用于鉴定颗粒蛋白前体的结合配偶体的方法
文献发布时间:2024-04-18 20:01:23
相关申请的交叉引用
本申请要求2021年4月23日提交的美国临时申请63/178,831的权益,其全文以引用方式并入本文。
技术领域
本发明涉及用于鉴定颗粒蛋白前体的结合配偶体的高通量筛选方法。
以电子方式提交的参考序列表
本申请包含已经以ASCII格式电子递交的序列表,并且据此全文以引用方式并入。创建于2022年2月28日的所述ASCII副本命名为PRD4129WOPCT1_SL.txt并且大小为16,384字节。
背景技术
当大脑和脊髓中的神经系统细胞(神经元)开始退化时,发生神经退行性疾病。如今,540万美国人患有阿尔茨海默病;500,000人患有帕金森病;并且50,000-60,000人患有额颞叶痴呆(FTD)。因为神经退行性疾病主要发生在中年到晚年,因此随着人口老龄化,预计发病率将大幅上升。到2030年,多达1/5的美国人将超过65岁。寻找神经退行性疾病的治疗和治愈方法是一个日益紧迫的目标。
颗粒蛋白前体(PGRN)是由GRN基因编码的富含半胱氨酸的分泌蛋白,并且已知其与神经退行性变和其他疾病有关。大脑中PGRN水平的降低与家族性额颞叶变性(FTLD)相关。尽管有很强的相关性,但其导致神经退行性变的生物学机制仍不清楚。尽管已经提出了与PGRN结合的细胞表面受体,但这些受体与神经退行性变之间的联系仍不清楚,这表明其他结合配偶体可能在起作用。需要以高通量和无偏见的方式鉴定那些相互作用配偶体的方法。
发明内容
本文提供了一种用于鉴定结合颗粒蛋白前体(PGRN)的跨膜蛋白的高通量筛选方法,该方法包括:a)提供包含多个表达载体的cDNA集合,每个表达载体编码不同的跨膜蛋白;b)提供包含多个孔的板,其中其一个或多个孔各自含有宿主细胞;c)向该一个或多个孔中的每个孔中引入来自该集合的不同表达载体,从而在每个孔中产生不同的转染细胞;d)在允许每个孔中不同的跨膜蛋白表达的条件下培养该转染细胞;e)使该一个或多个孔中的每个孔中的转染细胞与包含附接到可检测标签的PGRN的靶蛋白接触;f)在与该靶蛋白接触之后,用固定剂对该转染细胞进行固定;g)对所固定的细胞进行洗涤;以及h)在对所固定的细胞进行洗涤之后,确定该一个或多个孔中的每个孔中的可检测标签的存在,其中如果确定该可检测标签存在于孔中,则由该孔中的转染细胞表达的跨膜蛋白被鉴定为结合PGRN的跨膜蛋白。
在高通量筛选方法的一个实施方案中,宿主细胞选自由以下项组成的组:人胚肾293T(HEK293T)细胞、HEK293F细胞、HeLa细胞、中国仓鼠卵巢(CHO)细胞、NIH 3T3细胞、MCF-7细胞、Hep G2细胞、幼仓鼠肾(BHK)细胞、BV-2(小鼠、C57BL/6、脑、小神经胶质)细胞、Neuro-2a(N2a)细胞和Cos7细胞。
在高通量筛选的另一个实施方案中,固定剂选自戊二醛、甲醇和多聚甲醛。
在高通量筛选方法的另一个实施方案中,可检测标签选自由以下项组成的组:绿荧光蛋白(GFP)、myc、myc-丙酮酸激酶(myc-PK)、His6、麦芽糖结合蛋白(MBP)、人流感病毒血凝素(HA)标签、flag标签(FLAG)和谷胱甘肽-S-转移酶(GST)标签。
在高通量筛选方法的另一个实施方案中,靶蛋白是FLAG标记的PGRN。在一个方面,步骤h)包括h1)将与荧光染料共价附接的抗FLAG抗体添加到含有转染细胞的孔中以对FLAG标记的PGRN(如果存在的话)进行免疫染色,以及h2)使用荧光计或成像仪以高通量方式检测该荧光染料。在另一方面,荧光染料是花青染料。
在高通量筛选方法的另一个实施方案中,靶蛋白是HA标记的PGRN。在一个方面,步骤h)包括h1)将该细胞暴露于与荧光染料共价附接的抗HA抗体以对HA标记的PGRN(如果存在的话)进行免疫染色,以及h2)使用荧光计或成像仪检测该荧光染料。在另一方面,荧光染料是Dylight650。
在高通量筛选方法的另一个实施方案中,在步骤g)和h)之间,该方法还包括用透化剂使所固定的细胞透化以及对所透化的细胞进行洗涤。
在高通量筛选方法的另一个实施方案中,透化剂选自由以下项组成的组:皂草苷、Triton X-100、溶血卵磷脂、正辛基-B-D-吡喃葡萄糖苷和Tween 20。
本文还提供了一种用于鉴定结合PGRN的细胞内蛋白的方法,该方法包括:a)将编码异源蛋白的表达载体引入到宿主细胞中,从而产生转染细胞;b)在允许该异源蛋白表达的条件下培养该转染细胞;c)用透化剂使该转染细胞透化;d)使所透化的细胞与包含附接到可检测标签的PGRN的靶蛋白接触;e)在与该靶蛋白接触之后,用固定剂对该转染细胞进行固定;f)对所固定的细胞进行洗涤;以及g)在对所固定的细胞进行洗涤之后,确定所洗涤的细胞上该可检测标签的存在,其中如果确定该可检测标签存在,则由该细胞表达的该异源蛋白被鉴定为结合PGRN的细胞内蛋白。
在该方法的一个实施方案中,宿主细胞选自由以下项组成的组:人胚肾293T(HEK293T)细胞、HEK293F细胞、HeLa细胞、中国仓鼠卵巢(CHO)细胞、NIH 3T3细胞、MCF-7细胞、Hep G2细胞、幼仓鼠肾(BHK)细胞、BV-2(小鼠、C57BL/6、脑、小神经胶质)细胞、Neuro-2a(N2a)细胞和Cos7细胞。
在该方法的另一个实施方案中,可检测标签选自由以下项组成的组:绿荧光蛋白(GFP)、myc、myc-丙酮酸激酶(myc-PK)、His6、麦芽糖结合蛋白(MBP)、人流感血凝素(HA)标签、flag标签(FLAG)和谷胱甘肽-S-转移酶(GST)标签。
在该方法的另一个实施方案中,靶蛋白是FLAG标记的PGRN。在一个方面,步骤g)包括g1)将该细胞暴露于与荧光染料共价附接的抗FLAG抗体以对FLAG标记的PGRN(如果存在的话)进行免疫染色,以及g2)使用荧光计或成像仪检测该荧光染料。在另一方面,荧光染料是花青染料。
在高通量筛选方法的另一个实施方案中,靶蛋白是HA标记的PGRN。在一个方面,步骤g)包括g1)将该细胞暴露于与荧光染料共价附接的抗HA抗体以对HA标记的PGRN(如果存在的话)进行免疫染色,以及g2)使用荧光计或成像仪检测该荧光染料。在另一方面,荧光染料是Dylight650。
在该方法的另一个实施方案中,在步骤b)和c)之间,该方法还包括用固定剂对所培养的细胞进行固定以及对所固定的细胞进行洗涤。
在该方法的另一个实施方案中,固定剂选自戊二醛、甲醇和多聚甲醛。
在该方法的另一个实施方案中,在步骤f)和g)之间,该方法还包括用透化剂使所固定的细胞透化以及对所透化的细胞进行洗涤。
在该方法的另一个实施方案中,透化剂选自由以下项组成的组:皂草苷、TritonX-100、溶血卵磷脂、正辛基-B-D-吡喃葡萄糖苷和Tween 20。
本文还进一步提供了一种用于鉴定结合PGRN的细胞内蛋白的高通量筛选方法,该方法包括:a)提供包含多个表达载体的cDNA集合,每个表达载体编码不同的异源蛋白;b)提供包含多个孔的板,其中其一个或多个孔各自含有宿主细胞;c)向该一个或多个孔中的每个孔中引入来自该集合的不同表达载体,从而在每个孔中产生不同的转染细胞;d)在允许每个孔中不同的异源蛋白表达的条件下培养该转染细胞;e)用透化剂使该转染细胞透化;f)使该一个或多个孔中的每个孔中的所透化的细胞与包含附接到可检测标签的PGRN的靶蛋白接触;g)在与该靶蛋白接触之后,用固定剂对该转染细胞进行固定;h)对所固定的细胞进行洗涤;以及i)在对所固定的细胞进行洗涤之后,确定该一个或多个孔中的每个孔中的可检测标签的存在,其中如果确定该可检测标签存在于孔中,则由该孔中的转染细胞表达的该异源蛋白被鉴定为结合PGRN的细胞内蛋白。
在高通量筛选方法的一个实施方案中,宿主细胞选自由以下项组成的组:人胚肾293T(HEK293T)细胞、HEK293F细胞、HeLa细胞、中国仓鼠卵巢(CHO)细胞、NIH 3T3细胞、MCF-7细胞、Hep G2细胞、幼仓鼠肾(BHK)细胞、BV-2(小鼠、C57BL/6、脑、小神经胶质)细胞、Neuro-2a(N2a)细胞和Cos7细胞。
在高通量筛选方法的另一个实施方案中,可检测标签选自由以下项组成的组:绿荧光蛋白(GFP)、myc、myc-丙酮酸激酶(myc-PK)、His6、麦芽糖结合蛋白(MBP)、人流感血凝素(HA)标签、flag标签(FLAG)和谷胱甘肽-S-转移酶(GST)标签。
在高通量筛选方法的另一个实施方案中,靶蛋白是FLAG标记的PGRN。在一个方面,步骤i)包括i1)将与荧光染料共价附接的抗FLAG抗体添加到含有该转染细胞的孔中以对FLAG标记的PGRN(如果存在的话)进行免疫染色,以及i2)使用荧光计或成像仪以高通量方式检测该荧光染料。在另一方面,荧光染料是花青染料。
在高通量筛选方法的另一个实施方案中,靶蛋白是HA标记的PGRN。在一个方面,步骤i)包括i1)将该细胞暴露于与荧光染料共价附接的抗HA抗体以对HA标记的PGRN(如果存在的话)进行免疫染色,以及i2)使用荧光计或成像仪检测该荧光染料。在另一方面,荧光染料是Dylight650。
在高通量筛选方法的另一个实施方案中,在步骤d)和e)之间,该方法还包括用固定剂对所培养的细胞进行固定以及对所固定的细胞进行洗涤。
在高通量筛选方法的另一个实施方案中,固定剂选自戊二醛、甲醇和多聚甲醛。
在高通量筛选方法的另一个实施方案中,在步骤h)和i)之间,该方法还包括用透化剂使所固定的细胞透化以及对所透化的细胞进行洗涤。
在高通量筛选方法的另一个实施方案中,透化剂选自由以下项组成的组:皂草苷、Triton X-100、溶血卵磷脂、正辛基-B-D-吡喃葡萄糖苷和Tween 20。
附图说明
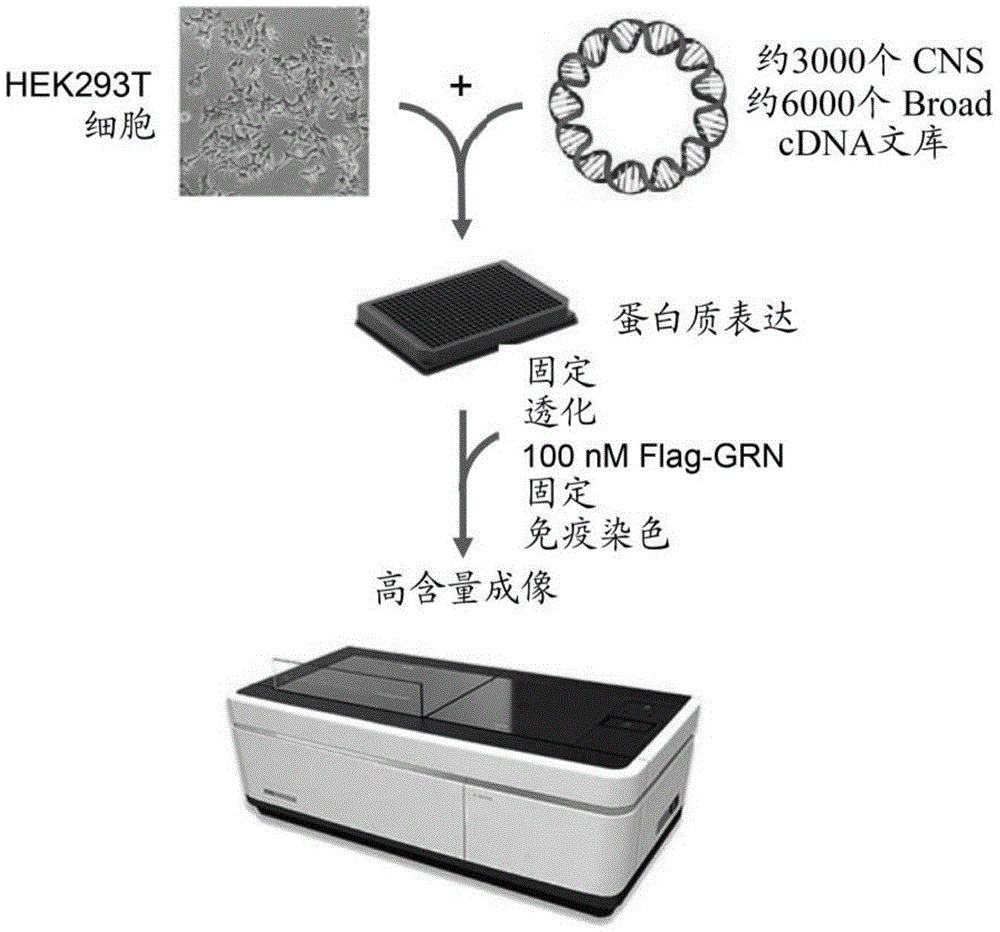
图1是描绘用于检测结合PGRN的细胞内蛋白的筛选策略的示意图。
图2示出了用pcDNA3载体转染的细胞(阴性对照)、用携带分拣蛋白(sortilin)编码序列的表达载体转染的细胞(阳性对照)以及用携带hit细胞内蛋白编码序列的表达质粒转染的细胞的Cy3强度。
图3A和图3C示出了转染细胞(阴性对照、阳性对照和Hit 1号)的Cy3强度或Dylight 650强度,该转染细胞暴露于FLAG标记的PGRN或HA标记的PGRN,随后分别用抗FlagM2-Cy3抗体或Dylight 650抗HA抗体进行免疫染色。图3B示出了用Hit 1号质粒转染但在免疫染色之前未暴露于标记的PGRN的细胞的Cy3信号和Dylight 650信号。
图4示出了转染细胞(阴性对照、阳性对照和Hit 1号)的Cy3强度或Dylight 650强度,该细胞在暴露于FLAG标记的PGRN或HA标记的PGRN以及免疫染色之前未经透化。
具体实施方式
背景以及说明书全篇中引用或描述了各种出版物、文章和专利;这些参考文献中的每一者全文均以引用方式并入本文。本说明书中包括的对文件、行为、材料、装置、文章等的讨论旨在为本发明提供上下文。此类讨论并不是承认这些事项中的任一事项或全部事项均关于所公开或受权利要求书保护的任何发明形成现有技术的一部分。
除非另有定义,否则本文使用的所有技术和科学术语的含义与本发明所属领域的普通技术人员通常所理解的含义相同。否则,本文所用的某些术语具有本说明书中所述的含义。
应该注意的是,除非上下文清楚地指明,否则如本文和所附权利要求中所用的单数形式“一个/一种”和“所述/该”包括复数引用物。
除非另有说明,否则任何数值,例如本文所述的浓度或浓度范围,应理解为在所有情况下均由术语“约”修饰。因此,数值通常包括所述值的±10%。例如,1mg/mL的浓度包括0.9mg/mL至1.1mg/mL。同样,1%至10%(w/v)的浓度范围包括0.9%(w/v)至11%(w/v)。除非上下文另有明确指示,否则如本文所用,使用的数值范围明确地包括所有可能的子范围、该范围之内的所有单个数值,包括此类范围之内的整数和该范围之内的分数。
除非另有说明,否则在一系列元素之前的术语“至少”应理解为指代系列中的每个元素。本领域的技术人员将会认识到、或仅使用常规实验就能够确定本文所述发明的具体实施方案的多种等同方案。此类等同方案旨在由本发明所涵盖。
如本文所用,术语“包含”、“包括”、“具有”或“含有”或其任何其它变型应被理解为是指包括指明的整数或整数组,但不排除任何其它整数或整数组,并且旨在是非排他性的或开放式的。例如,包含元素列表的组合物、混合物、过程、方法、制品或设备不一定仅限于那些元素,而是可以包括这些组合物、混合物、过程、方法、制品或设备未明确列出或固有的其它元素。此外,除非明确地指明相反,否则“或”是指包括性的或而不是指排他性的或。例如,条件A或B由以下任一项满足:A为真(或存在)而B为假(或不存在),A为假(或不存在)而B为真(或存在),以及A和B两者为真(或存在)。
如本文所用,多个列举的要素之间的连接术语“和/或”被理解为包含单个选项和组合选项两者。例如,在两个要素由“和/或”连接的情况下,第一种选项是指在没有第二个要素的情况下适用第一个要素。第二种选项是指在没有第一个要素的情况下适用第二个要素。第三种选项是指适合一起使用第一要素和第二要素。这些选项中的任一种均被理解为落在含义内,并且因此满足如本文所用的术语“和/或”的要求。多于一种选项的并行适用性也被理解为落在含义内,并且因此满足术语“和/或”的要求。
如本文所用,在说明书和权利要求书中通篇使用的术语“由……组成”表示包括任何列举的整数或整数组,但不能将附加的整数或整数组添加到指定的方法、结构或组成中。
如本文所用,在说明书和权利要求书中通篇使用的术语“基本上由……组成”表示包括任何列举的整数或整数组,并且任选地包括不会实质上改变指定方法、结构或组成的基本或新型特性的任何列举的整数或整数组。参见M.P.E.P.§2 111.03。
还应当理解,当提及优选发明的部件的尺寸或特性时,本文使用的“约”、“大约”、“大致”、“基本上”和类似的术语表示所描述的尺寸/特性不是严格的边界或参数,并且不排除在功能上相同或相似的微小变化,如本领域普通技术人员所理解的。至少,包括数值参数的这种参考将包括使用本领域已接受的数学和工业原理(例如,舍入、测量或其他系统误差、制造公差等)的变化,不会改变最低有效数字。
如本文所用,同义地称为“核酸分子”、“核苷酸”或“核酸”的术语“多核苷酸”是指任何多核糖核苷酸或多脱氧核糖核苷酸,其可为未修饰的RNA或DNA或者修饰的RNA或DNA。“多核苷酸”包括但不限于单链和双链的DNA、为单链区和双链区的混合物的DNA、单链和双链的RNA以及为单链区和双链区的混合物的RNA、包含可为单链或更典型地为双链或者为单链区和双链区的混合物的DNA和RNA的杂合分子。此外,“多核苷酸”是指包含RNA或DNA或RNA和DNA两者的三链区。术语多核苷酸还包括含有一个或多个修饰的碱基的DNA或RNA,以及具有出于稳定性或其它原因而被修饰的主链的DNA或RNA。“修饰的”碱基包括例如三苯甲基化的碱基和稀有碱基诸如肌苷。可以对DNA和RNA进行多种修饰;因此,“多核苷酸”包括通常天然存在的多核苷酸的化学修饰、酶修饰或代谢修饰形式,以及病毒和细胞特有的DNA和RNA的化学形式。“多核苷酸”也包括相对短的核酸链,通常被称为寡核苷酸。
如本文所用,术语“肽”、“多肽”或“蛋白质”可指由氨基酸组成的分子,并且可被本领域的技术人员识别为蛋白质。本文使用氨基酸残基的常规单字母或三字母代码。术语“肽”、“多肽”和“蛋白质”在本文中可互换使用,指任何长度的氨基酸的聚合物。该聚合物可为直链或支链的,其可包含经修饰的氨基酸,并且其可夹杂有非氨基酸。该术语还涵盖已被天然修饰或通过干预修饰的氨基酸聚合物;天然修饰或干预修饰为例如二硫键形成、糖基化、脂化、乙酰化、磷酸化或任何其他操作或修饰,诸如与标记组分缀合。该定义还包括例如含有一种或多种氨基酸类似物(包括例如非天然氨基酸等)以及本领域已知的其他修饰的多肽。
本文所述的肽序列根据通常的惯例书写,其中肽的N端区在左侧,并且C端区在右侧。虽然氨基酸的同分异构形式是已知的,但除非另外明确指明,它是所表示的氨基酸的L形式。
结合PGRN的跨膜蛋白的鉴定
在一个方面,本文公开的发明是用于以高通量(HTP)方式筛选与颗粒蛋白前体(PGRN)结合的跨膜蛋白的方法。
具体地,在筛选方法中利用由与可检测标签融合的PGRN构成的靶蛋白、cDNA文库或集合以及宿主细胞。
PGRN是由GRN基因(NCBI登录号:NM_002087.3)编码的富含半胱氨酸的分泌蛋白。在形成靶蛋白时,PGRN与可检测标签肽融合。此类标签肽是本领域众所周知的,并且包括但不限于绿荧光蛋白(GFP)、myc、myc-丙酮酸激酶(myc-PK)、多组氨酸(His6)标签、麦芽糖结合蛋白(MBP)、人流感病毒血凝素(HA)标签(YPYDVPDYA,SEQ ID NO:1)、flag标签(FLAG)(DYKDDDDK,SEQ ID NO:2)和谷胱甘肽-S-转移酶(GST)标签。然而,本发明决不应被解释为限于上文列出的标签。相反,可以以基本上类似于这些标签的方式起作用的任何肽或多肽应被解释为包括在本发明中。
cDNA文库包括多个表达载体,每个表达载体编码不同的跨膜蛋白。在一个实施方案中,表达载体中的每个表达载体编码人跨膜蛋白。术语“载体”是指能够转运与其连接的另一种核酸的核酸分子。一种类型的载体是“质粒”,其是指可以插入另外的DNA片段的环状双链DNA环。另一种类型的载体是病毒载体,其中可以插入另外的DNA片段。表达载体是能够指导与其可操作地连接的基因的表达的那些载体。本文所用的表达载体包含编码适合于在宿主细胞中表达核酸的形式的蛋白质序列的核酸。因此,表达载体可以包括一个或多个调控序列,诸如基于待用于表达的宿主细胞进行选择的、可操作地连接至待表达的核酸序列的启动子。当关于表达载体使用时,“可操作地连接”旨在表示所关注的核苷酸序列以允许表达核苷酸序列的方式(例如,在体外转录/翻译系统中或当载体被引入到宿主细胞中时在宿主细胞中)连接至调控序列。本领域普通技术人员应当理解,表达载体的设计可以取决于诸如待转化的宿主细胞的选择和期望的蛋白质的表达水平以及载体的预期用途之类的因素。适用于本文的示例性cDNA文库可包括但不限于来自ThermoFisher的
本文可以使用任何合适的宿主细胞。在一个实施方案中,本文使用的宿主细胞是哺乳动物细胞。合适的哺乳动物细胞可以选自人胚肾293T(HEK293T)细胞、HEK293F细胞、HeLa细胞、中国仓鼠卵巢(CHO)细胞、NIH 3T3细胞、MCF-7细胞、Hep G2细胞、幼仓鼠肾(BHK)细胞、BV-2(小鼠、C57BL/6、脑、小神经胶质)细胞、Neuro-2a(N2a)细胞和Cos7细胞。
用于鉴定结合颗粒蛋白前体(PGRN)的跨膜蛋白的高通量筛选方法使用多孔板,诸如96孔板、384孔板或1536孔板,并且其中将培养基中的宿主细胞放置在板的至少一个孔中。以高通量方式,将来自cDNA文库的表达载体引入到含有宿主细胞的每个孔中,并且将多孔板维持在合适的培养条件下,以允许由表达载体编码的跨膜蛋白的转染和表达。本文使用的培养基没有特别限制。示例性培养基包括但不限于Dulbecco改良的Eagle培养基(DMEM)、Roswell Park Memorial Institute 1640培养基(RPMI 1640)、Ham's F-12营养混合物(F-12)、Dulbecco改良的Eagle培养基:营养混合物F-12(DMEM/F-12)和最低必需培养基(MEM)。合适的培养条件可以是5% CO
在除去培养基之后,以高通量方式将靶蛋白(即,与可检测标签融合的PGRN)分配到含有转染的宿主细胞的每个孔中,并且将多孔板维持在合适的条件下以允许跨膜蛋白与靶蛋白之间的潜在结合。在一个实施方案中,将转染细胞与靶蛋白在约20℃-37℃下保持接触1小时-3小时。然后,将固定剂添加到多孔板的每个孔中以固定转染细胞,随后用洗涤缓冲液洗涤以除去未结合的靶蛋白。合适的固定剂的示例包括戊二醛、甲醇和多聚甲醛。这些固定剂的浓度范围通常对于多聚甲醛为0.01%至8%,并且对于戊二醛为0.001%至2%。也可以使采用这两种试剂的组合。多聚甲醛的优选浓度为0.1%至6%,最优选浓度为1%至5%。戊二醛的优选浓度为0.01%至1%,最优选浓度为0.05%至0.5%。调整固定剂的特定浓度以最佳地固定特定细胞类型。合适的洗涤缓冲液的示例包括HEPES平衡盐溶液(HBSS)、磷酸盐缓冲盐水(PBS)、Tris缓冲盐水(TBS)等。
最后,针对每个孔中的可检测标签的存在对板进行筛选,其中如果确定可检测标签存在于孔中,则由孔中含有的转染细胞表达的跨膜蛋白被鉴定为结合PGRN的跨膜蛋白。优选地,可检测标签的筛选是自动化过程。
任选地,在对可检测标签进行最终筛选之前,用透化剂使每个孔中的细胞透化,随后用洗涤缓冲液对其进行洗涤。透化剂通常是洗涤剂或洗涤剂样化合物,并且可包括但不限于皂草苷、Triton X-100、溶血卵磷脂、正辛基-B-D-吡喃葡萄糖苷和Tween 20。
从将宿主细胞放置在一个或多个孔中开始直到筛选可检测标签的存在,该过程的每个步骤可以以高通量方式,诸如通过机械臂进行。
在一个实施方案中,可检测标签是FLAG标签,并且靶蛋白是N末端FLAG标记的PGRN。最终筛选包括将与荧光染料(诸如花青染料,例如Cy3或Cy5)共价附接的抗FLAG抗体添加到含有转染细胞的孔中以对FLAG标记的PGRN(如果存在的话)进行免疫染色,以及使用例如荧光计或成像仪检测该荧光染料。
N末端FLAG标记的PGRN:
SEQ ID NO:3
ATGTGGACTCTGGTCTCATGGGTGGCTCTGACTGCTGGACTGGTGGCTGGAACCGACTACAAGGACGACGACGACAAACTCGCTGCCCTGACGGCCAGTTCTGCGACAAATGGCCCACAACACTGAGCAGGCATCTGGGTGGCCCCTGCCAGGTTGATGCCCACTGCTCTGCCGGCCACTCCTGCATCTTTACCGTCTCAGGGACTTCCAGTTGCTGCCCCTTCCCAGAGGCCGTGGCATGCGGGGATGGCCATCACTGCTGCCCACGGGGCTTCCACTGCAGTGCAGACGGGCGATCCTGCTTCCAAAGATCAGGTAACAACTCCGTGGGTGCCATCCAGTGCCCTGATAGTCAGTTCGAATGCCCGGACTTCTCCACGTGCTGTGTTATGGTCGATGGCTCCTGGGGGTGCTGCCCCATGCCCCAGGCTTCCTGCTGTGAAGACAGGGTGCACTGCTGTCCGCACGGTGCCTTCTGCGACCTGGTTCACACCCGCTGCATCACACCCACGGGCACCCACCCCCTGGCAAAGAAGCTCCCTGCCCAGAGGACTAACAGGGCAGTGGCCTTGTCCAGCTCGGTCATGTGTCCGGACGCACGGTCCCGGTGCCCTGATGGTTCTACCTGCTGTGAGCTGCCCAGTGGGAAGTATGGCTGCTGCCCAATGCCCAACGCCACCTGCTGCTCCGATCACCTGCACTGCTGCCCCCAAGACACTGTGTGTGACCTGATCCAGAGTAAGTGCCTCTCCAAGGAGAACGCTACCACGGACCTCCTCACTAAGCTGCCTGCGCACACAGTGGGGGATGTGAAATGTGACATGGAGGTGAGCTGCCCAGATGGCTATACCTGCTGCCGTCTACAGTCGGGGGCCTGGGGCTGCTGCCCTTTTACCCAGGCTGTGTGCTGTGAGGACCACATACACTGCTGTCCCGCGGGGTTTACGTGTGACACGCAGAAGGGTACCTGTGAACAGGGGCCCCACCAGGTGCCCTGGATGGAGAAGGCCCCAGCTCACCTCAGCCTGCCAGACCCACAAGCCTTGAAGAGAGATGTCCCCTGTGATAATGTCAGCAGCTGTCCCTCCTCCGATACCTGCTGCCAACTCACGTCTGGGGAGTGGGGCTGCTGTCCAATCCCAGAGGCTGTCTGCTGCTCGGACCACCAGCACTGCTGCCCCCAGGGCTACACGTGTGTAGCTGAGGGGCAGTGTCAGCGAGGAAGCGAGATCGTGGCTGGACTGGAGAAGATGCCTGCCCGCCGGGCTTCCTTATCCCACCCCAGAGACATCGGCTGTGACCAGCACACCAGCTGCCCGGTGGGGCAGACCTGCTGCCCGAGCCTGGGTGGGAGCTGGGCCTGCTGCCAGTTGCCCCATGCTGTGTGCTGCGAGGATCGCCAGCACTGCTGCCCGGCTGGCTACACCTGCAACGTGAAGGCTCGATCCTGCGAGAAGGAAGTGGTCTCTGCCCAGCCTGCCACCTTCCTGGCCCGTAGCCCTCACGTGGGTGTGAAGGACGTGGAGTGTGGGGAAGGACACTTCTGCCATGATAACCAGACCTGCTGCCGAGACAACCGACAGGGCTGGGCCTGCTGTCCCTACCGCCAGGGCGTCTGTTGTGCTGATCGGCGCCACTGCTGTCCTGCTGGCTTCCGCTGCGCAGCCAGGGGTACCAAGTGTTTGCGCAGGGAGGCCCCGCGCTGGGACGCCCCTTTGAGGGACCCAGCCTTGAGACAGCTGCTGTGAGGGACAGTACTGAAGACTCTGCAGCCCTCGGGACCCCACTCGGAGGGTGCCCTCTGCTCA
SEQ ID NO:4
MWTLVSWVALTAGLVAGTDYKDDDDKRCPDGQFCPVACCLDPGGASYSCCRPLLDKWPTTLSRHLGGPCQVDAHCSAGHSCIFTVSGTSSCCPFPEAVACGDGHHCCPRGFHCSADGRSCFQRSGNNSVGAIQCPDSQFECPDFSTCCVMVDGSWGCCPMPQASCCEDRVHCCPHGAFCDLVHTRCITPTGTHPLAKKLPAQRTNRAVALSSSVMCPDARSRCPDGSTCCELPSGKYGCCPMPNATCCSDHLHCCPQDTVCDLIQSKCLSKENATTDLLTKLPAHTVGDVKCDMEVSCPDGYTCCRLQSGAWGCCPFTQAVCCEDHIHCCPAGFTCDTQKGTCEQGPHQVPWMEKAPAHLSLPDPQALKRDVPCDNVSSCPSSDTCCQLTSGEWGCCPIPEAVCCSDHQHCCPQGYTCVAEGQCQRGSEIVAGLEKMPARRASLSHPRDIGCDQHTSCPVGQTCCPSLGGSWACCQLPHAVCCEDRQHCCPAGYTCNVKARSCEKEVVSAQPATFLARSPHVGVKDVECGEGHFCHDNQTCCRDNRQGWACCPYRQGVCCADRRHCCPAGFRCAARGTKCLRREAPRWDAPLRDPALRQLL
在一个实施方案中,可检测标签是HA标签,并且靶蛋白是N末端HA标记的PGRN。最终筛选包括将与染料共价附接的抗HA抗体(诸如Dylight
N末端HA标记的PGRN:
SEQ ID NO:5
ATGTGGACTCTGGTCTCATGGGTGGCTCTGACTGCTGGACTGGTGGCTGGAACCTACCCATACGATGTTCCAGATTACGCTCGCTGCCCTGACGGC
CAGTTCTGCGACAAATGGCCCACAACACTGAGCAGGCATCTGGGTGG
CCCCTGCCAGGTTGATGCCCACTGCTCTGCCGGCCACTCCTGCATCTTT
ACCGTCTCAGGGACTTCCAGTTGCTGCCCCTTCCCAGAGGCCGTGGCA
TGCGGGGATGGCCATCACTGCTGCCCACGGGGCTTCCACTGCAGTGCA
GACGGGCGATCCTGCTTCCAAAGATCAGGTAACAACTCCGTGGGTGC
CATCCAGTGCCCTGATAGTCAGTTCGAATGCCCGGACTTCTCCACGTG
CTGTGTTATGGTCGATGGCTCCTGGGGGTGCTGCCCCATGCCCCAGGC
TTCCTGCTGTGAAGACAGGGTGCACTGCTGTCCGCACGGTGCCTTCTG
CGACCTGGTTCACACCCGCTGCATCACACCCACGGGCACCCACCCCCT
GGCAAAGAAGCTCCCTGCCCAGAGGACTAACAGGGCAGTGGCCTTGT
CCAGCTCGGTCATGTGTCCGGACGCACGGTCCCGGTGCCCTGATGGTT
CTACCTGCTGTGAGCTGCCCAGTGGGAAGTATGGCTGCTGCCCAATGC
CCAACGCCACCTGCTGCTCCGATCACCTGCACTGCTGCCCCCAAGACA
CTGTGTGTGACCTGATCCAGAGTAAGTGCCTCTCCAAGGAGAACGCTA
CCACGGACCTCCTCACTAAGCTGCCTGCGCACACAGTGGGGGATGTG
AAATGTGACATGGAGGTGAGCTGCCCAGATGGCTATACCTGCTGCCG
TCTACAGTCGGGGGCCTGGGGCTGCTGCCCTTTTACCCAGGCTGTGTG
CTGTGAGGACCACATACACTGCTGTCCCGCGGGGTTTACGTGTGACAC
GCAGAAGGGTACCTGTGAACAGGGGCCCCACCAGGTGCCCTGGATGG
AGAAGGCCCCAGCTCACCTCAGCCTGCCAGACCCACAAGCCTTGAAG
AGAGATGTCCCCTGTGATAATGTCAGCAGCTGTCCCTCCTCCGATACC
TGCTGCCAACTCACGTCTGGGGAGTGGGGCTGCTGTCCAATCCCAGAG
GCTGTCTGCTGCTCGGACCACCAGCACTGCTGCCCCCAGGGCTACACG
TGTGTAGCTGAGGGGCAGTGTCAGCGAGGAAGCGAGATCGTGGCTGG
ACTGGAGAAGATGCCTGCCCGCCGGGCTTCCTTATCCCACCCCAGAGA
CATCGGCTGTGACCAGCACACCAGCTGCCCGGTGGGGCAGACCTGCT
GCCCGAGCCTGGGTGGGAGCTGGGCCTGCTGCCAGTTGCCCCATGCTG
TGTGCTGCGAGGATCGCCAGCACTGCTGCCCGGCTGGCTACACCTGCA
ACGTGAAGGCTCGATCCTGCGAGAAGGAAGTGGTCTCTGCCCAGCCT
GCCACCTTCCTGGCCCGTAGCCCTCACGTGGGTGTGAAGGACGTGGA
GTGTGGGGAAGGACACTTCTGCCATGATAACCAGACCTGCTGCCGAGACAACCGACAGGGCTGGGCCTGCTGTCCCTACCGCCAGGGCGTCTGTTGTGCTGATCGGCGCCACTGCTGTCCTGCTGGCTTCCGCTGCGCAGCCAGGGGTACCAAGTGTTTGCGCAGGGAGGCCCCGCGCTGGGACGCCCCTTTGAGGGACCCAGCCTTGAGACAGCTGCTGTGAGGGACAGTACTGAAGACTCTGCAGCCCTCGGGACCCCACTCGGAGGGTGCCCTCTGCTCA
SEQ ID NO:6
MWTLVSWVALTAGLVAGTYPYDVPDYARCPDGQFCPVACCLDPGGASYSCCRPLLDKWPTTLSRHLGGPCQVDAHCSAGHSCIFTVSGTSSCCPFPEAVACGDGHHCCPRGFHCSADGRSCFQRSGNNSVGAIQCPDSQFECPDFSTCCVMVDGSWGCCPMPQASCCEDRVHCCPHGAFCDLVHTRCITPTGTHPLAKKLPAQRTNRAVALSSSVMCPDARSRCPDGSTCCELPSGKYGCCPMPNATCCSDHLHCCPQDTVCDLIQSKCLSKENATTDLLTKLPAHTVGDVKCDMEVSCPDGYTCCRLQSGAWGCCPFTQAVCCEDHIHCCPAGFTCDTQKGTCEQGPHQVPWMEKAPAHLSLPDPQALKRDVPCDNVSSCPSSDTCCQLTSGEWGCCPIPEAVCCSDHQHCCPQGYTCVAEGQCQRGSEIVAGLEKMPARRASLSHPRDIGCDQHTSCPVGQTCCPSLGGSWACCQLPHAVCCEDRQHCCPAGYTCNVKARSCEKEVVSAQPATFLARSPHVGVKDVECGEGHFCHDNQTCCRDNRQGWACCPYRQGVCCADRRHCCPAGFRCAARGTKCLRREAPRWDAPLRDPALRQL
优选地,高含量通量成像仪用于检测标记的PGRN。
结合PGRN的细胞内蛋白的鉴定
在另一方面,本文公开的发明是用于筛选与颗粒蛋白前体(PGRN)结合的细胞内蛋白的方法。该方法的示意图在图1中示出。
在该方法中,使用由与可检测标签(如上所述)融合的PGRN构成的靶蛋白、包含各自编码不同蛋白(优选人蛋白,更优选人细胞内蛋白)的多个表达载体的cDNA文库或集合以及宿主细胞(如上所述)。
该方法包括将来自cDNA文库的表达载体引入到宿主细胞中,并在合适的培养条件下将表达载体和宿主细胞维持在合适的培养基中,以允许由表达载体编码的蛋白质的转染和表达。合适的培养条件与上文所述的那些相同。
在除去培养基之后,用透化剂(如上所述)使转染细胞透化,随后用洗涤缓冲液对其进行洗涤。透化剂可以充分破坏细胞的细胞膜以允许靶蛋白进入细胞。然后使透化的细胞与靶蛋白接触并维持在合适的条件(如上所述)下以允许细胞内蛋白与靶蛋白之间的潜在结合。任选地,在透化之前,用固定剂对转染细胞进行固定,随后用洗涤缓冲液对其进行洗涤。
在接触靶蛋白之后,用固定剂(如上所述)对细胞进行固定,并用洗涤缓冲液对其进行洗涤以除去未结合的靶蛋白。
最后,确定可检测标签的存在,其中如果确定该可检测标签存在,则由表达载体编码的蛋白质被鉴定为结合PGRN的细胞内蛋白。
任选地,在检测可检测标签之前,用透化剂使固定的细胞再次透化,随后用洗涤缓冲液对其进行洗涤。
在一个实施方案中,可检测标签是FLAG标签,并且靶蛋白是N末端FLAG标记的PGRN。为了确定FLAG标签的存在,添加与荧光染料(诸如花青染料,例如Cy3或Cy5)共价附接的抗FLAG抗体以对FLAG标记的PGRN(如果存在的话)进行免疫染色,并且使用成像仪或荧光计来检测细胞上该荧光染料的存在。
在一个实施方案中,可检测标签是HA标签,并且靶蛋白是N末端HA标记的PGRN。最终筛选包括将与染料共价附接的抗HA抗体(诸如Dylight
在一个实施方案中,以高通量方式进行与颗粒蛋白前体(PGRN)结合的细胞内蛋白的筛选。在高通量过程中,使用多孔板,诸如96孔板、384孔板或1536孔板。将合适培养基中的宿主细胞放置在板的一个或多个孔中。并且从将宿主细胞放置在一个或多个孔中开始直到筛选可检测标签的存在,该过程的每个步骤以高通量方式,诸如通过机械臂进行。
实施例
本领域的技术人员应当理解,在不脱离本发明的广义的发明构思的情况下,可对上述实施方案作出修改。因此,应当理解,本发明不限于所公开的特定实施方案,而是旨在涵盖如本说明书所定义的本发明实质和范围内的修改。
颗粒蛋白前体的细胞表面受体的鉴定
在该研究中,使用含有超过4,000个针对具有跨膜结构域的人和小鼠蛋白的转染就绪的cDNA质粒的cDNA集合(获自OriGene)。人开放阅读框(ORF)位于pCMV6-AC、pCMV6-XL4、pCMV6-XL5、pCMV6-XL6或pCMV6-NEO主链上,并且小鼠ORF位于pCMV6-Kan/Neo骨架上。使用Fugene 6(Promega)将cDNA质粒单独转染到384孔聚-D-赖氨酸涂覆的板(PerkinElmer)中的HEK293T细胞(ATCC)中。每个孔接种10,000个细胞。根据制造商的说明书使用Fugene 6,用60ng质粒DNA转染每个孔,其中0.3ng是作为转染效率对照的GFP质粒(在pcDNA3.1上表达的绿荧光蛋白(GFP)基因)。将细胞在37℃下温育1天,之后将它们移至30℃并温育2天。转染后三(3)天,将每个孔中的细胞与100nM N末端flag标记的PGRN在室温下温育2小时。在PGRN温育后,除去培养基,并且将细胞在室温下用4%多聚甲醛固定40分钟。然后,将细胞用HEPES平衡盐溶液(HBSS)洗涤3次,并在室温下用0.3% Triton X-100透化30分钟。在透化之后,将细胞再次洗涤3次,然后用400ng/mL的抗Flag M2-Cy3抗体(Sigma)在4℃下免疫染色过夜。第二天,将细胞再次洗涤3次,然后根据制造商的说明书用NucBlueLive ReadyProbes试剂(Invitrogen)染色。随后,使用Opera Phenix高含量通量成像机器(Perkin Elmer)对板进行成像。
颗粒蛋白前体的细胞内结合配偶体的鉴定
筛选约9,000个总质粒的两个单独的cDNA集合。对于在中枢神经系统(CNS)中表达的人和小鼠蛋白两者,第一个cDNA集合包括约3000个转染就绪的cDNA质粒。人ORF与上述类似,位于pCMV6-AC、pCMV6-XL4、pCMV6-XL5、pCMV6-XL6或pCMV6-NEO主链上。该集合中的小鼠ORF位于pCMV6-Entry主链上。该集合中的一些蛋白质用Myc-DDK标签标记,在这种情况下,HA标记的PGRN用于筛选。第二个cDNA集合含有约6000个选自hORFeome V8.1文库(获自Broad Institute)的转染就绪的cDNA质粒。使用Fugene 6(Promega)将质粒单独转染到384孔聚-D-赖氨酸涂覆的板(Perkin Elmer)中的HEK293T细胞(ATCC)中。每个孔接种10,000个细胞。根据制造商的说明书使用Fugene 6,用60ng质粒DNA转染每个孔,其中3ng是作为转染对照的GFP质粒。将细胞在37℃下温育1天,之后将它们移至30℃并温育2天。转染后三(3)天,除去培养基,并且将细胞在室温下用4%多聚甲醛固定40分钟。然后,将细胞用HBSS洗涤3次,并在室温下用0.3% Triton X-100透化30分钟。在透化之后,将细胞再次洗涤3次,并在室温下在含有100nM N末端flag标记的PGRN的Dulbecco改良的Eagle培养基(DMEM)中温育2小时。在与PGRN温育之后,除去DMEM,并且将细胞在室温下用4%多聚甲醛再次固定40分钟。在第2次固定之后,将细胞用HBSS再次洗涤3次,然后用400ng/mL的抗Flag M2-Cy3抗体(Sigma)在4℃下免疫染色过夜。第二天,将细胞再次洗涤3次,然后根据制造商的说明书用NucBlue Live ReadyProbes试剂(Invitrogen)染色。随后,使用Opera Phenix高含量通量成像机器(Perkin Elmer)对板进行成像。图2示出了用pcDNA3载体转染的细胞(阴性对照)和用携带分拣蛋白编码序列的表达载体转染的细胞(阳性对照)的Cy3强度。图2还示出了用9000个表达质粒中的一者转染的细胞的Cy3强度,其与阳性对照相当。因此,由表达质粒编码的细胞内蛋白被鉴定为Hit 1号。
Hit 1号的确认
将Hit 1号的质粒以及pcDNA3载体(阴性对照)和携带分拣蛋白编码序列的表达载体(阳性对照)单独转染到HEK293细胞中。按照根据“颗粒蛋白前体的细胞内结合配偶体的鉴定”描述的相同过程,将转染细胞暴露于N末端FLAG标记的PGRN或N末端HA标记的PGRN,随后分别用抗Flag M2-Cy3抗体和Dylight 650抗HA抗体进行免疫染色。如图3A和图3C所示,用Hit 1号质粒转染的细胞的Cy3和Dylight强度与阳性对照的Cy3和Dylight强度相当。此外,用Hit 1号质粒转染的细胞也用抗Flag M2-Cy3抗体和Dylight 650抗HA抗体进行免疫染色,而不预先暴露于FLAG标记的PGRN或HA标记的PGRN。如图3B所示,在两种情况下,荧光信号与阴性对照相同,证实了Hit 1号的鉴定不是由于非特异性抗体与用Hit 1号质粒转染的细胞结合。
此外,按照根据“颗粒蛋白前体的细胞表面受体的鉴定”所述的相同过程,将用pcDNA3载体(阴性对照)、携带分拣蛋白编码序列的表达载体(阳性对照)和Hit 1号质粒转染的HEK293细胞暴露于FLAG标记的PGRN或HA标记的PGRN而不进行透化,随后分别用抗FlagM2-Cy3抗体和Dylight 650抗HA抗体进行免疫染色。如图4所示,Hit 1号的荧光信号强度与阴性对照相同,证实了Hit 1号不是PGRN的表面受体。
序列表
<110> 詹森药业有限公司(Janssen Pharmaceutica NV)
<120> 用于鉴定颗粒蛋白前体的结合配偶体的方法
<130> PRD4129WOPCT1
<150> US 63/178831
<151> 2021-04-23
<160> 6
<170> PatentIn 3.5版本
<210> 1
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 1
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1 5
<210> 2
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 2
Asp Tyr Lys Asp Asp Asp Asp Lys
1 5
<210> 3
<211> 1808
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 3
atgtggactc tggtctcatg ggtggctctg actgctggac tggtggctgg aaccgactac60
aaggacgacg acgacaaact cgctgccctg acggccagtt ctgcgacaaa tggcccacaa 120
cactgagcag gcatctgggt ggcccctgcc aggttgatgc ccactgctct gccggccact 180
cctgcatctt taccgtctca gggacttcca gttgctgccc cttcccagag gccgtggcat 240
gcggggatgg ccatcactgc tgcccacggg gcttccactg cagtgcagac gggcgatcct 300
gcttccaaag atcaggtaac aactccgtgg gtgccatcca gtgccctgat agtcagttcg 360
aatgcccgga cttctccacg tgctgtgtta tggtcgatgg ctcctggggg tgctgcccca 420
tgccccaggc ttcctgctgt gaagacaggg tgcactgctg tccgcacggt gccttctgcg 480
acctggttca cacccgctgc atcacaccca cgggcaccca ccccctggca aagaagctcc 540
ctgcccagag gactaacagg gcagtggcct tgtccagctc ggtcatgtgt ccggacgcac 600
ggtcccggtg ccctgatggt tctacctgct gtgagctgcc cagtgggaag tatggctgct 660
gcccaatgcc caacgccacc tgctgctccg atcacctgca ctgctgcccc caagacactg 720
tgtgtgacct gatccagagt aagtgcctct ccaaggagaa cgctaccacg gacctcctca 780
ctaagctgcc tgcgcacaca gtgggggatg tgaaatgtga catggaggtg agctgcccag 840
atggctatac ctgctgccgt ctacagtcgg gggcctgggg ctgctgccct tttacccagg 900
ctgtgtgctg tgaggaccac atacactgct gtcccgcggg gtttacgtgt gacacgcaga 960
agggtacctg tgaacagggg ccccaccagg tgccctggat ggagaaggcc ccagctcacc1020
tcagcctgcc agacccacaa gccttgaaga gagatgtccc ctgtgataat gtcagcagct1080
gtccctcctc cgatacctgc tgccaactca cgtctgggga gtggggctgc tgtccaatcc1140
cagaggctgt ctgctgctcg gaccaccagc actgctgccc ccagggctac acgtgtgtag1200
ctgaggggca gtgtcagcga ggaagcgaga tcgtggctgg actggagaag atgcctgccc1260
gccgggcttc cttatcccac cccagagaca tcggctgtga ccagcacacc agctgcccgg1320
tggggcagac ctgctgcccg agcctgggtg ggagctgggc ctgctgccag ttgccccatg1380
ctgtgtgctg cgaggatcgc cagcactgct gcccggctgg ctacacctgc aacgtgaagg1440
ctcgatcctg cgagaaggaa gtggtctctg cccagcctgc caccttcctg gcccgtagcc1500
ctcacgtggg tgtgaaggac gtggagtgtg gggaaggaca cttctgccat gataaccaga1560
cctgctgccg agacaaccga cagggctggg cctgctgtcc ctaccgccag ggcgtctgtt1620
gtgctgatcg gcgccactgc tgtcctgctg gcttccgctg cgcagccagg ggtaccaagt1680
gtttgcgcag ggaggccccg cgctgggacg cccctttgag ggacccagcc ttgagacagc1740
tgctgtgagg gacagtactg aagactctgc agccctcggg accccactcg gagggtgccc1800
tctgctca 1808
<210> 4
<211> 601
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 4
Met Trp Thr Leu Val Ser Trp Val Ala Leu Thr Ala Gly Leu Val Ala
1 5 1015
Gly Thr Asp Tyr Lys Asp Asp Asp Asp Lys Arg Cys Pro Asp Gly Gln
202530
Phe Cys Pro Val Ala Cys Cys Leu Asp Pro Gly Gly Ala Ser Tyr Ser
354045
Cys Cys Arg Pro Leu Leu Asp Lys Trp Pro Thr Thr Leu Ser Arg His
505560
Leu Gly Gly Pro Cys Gln Val Asp Ala His Cys Ser Ala Gly His Ser
65707580
Cys Ile Phe Thr Val Ser Gly Thr Ser Ser Cys Cys Pro Phe Pro Glu
859095
Ala Val Ala Cys Gly Asp Gly His His Cys Cys Pro Arg Gly Phe His
100 105 110
Cys Ser Ala Asp Gly Arg Ser Cys Phe Gln Arg Ser Gly Asn Asn Ser
115 120 125
Val Gly Ala Ile Gln Cys Pro Asp Ser Gln Phe Glu Cys Pro Asp Phe
130 135 140
Ser Thr Cys Cys Val Met Val Asp Gly Ser Trp Gly Cys Cys Pro Met
145 150 155 160
Pro Gln Ala Ser Cys Cys Glu Asp Arg Val His Cys Cys Pro His Gly
165 170 175
Ala Phe Cys Asp Leu Val His Thr Arg Cys Ile Thr Pro Thr Gly Thr
180 185 190
His Pro Leu Ala Lys Lys Leu Pro Ala Gln Arg Thr Asn Arg Ala Val
195 200 205
Ala Leu Ser Ser Ser Val Met Cys Pro Asp Ala Arg Ser Arg Cys Pro
210 215 220
Asp Gly Ser Thr Cys Cys Glu Leu Pro Ser Gly Lys Tyr Gly Cys Cys
225 230 235 240
Pro Met Pro Asn Ala Thr Cys Cys Ser Asp His Leu His Cys Cys Pro
245 250 255
Gln Asp Thr Val Cys Asp Leu Ile Gln Ser Lys Cys Leu Ser Lys Glu
260 265 270
Asn Ala Thr Thr Asp Leu Leu Thr Lys Leu Pro Ala His Thr Val Gly
275 280 285
Asp Val Lys Cys Asp Met Glu Val Ser Cys Pro Asp Gly Tyr Thr Cys
290 295 300
Cys Arg Leu Gln Ser Gly Ala Trp Gly Cys Cys Pro Phe Thr Gln Ala
305 310 315 320
Val Cys Cys Glu Asp His Ile His Cys Cys Pro Ala Gly Phe Thr Cys
325 330 335
Asp Thr Gln Lys Gly Thr Cys Glu Gln Gly Pro His Gln Val Pro Trp
340 345 350
Met Glu Lys Ala Pro Ala His Leu Ser Leu Pro Asp Pro Gln Ala Leu
355 360 365
Lys Arg Asp Val Pro Cys Asp Asn Val Ser Ser Cys Pro Ser Ser Asp
370 375 380
Thr Cys Cys Gln Leu Thr Ser Gly Glu Trp Gly Cys Cys Pro Ile Pro
385 390 395 400
Glu Ala Val Cys Cys Ser Asp His Gln His Cys Cys Pro Gln Gly Tyr
405 410 415
Thr Cys Val Ala Glu Gly Gln Cys Gln Arg Gly Ser Glu Ile Val Ala
420 425 430
Gly Leu Glu Lys Met Pro Ala Arg Arg Ala Ser Leu Ser His Pro Arg
435 440 445
Asp Ile Gly Cys Asp Gln His Thr Ser Cys Pro Val Gly Gln Thr Cys
450 455 460
Cys Pro Ser Leu Gly Gly Ser Trp Ala Cys Cys Gln Leu Pro His Ala
465 470 475 480
Val Cys Cys Glu Asp Arg Gln His Cys Cys Pro Ala Gly Tyr Thr Cys
485 490 495
Asn Val Lys Ala Arg Ser Cys Glu Lys Glu Val Val Ser Ala Gln Pro
500 505 510
Ala Thr Phe Leu Ala Arg Ser Pro His Val Gly Val Lys Asp Val Glu
515 520 525
Cys Gly Glu Gly His Phe Cys His Asp Asn Gln Thr Cys Cys Arg Asp
530 535 540
Asn Arg Gln Gly Trp Ala Cys Cys Pro Tyr Arg Gln Gly Val Cys Cys
545 550 555 560
Ala Asp Arg Arg His Cys Cys Pro Ala Gly Phe Arg Cys Ala Ala Arg
565 570 575
Gly Thr Lys Cys Leu Arg Arg Glu Ala Pro Arg Trp Asp Ala Pro Leu
580 585 590
Arg Asp Pro Ala Leu Arg Gln Leu Leu
595 600
<210> 5
<211> 1809
<212> DNA
<213> 人工序列
<220>
<223> 合成多核苷酸
<400> 5
atgtggactc tggtctcatg ggtggctctg actgctggac tggtggctgg aacctaccca60
tacgatgttc cagattacgc tcgctgccct gacggccagt tctgcgacaa atggcccaca 120
acactgagca ggcatctggg tggcccctgc caggttgatg cccactgctc tgccggccac 180
tcctgcatct ttaccgtctc agggacttcc agttgctgcc ccttcccaga ggccgtggca 240
tgcggggatg gccatcactg ctgcccacgg ggcttccact gcagtgcaga cgggcgatcc 300
tgcttccaaa gatcaggtaa caactccgtg ggtgccatcc agtgccctga tagtcagttc 360
gaatgcccgg acttctccac gtgctgtgtt atggtcgatg gctcctgggg gtgctgcccc 420
atgccccagg cttcctgctg tgaagacagg gtgcactgct gtccgcacgg tgccttctgc 480
gacctggttc acacccgctg catcacaccc acgggcaccc accccctggc aaagaagctc 540
cctgcccaga ggactaacag ggcagtggcc ttgtccagct cggtcatgtg tccggacgca 600
cggtcccggt gccctgatgg ttctacctgc tgtgagctgc ccagtgggaa gtatggctgc 660
tgcccaatgc ccaacgccac ctgctgctcc gatcacctgc actgctgccc ccaagacact 720
gtgtgtgacc tgatccagag taagtgcctc tccaaggaga acgctaccac ggacctcctc 780
actaagctgc ctgcgcacac agtgggggat gtgaaatgtg acatggaggt gagctgccca 840
gatggctata cctgctgccg tctacagtcg ggggcctggg gctgctgccc ttttacccag 900
gctgtgtgct gtgaggacca catacactgc tgtcccgcgg ggtttacgtg tgacacgcag 960
aagggtacct gtgaacaggg gccccaccag gtgccctgga tggagaaggc cccagctcac1020
ctcagcctgc cagacccaca agccttgaag agagatgtcc cctgtgataa tgtcagcagc1080
tgtccctcct ccgatacctg ctgccaactc acgtctgggg agtggggctg ctgtccaatc1140
ccagaggctg tctgctgctc ggaccaccag cactgctgcc cccagggcta cacgtgtgta1200
gctgaggggc agtgtcagcg aggaagcgag atcgtggctg gactggagaa gatgcctgcc1260
cgccgggctt ccttatccca ccccagagac atcggctgtg accagcacac cagctgcccg1320
gtggggcaga cctgctgccc gagcctgggt gggagctggg cctgctgcca gttgccccat1380
gctgtgtgct gcgaggatcg ccagcactgc tgcccggctg gctacacctg caacgtgaag1440
gctcgatcct gcgagaagga agtggtctct gcccagcctg ccaccttcct ggcccgtagc1500
cctcacgtgg gtgtgaagga cgtggagtgt ggggaaggac acttctgcca tgataaccag1560
acctgctgcc gagacaaccg acagggctgg gcctgctgtc cctaccgcca gggcgtctgt1620
tgtgctgatc ggcgccactg ctgtcctgct ggcttccgct gcgcagccag gggtaccaag1680
tgtttgcgca gggaggcccc gcgctgggac gcccctttga gggacccagc cttgagacag1740
ctgctgtgag ggacagtact gaagactctg cagccctcgg gaccccactc ggagggtgcc1800
ctctgctca1809
<210> 6
<211> 601
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 6
Met Trp Thr Leu Val Ser Trp Val Ala Leu Thr Ala Gly Leu Val Ala
1 5 1015
Gly Thr Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Arg Cys Pro Asp Gly
202530
Gln Phe Cys Pro Val Ala Cys Cys Leu Asp Pro Gly Gly Ala Ser Tyr
354045
Ser Cys Cys Arg Pro Leu Leu Asp Lys Trp Pro Thr Thr Leu Ser Arg
505560
His Leu Gly Gly Pro Cys Gln Val Asp Ala His Cys Ser Ala Gly His
65707580
Ser Cys Ile Phe Thr Val Ser Gly Thr Ser Ser Cys Cys Pro Phe Pro
859095
Glu Ala Val Ala Cys Gly Asp Gly His His Cys Cys Pro Arg Gly Phe
100 105 110
His Cys Ser Ala Asp Gly Arg Ser Cys Phe Gln Arg Ser Gly Asn Asn
115 120 125
Ser Val Gly Ala Ile Gln Cys Pro Asp Ser Gln Phe Glu Cys Pro Asp
130 135 140
Phe Ser Thr Cys Cys Val Met Val Asp Gly Ser Trp Gly Cys Cys Pro
145 150 155 160
Met Pro Gln Ala Ser Cys Cys Glu Asp Arg Val His Cys Cys Pro His
165 170 175
Gly Ala Phe Cys Asp Leu Val His Thr Arg Cys Ile Thr Pro Thr Gly
180 185 190
Thr His Pro Leu Ala Lys Lys Leu Pro Ala Gln Arg Thr Asn Arg Ala
195 200 205
Val Ala Leu Ser Ser Ser Val Met Cys Pro Asp Ala Arg Ser Arg Cys
210 215 220
Pro Asp Gly Ser Thr Cys Cys Glu Leu Pro Ser Gly Lys Tyr Gly Cys
225 230 235 240
Cys Pro Met Pro Asn Ala Thr Cys Cys Ser Asp His Leu His Cys Cys
245 250 255
Pro Gln Asp Thr Val Cys Asp Leu Ile Gln Ser Lys Cys Leu Ser Lys
260 265 270
Glu Asn Ala Thr Thr Asp Leu Leu Thr Lys Leu Pro Ala His Thr Val
275 280 285
Gly Asp Val Lys Cys Asp Met Glu Val Ser Cys Pro Asp Gly Tyr Thr
290 295 300
Cys Cys Arg Leu Gln Ser Gly Ala Trp Gly Cys Cys Pro Phe Thr Gln
305 310 315 320
Ala Val Cys Cys Glu Asp His Ile His Cys Cys Pro Ala Gly Phe Thr
325 330 335
Cys Asp Thr Gln Lys Gly Thr Cys Glu Gln Gly Pro His Gln Val Pro
340 345 350
Trp Met Glu Lys Ala Pro Ala His Leu Ser Leu Pro Asp Pro Gln Ala
355 360 365
Leu Lys Arg Asp Val Pro Cys Asp Asn Val Ser Ser Cys Pro Ser Ser
370 375 380
Asp Thr Cys Cys Gln Leu Thr Ser Gly Glu Trp Gly Cys Cys Pro Ile
385 390 395 400
Pro Glu Ala Val Cys Cys Ser Asp His Gln His Cys Cys Pro Gln Gly
405 410 415
Tyr Thr Cys Val Ala Glu Gly Gln Cys Gln Arg Gly Ser Glu Ile Val
420 425 430
Ala Gly Leu Glu Lys Met Pro Ala Arg Arg Ala Ser Leu Ser His Pro
435 440 445
Arg Asp Ile Gly Cys Asp Gln His Thr Ser Cys Pro Val Gly Gln Thr
450 455 460
Cys Cys Pro Ser Leu Gly Gly Ser Trp Ala Cys Cys Gln Leu Pro His
465 470 475 480
Ala Val Cys Cys Glu Asp Arg Gln His Cys Cys Pro Ala Gly Tyr Thr
485 490 495
Cys Asn Val Lys Ala Arg Ser Cys Glu Lys Glu Val Val Ser Ala Gln
500 505 510
Pro Ala Thr Phe Leu Ala Arg Ser Pro His Val Gly Val Lys Asp Val
515 520 525
Glu Cys Gly Glu Gly His Phe Cys His Asp Asn Gln Thr Cys Cys Arg
530 535 540
Asp Asn Arg Gln Gly Trp Ala Cys Cys Pro Tyr Arg Gln Gly Val Cys
545 550 555 560
Cys Ala Asp Arg Arg His Cys Cys Pro Ala Gly Phe Arg Cys Ala Ala
565 570 575
Arg Gly Thr Lys Cys Leu Arg Arg Glu Ala Pro Arg Trp Asp Ala Pro
580 585 590
Leu Arg Asp Pro Ala Leu Arg Gln Leu
595 600
- 一种家用空调集成系统、智能控制系统及控制方法
- 一种微型植物工厂智能控制系统及其实现方法
- 一种电池智能中控系统及电池智能控制方法
- 一种基于数据融合的变压器远程智能控制系统及控制方法
- 一种清扫车的水系统智能控制方法
- 一种清扫车快速清理路面积液的智能控制方法及系统