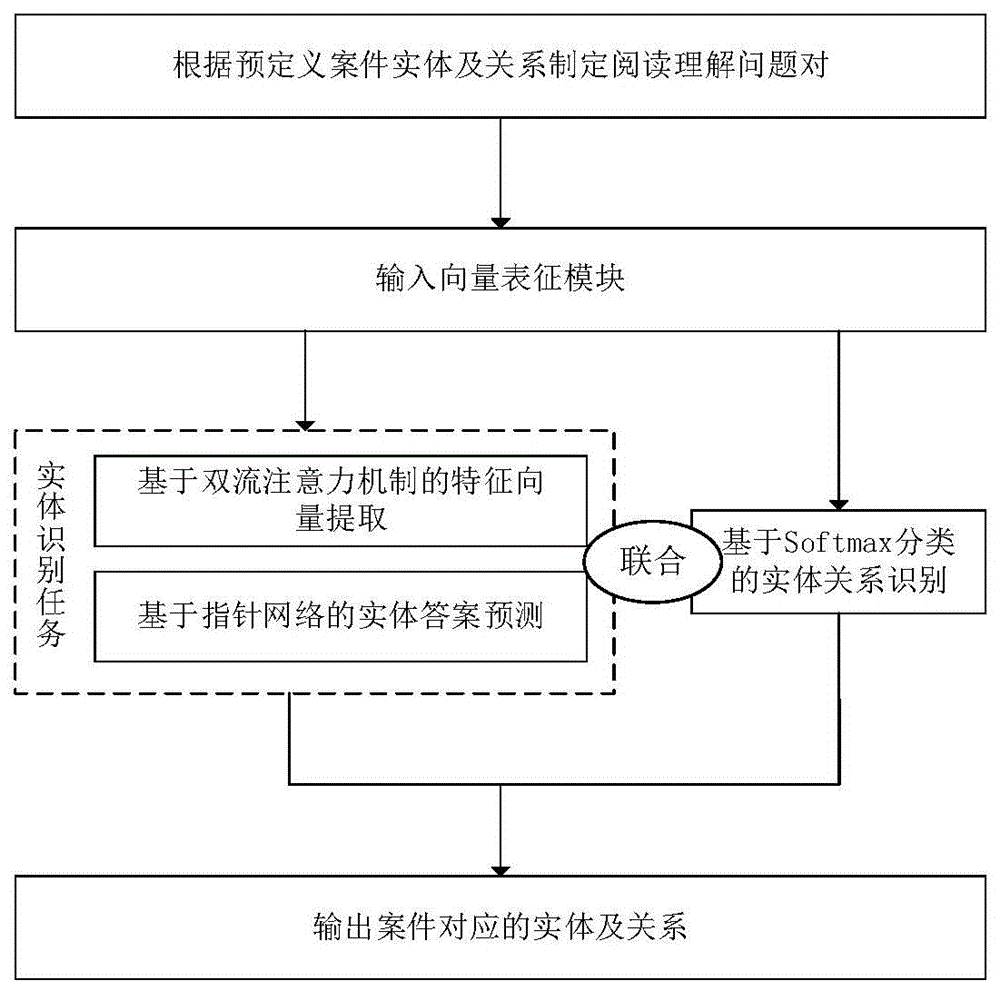
图2是本发明提供的基于双向自编码机制的阅读理解式信息抽取模型结构图;
图3是本发明提出的图卷积神经网络模型传播过程示意图;
图4是本发明提出的图卷积神经网络结构示意图。
具体实施方式
为使本发明的目的、内容和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
本发明涉及文书人工智能技术应用领域,特别提出一种多头注意力和图谱嵌入算法融合的类案推荐方法。
本发明为克服传统基于文书词频统计的类案推荐方法存在的问题及现有基于图神经网络的类案推荐存在的不足,提出一种多头注意力和图谱嵌入算法融合的图卷积神经网络的类案推荐方法,本方法对于所要查询的案件案情描述或者导入的类案件文书,可以检索出候选案件集中与查询案件文书语义相似度最高的案件。
本发明提供了一种多头注意力和图谱嵌入算法融合的类案推荐方法,具体包括:步骤一、使用基于双向自编码机制的阅读理解式信息抽取模型抽取案件中所有实体及关系,构建案件知识图谱,将其转换为案件图结构矩阵;步骤二、基于图谱嵌入算法获取所述案件实体嵌入向量及图结构嵌入向量;步骤三、基于多头注意力机制获取所述案件实体及图结构上下文特征向量;步骤四、融合所述案件实体及图结构的嵌入向量和上下文特征向量;步骤五、训练融合多头注意力机制和图谱嵌入算法的图卷积神经网络模型;步骤六、将待查询案件和候选案件输入类案推荐模型,计算查询案件与所有候选案件的相似度得分,输出最高得分对应的案件信息。本发明通过构建案件知识图谱,利用图谱嵌入算法得到实体及关系嵌入向量,与基于多头注意力机制提取的上下文特征向量融合,获取案件实体表征向量和图结构表征向量。这种方法更深层次捕获案件要素之间隐藏的关系语义信息,使得案件知识特征更为丰富。此外,使用AFM机制对图卷积网络模型训练策略进行优化,改善神经网络模型训练的过拟合问题,进一步提升类案推荐的准确度。本发明提供的模型方法在文书领域的类案推荐中取得了较好的结果。
本发明提出的一种多头注意力和图谱嵌入算法融合的图卷积神经网络的类案推荐方法,技术方案包括以下步骤:
S1、使用基于双向自编码机制的阅读理解式信息抽取模型抽取案件中所有实体及关系,构建由若干三元组组成的案件知识图谱,将案件知识图谱转换为图结构矩阵;
S2、基于知识图谱嵌入算法对三元组进行处理,同时,根据案件知识图谱和图结构矩阵,获取案件知识嵌入向量,包括:实体嵌入向量及图结构嵌入向量;
S3、基于多头注意力机制对S1中的实体、图结构矩阵进行处理,获取案件上下文特征向量,包括:实体上下文特征向量和图结构上下文特征向量;
S4、融合所述案件知识嵌入向量及案件上下文特征向量,获取案件实体表征向量和图结构表征向量;
S5、基于S1的图结构矩阵、S4获得的实体表征向量和图结构表征向量训练图卷积神经网络模型;
S6、将待查询案件和候选案件输入图卷积神经网络模型,计算查询案件与所有候选案件的相似度得分,输出最高得分对应的案件信息。
进一步地,所述S1中,使用分词、停用词过滤、特殊符号删除及关键词指代消解等预处理技术进行数据预处理,得到查询案件及候选案件样本集;使用基于双向自编码机制阅读理解式的信息抽取模型得到查询案件与候选案件样本集中存在的所有实体和关系,构建由若干三元组组成的案件知识图谱;最后使用节点关系化技术将查询案件及候选案件知识图谱转换为图结构矩阵。三元组包括:头实体、关系和尾实体。
进一步地,所述S2中,使用知识图谱嵌入算法TansE将所述案件知识三元组的实体和关系表征为低维连续空间向量。同时,根据步骤S1案件知识图谱及图结构矩阵,进一步获取案件实体嵌入向量及图结构嵌入向量。
进一步地,所述S3中,将步骤S1预处理得到查询案件和候选案件样本集输入对多头注意力机制的预训练语言模型进行微调训练,获取以字为粒度的特征向量,对实体中的字向量取均值得到实体上下文特征向量,对图结构矩阵中的字向量取均值得到图结构上下文特征向量。
进一步地,所述S4中,为了获取全面的案件知识特征,融合步骤S2案件知识嵌入向量与步骤S3案件上下文特征向量,将查询案件和候选案件相应的实体嵌入向量与实体上下文特征向量拼接得到实体表征向量,将图结构嵌入向量与图结构上下文特征向量拼接得到图结构表征向量,全面的表达案件知识特征。
进一步地,所述S5中,训练基于图卷积神经网络的案件相似度计算模型,包括输入层,图卷积网络层,损失层三模块组成。
具体包括:
S51、执行步骤S1获取训练集,即查询案件和候选案件样本集,抽取样本集案件知识图谱,将其转换为图结构矩阵,作为模型输入;
S52、依据步骤S4获取向量融合的实体表征向量和图结构表征向量,将其作为图卷积网络层输入,图卷积网络层由两个图卷积层堆叠而成,前一个图卷积层的输出作为下一个图卷积层的输入。
S53、损失层接收查询案件与每一个候选案件的表征向量,将图卷积层最后一层所有节点的隐藏层向量取均值再合并,得到案件知识图表征向量,定义损失函数拟合向量之间相似度。
进一步,为了改善神经网络模型训练存在的过拟合问题,基于注意力机制的因子分解机(Attention Factor Machine,AFM)算法构建模型损失函数,通过查询案件与候选案件表征向量融合的方式,构建自注意力网络筛选重要特征,使其对模型结果提供不同的贡献值。其表达式如下:
其中,S
其中,a
a'
其中,W∈R
进一步地,所述S6中,将查询案件和候选案件样本集输入基于图嵌入改进算法的图卷积神经网络模型,计算查询案件与所有候选案件的相似度得分,输出最高得分对应的案件信息。
实施例1:
下面对本发明提出的一种多头注意力和图谱嵌入算法融合的图卷积神经网络的类案推荐方法进行举例说明。本发明请求保护的范围包括但不限于以下实施例子。
图1为本发明实施例子中的一种多头注意力和图谱嵌入算法融合的图卷积神经网络的类案推荐方法整体流程示意图,该方法包括:
S1.使用基于双向自编码机制的阅读理解式信息抽取模型抽取案件中所有实体及关系,构建由若干三元组组成的案件知识图谱,将案件知识图谱转换为图结构矩阵;
S11、利用数据预处理技术对文书数据进行去噪处理,包括停用词过滤,特殊符号处理及脏数据清除等,得到查询案件与候选案件集合;
S12、将查询案件和所有候选案件输入基于双向自编码机制阅读理解式的信息抽取模型,得到案件对应实体及关系三元组表示。
基于双向自编码机制阅读理解式的信息抽取模型结构如图2所示,根据预定义案件实体及关系制定问题对模板,基于双向编码机制动态构建输入S向量表征,使用多层二分类网络进行实体识别任务训练,并联合Softmax多分类网络进行实体关系抽取,得到由若干三元组(头实体,关系,尾实体)组成的案件知识图谱。
S13、将案件知识图谱转换为可以表达实体关系的图网络结构,图中的节点表示两个实体间的关系。
进一步,将案件知识图谱三元组转换为图结构矩阵,即将每个实体及关系映射为数字编号,将所有实体关系映射为一个图结构矩阵,图中的节点表示案件图谱中关系对应编号。
S2.基于知识图谱嵌入算法TansE对三元组进行处理,同时,根据案件知识图谱和图结构矩阵,获取案件知识嵌入向量,包括:实体嵌入向量及图结构嵌入向量
使用知识图谱嵌入算法TansE进行所述图谱嵌入,将知识图谱中的实体集合和关系集合表示在同一空间中。假设案件三元组(h,r,t)对应的向量表示为h,r,t∈R
f
根据输入得到其对应案件的实体嵌入向量P
S3、基于多头注意力机制对S1中的实体、图结构矩阵进行处理,获取案件上下文特征向量,包括:实体上下文特征向量和图结构上下文特征向量;
将步骤S1中得到的查询案件与候选案件样本集输入基于多头注意力机制的预训练语言模型,进行模型微调,获取输入案件的字特征向量E
基于多头注意力机制的预训练语言模型采用双向Transformer作为编码器,每个编码器由多头自注意力机制和全连接前馈神经网络组成,对于一段文中的每个字向前向后直接和文本中任何一个字进行编码,使得每个字都能融合左右两边的语义。
S4、融合所述案件知识嵌入向量及案件上下文特征向量,获取案件实体表征向量和图结构表征向量;通过向量拼接方式融合知识嵌入向量和下文特征向量,得到所述查询案件和候选案件的实体表征向量H
S5.基于S1的图结构矩阵、S4获得的实体表征向量和图结构表征向量训练图卷积神经网络模型;
将所述案件实体表征向量和图结构表征向量输入图卷积神经网络的卷积层进行模型训练,提取案件多层次特征,其特征提取示意图如图3所示,包括以下步骤:
S51、执行步骤S1获取查询案件样本和候选案件样本集作为训练数据,通过抽取样本集案件知识图谱及图结构矩阵,获得模型输入;
S52、对模型输入进行图嵌入及上下文特征提取获取融合知识表征的案件实体表征向量H和图结构表征向量A,输入图卷积网络层进行案件多层次特征提取。
图卷积神经网络结构示意图如图4所示,采用两层图卷积层网络堆叠方式,将前一个卷积层的输出作为后一个卷积层的输入,并对最后一个卷积层的所有节点的隐藏层向量先取均值再合并,进一步得到查询案件及候选特征表征向量S
S53、进一步定义模型训练损失函数,动态调整损失函数与模型超参数之间的梯度,保存模型最佳状态。为了改善神经网络模型训练存在的过拟合问题,使用基于注意力机制的因子分解机(Attention Factor Machine,AFM)算法优化模型训练策略。
首先,将图卷积层网络的输出的查询案件和候选案件向量进行交互,交互方式采用向量哈达玛积运算,其表达如下:
f
其中,s
接着,对不同部分交互向量添加不同权重,基于注意力机制对交互向量加权求和,其表达式如下:
其中,a
a'
其中,W∈R
S6、将待查询案件和候选案件输入图卷积神经网络模型,计算查询案件与所有候选案件的相似度得分,输出最高得分对应的案件信息。
本发明创新点在于采用基于多头注意力机制的上下文特征提取算法和图谱嵌入算法捕捉文书中案件要素之间全面、复杂且非连续的依赖关系,获取多层次案件知识特征,使用图卷积神经网络,进一步深层次提取案件知识隐藏的语义信息,并基于AFM(AttentionFactor Machine,AFM)机制添加权重参数优化模型训练策略,从而提升案件相似度计算准确性,达到类案推荐目的。
本发明的优势在于,采用基于多头注意力机制的上下文特征提取算法和图谱嵌入算法能够捕捉到文书中案件要素之间全面、复杂且非连续的依赖关系,与图卷积神经网络结合,进一步深层次提取案件知识隐藏的语义信息,最后基于AFM(Attention FactorMachine,AFM)机制添加权重参数组合向量特征,进一步优化模型训练策略,计算案件相似度得分,输出相似度得分最高案件信息。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。