一种科研大宽表的生成方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明实施例涉及数据处理领域,尤其涉及一种科研大宽表的生成方法。
背景技术
在医疗领域中,一位患者可能进行多次就诊,在一次就诊中可能生成多张数据表(即就诊数据表或说科研数据表),而且每张数据表通常有多列。
在临床科研中,需将一位患者在多次就诊中的多张数据表转成一行后导出分析,即此时导出的宽表的列数约为
但是,现有数据库最多能支持1万余列数据的生成和导出,如EXCEL在一张数据表中仅能支持16384列,无法支持更多列的宽表(即大宽表)的生成。
发明内容
本发明实施例提供了一种科研大宽表的生成方法,解决了无法生成大宽表的问题。
根据本发明的一方面,提供了一种科研大宽表的生成方法,可以包括:
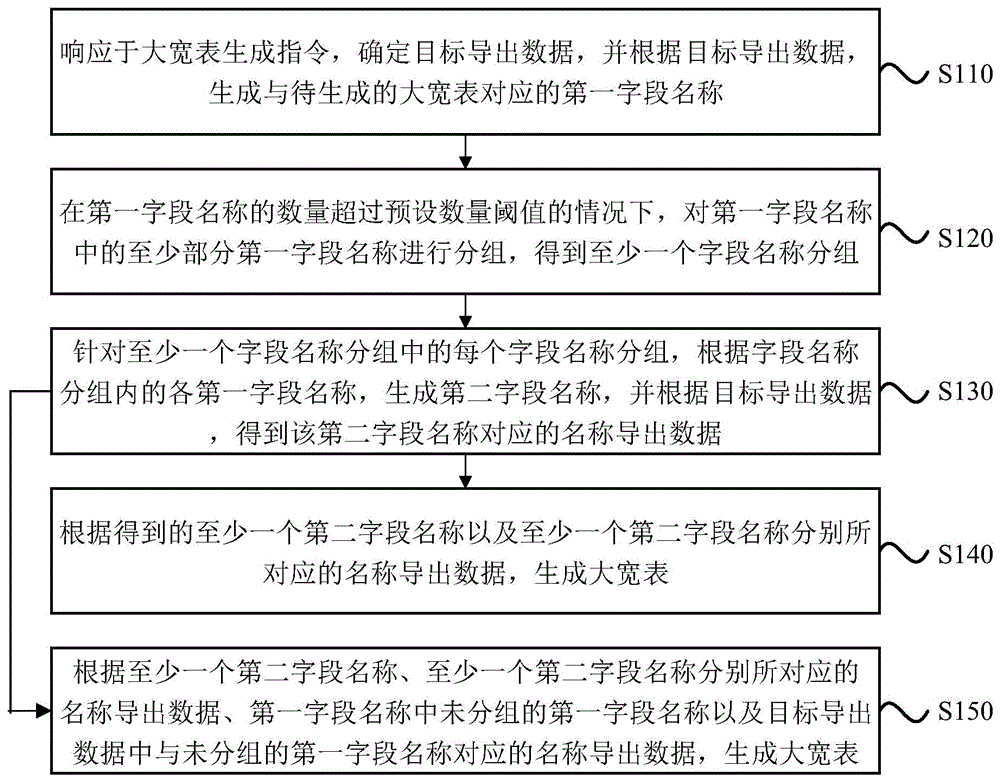
响应于大宽表生成指令,确定目标导出数据,并根据目标导出数据,生成与待生成的大宽表对应的第一字段名称;
在第一字段名称的数量超过预设数量阈值的情况下,对第一字段名称中的至少部分第一字段名称进行分组,得到至少一个字段名称分组;
针对至少一个字段名称分组中的每个字段名称分组,根据字段名称分组内的各第一字段名称,生成第二字段名称,并根据目标导出数据,得到第二字段名称对应的名称导出数据;
根据得到的至少一个第二字段名称以及至少一个第二字段名称分别所对应的名称导出数据,或者,根据至少一个第二字段名称、至少一个第二字段名称分别所对应的名称导出数据、第一字段名称中未分组的第一字段名称以及目标导出数据中与未分组的第一字段名称所对应的名称导出数据,生成大宽表。
本发明实施例中的技术方案,通过响应于大宽表生成指令,确定目标导出数据,并根据目标导出数据,生成与待生成的大宽表对应的第一字段名称;在第一字段名称的数量超过预设数量阈值的情况下,说明根据这些第一字段名称直接生成的大宽表的列数过多,无法得到支持,则可对这些第一字段名称中的至少部分第一字段名称进行分组,得到至少一个字段名称分组;进一步,针对每个字段名称分组,根据该字段名称分组内的各第一字段名称,生成第二字段名称,以减少大宽表的列数,然后根据目标导出数据,得到与该第二字段名称对应的名称导出数据;进一步,根据得到的全部第二字段名称以及它们各自对应的名称导出数据,或者,根据全部第二字段名称、它们各自对应的名称导出数据、未分组的全部第一字段名称以及它们各自对应的名称导出数据,生成大宽表。上述技术方案,通过将数量过多的第一字段名称转换为数量较少的第二字段名称,由此减少了待生成的大宽表的列数,从而实现了大宽表的有效生成。
应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或是重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例提供的一种科研大宽表的生成方法的流程图;
图2是根据本发明实施例提供的另一种科研大宽表的生成方法的流程图;
图3是根据本发明实施例提供的又一种科研大宽表的生成方法的流程图;
图4是根据本发明实施例提供的再一种科研大宽表的生成方法的流程图;
图5是根据本发明实施例提供的还一种科研大宽表的生成方法的流程图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。“目标”、“原始”等的情况类似,在此不再赘述。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
还需要说明的是,本发明的技术方案中,所涉及到的用户个人信息的采集、采集、更新、分析、处理、使用、传输、存储等方面,均符合相关法律法规的规定,被用于合法的用途,且不违背公序良俗。对用户个人信息采取必要措施,从而防止对用户个人信息数据的非法访问,维护用户个人信息安全、网络安全和国家安全。
图1是本发明实施例提供的一种科研大宽表的生成方法的流程图。本实施例可适用于生成列数较多的大宽表的情况。该方法可以由本发明实施例提供的科研大宽表的生成装置来执行,该装置可由软件和/或硬件的方式实现,该装置可以集成在电子设备上,该电子设备可以是各种用户终端或是服务器。
参见图1,本发明实施例的方法具体包括如下步骤:
S110、响应于大宽表生成指令,确定目标导出数据,并根据目标导出数据,生成与待生成的大宽表对应的第一字段名称。
其中,大宽表生成指令可理解为用于生成大宽表的指令,其可以是由科研用户根据大宽表生成需求,主动触发的指令;也可以是由电子设备根据预设的大宽表生成策略,自动触发的指令;等等,在此未做具体限定。
目标导出数据可理解是为生成大宽表而需要导出的数据,结合本发明实施例可能涉及的应用场景,可选的,该目标导出数据可以是目标导出数据表中的目标导出对象的数据,该目标导出对象可以是该目标导出数据表中包含的全部对象,也可以是符合筛选条件的部分对象,在此并未做具体限定。再可选的,目标导出数据可根据科研用户选择、筛选和确认操作进行确定。
响应于大宽表生成指令,确定与待生成的大宽表对应的目标导出数据。
进一步,根据目标导出数据,生成与大宽表对应的第一字段名称,该第一字段名称可理解是为在大宽表中呈现目标导出数据而需要涉及的字段的名称。
实际应用中,可选的,可获取预先为与目标导出数据对应的目标导出数据表绑定的第一拼接规则,然后基于第一拼接规则生成第一字段名称。
示例性的,从目标导出数据中,确定出同一目标导出数据表中、同一目标导出对象的且不同时间下的多行就诊数据,并将确定出的多行就诊数据进行行转列,生成第一字段名称。具体示例,参见表1a和表1b,表1b可理解为基于表1a所示的检验明细表生成的大宽表,其中的各第一字段名称可包括“第一次检验时间”、“第一次红细胞值”、“第一次白细胞值”,“第二次检验时间”、“第二次红细胞值”、“第二次白细胞值”,......,等等。
表1a检验明细表
表1b大宽表
再示例性的,从目标导出数据中,确定不同目标导出数据表中、同一目标导出对象的并且同一时间段内的就诊数据,并将确定出的就诊数据进行数据列拼接,生成第一字段名称,例如在目标导出数据对应的各目标导出数据表包括就诊检验表、就诊诊断表以及就诊用药表时,这时生成的各第一字段名称可以是“第一次就诊检验”、“第一次就诊诊断”、“第一次就诊用药”,“第二次就诊检验”、“第二次就诊诊断”、“第二次就诊用药”,......,“第N次......”、......等。
又示例性的,针对目标导出数据对应的目标导出数据表,将目标导出数据表中对应的列导出数据具有唯一性的列名,作为与大宽表对应的第一字段名称。其中,目标导出数据表可理解为目标导出数据来源的数据表,目标导出数据表包含一个或多个数据列,而该一个或多个数据列中的某数据列下的数据(即列导出数据)具有唯一性,例如对象标识下的列导出数据具有唯一性,那么可将这样的数据列的列名作为第一字段名称,由此便于区分不同的目标导出对象。
S120、在第一字段名称的数量超过预设数量阈值的情况下,对第一字段名称中的至少部分第一字段名称进行分组,得到至少一个字段名称分组。
其中,预设数量阈值可理解为预设的表征可生成大宽表的第一字段名称在数量上的上限,在实际应用中,可选的,其可根据现有数据库在导出大宽表时,最多支持的数据列的列数确定。获取预设数量阈值。
在第一字段名称的数量超过预设数量阈值的情况下,这说明无法基于如此多的第一字段名称生成大宽表,原因在于待生成的大宽表的列数过多。因此,为了有效生成大宽表,可通过减少大宽表的列数来实现。
具体的,针对上述生成的全部第一字段名称,对该全部第一字段名称中的至少部分(即部分或是全部)第一字段名称进行分组,得到至少一个字段名称分组。可以理解的是,每个字段名称分组中的第一字段名称的数量可以是一个或多个,各个字段名称分组中的第一字段名称的数量可能相同或不同,这均与实际情况有关,在此未做具体限定。另外,结合本发明实施例可能涉及的应用场景,可选的,针对每个第一字段名称,是否需对该第一字段名称进行分组,可根据该第一字段名称是否包含预设分组字符(例如“第一”和“第二”等)确定;还可根据该第一字段名称是否包含预设非分组字符(例如“性别”等)确定;当然,也可通过其余方式确定,在此未做具体限定。
S130、针对至少一个字段名称分组中的每个字段名称分组,根据字段名称分组内的各第一字段名称,生成第二字段名称,并根据目标导出数据,得到该第二字段名称对应的名称导出数据。
其中,本步骤针对至少一个字段名称分组中的每个字段名称分组分别进行处理。具体的,针对任一字段名称分组,根据该字段名称分组内的各第一字段名称,生成第二字段名称,由此可将该字段名称分组内的一个或多个第一字段名称,替换为一个第二字段名称,达到了减少大宽表的列数的目的。
示例性的,在该字段名称分组内的第一字段名称的数量是一个的情况下,可将该第一字段名称直接作为第二字段名称,由此可快速得到第二字段名称。
再示例性的,在该字段名称分组内的第一字段名称的数量是至少两个的情况下,按照预设顺序和预设分隔符,对至少两个第一字段名称进行拼接,生成第二字段名称。其中,预设顺序可理解为预先设置的表征各第一字段名称在拼接时的先后顺序,结合本发明实施例可能涉及的应用场景,例如可以是“第一”和“第二”。当然,也可以是其余的拼接顺序,在此未做具体限定。预设分隔符可理解为预先设置的用于分隔各第一字段名称的符号,例如可以是“;”、“&”或“/”等,在此未做具体限定。按照预设顺序和预设分隔符,拼接各第一字段名称,生成第二字段名称,这样的第二字段名称可表征出原始的第一字段名称,可读性较强,便于科研用户理解。
在生成第二字段名称之后,进一步,根据与待生成的大宽表这个整体对应的目标导出数据,得到与该第二字段名称对应的名称导出数据,即需填写在该第二字段名称所在的数据列中的数据。
示例性的,在该字段名称分组内的第一字段名称的数量是一个的情况下,可将目标导出数据中的与该第一字段名称对应的名称导出数据,直接作为与该第二字段名称对应的名称导出数据。
再示例性的,在该字段名称分组内的第一字段名称的数量是至少两个的情况下,可根据目标导出数据,得到至少两个第一字段名称分别对应的名称导出数据;按照预设顺序及预设分隔符,对至少两个第一字段名称分别对应的名称导出数据进行拼接,得到第二字段名称对应的名称导出数据。在实际应用中,可选的,在针对各第一字段名称进行拼接时采用的预设顺序,与在针对各第一字段名称分别对应的名称导出数据进行拼接时采用的预设顺序,可相同或不同,尤其可以相同,这便于科研用户理解。预设分隔符同理,在此不再赘述。
S140、根据得到的至少一个第二字段名称以及至少一个第二字段名称分别所对应的名称导出数据,生成大宽表。
其中,根据得到的全部第二字段名称以及各第二字段名称分别对应的名称导出数据,生成大宽表。
示例性的,根据表2a和表2b得到的第一字段名称包括“第一次检验时间”、“第一次红细胞值”、“第一次白细胞值”,“第二次检验时间”、“第二次红细胞值”、“第二次白红细胞值”,“检验对象”以及“性别”。将“第一次检验时间”和“第二次检验时间”划分到同一字段名称分组,由此生成的第二字段名称为“第一次检验时间;第二次检验时间”。白细胞值和红细胞值的处理过程类似,在此不再赘述。另外,将“检验对象”划分为一个字段名称分组,由此生成的第二字段名称是“检验对象”。“性别”的处理过程类似,在此不再赘述。然后,根据这些第二字段名称以及各自对应的名称导出数据,生成表2c所示的大宽表。
表2a基本信息表
表2b检验明细表
表2c大宽表
S150、根据至少一个第二字段名称、至少一个第二字段名称分别所对应的名称导出数据、第一字段名称中未分组的第一字段名称以及目标导出数据中与未分组的第一字段名称对应的名称导出数据,生成大宽表。
其中,在存在未分组的第一字段名称的情况下,可根据全部第二字段名称、这些第二字段名称各自对应的名称导出数据、未分组的全部第一字段名称以及这些第一字段名称分别对应的名称导出数据,生成大宽表。
需要说明的是,S140和S150根据实际情况,择一执行,例如在针对全部第一字段名称进行分组时,可通过执行S140生成大宽表;再如在针对部分第一字段名称进行分组时,可通过执行S150生成大宽表。
本发明实施例中的技术方案,通过响应于大宽表生成指令,确定目标导出数据,并根据目标导出数据,生成与待生成的大宽表对应的第一字段名称;在第一字段名称的数量超过预设数量阈值的情况下,说明根据这些第一字段名称直接生成的大宽表的列数过多,无法得到支持,则可对这些第一字段名称中的至少部分第一字段名称进行分组,得到至少一个字段名称分组;进一步,针对每个字段名称分组,根据该字段名称分组内的各第一字段名称,生成第二字段名称,以减少大宽表的列数,然后根据目标导出数据,得到与该第二字段名称对应的名称导出数据;进一步,根据得到的全部第二字段名称以及它们各自对应的名称导出数据,或者,根据全部第二字段名称、它们各自对应的名称导出数据、未分组的全部第一字段名称以及它们各自对应的名称导出数据,生成大宽表。上述技术方案,通过将数量过多的第一字段名称转换为数量较少的第二字段名称,由此减少了待生成的大宽表的列数,从而实现了大宽表的有效生成。
一种可选的技术方案,上述的科研大宽表的生成方法,还包括:
在第一字段名称的数量未超过预设数量阈值的情况下,针对每个第一字段名称,根据目标导出数据,得到第一字段名称对应的名称导出数据;
根据各个第一字段名称以及各个第一字段名称分别对应的名称导出数据,生成大宽表。
换言之,在第一字段名称的数量未超过预设数量阈值的情况下,这说明可基于这么多的第一字段名称生成大宽表,则根据目标导出数据,得到各个第一字段名称分别所对应的名称导出数据,然后再基于这些第一字段名称以及它们各自对应的名称导出数据,生成大宽表。
示例性的,根据表3a和表3b得到的第一字段名称包括“第一次检验时间”、“第一次红细胞值”,“第二次检验时间”、“第二次红细胞值”,“检验对象”以及“性别”,这些第一字段名称的数量未超过预设数量阈值,因此可根据它们以及它们各自对应的名称导出数据,生成表3c所示的大宽表。
表3a基本信息表
表3b检验明细表
表3c大宽表
图2是本发明实施例中提供的另一种科研大宽表的生成方法的流程图。本实施例以上述各技术方案为基础进行优化。本实施例中,可选的,对第一字段名称中的至少部分第一字段名称进行分组,得到至少一个字段名称分组,包括:针对第一字段名称中的至少部分第一字段名称中的每个第一字段名称,获取第一字段名称的属性信息,其中,属性信息包括来源属性和/或数据属性;根据至少部分第一字段名称分别对应的属性信息,对至少部分第一字段名称进行分组,得到至少一个字段名称分组。其中,与上述各实施例相同或相应的术语的解释在此不再赘述。
参见图2,本实施例的方法具体可以包括如下步骤:
S210、响应于大宽表生成指令,确定目标导出数据,并根据目标导出数据,生成与待生成的大宽表对应的第一字段名称。
S220、在第一字段名称的数量超过预设数量阈值的情况下,针对第一字段名称中的至少部分第一字段名称中的每个第一字段名称,获取第一字段名称的属性信息,其中,属性信息包括来源属性和/或数据属性。
其中,属性信息可用于描述第一字段名称的属性,在本发明实施例中,可用于描述第一字段名称的来源属性和/或数据属性。
其中,来源属性可表征第一字段名称的具体来源,结合本发明实施例可能涉及到的应用场景,例如可以是来源的目标导出数据表、目标导出对象、目标导出字段以及目标导出时间等中的至少一个。
数据属性可表征第一字段名称对应的名称导出数据是否具有唯一性,例如对象标识对应的名称导出数据具有唯一性,而诊断对应的名称导出数据不具有唯一性。
S230、根据至少部分第一字段名称分别对应的属性信息,对至少部分第一字段名称进行分组,得到至少一个字段名称分组。
其中,上文阐述的至少部分第一字段名称是全部第一字段名称中存在分组需求的第一字段名称,因此可根据这些第一字段名称分别对应的属性信息,对它们进行分组,从而得到至少一个字段名称分组。
示例性的,在属性信息是来源属性时,可根据至少部分第一字段名称分别对应的来源属性,确定至少部分第一字段名称中在将同一目标导出数据表中、同一目标导出对象的、同一目标导出字段下且不同时间(即不同目标导出时间)的多行就诊数据进行行转列之后生成的第一字段名称,然后将确定出的一个或多个第一字段名称划分至同一字段名称分组,以得到至少一个字段名称分组。
再示例性的,在属性信息是来源属性时,根据至少部分第一字段名称分别对应的来源属性,确定至少部分第一字段名称中与不同目标导出数据表中、同一目标导出对象的、不同目标导出字段下并且在同一时间段(即同一目标导出时间段)内存在关联的就诊数据有关的第一字段名称,然后将确定出的一个或多个第一字段名称划分至同一字段名称分组,以得到至少一个字段名称分组。例如,将检验明细表中的诊断与医生诊断表中的诊断划分到同一字段名称分组。
再示例性的,在属性信息是数据属性时,根据至少部分第一字段名称分别对应的数据属性,确定至少部分第一字段名称中对应的名称导出数据具有唯一性的第一字段名称,并将确定出的各第一字段名称划分到不同的字段名称分组,以得到至少一个字段名称分组。即为对应的名称导出数据具有唯一性的各第一字段名称,分别分配一个字段名称分组。
当然,还可根据属性信息,通过其余方式,划分字段名称分组,在此未做具体限定。
S240、针对至少一个字段名称分组中的每个字段名称分组,根据字段名称分组内的各第一字段名称,生成第二字段名称,并根据目标导出数据,得到该第二字段名称对应的名称导出数据。
S250、根据得到的至少一个第二字段名称以及至少一个第二字段名称分别所对应的名称导出数据,生成大宽表。
S260、根据至少一个第二字段名称、至少一个第二字段名称分别所对应的名称导出数据、第一字段名称中未分组的第一字段名称以及目标导出数据中与未分组的第一字段名称对应的名称导出数据,生成大宽表。
本发明实施例的技术方案,通过第一字段名称的属性信息来划分字段名称分组,由此实现了字段名称分组的准确划分。
图3是本发明实施例中提供的又一种科研大宽表的生成方法的流程图。本实施例以上述各技术方案为基础进行优化。在本实施例中,可选的,在生成大宽表之后,上述科研大宽表的生成方法,还包括:针对至少一个字段名称分组中具有至少两个第一字段名称的目标分组,根据目标分组内的各第一字段名称以及对应的名称导出数据,生成与第三字段名称对应的分表,其中,第三字段名称为大宽表中的至少一个第二字段名称中与目标分组对应的第二字段名称;或者,针对大宽表中的至少一个第二字段名称中与至少两个第一字段名称对应的第三字段名称,对第三字段名称及第三字段名称所对应的名称导出数据进行拆分,并根据得到的拆分结果,生成第三字段名称对应的分表。其中,与上述各实施例相同或相应的术语的解释在此不再赘述。
参见图3,本实施例的方法具体可以包括如下步骤:
S310、响应于大宽表生成指令,确定目标导出数据,并根据目标导出数据,生成与待生成的大宽表对应的第一字段名称。
S320、在第一字段名称的数量超过预设数量阈值的情况下,对第一字段名称中的至少部分第一字段名称进行分组,得到至少一个字段名称分组。
S330、针对至少一个字段名称分组中的每个字段名称分组,根据字段名称分组内的各第一字段名称,生成第二字段名称,并根据目标导出数据,得到该第二字段名称对应的名称导出数据。
S340、根据得到的至少一个第二字段名称以及至少一个第二字段名称分别所对应的名称导出数据,生成大宽表。
S350、根据至少一个第二字段名称、至少一个第二字段名称分别所对应的名称导出数据、第一字段名称中未分组的第一字段名称以及目标导出数据中与未分组的第一字段名称对应的名称导出数据,生成大宽表。
S360、针对至少一个字段名称分组中的具有至少两个第一字段名称的目标分组,根据目标分组内的各第一字段名称以及对应的名称导出数据,生成与第三字段名称对应的分表,其中,第三字段名称为大宽表中的至少一个第二字段名称中与目标分组对应的第二字段名称。
其中,目标分组可理解为全部字段名称分组中具有至少两个第一字段名称的字段名称分组。从全部字段名称分组中获取目标分组,然后根据该目标分组内的各第一字段名称以及这些第一字段名称分别对应的名称导出数据,生成与第三字段名称对应的分表,该第三字段名称可理解为大宽表中的根据这些第一字段名称生成的第二字段名称,即与该目标分组对应的第二字段名称。
S370、针对大宽表中的至少一个第二字段名称中与至少两个第一字段名称对应的第三字段名称,对第三字段名称及第三字段名称对应的名称导出数据进行拆分,并根据得到的拆分结果,生成与第三字段名称对应的分表。
其中,第三字段名称可理解为大宽表内全部第二字段名称中根据至少两个第一字段名称生成的第二字段名称。对第三字段名称以及对应的名称导出数据,分别进行拆分,从而可根据拆分后得到的各第一字段名称以及它们分别对应的名称导出数据,生成第三字段名称对应的分表,例如可按照预设顺序依次排列各第一字段名称以及它们分别对应的名称导出数据,从而生成分表。
可以理解的是,在生成第三字段名称对应的分表时,S360和S370,可根据实际情况择一执行,在此未做限定。
示例性的,这里以表2c所示的大宽表为例,针对基于“第一次检验时间”和“第二次检验时间”得到的目标分组,与该目标分组对应的分表如表4所示:
表4分表
本发明实施例的技术方案,针对大宽表内的各第二字段名称中对应于至少两个第一字段名称的第三字段名称,生成该第三字段名称对应的分表,这有助于与该第三字段名称对应的各名称导出数据的展示。
一种可选的技术方案,上述的科研大宽表的生成方法,还包括:
响应于针对第三字段名称的第一展开操作,基于预设展示方式,展示分表,其中,预设展示方式包括弹窗、新页面或是新表格。
其中,第一展开操作可理解为针对大宽表中的第三字段名称输入的,用于展示该第三字段名称对应的分表的操作。响应于第一展开操作,基于预设展示方式,展示分表,该预设展示方式例如可以是弹窗、新页面或是新表格等。
上述技术方案,实现了与该第三字段名称对应的各个名称导出数据的展示。
另一种可选的技术方案,上述的科研大宽表的生成方法,还包括:
响应于针对第三字段名称的第二展开操作,基于分表中的分表字段名称以及对应的名称导出数据,替换大宽表中的第三字段名称以及第三字段名称对应的名称导出数据,并对得到的第一替换宽表进行展示。
其中,第二展开操作可理解为针对大宽表中的第三字段名称输入的,用于基于该第三字段名称对应的分表中的相关内容,替换大宽表中的与该第三字段名称对应的相关内容,并进行展示的操作。响应于第二展开操作,基于分表中的分表字段名称,替换大宽表中的该第三字段名称,以及,基于分表中的与该分表字段名称对应的名称导出数据,替换大宽表中的与该第三字段名称对应的名称导出数据,得到第一替换宽表,并对第一替换宽表进行展示。
示例性的,这里以表2c展示的大宽表以及表4展示的分表为例,基于这二者得到的第一替换宽表,如表5所示:
表5第一替换宽表
上述技术方案,将分表中的相关内容替换并展示于大宽表中,这使得科研用户可在一张表中同时浏览到全局数据(即大宽表中的全部数据)及重点数据(即重点关注的第三字段名称对应的数据),便捷性较好。
图4是本发明实施例中提供的再一种科研大宽表的生成方法的流程图。本实施例以上述各技术方案为基础进行优化。本实施例中,可选的,在根据字段名称分组内的各第一字段名称,生成第二字段名称之后,上述的科研大宽表的生成方法,还包括:针对得到的至少一个第二字段名称构建名称标识映射表,其中,名称标识映射表中记录有与至少一个第二字段名称分别对应的字段标识;根据得到的至少一个第二字段名称及至少一个第二字段名称分别所对应的名称导出数据,生成大宽表,可包括:根据名称标识映射表,从名称标识映射表中确定与至少一个第二字段名称分别对应的至少一个字段标识的映射关系;根据映射关系、至少一个字段标识及与至少一个第二字段名称分别对应的名称导出数据,生成大宽表。其中,与上述各实施例相同或相应的术语的解释在此不再赘述。
参见图4,本实施例的方法具体可以包括如下步骤:
S410、响应于大宽表生成指令,确定目标导出数据,并根据目标导出数据,生成与待生成的大宽表对应的第一字段名称。
S420、在第一字段名称的数量超过预设数量阈值的情况下,对第一字段名称中的至少部分第一字段名称进行分组,得到至少一个字段名称分组。
S430、针对至少一个字段名称分组中的每个字段名称分组,根据字段名称分组内的各第一字段名称,生成第二字段名称,并根据目标导出数据,得到该第二字段名称对应的名称导出数据。
S440、针对得到的至少一个第二字段名称构建出名称标识映射表,其中,名称标识映射表中记录有与至少一个第二字段名称分别对应的字段标识。
其中,针对全部第二字段名称以及它们各自对应的字段标识,构建出名称标识映射表,从而将第二字段名称与相应的字段标识绑定。换言之,名称标识映射表中记录有各第二字段名称与各字段标识之间的映射关系,后续根据名称标识映射表可得到每个字段标识分别表征的第二字段名称。
S450、根据名称标识映射表,从名称标识映射表中确定与至少一个第二字段名称分别对应的至少一个字段标识的映射关系,并根据映射关系、至少一个字段标识以及与至少一个第二字段名称分别对应的名称导出数据,生成大宽表。
其中,实际应用中,有些数据库对数据表中的字段名称的字符长度有限制,例如MySQL允许的字符长度在64个字符以内,而Oracle允许的字符长度在30个字符以内,这些通常是由相应的数据库管理系统预先设定。
在此基础上,考虑到相较于第二字段名称,尤其是上述示例中给出的通过拼接得到的第二字段名称,与第二字段名称对应的字段标识的字符长度更短,因此为了避免出现因为第二字段名称的字符长度过长而无法生成大宽表的情况,在数据库层面,可基于字段标识生成大宽表。
具体的,根据名称标识映射表,得到各第二字段名称与各字段标识之间的映射关系,由此可根据映射关系、各字段标识以及各第二字段名称分别对应的名称导出数据,生成大宽表。
S460、根据至少一个第二字段名称、至少一个第二字段名称分别所对应的名称导出数据、第一字段名称中未分组的第一字段名称以及目标导出数据中与未分组的第一字段名称对应的名称导出数据,生成大宽表。
其中,S460生成大宽表的实现过程,可参见S440和S450,在此不再赘述。
可以理解的是,S440和S450,与,S460,可根据实际情况择一执行,例如在针对全部第一字段名称进行分组时,可通过执行S440和S450生成大宽表;再如在针对部分第一字段名称进行分组时,可通过执行S460生成大宽表。
本发明实施例的技术方案,通过构建可表征各第二字段名称与各字段标识之间的映射关系的名称标识映射表,从而可利用名称标识映射表,生成基于各字段标识表示的大宽表,由此可有效避免出现因第二字段名称的字符长度过长而无法生成大宽表的情况。
一种可选的技术方案,上述的科研大宽表的生成方法,还包括:
响应于针对大宽表的展示操作,根据名称标识映射表,获取大宽表中的每个字段标识分别对应的第二字段名称;
根据获取到的至少一个第二字段名称,替换大宽表中的至少一个字段标识,并对得到的第二替换宽表进行展示。
其中,展示操作可理解为针对大宽表输入的用于展示大宽表的操作。由于数据库层面的大宽表通过字段标识进行表示,但是字段标识并非是科研用户可快速理解的内容,因此在展示大宽表之前,可根据名称标识映射表,查询获取大宽表中的各字段标识分别对应的第二字段名称,然后基于这些第二字段名称分别替换大宽表中相应的字段标识,得到并展示第二替换宽表,从而方便科研用户对于大宽表的阅读与理解。
图5是本发明实施例中提供的还一种科研大宽表的生成方法的流程图。本实施例以上述各技术方案为基础进行优化。在本实施例中,可选的,在生成大宽表之后,上述的科研大宽表的生成方法,还包括:针对大宽表中的至少一个第二字段名称中的与至少两个第一字段名称对应的第四字段名称,响应于分析确认操作,根据大宽表中的至少一个第二字段名称的数量、第四字段名称对应的第一字段名称的数量以及预设数量阈值,对第四字段名称和第四字段名称对应的名称导出数据进行展开;或者,根据至少一个第二字段名称的数量与未分组的第一字段名称的数量之和、第四字段名称对应的第一字段名称的数量以及预设数量阈值,对第四字段名称和第四字段名称对应的名称导出数据进行展开。其中,与上述各实施例相同或相应的术语的解释在此不再赘述。
参见图5,本实施例的方法具体可以包括如下步骤:
S510、响应于大宽表生成指令,确定目标导出数据,并根据目标导出数据,生成与待生成的大宽表对应的第一字段名称。
S520、在第一字段名称的数量超过预设数量阈值的情况下,对第一字段名称中的至少部分第一字段名称进行分组,得到至少一个字段名称分组。
S530、针对至少一个字段名称分组中的每个字段名称分组,根据字段名称分组内的各第一字段名称,生成第二字段名称,并根据目标导出数据,得到该第二字段名称对应的名称导出数据。
S540、根据得到的至少一个第二字段名称以及至少一个第二字段名称分别所对应的名称导出数据,生成大宽表。
S550、根据至少一个第二字段名称、至少一个第二字段名称分别所对应的名称导出数据、第一字段名称中未分组的第一字段名称以及目标导出数据中与未分组的第一字段名称对应的名称导出数据,生成大宽表。
S560、针对大宽表中的至少一个第二字段名称中与至少两个第一字段名称对应的第四字段名称,响应于分析确认操作,根据大宽表中的至少一个第二字段名称的数量、第四字段名称对应的第一字段名称的数量以及预设数量阈值,对第四字段名称和第四字段名称对应的名称导出数据进行展开。
其中,第四字段名称可理解为全部第二字段名称中的对应于至少两个第一字段名称的第二字段名称。分析确认操作可理解为针对第四字段名称输入的,表征确认分析第四字段名称的操作。示例性的,可在大宽表中第四字段名称所表征的第四字段附近设置展开选项,该展开选项用于将第四字段名称,展开为相应的第一字段名称,以及将第四字段名称对应的名称导出数据,展开为相应的第一字段名称对应的名称导出数据。在此基础上,进一步,可将用于触发该展开选项的操作,作为分析确认操作。
根据上文阐述可知,预设数量阈值表征数据库针对数据列最多支持的列数,这意味着如果展开第四字段名称会导致大宽表的列数超过预设数量阈值,那么这一展开操作无法得到支持。因此,在响应分析确认操作时,可根据全部第二字段名称的数量、第四字段名称对应的第一字段名称的数量以及预设数量阈值,确定是否可展开第四字段名称,并在是的情况下,对第四字段名称和第四字段名称对应的名称导出数据进行展开,以便科研用户针对展开结果进行分析。
示例性的,在(预设数量阈值-全部第二字段名称的数量)≥第四字段名称所对应的第一字段名称的数量的情况下,展开第四字段名称之后的列数最多是全部第二字段名称的数量+第四字段名称对应的第一字段名称的数量,这≤预设数量阈值,即这时的大宽表可得到数据库支持,因此确定可展开第四字段名称。需要说明的是,上述阐述“最多是”的原因是,若展开第四字段名称之后得到的各第一字段名称会替换掉第四字段名称,那么展开第四字段名称之后的列数是全部第二字段名称的数量+第四字段名称对应的第一字段名称的数量-1。
S570、响应于分析确认操作,根据至少一个第二字段名称的数量与未分组的第一字段名称的数量之和、第四字段名称所对应的第一字段名称的数量以及预设数量阈值,对第四字段名称和第四字段名称对应的名称导出数据进行展开。
其中,S570展开第四字段名称的实现过程,与S560类似,在此不再赘述。
可以理解的是,在响应于分析确认操作时,S560和S570,可根据实际情况择一执行。
本发明实施例的技术方案,通过在第四字段名称展开后的大宽表的列数可得到支持的情况下,对第四字段名称以及对应的名称导出数据进行展开,以便科研用户可基于得到的展开结果进行进一步分析。
在此基础上,一种可选的技术方案,对第四字段名称和第四字段名称对应的名称导出数据进行展开,包括:
将第四字段名称拆分为与第四字段名称对应的至少两个第一字段名称,并将第四字段名称对应的名称导出数据拆分为与至少两个第一字段名称分别对应的名称导出数据;
在大宽表中的第四字段名称位置处,插入与至少两个第一字段名称的数量对应的空白列,并将拆分得到的至少两个第一字段名称以及至少两个第一字段名称分别对应的名称导出数据,插入空白列中;
删除大宽表中与第四字段名称对应的数据列。
其中,根据上文阐述可知,由于第四字段名称基于至少两个第一字段名称拼接得到,因此拆分第四字段名称,例如可基于拼接时应用的预设顺序和预设分隔符拆分第四字段名称,从而达到展开第四字段名称的目的。第四字段名称对应的名称导出数据的展开过程类似,在此不再赘述。
进一步,根据拆分出的第一字段名称的数量,在大宽表中的第四字段名称位置处,或是说第四字段名称表征的第四字段位置处,插入相应数量的空白列,从而可将拆分出的第一字段名称和名称导出数据,填写至空白列内,并删除大宽表中与第四字段名称对应的数据列。
示例性的,以表2c所示大宽表为例,在第四字段名称是“第一次检验时间;第二次检验时间”的情况下,展开后的大宽表如表5所示。
上述技术方案,于大宽表中展开第四字段名称以及对应的名称导出数据,这使得科研用户可在一张表中同时浏览到全局数据(即大宽表中的全部数据)以及需分析数据(即需分析的第四字段名称对应的数据),便捷性较好。
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发明中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本发明的技术方案所期望的结果,本文在此不进行限制。
上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。
- 一种基于硅藻土和硅土的多孔除磷滤料及其制备方法
- 一种硝酸化浒苔藻土在制备香烟滤棒的多孔吸附材料中的应用
- 一种硝酸化浒苔藻土在制备香烟滤棒的多孔吸附材料中的应用