一种对电子病历问答模型输出结果标准化的数据处理系统
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及文本处理技术领域,特别是涉及一种对电子病历问答模型输出结果标准化的数据处理系统。
背景技术
随着医疗业务量的不断增长以及人工智能技术的不断发展,病历电子化已成为趋势,准确的电子病历的问答系统成为热门研究方向,对模型输出的结果进行准确的标准化处理能够更加易于访问、管理和统计,医护人员可以更快地诊断和治疗,并为智能医疗的发展提供条件。
目前,现有技术中,进行标准化处理的方法为:将模型输出的结果与标准数据库中的数据进行相似度计算,从而实现对结果的标准化处理。
综上所述对文本进行分类的方法存在的问题:获取目标优先级时局限于一种方法获取,降低了获取到的实体对应优先级的准确度,从而使得基于电子病历问答模型输出结果对应的标准化结果不够准确。
发明内容
本发明提供了一种对电子病历问答模型输出结果标准化的数据处理系统,包括:一种对电子病历问答模型输出结果标准化的数据处理系统,所述系统包括:处理器和存储有计算机程序的存储器,当所述计算机程序被处理器执行时,实现以下步骤:
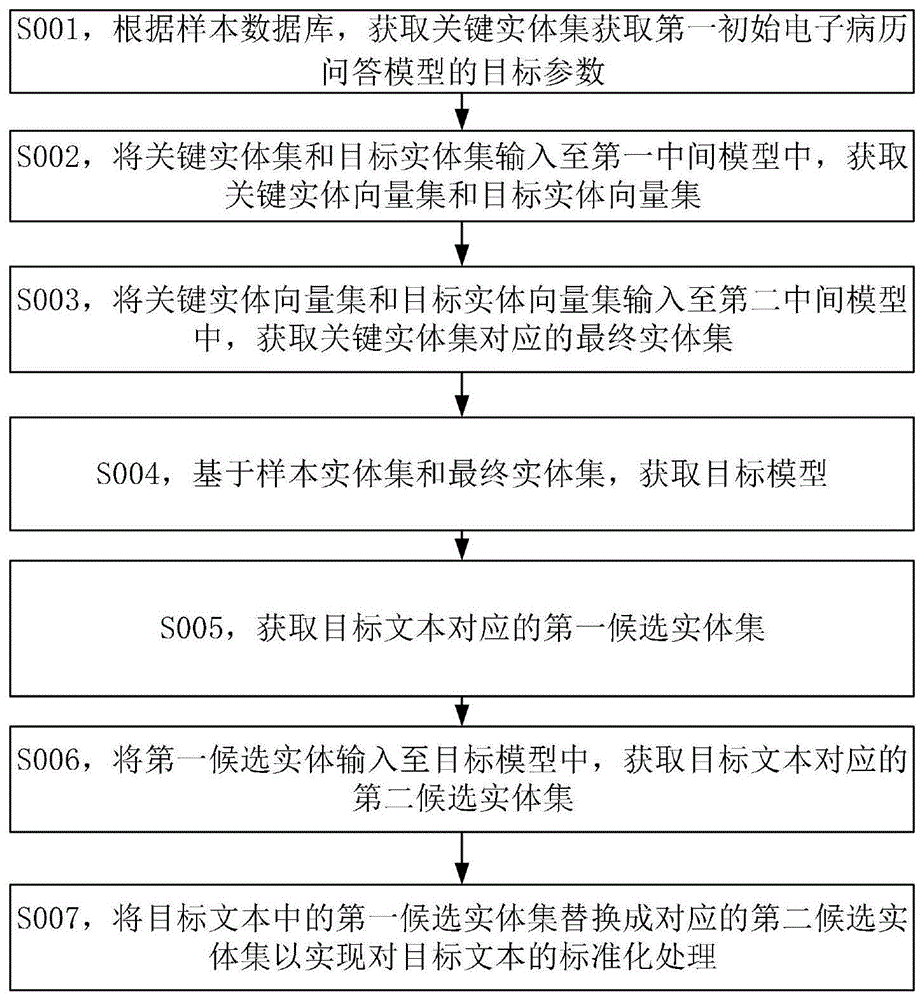
S001,根据样本数据库,获取关键实体集,其中,所述关键实体集包括若干个关键实体,所述关键实体为基于样本数据库获取到的与异常状态相关的实体。
S002,将关键实体集和目标实体集输入至第一中间模型中,获取关键实体向量集和目标实体向量集。
S003,将关键实体向量集和目标实体向量集输入至第二中间模型中,获取关键实体集对应的最终实体集,其中,所述第二中间模型为预设的神经网络模型。
S004,基于样本实体集和最终实体集,获取目标模型,其中,所述目标模型为基于样本实体集获取最终实体集过程训练出的模型。
S005,获取目标文本对应的第一候选实体集,其中,所述第一候选实体集包括若干个第一候选实体,所述第一候选实体为从目标文本中获取到的实体。
S006,将第一候选实体输入至目标模型中,获取目标文本对应的第二候选实体集,其中,所述第二候选实体集包括若干个第二候选实体,所述第二候选实体为基于第一候选实体和目标模型获取到的第一候选实体对应的目标实体中的实体。
S007,将目标文本中的第一候选实体集替换成对应的第二候选实体集以实现对目标文本的标准化处理。
本发明为一种对电子病历问答模型输出结果标准化的数据处理系统,系统包括:处理器和存储有计算机程序的存储器,当计算机程序被处理器执行时,实现以下步骤:根据样本数据库,获取关键实体集,将关键实体集和目标实体集输入至第一中间模型中,获取关键实体向量集和目标实体向量集,将关键实体向量集和目标实体向量集输入至第二中间模型中,获取关键实体集对应的最终实体集,基于样本实体集和最终实体集,获取目标模型,获取目标文本对应的第一候选实体集,将第一候选实体输入至目标模型中,获取目标文本对应的第二候选实体集以实现对目标文本的标准化处理,将目标文本中的第一候选实体集替换成对应的第二候选实体集以实现对目标文本的标准化处理,本发明获取目标优先级时不局限于一种方法获取,通过将多种方法进行结合的方法,获取到实体对应的最终的优先级,提高了获取到实体对应优先级的准确度,从而使得基于电子病历问答模型输出结果对应的标准化结果更加准确。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种对电子病历问答模型输出结果标准化的数据处理系统的执行计算机程序的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包括,例如,包括了一系列步骤或单元的过程、方法、系统、产品或服务器不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
实施例
一种对电子病历问答模型输出结果标准化的数据处理系统,所述系统包括:处理器和存储有计算机程序的存储器,当所述计算机程序被处理器执行时,实现以下步骤,如图1所示:
S001,根据样本数据库,获取关键实体集,其中,所述关键实体集包括若干个关键实体,所述关键实体为基于样本数据库获取到的与异常状态相关的实体。
具体的,所述样本数据库包括若干个与异常状态相关的信息,例如药物数据表、人体部位、ICD-10标准词库、症状体征和传染病等与异常状态相关的信息。
进一步的,在001中通过如下步骤获取关键实体:
S0011,根据样本数据集,获取样本实体集,其中,所述样本实体集包括若干个样本实体,所述样本实体为从样本数据集中获取到的与异常状态相关的实体,可以理解为:样本数据集中包括了大量描述与异常状态相关的文本,从这些文本中提取出与医疗领域相关联的术语,这些术语就是获取到的样本实体。
具体的,所述样本实体集包括的样本实体的数量为百万级。
进一步的,本领域知晓,现有技术中任一从文本中提取实体的方法,均落入本发明的保护范围,在此不再赘述。
S0013,根据样本实体集,获取第一样本实体集,其中,所述第一样本实体集包括如干个第一样本实体,所述第一样本实体为基于LLM模型获取到的与样本实体相似的实体。
具体的,本领域技术人员知晓,现有技术中任一基于LLM模型获取相似实体的方法,均落入本发明的保护范围,在此不再赘述,例如chatglm等LLM模型。
S0015,根据第一样本实体集,获取第二样本实体集,其中,所述第二样本实体集包括若干个第二样本实体,所述第二样本实体为与第一样本实体无相似特征的实体。
具体的,本领域技术人员知晓,现有技术中任一基于实体特征获取与实体无相似特征实体的方法,均落入本发明的保护范围,在此不再赘述,例如通过FM模型、FFM模型等模型获取与实体无相似特征的实体。
S0017,基于样本实体集、第一样本实体集和第二样本实体集,获取关键实体集,其中,所述关键实体集包括样本实体集、第一样本实体集和第二样本实体集。
具体的,所述关键实体集中关键实体的数量为千万级,其中,本领域技术人员知晓,可根据实际需求进行第一样本实体与第二样本实体比例的选取,均落入本发明的保护范围,在此不再赘述。
S002,将关键实体集和目标实体集输入至第一中间模型中,获取关键实体向量集和目标实体向量集。
具体的,所述目标实体集包括若干个目标实体,其中,所述目标实体为与异常状态相关的标准术语。
具体的,所述第一中间模型为将文本转换成向量的模型,其中,本领域技术人员知晓,可根据实际需求进行任一将文本转换成向量的自然语言处理模型,均落入本发明的保护范围,在此不再赘述,例如bert模型等自然语言处理模型。
具体的,所述关键实体向量集包括若干个关键实体向量,其中,所述关键实体向量为关键实体对应的向量。
进一步的,所述目标实体向量集包括若干个目标实体向量,其中,所述目标实体向量为目标实体对应的向量。
S003,将关键实体向量集和目标实体向量集输入至第二中间模型中,获取关键实体集对应的最终实体集,其中,所述第二中间模型为预设的神经网络模型。
具体的,在S003中通过如下步骤获取最终实体集:
S0031,从关键实体向量集中获取任一关键实体向量XY=(XY
S0032,获取目标实体向量集ZH={ZH
S0033,根据XY和ZH,获取XY对应的第一中间优先级列表XH={XH
上述,在获取实体对应的优先级时,不局限于一种方法获取,通过将多种方法进行结合的方法,获取到实体对应的最终的优先级,提高了获取到实体对应优先级的准确度,从而使得基于电子病历问答模型输出结果对应的标准化结果更加准确。
S0035,根据XH,获取XY对应的最终实体,其中,当XH
S004,基于样本实体集和最终实体集,获取目标模型,其中,所述目标模型为基于样本实体集获取最终实体集过程训练出的模型。
S005,获取目标文本对应的第一候选实体集,其中,所述第一候选实体集包括若干个第一候选实体,所述第一候选实体为从目标文本中获取到的实体。
具体的,本领域技术人员知晓,现有技术中任一从文本中获取实体的方法,均落入本发明的保护范围,在此不再赘述。
具体的,在S005中通过如下步骤获取目标文本:
S100,根据样本电子病历信息集,获取指定文本向量集。
具体的,所述样本电子病历信息集包括若干个样本电子病历信息,其中,所述样本电子病历信息为从数据库中获取到的病历中对应的异常状态特征信息,其中,所述异常状态特征信息为与疾病相关联的特征信息,例如异常糖链糖蛋白tap处于检测异常、鼻咽呈现低分化鳞癌等异常状态特征信息。
进一步的,本领域技术人员知晓,可根据实际需求进行任一可获取病例的医学公用数据库的选取,均落入本发明的保护范围,再次不再赘述。
进一步的,所述样本电子病历信息的数据格式包括文本格式和表格格式。
具体的,所述系统中还包括目标术语知识图谱,其中,所述目标术语知识图谱呈现三元组形态,其中,目标术语知识图谱中每个三元组形态包括两个与异常状态相关的实体以及两个与异常状态相关的实体之间的关系。
进一步的,本领域技术人员知晓,现有技术中任一基于目标术语构建知识图谱的方法,均落入本发明的保护范围,在此不再赘述。
具体的,在S100中还包括如下步骤:
S1,根据样本电子病历信息集,获取候选文本集A={A
具体的,在S1中通过如下步骤获取候选文本:
S11,当样本电子病例信息的数据格式为文本格式时,将样本电子病例信息按照分割符号进行切分以生成候选文本。
S13,当样本电子病例信息的数据格式为表格格式时,将样本电子病例信息中每个记录以及记录对应的字段名称进行整合以生成候选文本,可以理解为:当样本电子病例信息中每个字段对应的字段名称从左到右依次为ID、活检部位、组织学分类时,样本电子病例信息中某一行的内容从左到右依次为008号、鼻咽、鳞状细胞癌时,获取到一个候选文本为:ID为008号的活检部位为鼻咽,组织学分类为鳞状细胞癌。
S3,根据A和目标术语知识图谱,获取A对应的候选关键词集Q={Q
具体的,在S3中通过如下步骤获取Q
S31,根据A,获取A对应的第一中间词集B={B
具体的,所述第一中间词为从候选文本中获取到的词,其中,本领域技术人员知晓,现有技术中任一从文本中提取词的方法,均落入本发明的保护范围,在此不在赘述。
S33,根据目标术语知识图谱,获取目标词列表D={D
具体的,所述目标词为从目标术语知识图谱中获取到的与异常状态相关的实体。
S35,根据B和D,获取B对应的第一中间相似度集F={F
具体的,所述第一中间相似度为第一中间词对应的词向量与目标词对应的词向量之间的相似度,其中,本领域技术人员知晓,现有技术中任一计算向量之间相似度的方法,均落入本发明的保护范围,在此不再赘述。
进一步的,所述第一中间词对应的词向量的方法为将第一中间词向量输入至自然语言处理模型中获取到的词对应的向量,其中,本领域技术人员知晓,现有技术中任一将文本转换成向量的自然语言处理模型,均落入本发明的保护范围,在此不再赘述。
S37,当F
具体的,F
S5,根据A和Q,获取初始文本集T={T
具体的,所述初始文本为将候选文本与候选关键词进行拼接且候选关键词拼接在候选文本之后的文本。
S7,根据T,获取指定文本集U={U
S71,根据T
S72,当p+q=K时,获取U
具体的,在S72中通过如下步骤获取K:
S721,根据T,获取关键文本类型集C={C
具体的,所述关键文本为基于初始文本对应的文本类型从T中获取到的初始文本,其中,本领域技术人员知晓,现有技术中任一对文本进行分类的方法,均落入本发明的保护范围,在此不再赘述,例如通过文本的关键词对文本进行分类的方法,其中,文本类型例如分为心脏类型和眼鼻喉类型等初始文本对应的文本类型。
S723,根据C,获取C对应的第一文本字符串数量集C
具体的,所述第一文本字符串数量为关键文本对应的文本字符串数量。
S725,根据C
具体的,所述第二文本字符串数量为根据第一文本字符串数量按照从大到小的顺序依次获取到的文本字符串数量。
进一步的,所述文本字符串数量为文本对应的文字字符串数量。
S725,根据C
其中,C
具体的,
具体的,ε的取值范围为0.85~1,其中,本领域技术人员知晓,可根据实际需求进行ε的选取,均落入本发明的保护范围,在此不再赘述。
上述,基于关键文本的类型以及每个类型关键文本对应文本字符串的数量获取到预设的关键优先级阈值,使得初始文本对应的文本字符串的数量统一,结合文本的类型统一文本字符串的数量保证了后续获取到的指定文本向量对应的文本的全面性,基于每个类型关键文本对应文本字符串的数量设置阈值提高了获取到的文本字符串数量统一值的准确度,通过合理设置阈值,既能够避免文本字符串长度过短易造成文本数据的缺失的问题,也能避免文本字符串长度过长造成文本数据处理效率降低的问题,进而提高了后续获取到的指定文本向量集的准确度。
S73,当p+q>K时,获取Q对应的候选优先级集P={P
具体的,在S73中通过如下步骤获取P
S731,获取候选关键词列表Q
S733,根据目标术语知识图谱,获取Q
具体的,所述指定关键词为从目标术语知识图谱中获取到的与候选关键词相关联的目标词。
具体的,所述指定优先级为候选关键词与指定关键词之间的关联程度,其中,本领域技术人员知晓,现有技术中任一获取两个文本之间关联程度的方法,均落入本发明的保护范围,在此不在赘述。
S735,根据Q
其中,M
S74,基于P,对WT
具体的,在S74中还包括如下步骤:
S741,根据P
S743,当β
S745,当β
S747,重复执行S743~S745,直到获取到的U
S75,当p+q<K时,获取Q
S76,根据R
具体的,在S76中还包括如下步骤:
S761,当G
S763,基于T
S765,根据H
上述,基于初始文本对应的文本字符串的数量对初始文本进行处理,当初始文本对应的文本字符串超过预先设置的长度阈值时,基于初始文本对应的候选关键词对应的优先级进行截断处理,当初始文本对应的文本字符串不足预先设置的长度阈值时,基于与初始文本对应的候选关键词相关联的文本进行补充处理,基于初始文本对应的文本字符串数量的不同采用不同的处理方式将初始文本对应的文本字符串的数量进行统一,提高了获取到的指定文本向量集的准确度。
S9,根据U,获取指定文本向量集,其中,所述指定文本向量集包括若干个指定文本向量,其中,所述指定文本向量为将指定文本输入至预训练电子病历编码模型中获取到的。
具体的,所述预训练电子病历编码模型为基于预训练模型对病历文本训练集进行训练获取到的将文本转换成向量的模型。
进一步的,本领域技术人员知晓,可根据实际需求进行预训练模型的选取,均落入本发明的保护范围,在此不再赘述,例如ERNIE预训练模型。
进一步的,所述病历文本训练集为基于不同的搜索引擎获取到的用于模型训练的病历文本集,所述病历文本集包括若干个不同类型和形式的病历文本。
进一步的,本领域技术人员知晓,现有技术中任一从多个搜索引擎获取文本的方法,均落入本发明的保护范围,在此不再赘述,其中,例如百度等搜索引擎。
S200,基于第一预设文本集和指定文本向量集,获取第一预设文本集对应的第一目标文本集。
具体的,所述第一预设文本集包括若干个第一预设文本,其中,所述第一预设文本为基于异常状态获取到的有关异常状态的问题文本。
进一步的,所述问题文本为以提问形式呈现要求进行回答和解释的文本,例如:促黄体生成素低于3的表现等问题文本。
进一步的,所述第一预设文本为通过医学公用数据库获取到的问题文本,其中,本领域技术人员知晓,现有技术中任一基于医学公用数据库获取与医学有关的问题的文本,均落入本发明的保护范围,在此不再赘述。
具体的,在S200中还包括如下步骤:
S201,获取第一预设文本向量集I={I
具体的,所述第一预设文本向量为将第一预设文本输入至预训练电子病历编码模型中获取到的。
S203,获取指定文本向量集
S205,根据I和
具体的,本领域技术人员知晓,现有技术中任一获取向量之间相似度的方法,均落入本发明的保护范围,在此不再赘述,例如余弦相似度等计算向量之间相似度的方法。
S207,当ER
具体的,ER
S300,基于第一预设文本集和第一目标文本集,获取第一预设文本集对应的第二目标文本集。
具体的,所述第二目标文本集包括若干个第二目标文本,其中,所述第二目标文本为基于第一预设文本和第一目标文本集通过prompt指令生成的与第一预设文本相关联的解释内容文本,例如,当第一预设文本涉及到心脏时,结合与之相关的第一目标文本和一些异常状态领域的相关知识将心脏进行简单的解释,将第一预设文本以及基于第一预设文本获取到的解释内容当作第二目标文本。
进一步的,本领域技术人员知晓,现有技术中任一prompt指令进行训练从而输出结果的方法,均落入本发明的保护范围,在此不再赘述。
上述,基于第一预设文本集和第一目标文本通过prompt指令生成第一预设文本集对应的第二目标文本集,对于每个问题文本,获取到与之对应的病历文本,通过prompt指令为其设置指示指令,有利于电子病历问答系统的理解和回复,提高了电子病历问答系统输出结果的准确度。
S400,将第一预设文本集和第二目标文本集输入至预设的第一初始LLM模型中,获取第一预设文本集对应的第三目标文本集。
具体的,所述第三目标文本集包括若干个第三目标文本,其中,所述第三目标文本为基于第一预设文本获取到的第一预设文本对应的答案文本和解释文本。
进一步的,所述答案文本为基于问题文本进行回答的文本。
进一步的,所述解释文本为基于问题文本获取到对答案文本进行解释说明的文本。
进一步的,在S400中通过如下步骤获取第三目标文本:
S401,根据第一预设文本和第一预设文本对应的第二目标文本,获取第一预设文本对应的ψ个第四目标文本,其中,所述第四目标文本为基于第二目标文本在多个LLM模型获取到的第一预设文本对应的答案文本和解释文本。
具体的,本领域技术人员知晓,现有技术中任一通过LLM模型输出结果的方法,均落入本发明的保护范围,在此不再赘述,其中,例如Baichuan-13B模型、LLaMA模型等LLM模型。
具体的,ψ的取值范围为30~50,其中,本领域技术人员知晓,可根据实际需求进行ψ的选取,均落入本发明的保护范围,在此不再赘述。
S403,根据第四目标文本,获取第四目标文本对应的优选优先级,其中,所述优选优先级为基于投票法获取到的分数值,其中,本领域技术人员知晓,现有技术中任一基于投票法获取分数的方法,均落入本发明的保护范围,在此不再赘述。
具体的,所述优选优先级的取值范围为0~1。
S405,根据优选优先级,获取第一预设文本对应的第三目标文本,其中,所述第三目标文本为最大优选优先级对应的第四目标文本。
S500,将第一目标文本集、第二目标文本集和第三目标文本集作为训练集输入至预设的第二初始LLM模型中,生成初始电子病历问答模型。
在另一个具体的实施例中,在S500之后还包括如下步骤:
S501,当初始电子病历问答模型对应的训练集的数据量大于预设的数据量阈值时,获取初始电子病历问答模型对应的候选参数列表ω={ω
具体的,所述候选参数为降低初始电子病历问答模型中训练集的训练时间而设置的矩阵对应的秩,其中,可以理解为:在LLM模型进行数据处理时会涉及到矩阵与矩阵之间相乘,当训练集的数据量如果过大,会造成训练效率的降低,因此为了减少训练集的训练时间需要设置一个秩稍微较小的矩阵帮助训练,而候选参数就是设置的这个矩阵的秩。
进一步的,预设的数据量阈值的取值范围为100GB~1TB,本领域技术人员知晓,可根据实际需求进行预设的数据量阈值的选取,均落入本发明的保护范围,在此不再赘述。
S502,根据ω,获取ω对应的第一中间优先级列表Tω={Tω
具体的,所述第一中间优先级为初始电子病历问答模型运行过程中GPU的占有率,其中,本领域技术人员知晓,现有技术中任一获取GPU占有率的方法,均落入本发明的保护范围,在此不再赘述。
S503,当第一预设文本为第一类第一预设文本时,基于预设权重类型获取ω对应的第二中间优先级集Eω={Eω
具体的,所述第一类第一预设文本为第一预设文本为单独的问题且与其它问题无关联性的问题文本。
具体的,所述第二中间优先级为基于候选参数和第一类第一预设文本在不同预设权重类型下获取到的初始电子病历问答模型对应的分数值,其中,本领域技术人员知晓,现有技术中任一基于不同条件获取模型对应的方法,均落入本发明的保护范围,在此不再赘述。
具体的,所述预设权重类型为计算权重的矩阵类型,其中,可以理解为:在Transformer架构中,自注意模块中有四个权重矩阵(Wq、Wk、Wv、Wo),其中将Wq(或Wk,Wv)视为单个方矩阵。
具体的,4≤τ≤30。
优选地,τ的取值为6,其中,当τ取6时,既能避免进行大量测试导致效率较低的问题,又能保证测试的全面性。
S504,当第一预设文本为第二类第一预设文本时,基于预设权重类型获取ω对应的第三中间优先级集Lω={Lω
具体的,所述第二类第一预设文本为第一预设文本中包括多个问题且每个问题之间有关联的问题文本。
具体的,所述第三中间优先级为基于候选参数和第二类第一预设文本在不同预设权重类型下获取到的初始电子病历问答模型对应的分数值。
进一步的,所述第三中间优先级的获取方式与所述第二中间优先级的获取方式一致。
S505,根据Tω、Eω和Lω,获取ω对应的最终优先级列表Fω={Fω
S506,根据Fω,获取ω
上述,通过初始电子病历问答模型的候选参数获取到初始电子病历问答模型的性能,通过设置候选参数,能够节约模型训练的时间,不易造成资源的浪费,同时不会影响到模型本身的推理能力和相应能力,同时对参数进行调整,使得电子病历问答模型输出的结果更加准确。
S600,将第二预设文本集输入至初始电子病历问答模型中,获取初始电子病历问答模型对应的待选优先级。
具体的,所述第二预设文本集包括若干个第二预设文本,其中,所述第二预设文本为用于测试初始电子病历问答模型效果的有关异常状态的问题文本。
具体的,在S600中通过如下步骤获取待选优先级:
S601,将第二预设文本集输入至初始电子病历问答模型中,获取第二预设文本集对应的第一关键文本集EP={EP
具体的,所述第一关键文本为基于初始电子病历问答模型获取到的第二预设文本对应的答案文本和解释文本。
S603,根据EP,获取EP对应的第一关键文本向量集EP
具体的,所述第一关键文本向量为将第一关键文本输入至预训练电子病历编码模型中获取到的。
S605,获取第二预设文本集对应的第二关键文本集FP={FP
具体的,所述第二关键文本为第二预设文本对应的准确的答案文本和解释文本。
S607,根据FP,获取FP对应的第二关键文本向量集FP
具体的,所述第二关键文本向量的获取方式与所述第一关键文本向量的获取方式一致。
S609,根据EP
/>
在另一个具体的实施例中,在S600中通过如下步骤获取待选优先级:
S610,将第二预设文本集输入至初始电子病历问答模型中,获取第一初始文本集EW={EW
具体的,所述第一初始文本为从第一关键文本集中获取到的中英文比例在预设比例范围的第一关键文本。
进一步的,所述第一关键文本集包括若干个第一关键文本,其中,所述第一关键文本为基于初始电子病历问答模型获取到的第二预设文本对应的答案文本和解释文本。
进一步的,所述答案文本为基于问题文本进行回答的文本。
进一步的,所述解释文本为基于问题文本获取到对答案文本进行解释说明的文本。
进一步的,所述预设比例范围为tr
进一步的,tr
进一步的,所述样本文本为将预设样本文本输入至初始电子病历问答模型中输出的文本,其中,所述预设样本文本的性质与第一预设文本的性质一致,预设样本文本的获取方式可参照第一预设文本的获取方式。
S620,根据EW,获取第一初始文本向量集EW
具体的,所述第一初始文本向量为将第一初始文本输入至预训练电子病历编码模型中获取到的。
S630,根据第一初始文本集,获取第二初始文本集FW={FW
具体的,所述第二初始文本为第一初始文本对应的第二预设文本准确的答案文本和解释文本。
S640,根据FW,获取FW对应的第二初始文本向量集FW
具体的,所述第二初始文本向量的获取方式与第一初始文本向量的获取方式一致。
S650,根据EW
S660,根据EW,获取EW对应的第一初始关键词集,其中,所述第一初始关键词集包括若干个第一初始关键词列表,所述第一初始关键词列表包括一个第一初始关键词,所述第一初始关键词为第一初始文本中的关键词。
具体的,所述第一关键词为从第一初始文本中获取到的与目标术语知识图谱中的目标词相似的词、
具体的,所述第一初始关键词的获取方式与所述候选关键词的获取方式一致,可参照S31步骤~S37步骤。
S670,根据FW,获取FW对应的第二初始关键词集,所述第二初始关键词集包括若干个第二初始关键词列表,所述第二初始关键词列表包括一个第二初始关键词,所述第二初始关键词为第二初始文本中的关键词。
具体的,所述第二初始关键词的获取方式与第一初始关键词的获取方式一致。
S680,获取第一初始关键词集和第二初始关键词集,获取第二相似度列表ΔV={ΔV
具体的,所述ΔV
S690,根据ΔW和ΔV,获取初始电子病历问答模型对应的待选优先级KL。
具体的,在S690中通过如下步骤获取KL:
S691,当ΔW
具体的,ZM
S693,当ΔW
其中,ZM
具体的,ZM
S695,当ΔW
上述,基于第一相似度和第二相似度的不同,设置不同的计算待选优先级的相关系数,基于不同维度设置不同的相关系数使得获取到的待选优先级更加准确,基于不同维度获取电子病历问答模型对应的候选优先级,同时基于不同的情况采用不同的方式获取到待选优先级,通过合理设置优先级,使得电子病历问答系统输出的结果更加准确。
S700,基于待选优先级,对初始电子问答模型进行参数调整,直到待选优先级不小于预设的待选优先级阈值时以获取到目标电子病历问答模型。
具体的,所述预设的待选优先级阈值的取值范围为0.7~0.9,其中,本领域技术人员知晓,本领域技术人员可根据实际需求进行预设的待选优先级阈值的选取,均落入本发明的保护范围,在此不再赘述。
具体的,本领域技术人员知晓,现有技术中任一对训练模型进行参数调整的过程,均落入本发明的保护范围,在此不再赘述。
S800,获取预设关键文本,将预设关键文本输入至目标电子病历问题模型中获取目标文本,其中,所述预设关键文本为待查询的基于异常状态获取到的有关异常状态的问题文本,所述目标文本为预设关键文本对应的答案文本和解释文本。
上述,将LLM模型应用于电子病历问答上,能够对大规模数据进行处理,降低了电子病历问答模型的应用的局限性,通过prompt指令为其设置指示指令,有利于电子病历问答系统的理解和回复,提高了电子病历问答系统输出结果的准确度。
S006,将第一候选实体输入至目标模型中,获取目标文本对应的第二候选实体集,其中,所述第二候选实体集包括若干个第二候选实体,所述第二候选实体为基于第一候选实体和目标模型获取到的第一候选实体对应的目标实体中的实体。
S007,将目标文本中的第一候选实体集替换成对应的第二候选实体集以实现对目标文本的标准化处理。
上述,通过对电子病历问答模型输出的结果进行标准化处理,方便后续进行数据的查询和统计。
本实施例提供了一种对电子病历问答模型输出结果标准化的数据处理系统,系统包括:处理器和存储有计算机程序的存储器,当计算机程序被处理器执行时,实现以下步骤:根据样本数据库,获取关键实体集,将关键实体集和目标实体集输入至第一中间模型中,获取关键实体向量集和目标实体向量集,将关键实体向量集和目标实体向量集输入至第二中间模型中,获取关键实体集对应的最终实体集,基于样本实体集和最终实体集,获取目标模型,获取目标文本对应的第一候选实体集,将第一候选实体输入至目标模型中,获取目标文本对应的第二候选实体集以实现对目标文本的标准化处理,将目标文本中的第一候选实体集替换成对应的第二候选实体集以实现对目标文本的标准化处理,本发明获取目标优先级时不局限于一种方法获取,通过将多种方法进行结合的方法,获取到实体对应的最终的优先级,提高了获取到实体对应优先级的准确度,从而使得基于电子病历问答模型输出结果对应的标准化结果更加准确。
虽然已经通过示例对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员还应理解,可以对实施例进行多种修改而不脱离本发明的范围和精神。本发明开的范围由所附权利要求来限定。
- 用于级联感测的具有两个感测节点的感测电路
- 一种指纹感测电路及指纹感测装置
- 触控装置及其感测方法与触控感测电路
- 具讯号补偿的感测电路
- 附于电脑周边具侦测生理讯号与感测亮度的电路装置