基于SF-YOLOv5的电站屋面工程缺陷检测方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及缺陷检测技术领域,更具体的说是涉及一种基于SF-YOLOv5的电站屋面工程缺陷检测方法。
背景技术
目前,电站建筑物屋面工程是建筑物工程的一项关键工序,通常包括找坡层、隔汽层、保温层、找平层、防水层、隔离层、保护层7道工序,具有作业面广、工序多、隐蔽性强、管控难的特点。电站建筑物屋面工程如果发生质量问题造成漏水等事故,将严重危害屋内电气设备的安全稳定运行,威胁电网安全。传统的人工视觉检测存在准确性和效率方面的挑战。人力处理容易导致低效和人员疲劳等问题,无法保证检测结果的准确性和过程的高效性。
深度学习的进展极大地推动了缺陷检测方法的发展。通过让网络自主学习特征模式,通过与样本数据的交互进行训练,并通过反向传播来更新网络参数,实现自动特征提取。这种方法省略了手工设计特征提取算法的步骤,显著提高了准确性和效率。目前,基于深度学习的缺陷检测方法已广泛应用于工业领域的生产检测中。其中,以YOLO系列为代表的单阶段检测网络在目标检测领域具有重要地位。这些网络模型直接将图像输入模型,神经网络只需对图像进行一次学习即可输出相应的检测结果,既保证了速度,又具有一定的准确率。
电站建筑物屋面工程在施行过程中会出现找平层起砂、隔离层破损、防水层卷材皱起等不同类型的缺陷,有着缺陷尺寸大小差别过大的特点,而传统的检测网络对于小目标的检测精确度和准确度尚不够,而且随着卷积层的加深,小目标的特征会不断减小,导致小目标缺陷的漏检,无法应用于工业界。
因此,如何提高检测网络对小目标的检测精度和准确度,实现准确的电站屋面工程缺陷检测是本领域技术人员亟需解决的问题。
发明内容
有鉴于此,本发明提供了一种基于SF-YOLOv5的电站屋面工程缺陷检测方法,通过将传统YOLOv5与Swin-Transformer、Fusion-Concat结合,可以降低目标处在图像边缘时的漏检率,提高不同尺度缺陷的识别准确度。
为了实现上述目的,本发明采用如下技术方案:
基于SF-YOLOv5的电站屋面工程缺陷检测方法,步骤如下:
步骤1:获取进行缺陷标注的各种缺陷类型电站屋面工程缺陷图片,并对图片进行两次预处理,构建数据集;
步骤2:在YOLOv5框架中融合Swin-Transformer和Fusion-Concat构建SF-YOLOv5网络;
步骤3:将数据集输入所述SF-YOLOv5网络中,对所述SF-YOLOv5网络进行训练,获得缺陷检测模型;
步骤4:获取预测图像,输入至所述缺陷检测模型中,获得模型输出结果,采用CP-Cluster对模型输出结果进行后处理优化,获得预测结果。
优选的,所述步骤1中的预处理包括数据增强和数据裁剪,首先对获取的图片进行数据增强,对数据增强后的所有图片进行边界扩充后裁剪至设定大小,然后对裁剪后的图片再次进行边界扩充,再进行通道转置、添加批量大小、转换成张量类型;具体的:
对图片进行数据增强包括:
将不同规模的不同缺陷类型的电站屋面工程缺陷图片粘贴到新的背景图片,获得不同环境下的不同缺陷图片;
将原始的电站屋面工程缺陷图片进行高斯模糊处理;
从原始的电站屋面工程缺陷图片中随机选取四张通过mosaic拼接得到新的图片;
将原始的电站屋面工程缺陷图片进行旋转角度和平移调整;
将原始的电站屋面工程缺陷图片进行灰度、亮度调整;
对数据增强后的图片进行数据裁剪包括以下步骤:
步骤11:将图片像素小于设定阈值的图片的每条边采用灰度值0扩充固定像素点;
步骤12:将扩充后的图片裁剪至设定阈值大小;
步骤13:将裁剪后的图片的每条边采用灰度值0扩充固定像素点;
步骤14:对扩充后的图像进行通道转置操作,然后将转置后的图像扩充为设定的批量大小,并转换为张量类型。
优选的,所述SF-YOLOv5网络包括骨干网络、颈网络和检测头;
所述骨干网络包括第一特征提取层、第二特征提取层、第三特征提取层和第四特征提取层;
所述颈网络包括第一融合层、第二融合层和第三融合层;
所述检测头采用YOLO检测器,将特征图转换为模型输出结果,包括预测框的位置、类别和置信度。
优选的,所述第一特征提取层包括2个CBS和3个C3SwinTR;所述第二特征提取层包括1个CBS和6个C3SwinTR;所述第三特征提取层包括1个CBS和9个C3SwinTR;所述第四特征提取层包括2个CBS和1个融合了多头自注意力机制的C3_MHSA。
上述技术方案的技术效果为,所有特征提取层由CBS和不同数量的C3SwinTR实现特征提取;CBS是一个组合操作,由卷积层Conv,归一化层BN,激活函数SiLU组成,卷积层用于提取特征,归一化用于加速训练过程,激活函数单元用于引入非线性;C3SwinTR是由CBS和不同数量的Swin transformer blocks模块组成,C3SwinTR代替了传统YOLOv5的C3卷积模块,将CNN与transformer结合来捕获图像的全局信息。传统的C3模块需要使用多次局部卷积操作来获取图像的信息,而C3SwinTR在通道维度划分,只需要对一半的特征进行卷积操作,减少了计算量。
优选的,所述第一特征提取层提取数据集中图像的第一特征,获得特征图F0;
所述第二特征提取层根据特征图F0提取特征图F1;
所述第三特征提取层根据特征图F1提取特征图F2;
所述第四特征提取层根据特征图F2提取特征图F3。
优选的,所述第一融合层包括第一上采样、Concat拼接、2个C3_3、CBS、第二上采样、Fusion-Concat拼接和卷积;所述第二融合层包括CBS、Fusion-Concat拼接、C3_3和卷积;所述第三融合层包括CBS、Fusion-Concat拼接、C3_3和卷积。
优选的,所述第一融合层的所述第一上采样对特征图F3进行上采样;在Concat拼接将经过上采样的特征图F3与特征图F2进行融合,获得融合图1;融合图1依次经过2个C3_3和CBS获得中间特征图M1;中间特征图M1在所述第二上采样进行采样;在Fusion-Concat拼接将经过上采样的中间特征图M1与特征图F1进行同和,获得融合图2;融合图2经过C3_3获得中间特征图M2;中间特征图M2经过卷积获得检测头输出Ⅰ;
所述第二融合层的CBS对中间特征图M2进行处理;在Fusion-Concat拼接将经过处理的中间特征图M2与中间特征图M1进行融合,获得融合图3;融合图3经过C3_3获得中间特征图M3;中间特征图M3经过卷积获得检测头输出Ⅱ;
所述第三融合层的的CBS对中间特征图M3进行处理;在Fusion-Concat拼接将经过处理的中间特征图M3与特征图F3进行融合,获得融合图4;融合图4经过C3_3获得中间特征图M4;中间特征图M4经过卷积获得检测头输出Ⅲ。
优选的,所述第四特征提取层中的C3_MHSA包括三个CBS模块、MHSA多头自注意力层和Concat拼接,对数据进行处理时,特征图F2中一半的特征向量经过CBS模块,在Concat拼接与另一半依次经过CBS模块和MHSA多头自注意力层的特征向量进行拼接,拼接后的特征向量经过CBS模块获得特征图F3。不再将图像划分窗口,而是直接计算整个图像的信息,对输入的特征图进行全局的自注意力计算,从而捕捉特征图中不同位置之间的依赖关系。
优选的,MHSA多头自注意力层的多头自注意力机制源于Transformer架构,处理过程如下:
步骤41:第三特征提取层输出的特征图F2经过CBS模块得到多头自注意力的输入矩阵A1,将输入矩阵A1中的每个点的高度和宽度进行编码,获得相对位置编码;
步骤42:编码后的输入矩阵A1分别与查询权重矩阵、键权重矩阵、值权重矩阵相乘,得到查询编码Q、键编码K、值编码V;三组权重矩阵的初始化使用深度学习框架PyTorch提供的默认初始化方法,在训练过程中,三个权重矩阵的值会在迭代的过程中更新调整;
步骤43:将查询编码Q和键编码K之间的点积、查询编码Q和相对位置编码R之间的点积进行相加,得到自注意力分数,自注意力分数经过Softmax函数得到注意力权重,注意力权重点乘值编码V得到单层自注意力输出S
步骤44:将每个点的单层自注意力输出S
SA(R,Q,K,V)=Softmax(QRT-QK
S
O
其中,Softmax为归一化指数函数;SA表示自注意力机制;R
优选的,C3SwinTR由多个Swin-transformer blocks组成,Swin-transformerblocks由W-MSA、SW-MSA、MLP和LN组成。
优选的,Fusion-Concat拼接,替换了YOLOv5中PANet传统的维度拼接,在特征图逐元素相加的过程中引入初始权重,增加了特征图包含的信息量,但并不会增加维度,相当于在特征融合的阶段引入了注意力机制。
优选的,融合CP-Cluster式使用基于置信度传播聚类CP-Cluster方法对目标检测结果进行后处理,替代传统的基于NMS的聚类方法,通过消息传递机制来迭代地惩罚冗余边界框,增强正样本的置信度,从而提高检测精度。
经由上述的技术方案可知,与现有技术相比,产生的有益效果包括:
(1)本发明对图像进行统一大小的处理,且处理后的图像进行边界扩充,不会导致处于图像边缘的目标被分割,降低边缘目标漏检率。
(2)本发明通过Mosaic、粘贴、高斯模糊等数据增强处理扩大了数据集,加强了数据集中的特征信息,克服训练数据集不足、特征信息少导致训练效果差的问题,进一步提高检测精度。
(3)本发明提出的SF-YOLOv5网络结构,通过将YOLOv5中C3模块替换为C3SwinTR,可以更好地适应不同尺度的目标,通过滑动窗口机制,只计算感兴趣的局部像素,减少了计算量;通过多头自注意力机制,捕捉不同位置之间的依赖关系,从而更好地融合不同尺度的特征图,提高目标检测的精度;
在YOLOv5的骨干网络末端引入多头自注意力层C3_MHSA,实现低分辨率特征图上的全局自注意,做到了有效地处理并汇总特征图中不同尺寸大小缺陷的语义信息,提高缺陷检测的准确率;
在特征融合阶段使用Fusion-Concat替代PANet的Concat拼接,通过引入权重参数自适应地调整特征图之间的权重,从而更好地融合不同尺度的特征图,同时可视化权重可以直观地展示网络在特征融合阶段的注意力分布;
通过CP-Cluster对目标检测结果进行后处理,不需要对候选框按照置信度值进行排序,可以实现并行化,能更好地应用于实时任务场景;相比于传统的YOLOv5使用基于NMS的方法对候选框简单的去重操作,CP-Cluster通过消息传递机制在相邻的候选框之间进行迭代,在去除重复框的同时,可以增强真正的正样本的置信度值,惩罚冗余边界框,从而增加检测精度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
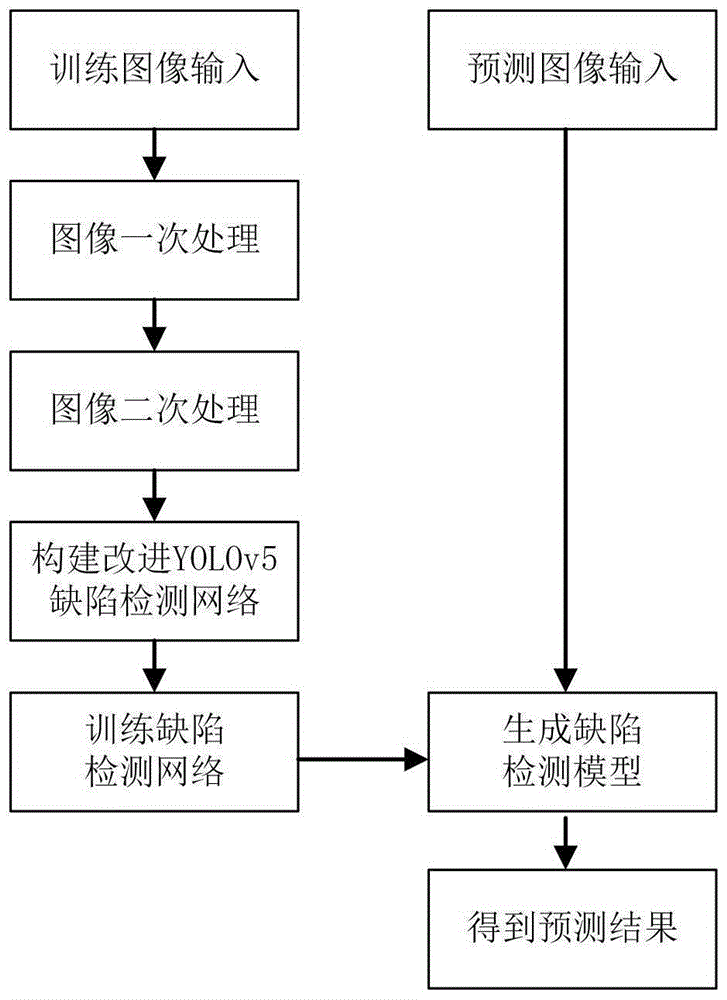
图1附图为本发明提供的基于改进YOLOv5的电站屋面工程缺陷检测方法流程图;
图2附图为本发明提供的基于改进YOLOv5的缺陷检测网络结构图;
图3附图为本发明提供的基本卷积单元C3模块结构图;
图4附图为本发明提供的残差单元结构图;
图5附图为本发明提供的C3SwinTR结构图;
图6附图为本发明提供的Swin-transformer结构图;
图7附图为本发明提供的融合Fusion-Concat的PANet结构图;
图8附图为本发明提供的CP-Cluster结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
本发明实施例公开了一种基于SF-YOLOv5的电站屋面工程缺陷检测方法,主要用于基于可见光设备拍摄图像的电站建筑物屋面工程表面缺陷检测,假设电站屋面工程图像由人工或者无人机航拍获得,经过人工标注得到电站屋面工程缺陷数据集,电站建筑物屋面工程缺陷包含找平层起砂、隔汽层破损、保温层拼缝不严密、隔离层破损、防水层卷材皱起五类缺陷,经过人工标注后的电站屋面工程缺陷数据集用于本发明中缺陷检测网络的训练。
本发明提出的缺陷检测网络为基于SF-YOLOv5的电站屋面工程缺陷检测网络,以电站屋面工程缺陷数据集为训练数据集,缺陷检测流程如图1所示,包括如下步骤:
S1:图像预处理,首先将电站屋面工程缺陷数据集中的原始图像进行一次处理,进行数据增强,然后对一次处理后的图像进行二次处理,生成统一大小的图片;
S2:将上述预处理后的数据集输入SF-YOLOv5网络结构中,进行强化训练,将训练完成的网络参数保存,得到优化的缺陷检测模型;
S3:将待检测的图像输入缺陷检测模型,获得检测结果,实现电站屋面工程缺陷检测。
进一步的,在YOLOv5框架中融合Swin-Transformer和Fusion-Concat构建SF-YOLOv5网络结构。
进一步的,SF-YOLOv5网络结构分为骨干网络、颈网络和检测头三部分;
骨干网络:首先经过4个基本的特征提取阶段进行特征提取,特征提取阶段由CBS和不同数量的C3SwinTR组成,如图2所示;第一个特征提取阶段由两个CBS和3个C3SwinTR组成,第二个特征提取阶段由CBS和6个C3SwinTR组成,第三个特征提取单元由CBS和9个C3SwinTR组成,第四个特征提取阶段依次由CBS、融合了多头自注意力机制的C3_MHSA、CBS组成;CBS是一个组合操作。由卷积层C,归一化层B,激活函数S组成,卷积层用于提取特征,归一化用于加速训练过程,激活函数单元用于引入非线性;
颈网络:第四个特征提取阶段提取的特征图F3经过上采样后与第三个特征提取阶段提取的特征图F2进行Concat拼接,融合后的特征图经过C3_3和CBS进行进一步的特征提取得到中间特征图M1,上采样后与第二特征提取阶段提取的特征图F1进行Fusion-Concat拼接,经过C3_3得到中间特征图M2,最后经过卷积作为检测头输出Ⅰ;中间特征图M2经过CBS后与中间特征图M1进行Fusion-Concat拼接,经过C3_3得到中间特征图M3,最后经过卷积作为检测头输出Ⅱ;中间特征图M3经过CBS和第四个特征提取阶段的输出F4进行Fusion-Concat拼接,经过C3_3和卷积作为检测头输出Ⅲ;C3是一个卷积层,如图3所示,使用3×3卷积核进行卷积操作,通过残差单元Res Unit进行特征图上进行局部特征提取。Fusion-Concat如图7所示,传统PANet的特征融合采用了Concat拼接,这样不能增加特征图包含的信息量,还会增加计算量。通过在特征图逐元素相加的过程中引入初始权重w1和w2,增加特征图包含的信息量,但并不会增加计算量,相当于在特征融合的阶段引入了注意力机制。
检测头:采用YOLO检测器,将特征图转换为模型输出结果,包括预测框的位置、类别和置信度。如图2中Prediction模块所示,负责生成目标检测结果的部分,其通常的作用是将网络中间特征图转换为目标检测结果,包括检测框的位置、类别和置信度信息。YOLOv5使用的检测头是基于YOLO系列的检测器。YOLO检测头将骨干网络提取的特征图分为不同的网格单元,并在每个单元上执行目标检测。使用锚框来定义不同尺度的检测框。这些锚框与不同尺度的网格单元相对应,用于检测不同大小的目标。锚框的尺寸和比例是在训练过程中学习的。本发明使用了76x76x255,38x38x255,19x19x255作为输出的维度,以此分别来检测较小、中等、较大的物体。
进一步的,残差单元Res Unit,如图4所示,是为了解决深层神经网络中存在的梯度消失和训练困难的问题。三个CBS是一部分输入先进行(Pointwise Convolution点卷积,即1x1卷积)对数据进行降维,再进行常规卷积核的卷积,最后PW对数据进行升维,然后与另一部分直接相加。假设输入是256维,如果不使用残差单元,而是直接与一个3×3×256的卷积层做卷积操作,那参数数量为256×3×3×256=589824。相比之下,如果使用瓶颈层,先经过1×1卷积核,再经过3×3卷积核,最后经过1×1卷积核,这样总的参数量为256×1×1×64+64×3×3×64+64×1×1×256=69632。相比之下减少了大量计算量和计算复杂度,提高了深度学习模型的性能。
MHSA多头自注意力层的计算过程如下:首先特征图F2经过CBS得到多头自注意力的输入矩阵A1,将输入矩阵A1中的每个点的高度和宽度编码,实现相对位置编码,然后经过三个投影矩阵,得到查询编码Q、键编码K和值编码V,再将各个向量编码和相对位置编码进行相乘和相加来得到单头自注意力层输出,再把多个单头自注意力层输出拼接,得到多注意力层输出,表达式为:
SA(R,Q,K,V)=Softmax(QR
S
O
其中,R为相对位置编码向量;Softmax为归一化指数函数,S为单头自注意力层输出,O
C3_MHSA模块如图2左下角所示:C3_MHSA包括三个CBS,一个MHSA和一个Concat,进行处理时,一半的特征向量经过CBS模块,另一半的特征向量经过CBS模块和多头自注意力层(MHSA),在Concat与经过CBS的一半特征向量拼接,再经过CBS模块生成第四特征提取层提取的特征图F3,避免了计算量冗余,更有效地处理和汇总特征图中密集、细小缺陷的语义信息。
骨干网络中特征提取阶段的C3SwinTR代替了传统YOLOv5的C3卷积模块,C3SwinTR结构如图5所示,将CNN与transformer结合来捕获图像的全局信息,而C3模块则使用多次局部卷积操作来获取图像的信息。C3SwinTR在通道维度划分,这样只需要对一半的特征进行卷积操作。C3SwinTR由多个Swin-transformer blocks组成,Swin-transformer blocks结构图如图6所示,由W-MSA,SW-MSA,MLP和LN组成。
W-MSA是将特征图划分到一个个窗口中,然后对每个窗口使用注意力模块,这样每个窗口内的像素点都会与其他像素点进行交互,从而得到窗口内的特征表示,划分多个窗口可以避免全局做自注意力计算时计算量过大的问题。
SW-MSA是一种局部平移的W-MSA,如果只采用W-MSA模块,则只会在每个窗口内进行自注意力计算,窗口与窗口之间是无法进行信息传递的。通过将窗口进行水平方向和垂直方向的平移,可以让不同窗口之间的信息交流。
MLP是一个多层感知机,用于对提出的特征进行非线性变换。它由多个全连接层组成,每个全连接层都包含一个线性变换和一个激活函数。
LN是一种归一化方法,用于加速模型的训练。将每个特征通道的均值和方差进行归一化,从而使得不同特征通道之间的分布更加一致,提高模型的泛化能力。
进一步的,融合CP-Cluster式使用基于置信度传播聚类CP-Cluster方法对目标检测结果进行后处理,替代传统的基于NMS的聚类方法,通过消息传递机制来迭代地惩罚冗余边界框,增强正样本的置信度,从而提高检测精度。
CP-Cluster计算流程如图8所示,CP-Cluster是一种后处理技术,当网络权重训练完成后,使用模型权重进行图片检测时,检测头生成了一系列预测框,CP-Cluster对这些预测框进行去重和优化,产生最终的检测结果。常规后处理的原理是将iou大于阈值的预测框使用边连接,构成几个无向图,然后同一个图结构里的预测框根据相邻边更新参数,过滤掉置信度低的预测框。CP-Cluster对目标检测结果进行后处理,通过消息传递机制在相邻的候选框之间进行,不需要对候选框按照置信度值进行排序,可以实现并行化在去除重复框的同时增强真正的正样本的置信度值,惩罚冗余边界框,从而增加检测精度。
实施例2
基于上述实施例,在一个具体实施例中,一次处理为扩充数据集,包括:将不同的缺陷对象的电站屋面工程缺陷图片更换背景得到不同环境下的缺陷图片;随机选取四张图片裁剪后Mosaic拼成一张新的数据图片;数据增强:将电站屋面工程缺陷图片进行高斯模糊处理,随机进行角度旋转、平行移动、亮度调节、灰度调整。
二次处理包括:对于图片像素小于520*520大小的每条边都采用灰度值0扩充20像素点;其次将图像裁剪至520*520大小;对裁剪后的图像进行边界扩充,每条边扩充20像素点,扩充后的图像大小为560*560大小;再将得到的图像进行通道转置,增加批量大小,转换为张量类型。其中,通道转置为将图像(h,w,3)转换为(3,h,w),增加批量大小,转换为(8,3,h,w),h为图像的高,w为图像的宽。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种油电混合动力机车能量管理控制系统和控制方法
- 一种油改电车型三电布置的设计方法和系统
- 一种基于三维实景建模技术的三电迁改设计方法