一种用于知识图谱实体对齐的初始对齐种子生成方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于知识融合和人工智能领域,特别是涉及一种用于知识图谱实体对齐的初始对齐种子生成方法。
背景技术
作为一种可以存储结构化知识的语义网络,知识图谱对现实世界中大量实体(即节点)及其关系(即边)进行了建模。随着大数据时代的到来,数据量呈现井喷式增长,知识图谱也从学术圈朝着适合现代化企业的大规模知识图谱转变。大规模的多语言知识图谱,如DBpedia、WordNet等,已经作为丰富的知识来源被应用到搜索、医疗、电商、教育等领域。
在知识图谱领域,无论是搜索引擎、推荐系统还是问答系统等应用场景,都会涉及到实体对齐(Entity Alignment,EA)问题,即链接和统一不同来源的知识图谱,找到引用同一现实世界对象的实体,使得大规模的多语言知识图谱之间可以高效协调。实体对齐通过消除概念的歧义,剔除冗余和错误概念,从而确保知识的质量。从本质上看,实体对齐是一个知识融合问题,是知识图谱应用的重要预处理步骤。
由于人工智能技术的快速发展,嵌入技术被广泛应用于实体对齐。大多数基于嵌入的方法假设相同的实体在其知识图谱中具有相似的网络结构,因此它们利用结构信息将实体编码为向量以促进对齐任务。一般来说,这些基于图结构的嵌入方法会产生合理的对齐结果,但它们也很容易受到一些限制,特别是对齐种子的高昂成本。为了克服这些限制,出现了各种无监督方法,它们利用名称信息、属性信息、描述信息和图像信息等辅助信息来生成初始对齐种子,以此驱动图结构主导的嵌入方法。其中,仅利用名称信息生成初始对齐种子的方法是最具实用性的,可分为以下两大类:
一、基于字符串相似度的方法。主要包括Levenshtein,其是一种著名的编辑距离度量,用于评估两个实体之间的名称相似度;
二、基于语义相似度的方法。主要包括:(1)Avg,对相应的令牌嵌入以相同权重加权形成一个表示实体的新嵌入;(2)CPM,将平均词嵌入的概念推广到幂次平均词嵌入;(3)NEAP,其先使用TF-IDF计算令牌对实体的重要性(令牌级局部特征),然后利用预训练模型计算不同令牌之间的语义相似度(令牌级全局特征),最后,基于令牌级局部特征和令牌级全局特征构造实体对齐矩阵。
基于字符串相似度的方法的优点是速度快,但生成的种子质量较低。而基于语义相似度的方法由于利用了丰富的语义信息,能生产较高质量的对齐种子,但时间和空间复杂度较高。
发明内容
本发明的目的是提供一种用于知识图谱实体对齐的初始对齐种子生成方法,以解决上述现有技术存在的问题。
为实现上述目的,本发明提供了一种用于知识图谱实体对齐的初始对齐种子生成方法,包括:
确定待进行实体对齐的两个知识图谱,分别对每个知识图谱中的每个实体名称进行分解,获得令牌集合,分解所述令牌集合中的每个令牌,获得字符词表;
基于所述字符词表获得字符级全局特征矩阵;
基于字符词表与令牌集合计算每个知识图谱的字符级局部特征矩阵;
基于所述字符级全局特征矩阵与所述字符级局部特征矩阵获得令牌级全局特征矩阵;
基于令牌集合与知识图谱的实体集合获得令牌级局部特征矩阵;
基于所述令牌级全局特征矩阵与所述令牌级全局特征矩阵获得实体对齐矩阵,基于实体对齐矩阵获得初始对齐种子。
可选的,获得字符级全局特征矩阵的过程包括:
将每个知识图谱的字符词表中每个字符编码为独热向量,获得第一字符向量矩阵与第二字符向量矩阵,对所述第一字符向量矩阵与所述第二字符向量矩阵进行余弦相似度操作,获得字符级全局特征矩阵。
可选的,基于字符词表与令牌集合计算每个知识图谱的字符级局部特征矩阵,所述字符级局部特征矩阵包括第一字符级局部特征矩阵与第二字符级局部特征矩阵,字符级局部特征矩阵的每个元素通过如下公式获得:
其中,
可选的,计算令牌级全局特征矩阵的公式如下:
其中,
可选的,基于令牌集合与知识图谱的实体集合获得知识图谱对应的令牌级局部特征矩阵,所述令牌级局部特征矩阵包括第一令牌级局部特征矩阵与第二令牌级局部特征矩阵,字符级局部特征矩阵的每个元素通过如下公式获得:
其中,
可选的,计算实体对齐矩阵的公式如下:
其中,
可选的,从所述实体对齐矩阵中根据相似度选取实体对,获得实体对齐的初始对齐种子。
本发明的技术效果为:
本发明仅利用实体名称的非语义信息,在不使用预训练模型的情况下更快、更准确地生成了实体对齐的初始种子,具有较低的时间和空间复杂度;生成的高质量初始种子能驱动基于图结构的有监督深度学习模型将实体编码成向量,使得实体向量之间的距离能更加反应实体之间的相似性,使得基于图结构的有监督深度学习模型不再需要标签数据;可以广泛地用于解决搜索引擎、推荐系统、问答系统等应用场景中的知识融合问题。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
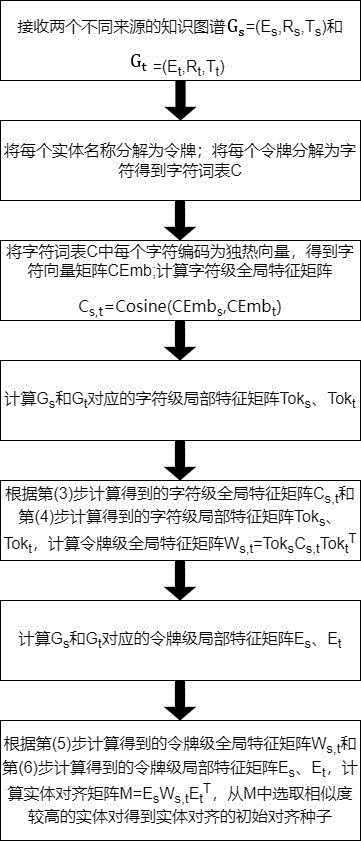
图1为本发明实施例中的知识图谱实体对齐的初始种子生成方法流程图;
图2为本发明实施例中的名为“Blues de Saint Louis”的实体局部特征矩阵计算过程示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
实施例一
如图1至图2所示,本实施例中提供一种用于知识图谱实体对齐的初始对齐种子生成方法,包括:
首先将NEAP定义的令牌级全局特征和令牌级局部特征推广到字符级,利用实体名称中每个令牌对应的字符级独热向量计算字符级全局特征矩阵,接着利用TF-IDF技术分别计算两个字符级局部特征矩阵和两个令牌级局部特征矩阵,然后根据字符级局部特征矩阵和令牌级局部特征矩阵构造令牌级全局特征矩阵以代替NEAP基于预训练模型生成的语义级全局特征矩阵;最后利用上述特征矩阵计算对齐矩阵并根据某种策略从中选取初始对齐种子。
具体步骤如下:
(1)假设有两个不同来源的知识图谱
(2)将每个实体名称
(3)将字符词表C中每个字符编码为独热向量,得到字符向量矩阵
(4)分别计算
(5)根据第(3)步计算得到的字符级全局特征矩阵
(6)分别计算
(7)根据第(5)步计算得到的令牌级全局特征矩阵
实施例二
本实施例假设有两个知识图谱
具体步骤如下:
(1)将
C={[(6,'d'),(4,'p'),(4,'r'),(0,'n'),(3,'m'),(1,'e'),(0,'s'),(3,'e'),(5,'c'),(2,'u'),(1,'o'),(3,'a'),(7,'y'),(1,'n'),(0,'a'),(6,'o'),(1,'p'),(4,'a'),(2,'r'),(3,'t'),(1,'a'),(5,'e'),(4,'s'),(8,'e'),(0,'v'),(7,'i'),(3,'p'),(0,'u'),(2,'n'),(2,'a'),(0,'h'),(1,'i'),(2,'p'),(2,'e'),(4,'e'),(5,'n'),(0,'d'),(2,'l')]}。
(2)将字符词表C中每个字符编码为独热向量,得到字符向量矩阵
(3)字符级局部特征矩阵
(4)根据第(2)步计算得到的字符级全局特征矩阵
(5)令牌级局部特征矩阵E的每个元素
:tensor(indices=tensor([[2,1,0],[0,0,1]]),
values=tensor([0.7071,0.7071,1.0000]),
size=(3,2),nnz=3,dtype=torch.float64,layout=torch.sparse_coo)
tensor(indices=tensor([[5,1,4,3,2,0],[0,0,1,1,1,1]]),
values=tensor([0.7071, 0.7071, 0.5000, 0.5000, 0.5000, 0.5000]),
size=(6,2),nnz=6,dtype=torch.float64,layout=torch.sparse_coo)
其中,tensor是PyTorch机器学习工具库中定义的张量数据类型,indices表示的是稀疏矩阵中非零元素所在的行和列的索引号,values表示的是稀疏矩阵中非零元素的值,size表示稀疏矩阵的大小,nnz表示非零元素的个数,dtype表示每个元素的存储类型,dtype=torch.float64表示每个元素的存储类型为64位浮点数,layout表示矩阵的表示方式,layout=torch.sparse_coo表示矩阵的表示方式为坐标格式的稀疏矩阵。
(6)根据第(4)步计算得到的令牌级全局特征矩阵
M:tensor(indices=tensor([[0,1],[0,1]]),
values=tensor([0.4094, 0.1578]),
size=(2,2),nnz=2,dtype=torch.float64,layout=torch.sparse_coo)
其中,tensor是PyTorch机器学习工具库中定义的张量数据类型,indices表示的是稀疏矩阵中非零元素所在的行和列的索引号,values表示的是稀疏矩阵中非零元素的值,size表示稀疏矩阵的大小,nnz表示非零元素的个数,dtype=torch.float64表示每个元素的存储类型为64位浮点数,layout=torch.sparse_coo表示矩阵的表示方式为坐标格式的稀疏矩阵。
从M中可见实体名称'Upper_Normandy'与'Haute-Normandie'的相似度为0.4094,实体名称'Dieppe'与'Santa_Ana_de_Velasco'的相似度为0.1578,其余实体名称对的相似度为0,因此M中选取相似度较高的实体对('Upper_Normandy','Haute-Normandie')作为实体对齐的初始对齐种子。
以上所述,仅为本申请较佳的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 图像降噪方法、装置、电子设备及计算机可读存储介质
- 图像处理方法和装置、电子设备、计算机可读存储介质
- 图像处理方法、装置、电子设备及计算机可读存储介质
- 图像处理方法和装置、电子设备、计算机可读存储介质
- 图像处理方法和装置、电子设备、计算机可读存储介质
- 图像优化方法、装置、电子设备及计算机可读存储介质
- 图像优化的方法、装置、电子设备及计算机可读存储介质