基于CI/CD的代码编译产物处理方法及装置
文献发布时间:2024-04-18 20:01:23
技术领域
本申请涉及互联网技术领域,具体涉及一种基于CI/CD的代码编译产物处理方法及装置。
背景技术
编译产物即链接器将经过编译器编译后的代码链接而成的文件,编译产物文件的大小影响最终可执行程序的大小。如图1a所示,在Android应用中动态库(如.so文件)常常占据大量的安装包体积,其不仅影响应用的分发效率,还占据用户终端大量的磁盘空间。
为了进一步降低安装包的体积,现有技术通常采用动态链接的特性,将一部分功能代码以动态库的形式在运行时下发给用户,但这样处理对程序的稳定性、兼容性、代码安全性等要求较高。因此,需要一种基于CI/CD的代码编译产物处理方法,以便能简便地降低执行程序的包体积,提升应用分发效率。
发明内容
鉴于上述问题,提出了本申请实施例以便提供一种克服上述问题或者至少部分地解决上述问题的基于CI/CD的代码编译产物处理方法及装置。
根据本申请实施例的第一方面,提供了一种基于CI/CD的代码编译产物处理方法,方法基于CI/CD打包流水线执行各步骤,方法包括:
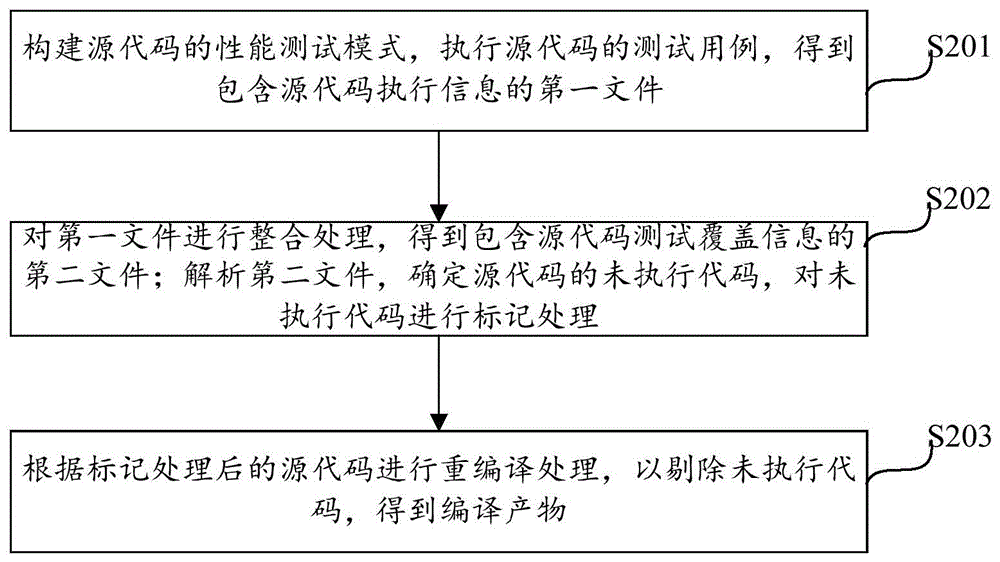
测试执行步骤,构建源代码的性能测试模式,执行源代码的测试用例,得到包含源代码执行信息的第一文件;
未执行代码标记步骤,对第一文件进行整合处理,得到包含源代码测试覆盖信息的第二文件;解析第二文件,确定源代码的未执行代码,对未执行代码进行标记处理;
重编译步骤,根据标记处理后的源代码进行重编译处理,以剔除未执行代码,得到编译产物。
可选地,测试执行步骤进一步包括:
根据源代码构建对应的全量测试用例,以及,构建性能测试模式的配置信息;全量测试用例包括多个正常执行和/或异常执行的单元测试用例;
基于性能测试模型依次执行源代码的全量测试用例的各单元测试用例,得到多个包含源代码执行信息的第一文件;第一文件包括预设后缀名的文件。
可选地,未执行代码标记步骤进一步包括:
调用预设覆盖率测试工具对第一文件进行整合处理,得到包含源代码测试覆盖信息的第二文件;第二文件包括代码覆盖率报告文件;第二文件包括源代码的函数名称、函数行号、函数执行次数、各行代码的行号和/或各行代码的执行次数。
可选地,未执行代码标记步骤进一步包括:
解析第二文件中的源代码的函数名称、函数行号、函数执行次数、各行代码的行号和/或各行代码的执行次数,确定执行次数为0的代码为未执行代码,记录未执行代码的行号,得到未执行行号集合;
将源代码拷贝至预设编译目录,并根据未执行行号集合对未执行代码进行标记处理。
可选地,将源代码拷贝至预设编译目录,并根据未执行行号集合对未执行代码进行标记处理进一步包括:
将源代码拷贝至预设编译目录;
遍历未执行行号集合,根据未执行代码的行号,为未执行代码添加预设注释语句,以对未执行代码进行标记处理。
可选地,方法还包括:
预设代码白名单配置文件;
将源代码拷贝至预设编译目录,并根据未执行行号集合对未执行代码进行标记处理进一步包括:
将源代码拷贝至预设编译目录;
针对未执行行号集合中任一未执行代码的行号,判断行号对应的代码是否在代码白名单配置文件;
若否,为未执行代码添加预设注释语句。
可选地,方法还包括:
将测试执行步骤、未执行代码标记步骤、重编译步骤依次添加至CI/CD打包流水线,以便基于CI/CD打包流水线自动执行得到编译产物。
可选地,源代码包括C语言或者C++语言的代码;源代码包括动态库的代码。
根据本申请实施例的第二方面,提供了一种基于CI/CD的代码编译产物处理装置,其中,装置基于CI/CD打包流水线执行各模块,装置包括:
测试执行模块,适于构建源代码的性能测试模式,执行源代码的测试用例,得到包含源代码执行信息的第一文件;
未执行代码标记模块,适于对第一文件进行整合处理,得到包含源代码测试覆盖信息的第二文件;解析第二文件,确定源代码的未执行代码,对未执行代码进行标记处理;
重编译模块,适于根据标记处理后的源代码进行重编译处理,以剔除未执行代码,得到编译产物。
根据本申请实施例的第三方面,提供了一种计算设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述基于CI/CD的代码编译产物处理方法对应的操作。
根据本申请实施例的第四方面,提供了一种计算机存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述基于CI/CD的代码编译产物处理方法对应的操作。
根据本申请的提供的基于CI/CD的代码编译产物处理方法及装置,通过构建源代码的性能测试模式,执行测试用例,从而得到源代码测试覆盖信息,解析确定未执行代码,对其进行标记处理,以便在重编译处理时,将标记处理的未执行代码剔除,不对其打包,从而减小生成的编译产物的大小。且通过CI/CD打包流水线自动触发,更方便快捷。
上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其它目的、特征和优点能够更明显易懂,以下特举本申请的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本申请的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1a示出了Android应用中动态库在安装包中的体积分布示意图;
图1b示出了编译器编译流程示意图;
图1c示出了动态库代码被调用示意图;
图2示出了根据本申请一个实施例的基于CI/CD的代码编译产物处理方法的流程图;
图3示出了CI/CD打包流水线各任务阶段示意图;
图4示出了根据本申请另一个实施例的基于CI/CD的代码编译产物处理方法的流程图;
图5示出了根据本申请一个实施例的基于CI/CD的代码编译产物处理装置的结构示意图;
图6示出了根据本申请一个实施例的一种计算设备的结构示意图。
具体实施方式
下面将参照附图更详细地描述本申请的示例性实施例。虽然附图中显示了本申请的示例性实施例,然而应当理解,可以以各种形式实现本申请而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本申请,并且能够将本申请的范围完整的传达给本领域的技术人员。
首先,对本申请一个或多个实施例涉及的名词术语进行解释。
编译器:一种计算机程序,将某种编程语言写成的源代码(原始语言)转换成另一种编程语言(源代码)。
源代码:计算机可以识别(可以直接执行)的代码,也被称为二进制文件。
编译产物:链接器将经过编译器编译后的源代码链接而成的文件即为产物,产物通常按链接方式分为静态库、动态库。
静态链接:链接器的链接静态库的方式。编译期间直接将所需的所有内容(包括静态库)链接到目标动态库或最终可执行程序中。
动态链接:链接器的链接动态库的方式。编译期间将动态库的符号地址用占位(stub)的形式链接到目标动态库或最终可执行程序中。在程序运行时动态地将内存中所需占位符号替换为动态库中实际的符号地址。
profiling:以收集程序运行时信息为手段研究程序行为的分析方法,是一种动态程序分析的方法。
代码覆盖率:用例描述程序中源代码被测试代码所执行的比例和程度。
LCOV:开源的代码覆盖率报告生成工具,生成的报告通常使用LCOV格式。LCOV格式是一种文本格式,用于描述代码覆盖率信息,包括源代码文件的行覆盖情况和总体覆盖率统计。
CI/CD:持续集成(Continuous Integration)持续交付(Continuous Delivery)的英文缩写,指代一种软件开发过程中的自动化流程工具。流行的CI/CD工具有Jenkins、GitLab CI、Travis CI等。
图2示出了根据本申请一实施例的基于CI/CD的代码编译产物处理方法的流程图,如图2所示,该方法包括如下步骤:
步骤S201,构建源代码的性能测试模式,执行源代码的测试用例,得到包含源代码执行信息的第一文件。
代码编译产物是基于源代码进行编译后得到的,以C语言、C++语言为例,编译器对源代码的编译流程如图1b所示,将.c、.cc、.cpp、.h等源文件经编译器得到目标代码.o、.obj文件,经由归档库archiver将静态库.a文件与链接器,得到动态库的.so、.dll等文件。
现有技术在优化编译产物体积时,通过如使用编译器编译选项:-fdata-sections和-ffunction-sections、开启编译器优化指令长度:-Os、禁用不用的语言特性:如-fno-exceptions、-fno-rtti等,对于动态库(如.so、.dll等文件)还可以使用如精简对外导出的符号:-fvisibility=hidden、使用链接器参数:-Wl、--gc-sections等。以上优化方式大多通过如调整编译器的编译参数和链接器链接参数来进行优化,但对于动态库而言,即便使用了以上如编译参数优化,但被用户程序执行到的代码仍然是一部分。如图1c所示,可执行程序调用了动态库中的函数foo(),函数bar()没有被执行,但依然被打包,编译参数优化的方式无法避免无用代码被打包。
基于上述问题,本实施例针对源代码,此处源代码可以为动态库的代码,在编译得到如.so、.dll文件之前,为其构建性能测试模式,执行对应的测试用例,得到包含源代码执行信息的第一文件,以便根据源代码执行信息确定其中未执行代码。
性能测试模式可以通过配置文件设置性能测试模式,如在CMakeLists.txt文件中增加如下信息:
if(ENABLE_COVERAGE)
set(CMAKE_C_FLAGS"${CMAKE_C_FLAGS}-O0--coverage")
set(CMAKE_CXX_FLAGS"${CMAKE_CXX_FLAGS}-O0--coverage")
endif()
根据配置的信息可以增加性能测试模式,基于性能测试模式可以调用执行源代码的测试用例,生成包含源代码执行信息的第一文件。第一文件可以包括如.gcda等文件。测试用例可以包含多个,如正常执行的测试用例、异常执行的测试用例等,每个测试用例执行后,都生成对应的第一文件。
步骤S202,对第一文件进行整合处理,得到包含源代码测试覆盖信息的第二文件;解析第二文件,确定源代码的未执行代码,对未执行代码进行标记处理。
第一文件中包含了源代码执行信息,如xx代码被执行n次等。第一文件可以包含多个,对第一文件进行整合处理,将源代码执行信息与源代码对应,得到包含源代码测试覆盖信息的第二文件。第二文件包括代码覆盖率报告文件,如.info文件,其中可以包括源代码中函数、代码的行号、执行的次数等,可以更方便地了解到基于测试用例会执行某些源代码,从而根据第二文件也可以解析确定出源代码中未执行代码,即执行测试用例后,源代码中存在的不会被调用执行的代码。未执行代码为无用代码,无需将其编译打包,可以将未执行代码进行标记处理,标记处理时,可以将未执行代码通过如注释方式使其不被编译。
步骤S203,根据标记处理后的源代码进行重编译处理,以剔除未执行代码,得到编译产物。
将标记处理后的源代码采用如release模式进行重编译处理,即二次编译,对于标记处理的未执行代码,在重编译处理时,会将其剔除,不将其编译打包至编译产物,从而大大减少编译产物的体积。
对于以上各步骤,可以基于CI/CD打包流水线执行,如利用GitLab的pipelineRunner自定义CI/CD打包流水线,将每个步骤作为CI/CD打包流水线中对应的一个或多个任务,按照各个步骤的顺序定义CI/CD打包流水线中任务顺序。通过自动触发CI/CD打包流水线,依次自动执行各个步骤,得到最终剔除未执行代码的编译产物。如图3所示,CI/CD打包流水线可以自定义不同任务,如编译性能测试、执行性能测试对应步骤S101-步骤S102,为源代码构建性能测试模式,执行性能测试即执行源代码的测试用例,得到第一文件,对第一文件进行整合处理,生成第二文件即代码覆盖率报告文件。预处理源码对应步骤S103,解析代码覆盖率报告文件,确定源代码的未执行代码,对未执行代码进行标记处理,即标记其中无用代码,重编译对应步骤S104,根据标记处理后的源代码进行重编译处理,得到编译产物。以上为举例说明,具体CI/CD打包流水线的任务划分可以根据实施情况设置,此处不做限定。
根据本申请提供的基于CI/CD的代码编译产物处理方法,通过构建源代码的性能测试模式,执行测试用例,从而得到源代码测试覆盖信息,解析确定未执行代码,对其进行标记处理,以便在重编译处理时,将标记处理的未执行代码剔除,不对其打包,从而减小生成的编译产物的大小。且通过CI/CD打包流水线自动触发,更方便快捷。
图4示出了根据本申请一实施例的基于CI/CD的代码编译产物处理方法的流程图,如图4所示,该方法包括以下步骤:
步骤S401,根据源代码构建对应的全量测试用例,以及,构建性能测试模式的配置信息,基于性能测试模型依次执行源代码的全量测试用例的各单元测试用例,得到多个包含源代码执行信息的第一文件。
针对源代码,需要为其预先构建对应的全量测试用例。全量测试用例包括多个正常执行、异常执行的单元测试用例,全量测试用例用于更全面的覆盖源代码。全量测试用例需要根据源代码自身的执行逻辑构建,具体根据实施情况设置,此处不做限定。
性能测试模式可以针对源代码增设对应的模式选项,如在CMakeLists.txt中配置性能测试模式选项:
if(ENABLE_COVERAGE)
set(CMAKE_C_FLAGS"${CMAKE_C_FLAGS}-O0--coverage")
set(CMAKE_CXX_FLAGS"${CMAKE_CXX_FLAGS}-O0--coverage")
endif()
根据“--coverage”选项,执行性能测试模式,依次执行源代码的全量测试用例的各单元测试用例,执行结束后得到多个包含源代码执行信息的第一文件。如下所示:
src
├──neon.cc.gcda
├──neon.cc.gcno
├──neon.cc.o
├──neon_debugging.cc.gcno
├──neon_debugging.cc.o
├──neon_file.cc.gcda
├──neon_file.cc.gcno
├──neon_file.cc.o
├──neon_logging.cc.gcda
├──neon_logging.cc.gcno
└──…
其中,第一文件包括预设后缀名的文件,预设后缀名如.gcda,第一文件如neon.cc.gcda、neon_file.cc.gcda、neon_logging.cc.gcda等,也可以根据实施情况设置预设后缀名,此处不做限定。
性能测试模型可以在集成环境中直接运行(如本地执行),也可以连接其它终端运行(如远程执行),具体根据CI/CD确定,此处不做限定。
步骤S402,调用预设覆盖率测试工具对第一文件进行整合处理,得到包含源代码测试覆盖信息的第二文件。
针对各第一文件,可以调用预设覆盖率测试工具如LCOV,对第一文件进行整合处理。如执行以下命令:
lcov--include"$BASE_DIR/*"--directory$BASE_DIR-b$BASE_DIR--capture-i-o$COVERAGE_OUT_DIR/base
./run_profile_app
lcov--include"$BASE_DIR/*"--directory$BASE_DIR-b$BASE_DIR--capture-o$COVERAGE_OUT_DIR/capture
lcov-a$COVERAGE_OUT_DIR/base-a$COVERAGE_OUT_DIR/capture-o$COVERAGE_OUT_DIR/coverage.info
得到包含源代码测试覆盖信息的第二文件,第二文件包括代码覆盖率报告文件,如coverage.info文件。CI/CD可以集成代码覆盖率工具如LCOV,方便自动触发打包流水线。第二文件主要包括源代码的函数名称、函数行号、函数执行次数、各行代码的行号、各行代码的执行次数等,还包括如文件中函数的总数、文件中已执行的函数的数量、每一行的执行次数和行号、文件中的行数、文件中已执行的行数等。
步骤S403,解析第二文件中的源代码的函数名称、函数行号、函数执行次数、各行代码的行号和/或各行代码的执行次数,确定执行次数为0的代码为未执行代码,记录未执行代码的行号,得到未执行行号集合。
对第二文件进行解析,结果如下所示:
TN:
SF:/Users/xxx/Documents/repos/neon/neon/src/neon_logging.cc
FN:12,4,_ZN4neon9log_debugEPKcz
FN:23,1,_ZN4neon8log_infoEPKcz
FNDA:4,_ZN4neon9log_debugEPKcz
FNDA:1,_ZN4neon8log_infoEPKcz
FNF:2
FNH:2
DA:12,1
DA:14,1
DA:18,2
DA:20,0
DA:21,0
DA:23,0
DA:24,0
LF:25
LH:10
end_of_record
其中,TN:测试用例;SF:源代码文件的路径;FN:函数开始的行号、执行次数和函数名称,格式为FN:
根据解析结果中的源代码的函数名称、函数行号、函数执行次数、各行代码的行号、各行代码的执行次数,可以确定执行次数为0的代码,即一次也没有执行过的代码即为未执行代码,筛选得到未执行代码的行号,记录未执行代码的行号,得到未执行行号集合。如xx.cc文件中,未执行代码的行号为10、32、40等。
步骤S404,将源代码拷贝至预设编译目录,并根据未执行行号集合对未执行代码进行标记处理。
将源代码拷贝至预设编译目录中,遍历未执行行号集合,根据每一个未执行代码的行号,为对应的未执行代码添加预设注释语句,如#if0…#endif,实现快速注释,也解决嵌套注释的问题,基于预设注释语句完成对未执行代码进行标记处理。
进一步,为避免测试用例不足导致误删代码,本实施例预设代码白名单配置文件,其中可以动态记录“有用代码”,保障代码白名单配置文件中的代码不会在编译时被剔除。当基于未执行行号集合进行标注处理时,针对未执行行号集合中任一未执行代码的行号,先判断行号对应的代码是否在代码白名单配置文件,若否,才为未执行代码添加预设注释语句,若是,则不对未执行代码进行处理。
步骤S405,根据标记处理后的源代码进行重编译处理,以剔除未执行代码,得到编译产物。
根据标记处理后的源代码,如动态库的源代码,可以对其按照release模式,在预设编译目录中进行重编译处理,剔除未执行代码,得到的编译产物的动态库会大大降低体积。
以上各步骤作为CI/CD打包流水线中的任务,可以在触发CI/CD打包流水线时,自动执行,等前一任务执行完成后,将执行结果传递给下一任务,如构建性能测试模式,执行各个测试用例,得到第一文件后,可以将第一文件传递给下一任务,进行整合得到第二文件,解析确定未执行行号集合,对未执行代码进行标记处理后,可以将标记处理后的源代码的编译目录告知下一任务,对编译目录进行重编译,得到编译产物。编译产物中的动态库的体积大大减少,整个编译产物的体积也会大大减少。
根据本申请提供的基于CI/CD的代码编译产物处理方法,通过构建源代码的性能测试模式,执行全量测试用例,确定源代码的执行信息,整合得到源代码测试覆盖信息。通过解析代码测试覆盖信息的结果,可以确定执行次数为0的未执行代码,记录未执行代码的行号,得到未执行行号集合。遍历未执行行号集合,为未执行代码添加预设注释语句进行标记处理,若行号对应的代码在代码白名单配置文件中,则无需标记处理,避免误删除。重新编译时根据标记处理后的源代码进行重编译,可以将标记处理的未执行代码剔除,不对其打包,从而减小生成的编译产物的大小,在动态库足够小的情况下,可以避免使用动态下发方案,从而避免一系列的稳定性、兼容性等问题,也提升了最终编译得到的应用的分发效率。进一步,以上处理通过CI/CD打包流水线自动触发,更方便快捷。
图5示出了本申请一实施例提供的基于CI/CD的代码编译产物处理装置的结构示意图。如图5所示,装置基于CI/CD打包流水线执行各模块,该装置包括:
测试执行模块510,适于构建源代码的性能测试模式,执行源代码的测试用例,得到包含源代码执行信息的第一文件;
未执行代码标记模块520,适于对第一文件进行整合处理,得到包含源代码测试覆盖信息的第二文件;解析第二文件,确定源代码的未执行代码,对未执行代码进行标记处理;
重编译模块520,适于根据标记处理后的源代码进行重编译处理,以剔除未执行代码,得到编译产物。
可选地,测试执行模块510进一步适于:
根据源代码构建对应的全量测试用例,以及,构建性能测试模式的配置信息;全量测试用例包括多个正常执行和/或异常执行的单元测试用例;
基于性能测试模型依次执行源代码的全量测试用例的各单元测试用例,得到多个包含源代码执行信息的第一文件;第一文件包括预设后缀名的文件。
可选地,未执行代码标记模块520进一步适于:
调用预设覆盖率测试工具对第一文件进行整合处理,得到包含源代码测试覆盖信息的第二文件;第二文件包括代码覆盖率报告文件;第二文件包括源代码的函数名称、函数行号、函数执行次数、各行代码的行号和/或各行代码的执行次数。
可选地,未执行代码标记模块520进一步适于:
解析第二文件中的源代码的函数名称、函数行号、函数执行次数、各行代码的行号和/或各行代码的执行次数,确定执行次数为0的代码为未执行代码,记录未执行代码的行号,得到未执行行号集合;
将源代码拷贝至预设编译目录,并根据未执行行号集合对未执行代码进行标记处理。
可选地,未执行代码标记模块520进一步适于:
将源代码拷贝至预设编译目录;
遍历未执行行号集合,根据未执行代码的行号,为未执行代码添加预设注释语句,以对未执行代码进行标记处理。
可选地,装置还包括:白名单模块540,适于预设代码白名单配置文件;
未执行代码标记模块520进一步适于:
将源代码拷贝至预设编译目录;
针对未执行行号集合中任一未执行代码的行号,判断行号对应的代码是否在代码白名单配置文件;
若否,为未执行代码添加预设注释语句。
可选地,装置还包括:流水线设置模块550,适于将测试执行模块510、未执行代码标记模块520、重编译模块530依次添加至CI/CD打包流水线,以便基于CI/CD打包流水线自动执行得到编译产物。
可选地,源代码包括C语言或者C++语言的代码;源代码包括动态库的代码。
以上各模块的描述参照方法实施例中对应的描述,在此不再赘述。
根据本申请提供的基于CI/CD的代码编译产物处理装置,通过构建源代码的性能测试模式,执行测试用例,从而得到源代码测试覆盖信息,解析确定未执行代码,对其进行标记处理,以便在重编译处理时,将标记处理的未执行代码剔除,不对其打包,从而减小生成的编译产物的大小。且通过CI/CD打包流水线自动触发,更方便快捷。
本申请还提供了一种非易失性计算机存储介质,计算机存储介质存储有至少一可执行指令,可执行指令可执行上述任意方法实施例中的基于CI/CD的代码编译产物处理方法。
图6示出了根据本申请一实施例的一种计算设备的结构示意图,本申请的具体实施例并不对计算设备的具体实现做限定。
如图6所示,该计算设备可以包括:处理器(processor)602、通信接口(Communications Interface)604、存储器(memory)606、以及通信总线608。
其中:
处理器602、通信接口604、以及存储器606通过通信总线608完成相互间的通信。
通信接口604,用于与其它设备比如客户端或其它服务器等的网元通信。
处理器602,用于执行程序610,具体可以执行上述基于CI/CD的代码编译产物处理方法实施例中的相关步骤。
具体地,程序610可以包括程序代码,该程序代码包括计算机操作指令。
处理器602可能是中央处理器CPU,或者是特定集成电路ASIC(ApplicationSpecific Integrated Circuit),或者是被配置成实施本申请的一个或多个集成电路。计算设备包括的一个或多个处理器,可以是同一类型的处理器,如一个或多个CPU;也可以是不同类型的处理器,如一个或多个CPU以及一个或多个ASIC。
存储器606,用于存放程序610。存储器606可能包含高速RAM存储器,也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
程序610具体可以用于使得处理器602执行上述任意方法实施例中的基于CI/CD的代码编译产物处理方法。程序610中各步骤的具体实现可以参见上述基于CI/CD的代码编译产物处理实施例中的相应步骤和单元中对应的描述,在此不赘述。所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的设备和模块的具体工作过程,可以参考前述方法实施例中的对应过程描述,在此不再赘述。
在此提供的算法或显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本申请也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本申请的内容,并且上面对特定语言所做的描述是为了披露本申请的较佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本申请的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本申请并帮助理解各个发明方面中的一个或多个,在上面对本申请的示例性实施例的描述中,本申请的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本申请要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本申请的单独实施例。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
此外,本领域的技术人员能够理解,尽管在此的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本申请的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
本申请的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(DSP)来实现根据本申请的一些或者全部部件的一些或者全部功能。本申请还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本申请的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
应该注意的是上述实施例对本申请进行说明而不是对本申请进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本申请可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。上述实施例中的步骤,除有特殊说明外,不应理解为对执行顺序的限定。
- 一种利用氯苯生产的副产氯化氢连续化生产氯乙烷的工艺
- 一种氯化苄连续氯化生产工艺与装置
- 一种连续化生产氯化苄的系统和工艺