一种基于循环神经网络的音乐生成和演奏方法及系统
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及音乐生成和演奏技术领域,尤其涉及一种基于循环神经网络的音乐生成和演奏方法及系统。
背景技术
音乐生成是一种利用计算机算法创作或编写新音乐的过程,它需要展现真正的创造力,而创造力取决于与音乐语言层次结构相关的各种因素。音乐生成面临着算法方法,最近,深度学习模型正被用于其他领域,例如计算机视觉。在本文中,我们希望将基于AI的音乐创作模型与人类音乐创作和创作过程之间的现有关系置于背景中;
循环神经网络(RNN)是一种能够存储序列信息的神经网络,它从前一阶段获取输入,并将其输出作为下一阶段的输入,RNN有一个重复模块,它从前一级获取输入,并将其输出作为下一级的输入,然而,RNN只能保留最近阶段的信息,因此我们的网络需要更多的内存来学习长期依赖关系,这就是长短期记忆网络(LSTMs),LSTMs是RNNs的一个特例,具有与RNNs相同的链状结构,但有不同的重复模块结构。
基于RNN的音乐生成模型通常使用NN架构,这些架构已被证明在计算机视觉或自然语言处理(NLP)等其他领域表现良好,在这些领域中还可以使用预训练的模型,可用于音乐生成,这称为迁移学习。
但是目前基于RNN的音乐生成模型存在以下几个缺点:
1、RNN模型容易出现梯度消失或梯度爆炸的问题,导致训练不稳定或难以收敛;
2、RNN模型需要大量的数据和计算资源来训练,而且训练时间较长;
3、RNN模型难以捕捉音乐中的复杂结构和长期依赖关系,导致生成的音乐缺乏多样性和连贯性;
4、RNN模型难以控制生成音乐的风格、情感和内容,导致生成的音乐缺乏个性和表达力;
而上述这些缺点主要是由于RNN模型的设计和原理所限制:
1.1、RNN模型通过反向传播算法来更新参数,但是当序列长度较长时,梯度会随着时间步长而衰减或增大,导致梯度消失或梯度爆炸的问题;
1.2、RNN模型需要对每个时间步长进行计算和存储,因此当序列长度较长时,会占用大量的内存和计算资源,并且无法并行化处理;
1.3、RNN模型通过隐藏状态来传递信息,但是隐藏状态的容量有限,并且会随着时间步长而遗忘旧信息,导致难以捕捉音乐中的复杂结构和长期依赖关系;
1.4、RNN模型通过概率分布来生成音符,但是概率分布的参数是由数据决定的,并不容易受到外部条件的影响,导致难以控制生成音乐的风格、情感和内容。
发明内容
本发明的一个目的在于提出一种基于循环神经网络的音乐生成和演奏方法及系统,本发明能够利用循环神经网络来生成具有多样性、连贯性、个性和表达力的音乐,并且能够根据用户的需求和喜好来调整音乐的风格、情感和内容,从而提高了音乐生成的质量和用户满意度,且采用了音乐风格提取模块和音乐情感识别模块,能够从音乐数据中提取音乐风格和情感的特征,并将其编码为向量或矩阵,从而增加了音乐生成的多样性和个性,其次采用了改进的LSTM网络,能够利用注意力机制和条件机制来生成音乐内容,从而增加了音乐生成的连贯性和表达力,并且采用了音乐后处理模块和音乐演奏模块,能够将生成的音乐内容转换为适合播放或保存的格式,并根据用户的选择来演奏或保存生成的音乐,从而增加了音乐生成的实用性和可操作性。
根据本发明实施例的一种基于循环神经网络的音乐生成和演奏方法,具体包括以下步骤:
S1、将原始音乐数据通过音乐数据预处理模块转换为RNN可接受的输入格式,并将其存储在数据库中;
S2、从数据库中选择音乐数据作为训练集,通过音乐风格提取模块和音乐情感识别模块,提取训练集中音乐的风格和情感特征,将其编码为向量和矩阵,同时,将训练集中的音乐数据作为目标输出;
S3、使用训练集中的音乐数据和相应的特征向量和矩阵,通过音乐内容生成模块训练改进的长短时记忆网络LSTM,并使用目标输出作为监督信号,计算损失函数并更新网络参数;
S4、接收用户的输入条件,并将其转换为相应的特征向量和矩阵,使用这些特征向量和矩阵作为条件输入,通过已训练好的LSTM网络生成相应的音乐内容;
S5、将生成的音乐内容通过音乐后处理模块转换为适合播放以及保存的格式,并将其存储在数据库中;
S6、根据用户的选择,通过音乐演奏模块演奏以及保存生成的音乐。
优选的,所述步骤S1中将音乐数据转换为适合循环神经网络输入格式的具体步骤为:
S1.1、根据音频文件的编码格式,使用相应的解码器将其转换PCM脉冲编码调制格式,即将连续的模拟信号转换为离散的数字信号;
S1.2、对PCM格式的音频数据进行重采样,即将采样率调整为一个固定的值;
S1.3、对重采样后的音频数据进行分帧,即将音频数据分割为一系列固定长度的帧,每个帧之间有一定的重叠;
S1.4、对每个帧进行窗函数处理,即将每个帧乘以一个窗函数,以减少帧边缘处的信号波动;
S1.5、对每个帧进行快速傅里叶变换FFT,即将每个帧从时域转换为频域,得到每个帧的幅度谱和相位谱;
S1.6、对每个帧的幅度谱进行梅尔滤波器组处理,即将每个帧的幅度谱乘以一组三角形滤波器,得到每个帧的梅尔频谱;
S1.7、对每个帧的梅尔频谱进行对数处理,即将每个帧的梅尔频谱取对数,得到每个帧的梅尔倒谱;
S1.8、对每个帧的梅尔倒谱进行离散余弦变换DCT,即将每个帧的梅尔倒谱从频域转换为倒谱域,得到每个帧的梅尔频率倒谱系数MFCC。
优选的,所述步骤S3中改进的LSTM网络生成相应音乐内容的具体步骤为:
S3.1、将用户的输入条件转换为特征向量和矩阵;
S3.2、将特征向量和矩阵作为输入,使用改进的长短期记忆网络LSTM来生成音乐内容,所述改进的LSTM网络在每个时间步长增加了一个注意力机制,用于关注与当前输出相关的输入信息,并增加了一个条件机制,用于根据用户的输入条件来调整输出概率分布;
S3.3、将改进的LSTM网络的输出序列作为音乐内容,根据需要转换为音符序列以及MIDI文件,所述音符序列是一种表示音乐数据的简单格式,每个音符由音高、时值和力度组成,所述MIDI文件是一种表示音乐数据的标准格式,每个音符由音高、时值、力度和乐器信息组成。
优选的,所述S4中通过已训练好的LSTM网络生成相应的音乐内容具体步骤包括:
S4.1、将用户的输入条件转换为相应的特征向量和矩阵,使用预训练的词嵌入模型将文本条件转换为向量,使用预训练的分类模型将音频条件转换为向量;
S4.2、使用这些特征向量和矩阵作为条件输入,通过已训练好的LSTM网络生成相应的音乐内容,从而根据用户的输入条件生产符合用户需求和喜好的音乐内容;
S4.3、将生成的音符序列以及MIDI文件作为音乐内容输出。
一种基于循环神经网络的音乐生成和演奏系统,其特征在于,具体包括:
音乐数据预处理模块,所述音乐数据预处理模块用于将原始音乐数据转换为适合RNN输入的格式,包括数据归一化、序列划分和特征提取;
音乐风格提取模块,所述音乐风格提取模块从音乐数据中提取音乐风格的特征,并将其编码为向量和矩阵;
音乐情感识别模块,从音乐数据中识别音乐情感的类别,并将其编码为向量和矩阵;
音乐内容生成模块,所述音乐内容生成模块根据用户的输入条件生成音乐内容,其中所述生成模块采用改进的LSTM网络,该网络在每个时间步增加了一个注意力机制和一个条件机制;
音乐后处理模块,所述音乐后处理模块用于将生成的音乐内容进行音频格式转换、音符优化和音效增强,以生成适合播放以及保存的音乐;
音乐演奏模块,所述音乐演奏模块用于根据用户的选择演奏以及保存生成的音乐。
优选的,所述音乐风格提取模块通过对音乐数据进行频谱分析、节奏分析以及和弦分析,提取音乐的风格特征,并将其编码为向量和矩阵。
优选的,所述音乐情感识别模块通过对音乐数据进行情感识别算法分析,识别音乐的情感类别,并将其编码为向量和矩阵。
优选的,所述音乐内容生成模块中改进的LSTM网络由以下几个部分组成:
编码器,所述编码器用于将输入特征向量和矩阵编码为一个隐藏状态向量;
解码器,所述解码器用于根据编码器的隐藏状态向量和用户的输入条件来生成输出序列;
注意力机制,所述注意力机制用于计算解码器在每个时间步长对编码器隐藏状态向量的注意力权重,并根据权重得到一个上下文向量;
条件机制,所述条件机制用于根据用户的输入条件和上下文向量来调整解码器输出概率分布。
优选的,所述音乐演奏模块通过模拟不同乐器的演奏特性,实现对生成音乐的逼真演奏。
优选的,所述音乐数据预处理模块通过时频转换、特征提取和数据标准化,将原始音乐数据转换为适用于循环神经网络的输入格式。
本发明的有益效果是:
1、本发明利用循环神经网络来生成具有多样性、连贯性、个性和表达力的音乐,并且能够根据用户的需求和喜好来调整音乐的风格、情感和内容,从而提高了音乐生成的质量和用户满意度。
2、本发明采用了音乐风格提取模块和音乐情感识别模块,能够从音乐数据中提取音乐风格和情感的特征,并将其编码为向量或矩阵,从而增加了音乐生成的多样性和个性。
3、本发明采用了改进的LSTM网络,能够利用注意力机制和条件机制来生成音乐内容,从而增加了音乐生成的连贯性和表达力。
4、本发明采用了音乐后处理模块和音乐演奏模块,能够将生成的音乐内容转换为适合播放或保存的格式,并根据用户的选择来演奏或保存生成的音乐,从而增加了音乐生成的实用性和可操作性。
5、本发明能够实现自动化、智能化、个性化和创新化的音乐生成和演奏,从而节省了人力、时间和资源,拓展了音乐创作和欣赏的范围和可能性。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
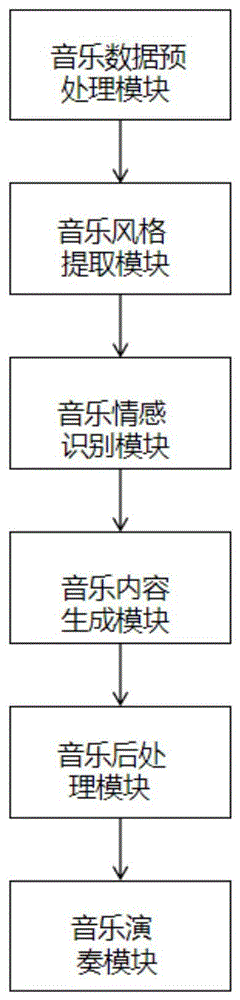
图1为本发明提出的一种基于循环神经网络的音乐生成和演奏方法及系统的系统模块结构示意图;
图2为本发明提出的一种基于循环神经网络的音乐生成和演奏方法及系统的方法流程框架结构示意图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
参考图1-2,一种基于循环神经网络的音乐生成和演奏系统,具体包括:
个音乐数据预处理模块,用于将原始的音乐数据转换为适合循环神经网络输入的格式,例如MIDI文件或音符序列。
一个音乐风格提取模块,用于从音乐数据中提取音乐风格的特征,例如节奏、和弦、旋律等,并将其编码为向量或矩阵。
一个音乐情感识别模块,用于从音乐数据中识别音乐情感的类别,例如快乐、悲伤、愤怒等,并将其编码为向量或矩阵。
一个音乐内容生成模块,用于根据用户的输入条件(例如风格、情感、主题等)来生成音乐内容,例如音符序列或MIDI文件;
其中,该模块采用了一种改进的长短期记忆网络(LSTM),在每个时间步长增加了一个注意力机制,用于关注与当前输出相关的输入信息,并增加了一个条件机制,用于根据用户的输入条件来调整输出概率分布。
一个音乐后处理模块,用于将生成的音乐内容转换为适合播放或保存的格式,例如WAV文件或MP3文件。
一个音乐演奏模块,用于根据用户的选择来演奏或保存生成的音乐。
参考图1-2,一种基于循环神经网络的音乐生成和演奏方法,具体包括:
S1、将原始的音乐数据通过音乐数据预处理模块转换为适合循环神经网络输入的格式,例如MIDI文件或音符序列,并将其存储在数据库中;
在该实施方式中,其音乐数据通过音乐数据预处理模块转换为适合循环神经网络输入的格式的具体步骤为:
S1.1、根据音频文件的编码格式,使用相应的解码器将其转换为PCM(脉冲编码调制)格式,即将连续的模拟信号转换为离散的数字信号;
其中,解码器可以使用开源的库如SoX1或ffmpeg2。
S1.2、对PCM格式的音频数据进行重采样,即将采样率调整为一个固定的值,例如22050Hz;
其中,重采样可以使用开源的库如librosa3或scipy4。
S1.3、对重采样后的音频数据进行分帧,即将音频数据分割为一系列固定长度的帧,每个帧之间有一定的重叠;
其中,分帧可以使用numpy5或librosa3等库实现。
S1.4、对每个帧进行窗函数处理,即将每个帧乘以一个窗函数,例如汉明窗或汉宁窗,以减少帧边缘处的信号波动;
其中,窗函数处理可以使用numpy5或scipy4等库实现。
S1.5、对每个帧进行快速傅里叶变换(FFT),即将每个帧从时域转换为频域,得到每个帧的幅度谱和相位谱;
其中,FFT可以使用numpy5或scipy4等库实现。
S1.6、对每个帧的幅度谱进行梅尔滤波器组处理,即将每个帧的幅度谱乘以一组三角形滤波器,得到每个帧的梅尔频谱。
其中,梅尔滤波器组可以根据人耳对不同频率敏感度的差异来设计,例如低频滤波器密集而高频滤波器稀疏;
除此之外,梅尔滤波器组处理可以使用librosa3或scipy4等库实现。
S1.7、对每个帧的梅尔频谱进行对数处理,即将每个帧的梅尔频谱取对数,得到每个帧的梅尔倒谱;
其中,对数处理可以使用numpy5或librosa3等库实现。
S1.8、对每个帧的梅尔倒谱进行离散余弦变换(DCT),即将每个帧的梅尔倒谱从频域转换为倒谱域,得到每个帧的梅尔频率倒谱系数(MFCC);
其中,DCT可以使用numpy5或scipy4等库实现。
上述步骤可以用以下公式表示:
设x[n]为PCM格式的音频数据序列,N为重采样后的采样率,M为分帧时的帧长(以采样点数计),R为分帧时的跳跃长度(以采样点数计),w[n]为窗函数序列,则第k帧x
x
设X
设A
A
设H[m]为梅尔滤波器组,K为滤波器的个数,则第k帧A
设L
L
设C
最终,将所有帧的MFCC拼接起来,得到一个矩阵,每一行代表一个帧的MFCC,每一列代表一个MFCC的维度;
需要注意的是,这个矩阵就是音乐数据的预处理结果,可以作为循环神经网络的输入。
S2、从数据库中随机抽取一部分音乐数据作为训练集,通过音乐风格提取模块和音乐情感识别模块分别提取音乐风格和情感特征,并将其编码为向量或矩阵,同时,将训练集中的音乐数据作为目标输出;
其中,音乐风格提取模块的目的是根据音乐数据的音频特征,如节奏、音高、和弦、乐器等,判断音乐属于哪种风格,例如古典、流行、摇滚等;
值得一提的是,这是一个多分类问题,可以使用深度学习的方法来解决,具体步骤如下:
S2.11、将音乐数据转换为梅尔频谱图,即将音频信号分帧、窗函数处理、快速傅里叶变换、梅尔滤波器组处理、对数处理和离散余弦变换等操作,得到一个二维矩阵,每一行代表一个帧的梅尔频率倒谱系数(MFCC),每一列代表一个MFCC的维度;
其中,梅尔频谱图可以反映音乐数据的时频特征,且具有一定的感知意义。
S2.12、将梅尔频谱图作为输入,使用卷积神经网络(CNN)来提取音乐数据的高层特征;
其中,CNN是一种具有良好特征提取能力的深度学习模型,可以自动学习音乐数据中的局部和全局特征,并将其映射到一个高维向量中;
其次,CNN的结构通常包括多个卷积层、池化层和全连接层,其中卷积层用于提取特征,池化层用于降低维度和增加不变性,全连接层用于分类。
S2.13、将CNN的输出向量作为输入,使用softmax函数来计算音乐数据属于每个风格类别的概率,并选择概率最大的类别作为最终的预测结果;
其中,softmax函数是一种归一化指数函数,可以将任意实数向量转换为一个概率分布向量,其定义如下:
其中x是输入向量,n是类别数,softmax(x)
除此之外,音乐情感识别模块的目的是根据音乐数据的音频特征和歌词特征,判断音乐所表达或引发的情感状态,例如快乐、悲伤、愤怒等;
值得一提的是,这也是一个多分类问题,可以使用深度学习的方法来解决,具体步骤如下:
S2.21、将音乐数据转换为梅尔频谱图,同上述方法相同。同时,将歌词数据转换为词向量矩阵,即将歌词分词,并使用预训练的词嵌入模型(如Word2Vec或GloVe)将每个词转换为一个低维向量,然后拼接成一个二维矩阵;
其中,词向量矩阵可以反映歌词数据的语义特征。
S2.22、将梅尔频谱图和词向量矩阵分别作为输入,使用卷积神经网络(CNN)和长短期记忆网络(LSTM)来提取音乐数据的高层特征;
其中,CNN用于提取音频特征,同上述方法相同;
其次,LSTM是一种能够处理序列数据的深度学习模型,可以捕捉歌词数据中的长期依赖关系,并将其映射到一个高维向量中;
需要注意的是,LSTM的结构包括输入门、遗忘门、输出门和记忆单元,可以有效地防止梯度消失或爆炸的问题。
S2.23、将CNN和LSTM的输出向量进行拼接,作为输入,使用softmax函数来计算音乐数据属于每个情感类别的概率,并选择概率最大的类别作为最终的预测结果;
其中,softmax函数同上述方法相同。
S3、使用训练集中的音乐数据和特征向量或矩阵作为输入,通过音乐内容生成模块训练改进的LSTM网络,并使用目标输出作为监督信号,计算损失函数并更新网络参数;
重复这一步骤直到网络收敛或达到预设的迭代次数。
其中,音乐内容生成模块的目的是根据用户的输入条件(例如风格、情感、主题等)来生成音乐内容,例如音符序列或MIDI文件。
需要注意的是,这是一个序列生成问题,可以使用深度学习的方法来解决。具体步骤如下:
S3.1、将用户的输入条件转换为特征向量或矩阵,例如使用预训练的词嵌入模型(如Word2Vec或GloVe)将文本条件转换为向量,或使用预训练的分类模型(如CNN或LSTM)将音频条件转换为向量。
S3.2、将特征向量或矩阵作为输入,使用改进的长短期记忆网络(LSTM)来生成音乐内容;
其中,改进的LSTM网络在每个时间步长增加了一个注意力机制,用于关注与当前输出相关的输入信息,并增加了一个条件机制,用于根据用户的输入条件来调整输出概率分布。
S3.3、将改进的LSTM网络的输出序列作为音乐内容,根据需要转换为音符序列或MIDI文件;
其中,音符序列是一种表示音乐数据的简单格式,每个音符由音高、时值和力度组成;
其次,IDI文件是一种表示音乐数据的标准格式,每个音符由音高、时值、力度和乐器等信息组成。
改进的LSTM网络的详细技术原理如下:
改进的LSTM网络是一种能够处理序列数据的深度学习模型,可以捕捉音乐数据中的长期依赖关系,并根据用户的输入条件来生成音乐内容;
改进的LSTM网络由以下几个部分组成:
一个编码器,用于将输入特征向量或矩阵编码为一个隐藏状态向量。
一个解码器,用于根据编码器的隐藏状态向量和用户的输入条件来生成输出序列。
一个注意力机制,用于计算解码器在每个时间步长对编码器隐藏状态向量的注意力权重,并根据权重得到一个上下文向量。
一个条件机制,用于根据用户的输入条件和上下文向量来调整解码器输出概率分布。
其中,编码器是一个标准的LSTM网络,其结构包括输入门、遗忘门、输出门和记忆单元,可以有效地防止梯度消失或爆炸的问题。
需要注意的是,编码器接收输入特征向量或矩阵X={x
i
f
o
τ
h
其中,i
除此之外,解码器是一个改进的LSTM网络,其结构在标准的LSTM网络的基础上增加了一个注意力机制和一个条件机制。
解码器接收编码器的隐藏状态向量H={h
解码器的计算公式如下:
i
f
o
c
s
a
y
其中i
注意力机制是一种能够使解码器在每个时间步长关注与当前输出相关的输入信息的机制;
其中,注意力机制通过计算解码器隐藏状态和编码器隐藏状态之间的相似度,得到一个注意力权重向量a
然后,根据注意力权重向量和编码器隐藏状态向量,得到一个上下文向量
注意力机制的计算公式如下:
a
其中W
条件机制是一种能够使解码器根据用户的输入条件来调整输出概率分布的机制。
条件机制通过将用户的输入条件和上下文向量拼接到解码器隐藏状态后,作为输出向量转换为输出概率分布,表示音符的概率分布。输出层的计算公式如下:
y
其中W
音乐内容生成模块的训练过程如下:
首先,将训练集中的音乐数据和特征向量或矩阵作为输入,通过编码器和解码器得到输出序列,并与目标输出序列进行比较,计算交叉摘损失函数:
其中
然后,使用反向传播算法来更新网络参数,即根据损失函数对网络参数求梯度,并使用优化器(如随机梯度下降或Adam)来调整网络参数。
S4、接收用户的输入条件(例如风格、情感、主题等),并将其转换为相应的特征向量或矩阵;
其中,使用这些特征向量或矩阵作为条件输入,通过已训练好的LSTM网络生成相应的音乐内容,例如音符序列或MIDI文件。
该实施方式中,将输入条件转换为相应的特征向量或矩阵而的具体步骤为:
S4.1、将用户的输入条件(例如风格、情感、主题等)转换为相应的特征向量或矩阵,例如使用预训练的词嵌入模型(如Word2Vec或GloVe)将文本条件转换为向量,或使用预训练的分类模型(如CNN或LSTM)将音频条件转换为向量;
需要注意的是,这一步骤的目的是将用户的输入条件用一种数值化的方式表示,以便作为改进的LSTM网络的输入。
S4.2、使用这些特征向量或矩阵作为条件输入,通过已训练好的LSTM网络生成相应的音乐内容,例如音符序列或MIDI文件;
需要注意的是,这一步骤的目的是根据用户的输入条件来生成符合用户需求和喜好的音乐内容,而该步骤的具体过程如下:
S4.21、初始化解码器的隐藏状态和记忆单元为零向量,即s
S4.22、将一个特殊的开始符号(如)作为解码器的第一个输入,即y
S4.23、根据解码器的计算公式,得到第一个时间步长的输出概率分布y
S4.24、将采样出的音符
S4.25、直到生成一个特殊的结束符号(如)或达到预设的最大长度,即y
S4.3、将生成的音符序列或MIDI文件作为音乐内容输出。
S5、将生成的音乐内容通过音乐后处理模块转换为适合播放或保存的格式,例如WAV文件或MP3文件,并将其存储在数据库中。
S6、根据用户的选择,通过音乐演奏模块演奏或保存生成的音乐。
最后,重复以上步骤直到网络收敛或达到预设的迭代次数。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 图像信息的传输方法、装置、存储介质及电子设备
- 图像传输方法、装置、电子设备和存储介质
- 音频传输方法、装置、电子设备及存储介质
- 一种信号传输方法、装置、电子设备以及计算机可读存储介质
- 音频传输方法、装置、电子设备及存储介质
- 视频流传输方法、装置、电子设备及计算机可读存储介质
- 视频流传输方法、装置、电子设备及存储介质