考虑流-热耦合效应的土石坝渗流参数联合反演方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于渗流性态分析方法技术领域,涉及考虑流-热耦合效应的土石坝渗流参数联合反演方法。
背景技术
土石坝是世界上建造最广泛的坝型,为了蓄水和发电,这些大坝的上游和下游之间会产生非常大的静水压差,对于大坝的抗渗性能是巨大的挑战。超过1/3的土石坝溃决是由异常渗流引起的,准确评估渗流性态对确保大坝的安全运行尤为重要。在土石坝的渗流分析中,渗流参数通常是通过室内土工试验或工程类比确定的,受地质条件、运行环境和施工质量的影响,可能无法反映大坝填筑材料的真实性能。反演分析能够有效解决这一问题,已经成为土石坝渗流计算中用来确定大坝渗流参数的一种重要方法。
反演分析通常需要定义一个模拟值与实测值之间的目标函数,并通过优化算法寻找目标函数的最小值,即模拟值与实测值的差最小,此时对应的参数即为反演得到的最优参数。最初的反演分析需要多次调用数值模拟程序,这是一个非常耗时的过程,建立代理模型替代复杂的数值模拟程序大大提升了反演分析的速度,减小了计算成本。常用的代理模型包括Kriging模型、响应面法、径向基函数(RBF)、极限学习机等。几十年来,研究者们在这一领域取得了可观的成就,但仍存在一些关键问题亟待解决。首先,传统参数反演大多利用监测点的渗透压力或渗流量作为大坝渗流的响应,然而,渗流过程还将导致多孔介质温度的变化,大坝渗流场与温度场的耦合作用已经被证明,利用多种不同类型的监测信息构建联合反演模型尚未被考虑。此外,在传统的参数反演流程中,通常是对每个监测点的观测数据分别建立代理模型,如此庞大的工作量显著影响了反演分析的效率。机器学习的优势是能够在多个输入与多个输出之间建立映射关系。然而,多个观测点的监测值序列之间具有多重共线性,直接将其作为输出值不仅提升了机器学习代理模型的复杂度,还将导致代理模型的泛化能力下降,从而影响反演结果的准确性。
发明内容
本发明的目的是提供一种考虑流-热耦合效应的土石坝渗流参数联合反演方法,解决了现有技术中存在的反演效率和准确性低的问题。
本发明所采用的技术方案是,考虑流-热耦合效应的土石坝渗流参数联合反演方法,包括:获取待反演渗流参数样本点,计算各样本点对应的水头、温度监测点模拟值;对水头、温度监测点模拟值及水头、温度监测点实测值进行数据降维;分别建立水头、温度为观测信息的目标函数,将水头、温度对应的目标函数线性相加得到单目标函数,对单目标函数进行寻优求解,结合universal kriging代理模型,获得待反演渗流参数。
本发明的特点还在于:
包括以下步骤:
步骤1、获取待反演渗流参数样本点,通过流-热耦合有限元数值模拟计算各样本点对应的水头、温度监测点模拟值;
步骤2、通过熵权法获取各监测点水头、温度模拟值及水头、温度监测点实测值的权重系数,加权求和获取水头、温度监测点的加权模拟值及水头、温度监测点的加权实测值;
步骤3、分别建立水头、温度为观测信息的目标函数,将水头、温度对应的目标函数线性相加得到单目标函数;
步骤4、结合universal kriging代理模型,采用多岛遗传优化算法对单目标函数进行寻优求解,获得待反演渗流参数。
步骤2具体包括以下步骤:
步骤2.1、假设样本点包括n组,每组包括m个监测点的值,则x
步骤2.2、对监测序列进行标准化处理:
步骤2.3、计算监测序列的熵:
步骤2.4、计算权重:
步骤2.5、计算加权值:
universal kriging代理模型的数学表达式为:
式中,x为待反演渗流参数,Y(x)为监测点的模拟水头或温度值,α为回归系数,P为多项式函数的数量,Z(x)为universal kriging代理模型的随机项,其协方差函数为:
Cov[Z(x
式中,σ
式中,其中l是长度标度参数,Γ是伽玛函数,v是控制函数平滑度的正参数,K
步骤4中以水头、温度为观测信息的目标函数分别为:
式中,e为反演选择的时间点数量,n为水头监测点的数量,H
式中,l为反演选择的时间点数量,m为温度监测点的数量,T
步骤4中单目标函数为:
式中,w
本发明的有益效果是:本发明考虑流-热耦合效应的土石坝渗流参数联合反演方法,能够充分联合土石坝不同类别的观测信息,准确高效地获得土石坝渗流参数,有助于提高反演精度,从而为大坝渗流性态分析提供可靠的支撑和依据;利用熵权法对多个监测点的水头和温度观测信息进行预处理,有效降低了数据维度,不仅提高了参数反演效率,而且避免了数据多重共线性导致的代理模型泛化能力差的问题,从而提高参数反演结果的准确性;不仅可以用于土石坝工程,还可以用于边坡、隧道、堤防等工程领域,可推广性较强。
附图说明
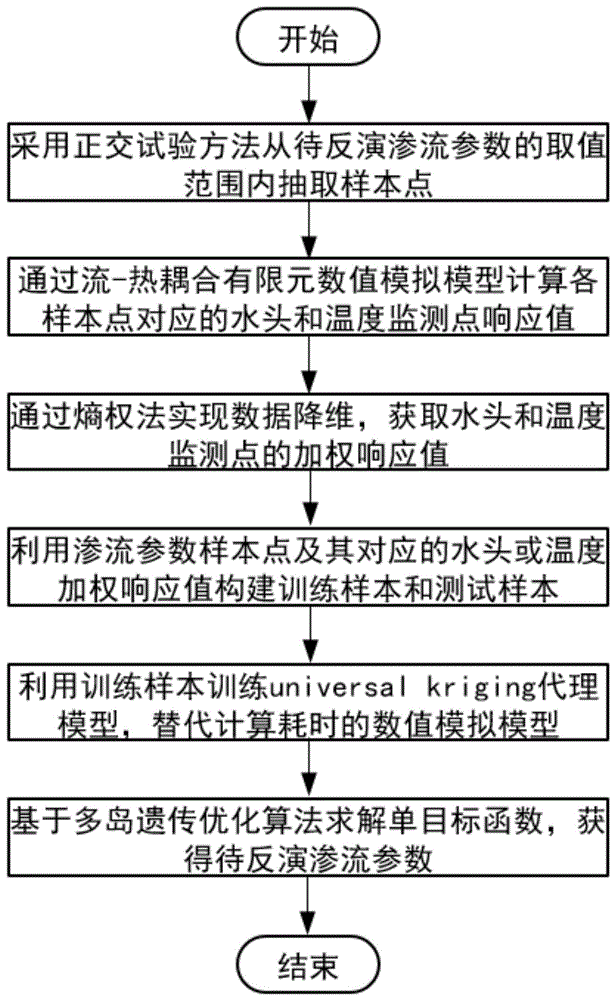
图1是本发明考虑流-热耦合效应的土石坝渗流参数联合反演方法的流程图;
图2是本发明考虑流-热耦合效应的土石坝渗流参数联合反演方法的实施例的大坝结构图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
实施例1
考虑流-热耦合效应的土石坝渗流参数联合反演方法,包括以下步骤:
步骤1、获取待反演渗流参数样本点,通过流-热耦合有限元数值模拟计算各样本点对应的水头、温度监测点模拟值;
步骤2、通过熵权法获取各监测点水头、温度模拟值及水头、温度监测点实测值的权重系数,加权求和获取水头、温度监测点的加权模拟值及水头、温度监测点的加权实测值;
步骤3、分别建立水头、温度为观测信息的目标函数,将水头、温度对应的目标函数线性相加得到单目标函数;
步骤4、结合universal kriging代理模型,采用多岛遗传优化算法对单目标函数进行寻优求解,获得待反演渗流参数。
实施例2
考虑流-热耦合效应的土石坝渗流参数联合反演方法,如图1所示,包括以下步骤:
步骤1、根据工程经验以及室内试验和原位试验数据确定待反演渗流参数的取值范围和服从的分布函数类型,采用正交试验方法从待反演渗流参数的取值范围内获取渗流参数的n组样本点,如图2所示;
步骤2、通过流-热耦合有限元数值模拟模型计算各样本点对应的水头、温度监测点模拟值;
步骤3、通过熵权法获取各监测点模拟值、实测值的权重系数,加权求和获取水头和温度监测点的加权模拟值及水头、温度监测点的加权实测值,实现数据降维;“熵”,是系统无序程度的一个度量,如果一个监测序列的信息熵越小,该监测序列提供的信息量越大,在新的加权序列中所起作用理当越大,权重就应该越高。
步骤3.1、每组样本点包括m个监测点的值,则x
步骤3.2、对监测序列进行标准化处理:
步骤3.3、计算监测序列的熵:
步骤3.4、计算权重:
步骤3.5、计算加权值:
步骤4、将渗流参数样本点及其对应的水头或温度加权模拟值组成样本对,取设定比例的样本对为训练样本,剩下的样本对为测试样本。将训练样本输入universal kriging代理模型进行训练,得到训练后的universal kriging代理模型;
universal kriging代理模型的数学表达式为:
式中,x为待反演渗流参数,Y(x)为监测点的水头或温度模拟值,α为回归系数,P为多项式函数的数量,Z(x)为universal kriging代理模型的随机项,其协方差函数为:
Cov[Z(x
式中,σ
式中,其中l是长度标度参数,Γ是伽玛函数,v是控制函数平滑度的正参数,K
步骤5、分别建立水头、温度为观测信息的目标函数,将水头、温度对应的目标函数线性相加得到单目标函数;
具体的,步骤5.1、以水头、温度为观测信息的目标函数分别为:
式中,e为反演选择的时间点数量,n为水头监测点的数量,H
式中,l为反演选择的时间点数量,m为温度监测点的数量,T
步骤5.2、联合反演需要同时满足式8和式9两个目标函数,这是一个典型的多目标优化问题,为了简化优化算法,并避免多目标寻优可能产生的大量非支配解,采用线性加权方法将多目标优化问题转化为单目标优化问题,即将水头、温度对应的目标函数线性相加得到单目标函数:
式中,w
步骤6、结合universal kriging代理模型,采用多岛遗传优化算法对单目标函数进行寻优求解,获得待反演渗流参数。
通过以上方式,本发明考虑流-热耦合效应的土石坝渗流参数联合反演方法,能够充分联合土石坝不同类别的观测信息,准确高效地获得土石坝渗流参数,有助于提高反演精度,从而为大坝渗流性态分析提供可靠的支撑和依据;利用熵权法对多个监测点的水头和温度观测信息进行预处理,有效降低了数据维度,不仅提高了参数反演效率,而且避免了数据多重共线性导致的代理模型泛化能力差的问题,从而提高参数反演结果的准确性;不仅可以用于土石坝工程,还可以用于边坡、隧道、堤防等工程领域,可推广性较强。
实施例3
以坝体渗透系数反演来证明本发明提出方法的有效性和优越性,为简化计算,不考虑坝基。坝体包括堆石区、过渡层和粘土心墙三部分,每部分设为各向同性的均匀多孔介质,共有9个监测点。流-热耦合数值模拟的参数如表1所示:
表1流-热耦合数值模拟模型参数表
表中,n是孔隙率,θ
在取值范围内,对每个区域的渗透系数选取9个水平,通过正交设计生成81组样本点。将这81组渗透系数样本点输入到大坝流-热耦合数值模型中进行模拟计算。假设上游水位不发生变化,选取12个时间控制点,得出各组渗透系数样本点对应的各监测点水头和温度模拟值。通过熵权法获取各监测点响应值的权重系数,加权求和获取水头和温度监测点的加权模拟值,将渗透系数样本点与监测点的加权模拟值组成81组样本对。取81组样本对中的60组样本对作为训练样本,训练universal kriging代理模型,将剩余的21组样本对作为测试样本。用训练好的代理模型替代计算耗时的流-热耦合数值模拟模型。通过多岛遗传优化算法对目标函数进行优化求解,得到坝体各区域的渗透系数反演值。
为了进一步验证本文提出的联合土石坝不同类别的观测信息进行渗流参数反演方法的优越性,计算了w
表2渗流参数反演结果
从表2可知,相比于单一类别的观测信息,利用温度和水头两类观测信息对大坝渗流参数进行联合反演在一定程度上有助于提高反演精度,其中,w
为了进一步验证本发明提出的数据降维程序对参数反演效率和代理模型泛化能力的提升效果,对比了利用监测点的加权响应值和原始数据构建代理模型的相关系数,前者代理模型数量为24,相关系数平均值为0.961,后者代理模型数量为216,相关系数平均值为0.943。采用本发明提出的数据降维程序所构建的代理模型数量更少,相关系数更高。故可说明本发明提出的数据降维程序对参数反演效率和代理模型泛化能力有良好的提升效果。