用于在深度学习中对基于语义的篇章进行分层获取的系统和方法
文献发布时间:2024-04-18 20:00:50
交叉引用
本申请要求2021年11月23日提交的美国非临时申请号17/533,613和2021年5月17日提交的美国临时申请号63/189,505的优先权,这些申请据此全文以引用方式明确地并入本文中。
版权声明
本专利文档的公开内容的一部分包含受版权保护的材料。版权所有者对于任何人对本专利文档或本专利公开内容的完全相同之复制没有任何异议,就如同其在专利商标局的专利文件或记录中一样,但是保留此外的其他一切权利。
技术领域
实施方案整体涉及机器学习系统和深度学习,并且更具体地涉及基于语义的数据的分层获取框架。
背景技术
在背景技术部分中讨论的主题不应仅由于其在背景技术部分中提及而被假定为现有技术。类似地,在背景技术部分中提及的或与背景技术部分的主题相关联的问题不应被假定为先前已经在现有技术中认识到。背景技术部分中的主题仅表示不同的方法,其本身也可以是发明。
机器学习(ML)和神经网络(NN)系统可以用于试图理解人类语音和书写,例如,用于理解人类交流的总体意图、句法和/或语义。可以使用大量训练文本来训练这种ML/NN系统,包括利用标签预注释的(受监督的)或没有预注释标签的(无监督的)不同文档的语料库。当训练ML系统时,可以利用不同的训练数据,包括来自文档的字符、字词、短语、篇章和内容。然而,训练数据和这种数据的规范在范围上有所变化,这在使用大型文档的语料库时可以导致不同的预测和分类。此外,一旦ML/NN模型被训练,对具有不同文档、来自文档的不同篇章等的训练数据的不同使用可以导致不可预测的和/或较慢的搜索结果。
最近对密集神经获取器的研究在通过ML/NN系统进行开放域问答(QA)方面实现了有希望的结果,其中可以利用问题和篇章的潜在表示在获取过程中进行最大内积搜索。然而,训练密集获取器需要将文档拆分成短篇章,这些短篇章的表示可能包含本地、部分和有时有偏见的内容,因此训练高度依赖于拆分过程。因此,训练可能在模型中产生不准确且误导的隐藏表示,从而使ML/NN系统的最终获取结果变差。
附图说明
图1示出了根据一些实施方案的其中可以使用用于预测数据库查询结果的系统和方法的示例性环境的框图。
图2示出了根据一些实施方案的另一示例性环境的框图。
图3示出了根据一些实施方案的用于在深度学习中使用分层获取来获取文档和篇章的示例性计算系统的框图。
图4示出了根据一些实施方案的可以在深度学习中使用对基于语义的篇章的分层获取来获取的文档的语料库中的示例性文档和篇章的简化图。
图5示出了根据一些实施方案的用于在深度学习中对基于语义的篇章进行分层获取的示例性部件的简化图。
图6示出了根据一些实施方案的用于使用图3、图4和图5中描述的文档级获取器和篇章级获取器在深度学习中对基于语义的篇章进行分层获取的流程图的简化图。
在附图中,具有相同标号的元件具有相同或相似的功能。
具体实施方式
本说明书和示出方面、实施方案、实现方式或应用的附图不应视为限制性的—权利要求书限定所保护的发明。在不脱离本说明书和权利要求书的精神和范围的情况下,可以进行各种机械、组成、结构、电气和操作的改变。在一些情况下,没有详细地示出或描述公知的电路、结构或技术,因为这些对于本领域技术人员而言是公知的。两个或更多个图中的相似标号表示相同或相似的元件。
在本说明书中,阐述了描述与公开文本相一致的一些实施方案的具体细节。阐述了许多具体细节以便提供对实施方案的透彻理解。然而,对于本领域技术人员来说显而易见的是,可以在没有这些具体细节中的一些或全部的情况下实践一些实施方案。本文公开的具体实施方案旨在作为例示而非限制。本领域技术人员可以认识到,其他元件落入公开文本的范围和精神内,尽管其他元件在此没有具体描述。另外,为了避免不必要的重复,除非另有具体描述或者当一个或多个特征将使实施方案不起作用时,否则与一个实施方案相关联地示出和描述的一个或多个特征可以被并入到其他实施方案中。
深度学习已经广泛地用于ML和NN系统中。在对比学习中,开放域QA可以用于回答仿真陈述问题。以前,密集篇章获取可以用于回答问题。流行方法中的一种方法是利用获取器-读取器方法来提供回答。在这种开放域问答中,给出问题并且预测文档的语料库内的一组相关上下文。然而,从大型文档的语料库(诸如维基百科)提取相关上下文是困难的,并且存在弱点,诸如类似主题可能与特定问题相关的情况。此外,来自文档的篇章可能仅包含本地和特定信息,导致分散注意力的表示。
相反,密集分层获取(DHR)可以用于通过利用文档中的宏观语义和每个篇章特定的微观语义两者来生成篇章的准确密集表示。首先,例如基于对来自文档的语料库的文档进行编码来获取问题的相关文档。可以使用文档内的文档摘要、内容表和/或其他标题表以文档级对文档进行编码。此后,可以通过利用文档级相关性校准的篇章级获取模型来获取相关篇章。为了进一步增强全局语义,每个篇章与分层标题列表组合。为了更好地学习正篇章,可以引入两种负采样策略,即,可以使用文档内(文档内)负样本和章节内(章节内)负样本作为难对比样本。DHR被应用于大型开放域QA数据集,其中密集分层获取模型可以胜过密集篇章获取器,并且帮助端到端QA系统在多个开放域QA基准上建立更好的结果。
如本文所用,术语“网络”可以包括任何基于硬件或软件的框架,其包括任何人工智能网络或系统、NN或系统、和/或在其上实现或与其一起实现的任何训练或学习模型。
如本文所用,术语“模块”可以包括执行一个或多个功能的任何基于硬件或软件的框架。在一些实施方案中,模块可以在一个或多个NN上实现。
概述
对于能够由多个单独的组织访问的数据库系统,诸如多租户数据库系统,提供了用于使用文档级获取模型和篇章级获取模型处理文档的语料库的方法、数据结构和系统。数据库系统存储能够由数据库系统的用户访问的多个文档,称为文档的语料库或文档的语料库。例如,可以由数据库系统的用户或管理员(例如,组织代理人)基于输入、文章、请求、以及可以提供一些信息的其他文档(诸如信息文章、百科全书条目、帮助请求、培训手册、小册子或提供信息的其他主题相关文章)来生成文档。由数据库系统存储的至少一些文档与具有文档标题或主题的相关文本的篇章相关联。文档的语料库内的文档还可以包括一个或多个文档结构,包括摘要、内容表(ToC)、章节和对应的章节标题、子章节和对应的子章节标题、标题表、段落、句子和/或其他文本。
本文描述的实施方案提供了用于使用采用ML和NN技术的文档级获取模型和篇章级获取模式从文档中对基于语义的篇章进行分层获取的方法、计算机程序产品和计算机数据库系统。在线系统向用户提供对在线服务和文档的语料库的访问。例如,在线系统可以是基于web的系统,其向用户提供对百科全书资源和/或客户关系管理(CRM)软件应用的访问。作为向用户提供服务的一部分,在线系统存储文档的语料库,文档的语料库能够由在线系统的用户访问并且能够使用受过训练的ML/NN过程和/或其他搜索引擎(诸如自然语言处理器)来进行搜索。文档的语料库可以例如由在线系统的用户或管理员基于文档的输入和标识来生成。
根据一些实施方案,在能够由多个单独且不同的组织访问的多租户数据库系统中,提供了神经网络模型,以用于处理文档的语料库,以及使用DHR提供相关的基于语义的篇章,考虑每个文档、文档结构和篇章的特异性,从而增强与组织相关联的用户的体验,提供更快的获取结果,并且最小化用于文本获取的即时处理成本。
示例性环境
公开文本的系统和方法可以包括数据库、并入数据库或与数据库的环境相结合地或在数据库的环境中操作,在一些实施方案中,数据库可以被实现为多租户的基于云的架构。已经开发了多租户的基于云的架构以在不牺牲数据安全的情况下改进客户租户之间的协作、集成和基于社区的合作。一般来讲,多租户是指其中单个硬件和软件平台从公共数据存储元件(也称为“多租户数据库”)同时支持多个用户组(也称为“组织”或“租户”)的系统。多租户设计提供了优于常规服务器虚拟化系统的多个优点。首先,多租户平台运营商通常可以基于来自整个租户社区的集体信息来对平台进行改进。另外,因为多租户环境中的所有用户在公共处理空间内执行应用,所以相对容易授权或拒绝多租户平台内的任何用户对特定数据集的访问,从而改进应用与由各种应用管理的数据之间的协作和集成。因此,多租户架构允许在多个用户集之间方便且成本有效地共享类似的应用特征。
图1示出了根据一些实施方案的示例性环境110的框图。环境110可以包括用户系统112、网络114、系统116、处理器系统117、应用平台118、网络接口120、租户数据存储122、系统数据存储124、程序代码126、和用于执行数据库系统进程和租户特定进程(诸如作为应用托管服务的一部分运行应用)的进程空间128。在其他实施方案中,环境110可以不具有所列出的所有部件和/或可以具有作为上文所列出的那些元件的代替或补充的其他元件。
在一些实施方案中,环境110是其中存在按需数据库服务的环境。用户系统112可以是由用户用于访问数据库用户系统的任何机器或系统。例如,用户系统112中的任何用户系统可以是手持式计算设备、移动电话、膝上型计算机、笔记本计算机、工作站和/或计算设备网络。如图1所示(并且在图2中更详细地示出),用户系统112可以经由网络114与作为系统116的按需数据库服务交互。
诸如可以使用系统116实现的按需数据库服务是一种对拥有、维护或提供对系统116的访问的企业外部的用户可用的服务。如上所述,这种用户不一定需要关心构建和/或维护系统116。相反,当用户需要由系统116提供的服务时(例如,按照用户的需求),由系统116提供的资源可以用于供这种用户使用。一些按需数据库服务可以存储来自一个或多个租户的信息,这些信息存储到公共数据库图像的表中以形成多租户数据库系统(MTS)。因此,“按需数据库服务116”和“系统116”在本文中将被互换地使用。术语“多租户数据库系统”可以是指其中数据库系统的硬件和软件的各种元件可以由一个或多个客户或租户共享的那些系统。例如,给定的应用服务器可以同时为大量客户处理请求,并且给定的数据库表可以为可能更大量客户存储数据行,诸如馈送项目。数据库图像可以包括一个或多个数据库对象。关系数据库管理系统(RDBMS)或其等同物可以针对数据库对象执行信息的存储和获取。
应用平台118可以是允许系统116的应用运行的框架,诸如硬件和/或软件基础设施,例如,操作系统。在一个实施方案中,系统116可以包括应用平台118,应用平台使得能够创建、管理和执行由按需数据库服务的提供者、经由用户系统112访问按需数据库服务的用户、或经由用户系统112访问按需数据库服务的第三方应用开发者开发的一个或多个应用。
用户系统112的用户在其相应能力方面可以有所不同,并且用户系统112中的特定一个用户系统的能力可以完全由当前用户的许可(许可级别)确定。例如,在销售人员正在使用特定用户系统112与系统116交互的情况下,用户系统具有分配给销售人员的能力。然而,在管理员正在使用用户系统112与系统116交互时,用户系统112具有分配给管理员的能力。在具有分层角色模型的系统中,一个许可级别下的用户可以访问能够由更低许可级别用户访问的应用、数据和数据库信息,但是不可以访问能够由更高许可级别下的用户访问的某些应用、数据库信息和数据。因此,不同用户将具有关于访问和修改应用和数据库信息的不同能力,这取决于用户的安全或许可级别。
网络114是任何网络或彼此通信的设备的网络的任何组合。例如,网络114可以是局域网(LAN)、广域网(WAN)、电话网、无线网、点对点网络、星型网络、令牌环网、集线器网络或其他适当配置中的任何一个或任何组合。由于当前使用的计算机网络的最常见类型是传输控制协议和互联网协议(TCP/IP)网络,诸如通常称为“互联网(Internet)”的具有大写字母“I”的全球网络互联网,因此将在本文的许多示例中使用网络。然而,应当理解,本实施方案可以使用的网络不限于此,但是TCP/IP是频繁实现的协议。
用户系统112可以使用TCP/IP与系统116通信,并且在更高的网络级别下,使用其他公共互联网协议来通信。诸如超文本传输协议(HTTP)、文件传输协议(FTP)、安德鲁文件系统(AFS)、无线应用协议(WAP)等。在其中使用HTTP的示例中,用户系统112可以包括通常称为“浏览器”的HTTP客户端,以用于向系统116处的HTTP服务器发送HTTP消息以及从HTTP服务器接收HTTP消息。这种HTTP服务器可以被实现为系统116与网络114之间的唯一网络接口,但是也可以使用其他技术或者代替地使用其他技术。在一些实现方式中,系统116与网络114之间的接口包括负载共享功能,诸如轮询HTTP请求分发器,以平衡负载并在多个服务器上均匀地分发即将到来的HTTP请求。至少对于正在访问服务器的用户而言,多个服务器中的每个服务器都可以访问MTS数据;然而,可以代替地使用其他替代配置。
在一些实施方案中,图1所示的系统116实现基于web的CRM系统。例如,在一个实施方案中,系统116包括应用服务器,应用服务器被配置为实现和执行CRM软件应用,以及向和从用户系统112提供相关数据、代码、表单、网页和其他信息,以及向数据库系统存储和从其获取相关数据、对象和网页内容。利用多租户系统,多个租户的数据可以被存储在同一物理数据库对象中。然而,租户数据通常被布置成使得一个租户的数据在逻辑上保持与其他租户的数据分开,使得一个租户不能访问另一租户的数据,除非这种数据被明确地共享。在某些实施方案中,系统116实现不同于CRM应用或作为CRM应用的补充的应用。例如,系统16可以向租户提供对包括CRM应用的多个托管(标准和定制)应用的访问。可以包括或可以不包括CRM的用户(或第三方开发者)应用可以由应用平台118支持,应用平台管理应用的创建、将应用存储到一个或多个数据库对象中、以及在系统116的进程空间中的虚拟机中执行应用。
图1中示出了系统116的元件的一种布置,包括网络接口120、应用平台118、针对租户数据123的租户数据存储122、针对系统116和可能的多个租户能够访问的系统数据125的系统数据存储124、用于实现系统116的各种功能的程序代码126、以及用于执行MTS系统进程和租户特定进程(诸如作为应用托管服务的一部分运行应用)的进程空间128。可以在系统116上执行的附加进程包括数据库索引编排进程。
图1所示系统中的若干元件包括常规的公知元件,在此仅简要地解释这些公知元件。例如,用户系统112中的每个用户系统可以包括台式个人计算机、工作站、膝上型计算机、笔记本计算机、PDA、蜂窝电话、或任何无线接入协议(WAP)使能的设备、或能够直接或间接连接到互联网或其他网络连接的任何其他计算设备。用户系统112中的每个用户系统通常运行HTTP客户端,例如,浏览程序,诸如Microsoft的Internet Explorer浏览器、Netscape的Navigator浏览器、Opera的浏览器,或者在蜂窝电话、笔记本计算机、PDA或其他无线设备等的情况下的WAP使能的浏览器,从而允许用户系统112的用户(例如,多租户数据库系统的订户)通过网络114访问、处理和查看能够从系统116获得的信息、页面和应用。用户系统112中的每个用户系统通常还包括一个或多个用户接口设备,诸如键盘、鼠标、轨迹球、触摸板、触摸屏、笔等,以用于结合由系统116或其他系统或服务器提供的页面、表单、应用和其他信息与由浏览器在显示器(例如,监视器屏幕、液晶显示器(LCD)监视器、发光二极管(LED)监视器、有机发光二极管(OLED)监视器等)上提供的图形用户界面(GUI)交互。例如,用户接口设备可以用于访问由系统116托管的数据和应用,以及对所存储的数据执行搜索,以及以其他方式允许用户与可以呈现给用户的各种GUI页面交互。如上所述,实施方案适合于与互联网一起使用,互联网是指特定的全球网络互联网。然而,应当理解,可以使用其他网络来代替互联网,诸如内联网、外联网、虚拟专用网络(VPN)、基于非TCP/IP的网络、任何LAN或WAN等。
根据一个实施方案,用户系统112中的每个用户系统及其所有部件是操作者可使用应用(诸如浏览器)配置的,应用包括使用中央处理单元(诸如Intel
根据一个实施方案,系统116被配置为向用户(客户端)系统112提供网页、表单、应用、数据和媒体内容,以支持作为系统116的租户的用户系统112的访问。因此,系统116提供安全机制以保持每个租户的数据分开,除非数据被共享。如果使用多于一个MTS,则它们可以定位得彼此靠近(例如,在位于单个建筑物或校园中的服务器场中),或者它们可以分布在彼此远离的位置(例如,位于城市A中的一个或多个服务器和位于城市B中的一个或多个服务器)。如本文所用,每个MTS可以包括一个或多个逻辑上和/或物理上连接的服务器,这些服务器本地分布或跨一个或多个地理位置分布。另外,术语“服务器”意味着包括计算机系统,计算机系统包括处理硬件和进程空间,以及相关联的存储系统和数据库应用(例如,面向对象的数据库管理系统(OODBMS)或关系型数据库管理系统(RDBMS)),如本领域所公知的。还应当理解,“服务器系统”和“服务器”在本文中经常被互换地使用。类似地,本文描述的数据库对象可以被实现为单个数据库、分布式数据库、分布式数据库的集合、具有冗余在线或离线备份或其他冗余的数据库等,并且可以包括分布式数据库或存储网络以及相关联的处理智能。
图2也示出了环境110,其可以用于实现本文描述的实施方案。图2进一步示出了根据一些实施方案的系统116的元件和各种互连。图2示出了用户系统112中的每个用户系统可以包括处理器系统112A、存储器系统112B、输入系统112C和输出系统112D。图2示出了网络114和系统116。图2还示出系统116可以包括租户数据存储122、租户数据123、系统数据存储124、系统数据125、用户界面(UI)230、应用程序接口(API)232、PL/Salesforce.com对象查询语言(PL/SOQL)234、保存例程236、应用设置机制238、应用服务器200
用户系统112、网络114、系统116、租户数据存储122和系统数据存储124已在上文在图1中讨论。关于用户系统112,处理器系统112A可以是一个或多个处理器的任何组合。存储器系统112B可以是一个或多个存储器设备、短期和/或长期存储器的任何组合。输入系统112C可以是输入设备的任何组合,诸如一个或多个键盘、鼠标、轨迹球、扫描仪、相机和/或到网络的接口。输出系统112D可以是输出设备的任何组合,诸如一个或多个监视器、打印机和/或到网络的接口。如图2所示,系统116可以包括被实现为一组HTTP应用服务器200、应用平台118、租户数据存储122和系统数据存储124的(图1的)网络接口120。还示出了系统进程空间202,其包括单独的租户进程空间204和租户管理进程空间210。每个应用服务器200可以被配置为访问租户数据存储122和其中的租户数据123、以及系统数据存储124和其中的系统数据125以服务用户系统112的请求。租户数据123可以被划分到单独的租户存储区域212中,这些租户存储区域可以是数据的物理布置和/或逻辑布置。在每个租户存储区域212内,可以类似地将用户存储214和应用元数据216分配给每个用户。例如,用户最近使用的(MRU)项目的副本可以被存储到用户存储214。类似地,作为租户的整个组织的MRU项目的副本可以被存储到租户存储区域212。UI 230提供用户界面,并且API 232向系统116驻留的进程以及用户系统112处的用户和/或开发者提供应用编程接口。租户数据和系统数据可以被存储在各种数据库中,诸如一个或多个Oracle
应用平台118包括支持应用开发者对应用的创建和管理的应用设置机制238,例如,应用可以通过保存例程236作为元数据保存到租户数据存储122中以供订户作为由租户管理进程空间210管理的一个或多个租户进程空间204来执行。对这种应用的调用可以使用向API 232提供编程语言风格接口扩展的PL/SOQL 234来进行编码。PL/SOQL语言的一些实施方案在2007年9月21日提交的名称为“Method and System For Allowing Access toDeveloped Applications Via a Multi-Tenant On-Demand Database Service”的美国专利号7,730,478中更详细地讨论,该美国专利以引用方式并入本文中。对应用的调用可以由一个或多个系统进程检测,一个或多个系统进程管理为订户获取应用元数据216、进行调用以及作为虚拟机中的应用执行元数据。
每个应用服务器200可以经由不同的网络连接通信地联接至数据库系统,例如,访问系统数据125和租户数据123。例如,一个应用服务器200
在某些实施方案中,每个应用服务器200被配置为针对与作为租户的任何组织相关联的任何用户处理请求。因为期望能够在任何时间出于任何原因从服务器池中添加和移除应用服务器,所以优选地,对于用户和/或组织而言不存在与特定应用服务器200的服务器亲缘关系。因此,在一个实施方案中,实现负载平衡功能的接口系统(例如,F5 Big-IP负载平衡器)通信地联接在应用服务器200与用户系统112之间,以将请求分发给应用服务器200。在一个实施方案中,负载平衡器使用最小连接算法来将用户请求路由到应用服务器200。也可以使用负载平衡算法的其他示例,诸如轮询和观测响应时间。例如,在某些实施方案中,来自同一用户的三个连续请求可能命中三个不同的应用服务器200,并且来自不同用户的三个请求可能命中同一应用服务器200。这样,系统116是多租户的,其中系统116处理跨不同用户和组织的对不同对象、数据和应用的存储和访问。
作为存储的示例,一个租户可以是雇用销售团队的公司,其中每个销售人员使用系统116来管理其销售过程和/或向其他用户、代理人和管理员提供信息,这些信息可以是可搜索的。因此,用户可以维护联系人数据、潜在客户数据、客户跟踪数据、性能数据、目标和进展数据、培训材料、研究文章等,所有这些都适用于用户(例如,在租户数据存储122中)。在MTS布置的示例中,由于要访问、查看、修改、报告、传输、计算等的所有数据和应用都可以通过仅具有网络访问的用户系统来维护和访问,因此用户可以从许多不同用户系统中的任何用户系统管理其信息。例如,如果销售人员正在拜访客户并且客户在其大厅有互联网接入,则销售人员可以在等待客户到达大厅的同时获得关于客户的关键更新。
虽然每个用户的数据可以与其他用户的数据分开而与每个用户的雇主无关,但是一些数据可以是由作为租户的给定组织的多个用户或所有用户共享或能够访问的组织范围内数据。因此,可以存在由系统116管理的在租户级下分配的一些数据结构,而其他数据结构可以在用户级下进行管理。因为MTS可以支持包括可能竞争者的多个租户,所以MTS应当具有保持数据、应用和应用使用分开的安全协议。此外,因为许多租户可以选择访问MTS而不是维护其自身的系统,所以冗余、正常运行时间和备份是可以在MTS中实现的附加功能。除了用户特定数据和租户特定数据之外,系统116还可以维护能够由多个租户使用的系统级数据或其他数据。这种系统级数据可以包括能够在租户之间共享的行业报告、新闻、帖子等。
在某些实施方案中,用户系统112(其可以是客户端系统)与应用服务器200通信以请求和更新来自系统116的系统级和租户级数据,这可能需要向租户数据存储122和/或系统数据存储124发送一个或多个查询。系统116(例如,系统116中的应用服务器200)自动生成被设计成访问期望信息的一个或多个结构化查询语言(SQL)语句(例如,一个或多个SQL查询)。在其他实施方案诸如自然语言处理器或机器学习引擎中,可以基于输入数据执行其他类型的搜索。系统数据存储124可以生成查询计划以从数据库中访问所请求的数据,数据库可以包括基于对文档内的对象的参考的外部对象。
在数据库系统诸如相对于图1和图2示出和描述的系统116中,数据或信息可以按类别或分组进行组织或布置。每个数据库通常可以被视为对象的集合,诸如一组逻辑表,包含适配在预定义类别中的数据。“表”是数据对象的一种表示,并且可以在本文中用于简化对象和定制对象的概念性描述。应当理解,“表”和“对象”在本文中可以被互换地使用。每个表通常包含一个或多个数据类别,一个或多个数据类别在逻辑上被布置为可查看模式中的列或字段。表的每个行或记录包含由字段定义的针对每个类别的数据实例。
例如,在百科全书和/或CRM系统中,这些类别或分组可以包括与文档的语料库相关联的各种标准表,诸如属于语料库的文档列表,以及提交给系统的与搜索那些语料库相关联的信息(例如,经编码文档、摘要、ToC、文本篇章和附加的前述文档文本)。例如,数据库可以包括描述文档的语料库(例如,可以针对主题或系统本身搜索的一个或多个文档)的表,并且可以包括语料库内的文档的文本。在一些多租户数据库系统中,数据库中的表和文档可以被提供以供所有租户使用,或者可以仅可由系统的一些租户和代理人(例如,用户和管理员)查看。
在一些多租户数据库系统中,可以允许租户创建和存储定制对象,或者可以允许租户例如通过创建用于标准对象的定制字段(包括定制索引字段)来定制标准实体或对象。用于在多租户数据库系统中创建定制对象以及定制标准对象的系统和方法在2004年4月2日提交的名称为“Custom Entities and Fields in a Multi-Tenant Database System”的美国专利号7,779,039中更详细地描述,该美国专利以引用方式并入本文中。在某些实施方案中,例如,所有定制实体数据行被存储在单个多租户物理表中,单个多租户物理表可以包含每组织多个逻辑表。对客户来说透明的是,他们的多个“表”实际上被存储在一个大型表中,或者他们的数据可以被存储在与其他客户的数据相同的表中。
上述多租户数据库系统116可以由多个客户、客户端或其他人(通常为“用户”)访问和使用,以便搜索和/或浏览百科全书条目、询问、问题、提问、疑问、支持相关事项、培训或教育等。然而,在其他实施方案中,其他类型的搜索系统也可以利用本文描述的过程以提供在文档中对基于语义的篇章的密集分层获取。为了便于系统116与用户之间的交互,提供了搜索栏、语音接口或类似的用户接口工具。搜索工具允许用户查询数据库以访问关于或涉及与用户相关的各种文档、对象和/或实体的信息或数据。
然而,对于具有许多记录和信息的大型数据库,可能存在大量文档,其中一些或所有文档包括一个或多个文档结构(例如,摘要、ToC、章节和对应的章节标题、子章节和对应的子章节标题、标题表等)和篇章(例如,段落、句子和/或其他文本)。例如,文档可以包括指定章节和篇章以及篇章的对应文本的文档结构。当搜索文档时,用于开放域QA的常规搜索技术(例如,使用字符或字词嵌入或向量训练的机器学习系统)可能仅通过拆分文档中的篇章并对问题和篇章进行编码以供搜索来搜索文档的内容。因此,当不考虑文档和除了篇章之外的文档结构时,数据库系统的搜索索引数据可能不是预测搜索查询的适当搜索结果的准确基础。针对用户对大型文档的语料库执行搜索的搜索结果进行预测和排序是一项困难任务。在多租户系统(诸如Salesforce.com)中,文档可以包括文档结构、篇章等。继续该示例,因为用户可能对针对查询的具有所有返回数据的相关搜索结果最感兴趣,所以为了最佳或增强的用户体验,可能期望或优选的是数据库系统预测与用户的搜索或查询最相关或最适用的文档,使得以最少数量的击键、鼠标点击、用户界面等向用户呈现期望的信息或数据。因此,根据一些实施方案,提供了用于使用一个或多个密集分层获取模型来预测和返回搜索结果的系统和方法,一个或多个密集分层获取模型可以包括文档级获取模型和编码器以及篇章级获取模型和编码器。
密集分层获取模型
根据一些实施方案,在能够由多个分开且不同的组织访问的多租户数据库系统(诸如相对于图1和图2示出和描述的系统116)中,提供了用于智能搜索过程的密集分层获取模型,密集分层获取模型将与给定查询最相关的返回结果提供到数据库中,其考虑一个或多个语料库的文档的文档级数据和结构以及篇章级数据,从而提供增强的用户体验。
图3是根据本文描述的一些实施方案的实现用于深度学习的对基于语义的训练数据的分层获取的计算设备的简化图。如图3所示,计算设备300包括联接至存储器320的处理器310。计算设备300的操作由处理器310控制。尽管计算设备300被示出为具有仅一个处理器310,但是应当理解,处理器310可以表示计算设备300中的一个或多个中央处理单元、多核处理器、微处理器、微控制器、数字信号处理器、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、图形处理单元(GPU)等。计算设备300可以被实现为独立子系统、添加到计算设备的板、和/或虚拟机。
存储器320可以用于存储由计算设备300执行的软件和/或在计算设备300的操作期间使用的一个或多个数据结构。存储器320可以包括一种或多种类型的机器可读介质。机器可读介质的一些常见形式可以包括软盘、柔性盘、硬盘、磁带、任何其他磁介质、CD-ROM、任何其他光学介质、打孔卡、纸带、任何其他具有孔图案的物理介质、RAM、PROM、EPROM、闪存EPROM、任何其他存储器芯片或盒、和/或处理器或计算机适于从其进行读取的任何其他介质。
处理器310和/或存储器320可以以任何合适的物理布置来布置。在一些实施方案中,处理器310和/或存储器320可以在同一板上、在同一封装(例如,系统级封装)中、在同一芯片(例如,片上系统)上等实现。在一些实施方案中,处理器310和/或存储器320可以包括分布式、虚拟化和/或容器化计算资源。根据这种实施方案,处理器310和/或存储器320可以位于一个或多个数据中心和/或云计算设施中。
在一些示例中,存储器320可以包括一个和/或多个非暂态有形机器可读介质,其包括可执行代码,可执行代码当由一个或多个处理器(例如,处理器310)运行时可以使一个或多个处理器执行本文更详细地描述的方法。例如,如图所示,存储器320包括用于深度学习模块330的指令,其可以用于实现和/或仿真系统和模型、和/或实现本文进一步描述的任何方法。在一些示例中,深度学习模块330可以经由数据接口315接收输入340,例如,针对文档的语料库的问题。深度学习模块330还可以针对问题接收和/或访问一个或多个文档的语料库。数据接口315可以是接收针对QA数据集的问题的用户接口、或可以从另一系统接收或获取先前请求的问题和/或获取由数据库存储的先前请求的问题的通信接口中的任何一个。深度学习模块330可以基于问题输入340来生成输出350,诸如来自文档的语料库的回答结果。回答结果可以包括来自使用深度学习模块330确定的文档的一个或多个文档和/或篇章,一个或多个文档和/或篇章可以基于使用文档级获取模型和篇章级获取模型确定的其与问题的相关性来排序、列举、分类和/或评分。
在一些实施方案中,深度学习模块330还可以包括密集分层获取模块331以及文档和篇章编码器模块332。密集分层获取模块331以及文档和篇章编码器模块332可以用于通过使用考虑问题的DHR方法来向开放域问题提供更好的结果,DHR方法使用密集文档级获取模型结合密集篇章级获取模型。针对标识用于使用问题进行搜索的文档的语料库的密集分层获取模块331可以接收对文档的语料库的开放域QA问题并对其进行编码。密集文档级获取模型可以使用由文档和篇章编码器模块332进行编码和索引编排的经编码文档(例如,基于其摘要、ToC和/或其他文档结构)。密集分层获取模块331可以利用文档和篇章编码器模块332来从文档的语料库中标识具有篇章的一个或多个文档。可以由密集分层获取模块331过滤无关文档,并且可以标识用于进行搜索和/或排序的一个或多个文档。
当对来自根据文档级获取模型和经编码问题标识的文档的篇章进行编码时,可以使用文档和篇章编码器模块332的密集篇章级获取模型。密集篇章级获取模型可以使用经编码的篇章和问题从前位评级文档中获得前位评级篇章,这些前位评级文档被评分或排序以返回到对文档的语料库的开放域QA问题。可以基于来自密集文档级获取模型的文档相关性得分和来自密集篇章级获取模型的篇章相关性得分的组合相关性得分来确定所返回的文档和/或篇章的相关性得分。密集分层获取模块331以及文档和篇章编码器模块332的其他功能将参考图4至图6更详细地讨论。在一些示例中,深度学习模块330和子模块331至332可以使用硬件、软件和/或硬件和软件的组合来实现。
根据一些实施方案,包括深度学习模块330的计算设备300的功能可以被实现或并入到搜索模型服务(SMS)插件中。SMS是托管并执行机器学习模型的gRPC微服务。SMS经由Protobuf文件接收参数,并使用这些输入参数执行模型。SMS根据所限定的响应参数向客户端(例如,用户设备)返回应答。在一些实施方案中,SMS实现方式在用于容器化应用(例如,Salesforce应用模型(SAM))的环境上运行,容器化应用与多租户数据库系统(诸如系统116)的核心应用分开或独立于核心应用。SMS可以提供模型的更快部署。SMS还提供Java虚拟机(JVM)的隔离/容器化,使得与其模型执行相关的崩溃将不会冲击或影响数据库系统的应用服务器。SMS插件是孤立代码,其可以初始化特定模型类型的模型数据,执行模型特定的特征处理,并基于特征向量和其他参数执行模型。插件架构提供了各种优点,包括可以在不对模型执行器代码做出改变的情况下对插件代码做出改变,以及利用插件减少或消除关于负载平衡、路由和并行化的担忧。
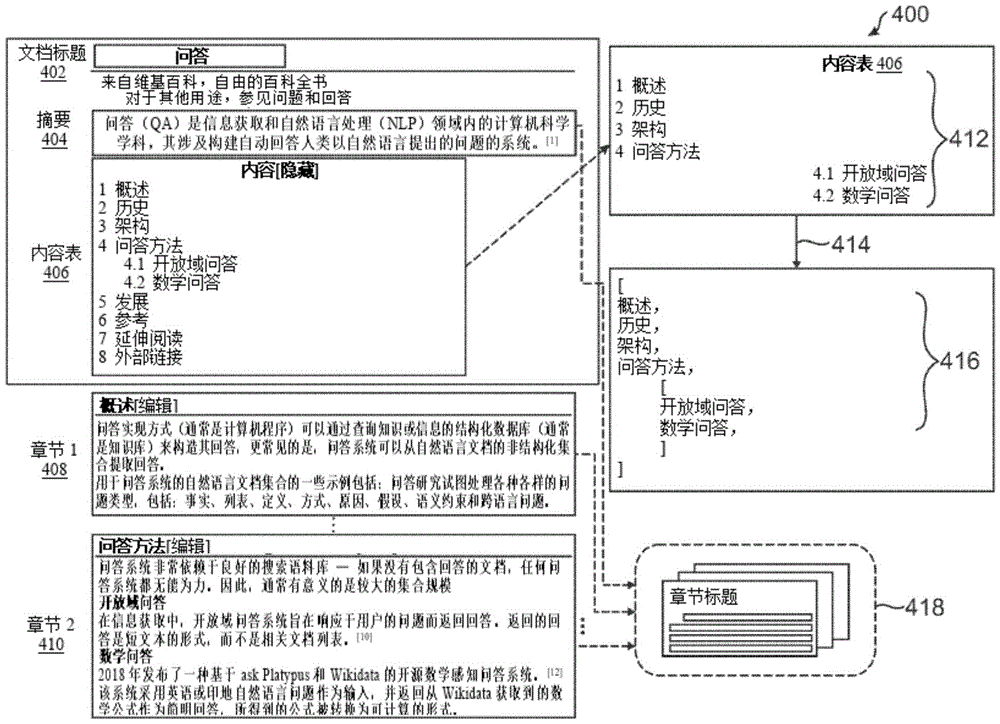
图4示出了根据一些实施方案的可以在深度学习中使用对基于语义的篇章的分层获取来获取的文档的语料库中的示例性文档和篇章的简化图。图4中的文档400显示构成文档的语料库(诸如文章、百科全书条目、培训材料、客户帮助请求和回答、以及数据库系统中的其他文档)中具有文本篇章的文档的文档结构和结构元素。因此,文档400可以用于基于一个或多个文档结构以及来自文档400的段落内短长度拆分文本篇章的篇章编码来生成文档编码。
文档400包括文档标题402、摘要404、内容表(ToC)406、第一章节408和第二章节410。文档400可以对应于文档的语料库(诸如用于在线百科全书的百科全书条目或其他可搜索数据库和平台)内的文档。就这一点而言,文档400可以被视为结构文档,其中不同的输入和数据被提取并被用作文档级获取模型和篇章级获取模型的输入。用于DHR的这些模型可以用于确定相关性得分的组合,以更好地获取、评分和/或排序针对开放域QA提交的问题的文档和篇章。就这一点而言,对于来自语料库的文档的文档级获取,密集文档级获取模型可以利用来自索引的经编码文档。经编码文档可以基于一个或多个文档结构从文档的语料库进行编码,并且可以在离线环境中进行索引编排。因此,当在运行时提交和查询问题时,可以访问索引并将其与问题的编码一起用于文档级获取。
对于文档级获取,需要针对文档的语料库中的每个文档对一个或多个文档结构进行编码。编码可以对应于基于用于对文档进行编码的文档结构的组成部分创建表示文档的嵌入或向量表示(例如,具有n个特征、变量或属性)。就这一点而言,文档400包括ToC 406,其可以对应于用于对文档400进行编码以供文档级获取的文档结构。在一些实施方案中,文档标题402和/或摘要404也可以用于文档级获取编码。文档400还包括摘要404、第一章节408和第二章节410,它们可以在对文档400的篇章进行编码以供篇章级获取时使用。
ToC 406包括章节和/或子章节标题列表412,然后,使用提取操作414提取和清理列表以生成分层标题列表416。然后,当对问题进行查询和编码时,分层标题列表416可以用于针对文档级获取模型和文档级获取器对文档400进行编码。因此,每个文档可以被视为具有章节S、子章节Ss及其对应段落的结构集合。每个章节或子章节具有对应的标题。因此,每个文档D
此外,为了执行针对文档400的篇章级获取,文档400的摘要404、第一章节408、第二章节410和/或其他文本可以被拆分成短长度篇章。就这一点而言,当将摘要404、第一章节408和第二章节410拆分成短长度篇章时,可以生成章节内拆分篇章文本418。这可以通过仅将同一章节或子章节标题下的段落拆分成有限长度篇章来完成。每个篇章可以对应于具有嵌套标题的令牌序列。语料库C={P
图5示出了根据一些实施方案的用于在深度学习中对基于语义的篇章进行分层获取的示例性部件的简化图。在一些实施方案中,图5中使用密集文档级获取模型和密集篇章级获取模型的密集分层获取可以是计算设备300的深度学习模块330的实现方式。
图5的部件500可以对应于用于使用文档级获取模型和篇章级获取模型从文档的语料库中对基于语义的特征和篇章进行密集分层获取的系统图。例如,可以为开放域QA系统提供问题501,并且可以使用问题编码器将问题编码为E
基于文档级获取模型从经编码的文档和问题确定前k
问题501的编码还可以与篇章级获取器508一起使用,其中对来自前k
为了训练文档级获取器502和篇章级获取器508的模型并生成经编码文档E
密集文档级获取可以使用以基于变换器的双向编码器表示(BERT)深度NN模型为基础的问题编码器和文档编码器。BERT对应于语言表示深度学习模型,其允许在NN模型层中训练深度双向表示。问题和文档可以被编码为密集表示向量,并且文档与问题的相关性得分可以通过以下点积来计算:Sim(q,d)=〈E
当训练密集文档级获取模型的编码器时,可以使用用于训练数据的QA数据集。这些可以包括标准化的开放域QA评估数据集,包括具有从真实的
例如,当训练数据集时,在包含给定问题的黄金标题(例如,具有正例和/或最佳匹配的标题)的数据集中,正文档可以是具有黄金标题的文档。在其他数据集中,当使用BM25时,获取在整个文档文本中包含回答的Top-1(前1)文档作为正文档。此后,为了训练,可以使用三种不同类型的负例。引言负例可以使用第一章节来表示每个文档,然后,BM25可以用于获取前位文档,但是这些前位文档在整个文档文本中不包含回答。全文本负例可以使用整个文档文本来表示每个文档,然后,BM25可以用于获取前位文档,但是这些前位文档在整个文档文本中不包含回答。此外,可以从与出现在训练数据集中的其他问题配对的篇章中使用批量负例。
篇章级获取器508还可能需要使用被训练用于篇章级获取的篇章级获取模型来对篇章进行编码。当训练密集篇章级获取模型的编码器时,可以与文档标题一起考虑子标题列表(例如,章节和/或子章节标题列表)。篇章P将表示为[CLS]标题[SEP]子标题
可以以与密集篇章获取(DPR)类似的方式确定正篇章和负篇章以用于训练。例如,在具有给定问题的黄金(例如,最佳或前1)上下文的数据集中,正篇章可以是篇章集{P}中具有黄金上下文的篇章的映射。对于其他数据集,BM25可以用于获取包含回答的前1篇章。也可以使用BM25负例和批量负例。此外,为了改进在给定正文档的情况下从文档级获取中找到正篇章的模型能力,可以将文档内负例和章节内负例用于所获取的篇章。文档内负例可以是与正篇章在同一文档中、不包含回答的篇章,而章节内负例可以是与正篇章在同一章节中、不包含回答的其他篇章。
因此,在推断时间期间,应用文档级获取器502来选择前k
因此,来自密集文档获取和密集篇章获取两者的获取排序和/或相关性得分有助于经重新排序的前k
图6示出了根据一些实施方案的用于使用图3、图4和图5中描述的文档级获取器和篇章级获取器在深度学习中对基于语义的篇章进行分层获取的流程图的简化图。方法600的过程602至614中的一个或多个过程可以至少部分地以存储在非暂态有形机器可读介质上的可执行代码的形式来实现,可执行代码当由一个或多个处理器运行时可以使一个或多个处理器执行过程602至614中的一个或多个过程。在一些实施方案中,方法600可以由图1和图2的环境110中的一个或多个计算设备执行。
深度学习模块330的模型使用数据解析、提取、编码、转换和QA预测过程以基于文档级获取模型和篇章级获取模型来执行在数据库系统(例如,系统116)中对基于语义的篇章和/或文档的密集分层获取。在一些实施方案中,这些包括可以作为数据库系统的标准并且被提供给CRM或其他系统的客户的文档和文档的语料库(例如,文章、百科全书条目、培训材料、客户帮助请求和回答、以及可能与特定数据库系统相关的其他文档)。
为了实现这一点,并且参考图4和图5,方法600开始于过程602。在过程602处,深度学习模块330接收针对文档的语料库的问题,其中语料库中的文档与篇章的相应集合相关联。文档的语料库可以对应于文档的语料库504,并且可以包括类似于文档400的文档,诸如信息文章、百科全书条目、帮助请求、培训手册、小册子或提供信息的其他主题相关文章。问题501可以对应于作为用于开放域QA的查询的输入问题。在过程604处,访问文档的语料库和经编码文档的索引。例如,密集文档级获取模型可以用于生成文档(包括文档400和/或来自文档的语料库504的文档)的编码,其可以被指定为E
在过程606处,对问题进行编码。问题501可以被编码为E
在过程610处,基于文档相关性得分从文档过滤无关文档。例如,前k
在过程614处,获得针对问题的前位评级篇章。使用经编码篇章E
对于上述过程,可以在训练数据上训练一个或多个神经网络模型。在一些实施方案中,为了训练,神经网络可以对训练数据执行预处理,例如,针对训练文本中的每个字词、字词的一部分、或字符。例如,利用神经网络的一个或多个编码层对嵌入进行编码以生成相应向量。预处理层为文本输入序列中的每个字词生成嵌入。每个嵌入可以是向量。在一些实施方案中,这些可以是诸如通过运行方法如word2vec、FastText或GloVe获得的字词嵌入,这些方法中的每个方法限定学习具有有用属性的字词向量的方式。在一些实施方案中,可以使用特定维度的预训练向量。在一些实施方案中,嵌入可以包括与字词的部分相关的部分字词嵌入。例如,字词“where”包括部分“wh”、“whe”、“her”、“ere”和“re”。部分字词嵌入可以帮助利用子词信息/FastText丰富字词向量。类似地,当将预处理层应用于来自训练数据的字词和/或短语时,可以基于文档和文档结构内的字词序列来生成字词向量序列。在一些情况下,例如用于训练的文本输入序列可以包括很少字词,在这种情况下,从预处理层输出的嵌入可以例如用零来“填充”。掩膜层掩蔽这种数字,使得它们在后续层中被忽略或不被处理,例如,以帮助减少训练时间。
编码层从文本输入序列的字词中学习高级特征。每个编码层生成将文本输入序列中的字词映射到更高维空间的编码(例如,向量)。编码可以对字词之间的语义关系进行编码。在一些实施方案中,编码层或编码器堆叠用循环神经网络(RNN)来实现。RNN是处理可变长度的向量序列的深度学习模型。这使得RNN适合于处理字词向量的序列。在一些实施方案中,编码层可以用一个或多个门控循环单元(GRU)来实现。GRU是旨在使用通过节点序列的连接来执行任务的机器学习的循环神经网络(RNN)的特定模型。GRU帮助调整神经网络输入权重以解决RNN常见的梯度消失问题。在一些实施方案中,编码层可以用一个或多个长期短期记忆(LSTM)编码器来实现。
多个GRU可以按行布置。第一行GRU在第一(例如,“前向”)方向上查看或操作文本输入序列中的相应字词的信息(例如,嵌入或编码),其中每个GRU生成对应状态向量并将向量传递到行中的(例如,如从左指向右的箭头所指示的)下一GRU。第二行GRU在第二(例如,“后向”)方向上查看或操作输入序列中的相应字词的信息(例如,嵌入或编码),其中每个GRU生成对应隐藏状态向量并将向量传递到该行中的下一GRU。嵌入矩阵的权重(值)可以随机和/或单独初始化,并且在训练时间使用反向传播来更新/学习。
根据一些实施方案,可以在对机器学习引擎和/或神经网络模型(具有其他特征)进行其分类任务训练的同时,端到端地学习嵌入。训练将导致每字符、字词、短语或句子具有一个向量,并将这些向量聚类。例如,具有类似嵌入的两个字符、字词、短语或句子将最终具有比远嵌入更近的类似向量。然后,嵌入在相应的展平器处被展平和/或在相应级联器处被级联。
使用经级联的特征或向量来训练神经网络的模型。为了训练,神经网络可以包括或实现有具有一个或多个层的多层或深度神经网络或神经模型。根据一些实施方案,多层神经网络的示例包括ResNet-32、DenseNet、PyramidNet、SENet、AWD-LSTM、AWD-QRNN和/或类似的神经网络。ResNet-32神经网络在He等人于2015年12月10日提交的“Deep ResidualLearning for Image Recognition”(arXiv:1512.03385)中更详细地描述;DenseNet神经网络在Iandola等人于2014年4月7日提交的“Densenet:Implementing Efficient ConvnetDescriptor Pyramids”(arXiv:1404.1869)中更详细地描述;PyramidNet神经网络在Han等人于2016年10月10日提交的“Deep Pyramidal Residual Networks”(arXiv:1610.02915)中更详细地描述;SENet神经网络在Hu等人于2017年9月5日提交的“Squeeze-and-Excitation Networks”(arXiv:1709.01507)中更详细地描述;AWD-LSTM神经网络在Bradbury等人于2016年11月5日提交的“Quasi-Recurrent Neural Networks”(arXiv:1611.01576)中更详细地描述;这些文献中的每个文献以引用方式并入本文中。
每个神经网络层可以操作或处理特征或向量,从而执行例如正则化(例如,L2和L1正则化、提前停止等)、归一化和激活。在一些实施方案中,每个神经网络层可以包括用于深度学习的密集层、批量归一化和丢弃。在一些实施方案中,在每层的末端处的相应修正线性单元(ReLU)执行ReLU激活功能。神经网络的输出层执行softmax函数以产生或生成用于所有上下文的一个单一模型。全局模型预测用于当前查询的样例对象或进入数据库系统(诸如系统116)的测试样例对象。在一些实施方案中,模型包括或表示相对于给定训练文档和/或文档结构(例如,具有篇章和文档结构的一个或多个文档的语料库)的文档和/或文档结构(无论是标准的还是定制的)内的嵌入的概率分布。对于分布,每个嵌入具有表示或指示这种嵌入与当前搜索的相关性的对应数值。在一些实施方案中,可以利用称为混合Softmax(MoS)的高秩语言模型来实现softmax层,以减轻softmax瓶颈问题。
如上所述以及在此进一步强调的,图3、图4、图5和图6仅仅是用于训练和使用的深度学习模块330和对应方法600的示例,其不应不当地限制权利要求书的范围。本领域普通技术人员将认识到许多变化、替代和修改。
计算设备(诸如计算设备300)的一些示例可以包括非暂态有形机器可读介质,其包括可执行代码,可执行代码当由一个或多个处理器(例如,处理器310)运行时可以使一个或多个处理器执行方法600的过程。可以包括方法600的过程的机器可读介质的一些常见形式是例如软盘、柔性盘、硬盘、磁带、任何其他磁介质、CD-ROM、任何其他光学介质、打孔卡、纸带、任何其他具有孔图案的物理介质、RAM、PROM、EPROM、闪存EPROM、任何其他存储器芯片或盒、和/或处理器或计算机适于从其进行读取的任何其他介质。
尽管已经示出和描述了例示性实施方案,但是在前述公开内容中可以设想各种各样的修改、改变和替换,并且在一些情况下,可以采用实施方案的一些特征而不对应地使用其他特征。本领域普通技术人员将认识到许多变化、替代和修改。因此,本申请的范围应当仅由所附权利要求书限定,并且应当以与本文公开的实施方案的范围相一致的方式来宽泛地解释权利要求书。
- 一种新型土壤中全钙的测定液及其制备方法、土壤中全钙的测定方法
- 一种高铝、铁含量土壤中全钙的测定方法