一种治疗和预防癌症的融合蛋白及其医药应用
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及一种融合蛋白,具体涉及一种含有人MUC1的融合蛋白,还涉及该融合蛋白的编码基因,以及该融合蛋白的制备方法及医疗用途。
背景技术
结直肠癌是第三大致人死亡的癌症。尽管手术、放疗、化疗对对局部肿瘤有标准治疗方案,但是转移性结直肠癌的治疗却面临挑战。几十年来,对于晚期的结直肠癌的化疗方案有5-氟尿嘧啶为基础的FOLFOX(奥沙利铂)、FOLFIRI(伊利替康)、FOLFOXIRI(奥沙利铂伊利替康)方案和生物靶向疗法。生物靶向疗法包括VEGF阻断、EGFR阻断等。但晚期肿瘤患者应用EGFR抗体会造成病态,总体患者并未获益。总之,虽然化疗加生物靶向治疗使患者总体存活率有所提高,但是结直肠癌的5年存活率却只有14%,平均寿命不过30个月,治疗效果有待改善。
另一方面,癌症免疫系统的激活是另一种抑制结直肠癌细胞生长的的方法。2018年,可瑞达和纳武单抗这两种抗体被批准用于化疗抵抗的dMMR-MSI-H亚型结直肠癌的治疗。2020年又批准了可瑞达和纳武单抗这两种抗体用于不能手术的dMMR-MSI-H亚型的转移性结直肠癌的治疗。在淋巴器官内T细胞激活的启动期,CTLA-4(细胞毒淋巴细胞抗原4)和激活了的抗原递呈细胞上的B7蛋白质结合,从而抑制了T细胞的激活,降低了抗肿瘤的免疫反应。PD-1在外周组织和PD-L1、PD-L2相互作用,限制肿瘤微环境的效应T细胞活性。T细胞在肿瘤细胞的浸润是一个预后良好的标志,肿瘤浸润T细胞的数量和生存率的改善有关、和癌症的低复发也有关,肿瘤如何逃避免疫系统的监测被逐渐解析。但是癌症细胞如何和肿瘤微环境相互作用降低免疫功能、促进肿瘤生长还未完全了解,特别是如何促进从冷肿瘤变成热肿瘤是当前要解决的问题。例如,在胃癌、肝癌、结直肠癌的研究中,发现肿瘤反应率不依赖于生物标志物如微卫星高度不稳定(MSI-H)或者PD-L1表达,可能存在其它的免疫逃逸机制。
结肠癌的发展是一个复杂的过程,它积累遗传突变,导致治疗反应的异质性。只有5-15%的结直肠癌患者具有dMMR-MSI-H亚型这些预测性生物标志物,而大部分患者不能从这些治疗中获益。使用抗体的病人有助于降低复发风险,减少细胞毒治疗的副作用,但受到个体化、共发疾病的影响、免疫微环境、肠道微生物复杂因素的限制。更让患者头疼的是出现疲劳、腹泻、瘙痒(pruritus)、甲状腺功能障碍、肝炎、关节痛(arthralgia)、发烧、皮疹(rash)等多种副作用。联合免疫点监测疗法增加了3-4级副作用出现的几率。
长期以来,结直肠癌过继性细胞治疗如肿瘤浸润淋巴细胞治疗(TIL)、细胞因子诱导杀伤性细胞治疗(CIK)的研究在进行中,但效果不明朗,可能和结直肠癌TIL较少和免疫细胞被抑制有关系。癌细胞上表达的自然杀伤组2D配体(NKG2D)、表皮生长因子受体2(HER2)、间皮素、鸟苷酰环化酶、粘蛋白1、新生抗原、CEA为靶点进行的CAR-T疗法也在进展中。其中CEA为靶点进行的CAR-T治疗取得了部分临床效果,但面临癌细胞周围物理屏障、免疫抑制微环境的阻碍,花费也非常高昂。
为此,开发花费较低、效果更好的治疗方法显得非常重要,其中治疗性癌症疫苗被寄予厚望。目前研究较为火热的新生抗原(neoantigen)疫苗需要高通量的测序和生物信息学的筛选,时间花费和资源需求较大,难以造福患者。本发明公开一种可用于价格低廉的治疗性癌症疫苗制备的、适用于大肠杆菌生产且抑制结肠癌细胞生长的重组蛋白质的基因优化方法。
发明内容
为了提供更为有效的肿瘤预防和治疗生物制剂,本发明提供了一种优化的MUC1-N、MBP以及其融合蛋白,及其医药用途。
本发明提供了一种优化的MUC1-N蛋白,其特征在于,其核苷酸序列如SEQ ID NO.3所示。
本发明还提供了一种优化的多核苷酸,其特征在于,其编码本发明的MUC1-N蛋白。优选地,所述多核苷酸序列如SEQ ID NO.3所示。
本发明提供了一种优化的MBP蛋白,其特征在于,其核苷酸序列如SEQ ID NO.6所示。
本发明还提供了一种优化的多核苷酸,其特征在于,其编码本发明的MBP蛋白。优选地,所述多核苷酸序列如SEQ ID NO.6所示。
本发明提供了一种优化的融合蛋白,其特征在于,所述融合蛋白包括蛋白MBP和/或蛋白MUC1-N。
在一个具体实施方式中,所述融合蛋白由蛋白MBP基因和蛋白MUC1-N基因串联而成。
优选地,所述融合蛋白由麦芽糖结合蛋白MBP基因和黏蛋白MUC1-N基因串联而成。
更进一步地,所述麦芽糖结合蛋白MBP基因的核苷酸序列如SEQ ID NO.6所示,所述黏蛋白MUC1-N基因的核苷酸序列如SEQ ID NO.3所示。
根据本发明,所述融合蛋白的氨基酸序列如SEQ ID NO.7所示。
本发明还提供一种融合蛋白,其特征在于,所述融合蛋白含有本发明的MUC1-N蛋白和/或本发明的MBP蛋白。
优选地,所述融合蛋白由本发明的MUC1-N蛋白和/或本发明的MBP蛋白串联而成。
本发明还提供了一种优化的多核苷酸,其编码本发明的融合蛋白。
本发明还提供了一种优化的融合蛋白的重组表达载体或宿主细胞,其包括本发明所述融合蛋白的序列或本发明的多核苷酸序列,优选地,表达载体为原核表达载体pET26b(+)。
根据本发明,所述融合蛋白包括蛋白MBP基因和/或蛋白MUC1-N基因。
在一个具体实施方式中,所述融合蛋白由蛋白MBP基因和蛋白MUC1-N基因串联而成。
优选地,所述融合蛋白由麦芽糖结合蛋白MBP基因和黏蛋白MUC1-N基因串联而成。
更进一步地,所述麦芽糖结合蛋白MBP基因的核苷酸序列如SEQ ID NO.6所示,所述黏蛋白MUC1-N基因的核苷酸序列如SEQ ID NO.3所示。
根据本发明,所述融合蛋白的氨基酸序列如SEQ ID NO.7所示。
本发明提供一种药物组合物,其包含本发明的融合蛋白。
根据本发明,所述融合蛋白包括蛋白MBP和/或蛋白MUC1-N。
根据本发明,所述融合蛋白由蛋白MBP基因和蛋白MUC1-N基因串联而成。
优选地,所述融合蛋白由麦芽糖结合蛋白MBP基因和黏蛋白MUC1-N基因串联而成。
更进一步地,所述麦芽糖结合蛋白MBP基因的核苷酸序列如SEQ ID NO.6所示,所述黏蛋白MUC1-N基因的核苷酸序列如SEQ ID NO.3所示。
根据本发明,所述融合蛋白的氨基酸序列如SEQ ID NO.7所示。
本发明提供一种疫苗,其包含本发明的融合蛋白。
本发明还提供了融合蛋白的制备方法,包括如下步骤:
(1)扩增MBP基因,MUC1-N基因;
(2)将MBP和Muc1-N基因的基因序列进行串联,获得含有MBP-MUC1-N的融合蛋白基因,
根据本发明,所述MBP基因选自麦芽糖结合蛋白MBP基因;所述蛋白MUC1-N基因选自黏蛋白MUC1-N基因。
根据本发明,所述麦芽糖结合蛋白MBP基因的核苷酸序列如SEQ ID NO.6所示,所述MUC1-N基因的核苷酸序列如SEQ ID NO.3所示。
根据本发明,所述融合蛋白的氨基酸序列如SEQ ID NO.7所示。
更优选地,上述方法还包括将MBP-MUC1-N融合蛋白基因插入大肠杆菌表达载体。优选的,表达载体为原核表达载体pET26b(+),表达菌株为大肠杆菌BL21(DE3),亲和柱纯化。
本发明还提供了融合蛋白在制备抗肿瘤药物中的用途。优选地,所述肿瘤为MUC1阳性的肿瘤,更优选地,所述肿瘤为结直肠癌。
本发明还提供了融合蛋白在延迟肿瘤患者寿命的药物中的用途。优选地,所述肿瘤为MUC1阳性的肿瘤,更优选地,所述肿瘤为结直肠癌。
本发明还提供一种预防和/或治疗肿瘤的方法,其特征在于,使用本发明的融合蛋白或包含融合蛋白的多核苷酸。
优选地,所述肿瘤为MUC1阳性的肿瘤,更优选地,所述肿瘤为结直肠癌。
本发明还提供一种延迟肿瘤患者寿命的方法,其特征在于,使用本发明的融合蛋白或包含融合蛋白的多核苷酸。
优选地,所述肿瘤为MUC1阳性的肿瘤,更优选地,所述肿瘤为结直肠癌。
本发明还提供了蛋白MBP基因和/或蛋白MUC1-N基因在制备预防和/或治疗肿瘤药物中的用途,其特征在于,所述MUC1-N基因的核苷酸序列如SEQ ID NO.3所示,所述MBP基因如SEQ ID NO.6所示。
根据本发明,所述肿瘤包括所有表达MUC1的肿瘤,包括表达MUC1的结直肠癌。
本发明还提供了蛋白MBP基因和/或蛋白MUC1-N基因在制备预防和/或治疗结直肠药物中的用途,其特征在于,所述MUC1-N基因的核苷酸序列如SEQ ID NO.3所示,所述MBP基因的核苷酸序列如SEQ ID NO.6所示。
本发明的有益效果:
1、优化前的序列MBP-Muc1-N表达量只有总蛋白的2%,本发明优化后的序列MBP-Muc1-N表达量占总蛋白的51%,上升了25.5倍。经过亲和柱纯化后,未优化的基因表达的蛋白质进行10倍浓缩才能上样观察,浓缩后纯化蛋白质产量为100ml培养物0.8mg,而优化后的序列MBP-Muc1-N产量为9.6mg,上升了12倍。大幅度提高了表达量和产量,大大节约了生产成本。
2、本发明的融合蛋白对于结肠癌细胞生长具有显著的抑制作用,并延长了患癌小鼠的生存寿命。患癌小鼠最短存活期从30天延长到50天,即延长了患癌小鼠的60%生存寿命。同时,由具体实施方式可见,注射药物6天后就能起作用,最高抑制率达到48.7%。
附图说明
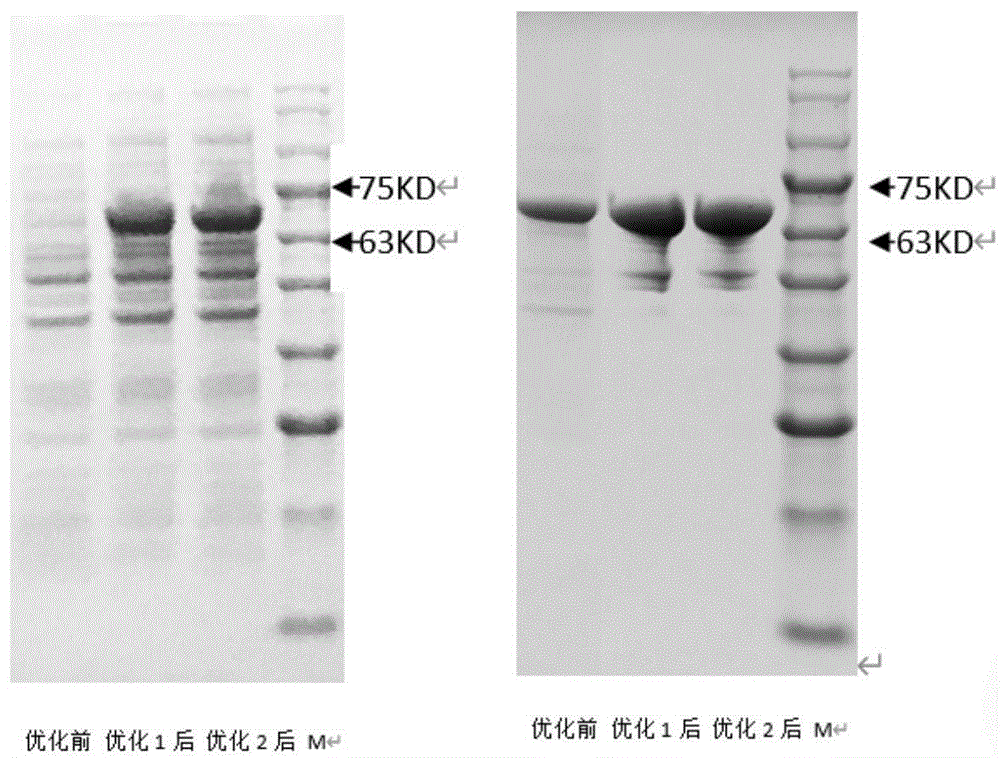
图1:蛋白质表达和纯化后的胶图;
图2:MBP-Muc1-N抑制结直肠癌细胞增殖实验结果;
图3:MBP-Muc1-N延迟结直肠癌小白鼠寿命的实验结果。
具体实施方式
实施例1:融合蛋白的构建及表达
1.基因优化
(1)MUC1-N基因的优化
本发明根据Muc1-N氨基酸序列SEQ ID NO.1的特点,进行密码子优化获得SEQ IDNO.3,经比对,优化修改了28%的碱基序列;
①SEQ ID NO.1
②优化前基因序列SEQ ID NO.2
③优化后基因序列SEQ ID NO.3
④优化1前后基因对比(同源性72%,修改28%)
(2)MBP基因的优化
根据MBP氨基酸序列SEQ ID NO.4的特点,利用DNA软件进行密码子优化,获得优化后的序列SEQ ID NO.6,经比对,优化序列有15%的碱基序列改变。
①氨基酸序列SEQ ID NO.4
②优化前基因序列SEQ ID NO.5
/>
③优化后基因序列SEQ ID NO.6
④优化1前后基因对比(同源性85%,修改15%)
(3)MUC1-N融合MBP优化基因序列的合成
MBP和Muc1-N的依次串联表达,获得融合蛋白序列为SEQ ID NO.7,其序列为:
KIEEGKLVIWINGDKGYNGLAEVGKKFEKDTGIKVTVEHPDKLEEKFPQVAATGDGPDIIFWAHDRFGGYAQSGLLAEITPDKAFQDKLYPFTWDAVRYNGKLIAYPIAVEALSLIYNKDLLPNPPKTWEEIPALDKELKAKGKSALMFNLQEPYFTWPLIAADGGYAFKYENGKYDIKDVGVDNAGAKAGLTFLVDLIKNKHMNADTDYSIAEAAFNKGETAMTINGPWAWSNIDTSKVNYGVTVLPTFKGQPSKPFVGVLSAGINAASPNKELAKEFLENYLLTDEGLEAVNKDKPLGAVALKSYEEELVKDPRIAATMENAQKGEIMPNIPQMSAFWYAVRTAVINAASGRQTVDEALKDAQTNSSSNNNNNNNNNNLGIEGRISGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAH
制备方法如下:根据MBP和Muc1-N融合蛋白质的基因序列进行串联合成。为此,先合成1a_1、1a_2、1a_3、1a_4、1a_5、1a_6、1a_7、1a_8、1a_9、1a_10、1a_11、1a_12、1a_13、1a_14、1a_15、1a_16、1a_17、1a_18、1a_19、1a_20、1a_21、1a_22、1a_23、1a_24、1a_25、1a_26、1a_27、1a_28、1a_29、1a_30寡核苷酸序列,再合成1b_1、1b_2、1b_3、1b_4序列,利用1-seq2、1-R序列进行基因扩增,获得MUC1-N融合MBP优化基因序列。
/>
实施例2.蛋白纯化、样品的制备过程
将融合基因的5’PCR引物附加NcoI酶切位点,3’PCR引物附加EcoI酶切位点,扩增出的基因双酶切,插入到同样双酶切的pET26b(+)大肠杆菌表达载体中。经过抗性细菌培养板的筛选和单克隆挑选,用卡那霉素抗性的培养基培养和IPTG诱导操纵子的表达。将未优化的序列和优化的序列MBP-Muc1-N分别进行实验。最后得到的全菌液用含有SDS的缓冲液进行95℃预处理,用5%-12%聚丙烯酰胺凝胶电泳进行分析。
结果如图1所示,优化前的序列MBP-Muc1-N表达量只有总蛋白的2%,优化后的序列MBP-Muc1-N表达量占总蛋白的51%,上升了25.5倍。经过亲和柱纯化后,未优化的基因表达的蛋白质进行10倍浓缩才能上样观察,浓缩后纯化蛋白质产量为100ml培养物0.8mg,而优化后的序列MBP-Muc1-N产量为9.6mg,上升了12倍。
实施例3.优化后的融合蛋白的活性测试
1.MBP-Muc1-N动物实验
1.材料
实验试剂:使用本发明的方法重组MBP-MUC1-N融合蛋白;MC38结肠癌细胞购自国家实验细胞资源中心;注射生理盐水购自北京天坛生物制品股份有限公司。
实验动物:C57 BL/6J小鼠购自北京华阜康生物科技有限公司。
2.方法
将MC38结肠癌细胞按照1.0×10
3.结果
表1 MBP-Muc1-N抑制肿瘤的效果
结果从图2可见,注射MBP-Muc1-N后,肿瘤显著缩小。特别是第一次注射MBP-Muc1-N后的6、12天,肿瘤极显著缩小。从图2和表1中可见,注射药物6天后起作用,最高抑制率达到48.7%。从图3可见,与注射生理盐水组对照相比,注射MBP-Muc1-N延长了MC38结肠癌小鼠的生存时间。患癌小鼠最短存活期从30天延长到50天,即延长了患癌小鼠的60%生存寿命。
4.结论
本发明通过改造后的MBP-Muc1-N动物实验,测定改造后的融合蛋白对于结肠癌细胞生长具有显著的抑制作用,注射药物6天后起作用,最高抑制率达到48.7%,并延长了患癌小鼠的60%生存寿命。
以上,对本发明的实施方式进行了说明。但是,本发明不限定于上述实施方式。凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
SEQUENCE LISTING
<110>元本(珠海横琴)生物科技有限公司
<120>一种治疗和预防癌症的融合蛋白及其医药应用
<130>2021
<160>7
<170>PatentIn version 3.5
<210>1
<211>140
<212>PRT
<213>未知
<400>1
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
1 5 1015
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
202530
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
354045
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
505560
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
65707580
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
859095
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
100 105 110
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
115 120 125
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
130 135 140
<210>2
<211>420
<212>DNA
<213>未知
<400>2
ggtgtcacct cggccccgga caccaggccg gccccgggct ccaccgcccc cccagcccac60
ggtgtcacct cggccccgga gagcaggccg gccccgggct ccaccgcccc cccagcccac 120
ggtgtcacct cggccccgga gagcaggccg gccccgggct ccaccgcgcc cgcagcccac 180
ggtgtcacct cggccccgga gagcaggccg gccccgggct ccaccgcgcc cgcagcccac 240
ggtgtcacct cggccccgga gagcaggccg gccccgggct ccaccgcccc ccgagcccac 300
ggtgtcacct cggccccgga caccaggccg gccccgggct ccaccgcccc cccagcccac 360
ggtgtcacct cggccccgga caccaggccg gccccgggct ccaccgcccc cccagcccac 420
<210>3
<211>420
<212>DNA
<213>人工合成
<400>3
ggtgttactt ctgctcctga tactcgtcct gctcctggtt ctactgcacc gccagcacat60
ggcgtgacgt ctgcgccaga tacccgtccg gcaccgggtt ccaccgcccc accggcacac 120
ggcgtaacct ccgcgccaga cacccgtcca gcgccaggtt ctaccgctcc gcctgctcat 180
ggtgttacct ctgccccgga cactcgtccg gctccaggtt ctactgcccc gccagctcat 240
ggcgtcactt ccgccccgga tacccgtcct gccccgggct ctactgcgcc tccggctcac 300
ggcgttacct ctgcaccgga tactcgtccg gctccgggct ctaccgcacc acctgctcat 360
ggcgtaacga gcgctcctga tacccgtccg gctccgggtt ccactgcacc tccggcccac 420
<210>4
<211>388
<212>PRT
<213>未知
<400>4
Lys Ile Glu Glu Gly Lys Leu Val Ile Trp Ile Asn Gly Asp Lys Gly
1 5 1015
Tyr Asn Gly Leu Ala Glu Val Gly Lys Lys Phe Glu Lys Asp Thr Gly
202530
Ile Lys Val Thr Val Glu His Pro Asp Lys Leu Glu Glu Lys Phe Pro
354045
Gln Val Ala Ala Thr Gly Asp Gly Pro Asp Ile Ile Phe Trp Ala His
505560
Asp Arg Phe Gly Gly Tyr Ala Gln Ser Gly Leu Leu Ala Glu Ile Thr
65707580
Pro Asp Lys Ala Phe Gln Asp Lys Leu Tyr Pro Phe Thr Trp Asp Ala
859095
Val Arg Tyr Asn Gly Lys Leu Ile Ala Tyr Pro Ile Ala Val Glu Ala
100 105 110
Leu Ser Leu Ile Tyr Asn Lys Asp Leu Leu Pro Asn Pro Pro Lys Thr
115 120 125
Trp Glu Glu Ile Pro Ala Leu Asp Lys Glu Leu Lys Ala Lys Gly Lys
130 135 140
Ser Ala Leu Met Phe Asn Leu Gln Glu Pro Tyr Phe Thr Trp Pro Leu
145 150 155 160
Ile Ala Ala Asp Gly Gly Tyr Ala Phe Lys Tyr Glu Asn Gly Lys Tyr
165 170 175
Asp Ile Lys Asp Val Gly Val Asp Asn Ala Gly Ala Lys Ala Gly Leu
180 185 190
Thr Phe Leu Val Asp Leu Ile Lys Asn Lys His Met Asn Ala Asp Thr
195 200 205
Asp Tyr Ser Ile Ala Glu Ala Ala Phe Asn Lys Gly Glu Thr Ala Met
210 215 220
Thr Ile Asn Gly Pro Trp Ala Trp Ser Asn Ile Asp Thr Ser Lys Val
225 230 235 240
Asn Tyr Gly Val Thr Val Leu Pro Thr Phe Lys Gly Gln Pro Ser Lys
245 250 255
Pro Phe Val Gly Val Leu Ser Ala Gly Ile Asn Ala Ala Ser Pro Asn
260 265 270
Lys Glu Leu Ala Lys Glu Phe Leu Glu Asn Tyr Leu Leu Thr Asp Glu
275 280 285
Gly Leu Glu Ala Val Asn Lys Asp Lys Pro Leu Gly Ala Val Ala Leu
290 295 300
Lys Ser Tyr Glu Glu Glu Leu Val Lys Asp Pro Arg Ile Ala Ala Thr
305 310 315 320
Met Glu Asn Ala Gln Lys Gly Glu Ile Met Pro Asn Ile Pro Gln Met
325 330 335
Ser Ala Phe Trp Tyr Ala Val Arg Thr Ala Val Ile Asn Ala Ala Ser
340 345 350
Gly Arg Gln Thr Val Asp Glu Ala Leu Lys Asp Ala Gln Thr Asn Ser
355 360 365
Ser Ser Asn Asn Asn Asn Asn Asn Asn Asn Asn Asn Leu Gly Ile Glu
370 375 380
Gly Arg Ile Ser
385
<210>5
<211>1164
<212>DNA
<213>未知
<400>5
aaaatcgaag aaggtaaact ggtaatctgg attaacggcg ataaaggcta taacggtctc60
gctgaagtcg gtaagaaatt cgagaaagat accggaatta aagtcaccgt tgagcatccg 120
gataaactgg aagagaaatt cccacaggtt gcggcaactg gcgatggccc tgacattatc 180
ttctgggcac acgaccgctt tggtggctac gctcaatctg gcctgttggc tgaaatcacc 240
ccggacaaag cgttccagga caagctgtat ccgtttacct gggatgccgt acgttacaac 300
ggcaagctga ttgcttaccc gatcgctgtt gaagcgttat cgctgattta taacaaagat 360
ctgctgccga acccgccaaa aacctgggaa gagatcccgg cgctggataa agaactgaaa 420
gcgaaaggta agagcgcgct gatgttcaac ctgcaagaac cgtacttcac ctggccgctg 480
attgctgctg acgggggtta tgcgttcaag tatgaaaacg gcaagtacga cattaaagac 540
gtgggcgtgg ataacgctgg cgcgaaagcg ggtctgacct tcctggttga cctgattaaa 600
aacaaacaca tgaatgcaga caccgattac tccatcgcag aagctgcctt taataaaggc 660
gaaacagcga tgaccatcaa cggcccgtgg gcatggtcca acatcgacac cagcaaagtg 720
aattatggtg taacggtact gccgaccttc aagggtcaac catccaaacc gttcgttggc 780
gtgctgagcg caggtattaa cgccgccagt ccgaacaaag agctggcaaa agagttcctc 840
gaaaactatc tgctgactga tgaaggtctg gaagcggtta ataaagacaa accgctgggt 900
gccgtagcgc tgaagtctta cgaggaagag ttggtgaaag atccgcgtat tgccgccact 960
atggaaaacg cccagaaagg tgaaatcatg ccgaacatcc cgcagatgtc cgctttctgg1020
tatgccgtgc gtactgcggt gatcaacgcc gccagcggtc gtcagactgt cgatgaagcc1080
ctgaaagacg cgcagactaa ttcgagctcg aacaacaaca acaataacaa taacaacaac1140
ctcgggatcg agggaaggat ttca 1164
<210>6
<211>1164
<212>DNA
<213>人工合成
<400>6
aaaatcgaag aaggcaaact ggtgatctgg atcaacggtg ataagggtta taacggtctg60
gcggaagtag gcaagaaatt cgaaaaagac accggtatca aagttaccgt tgaacatcca 120
gacaaactgg aagaaaaatt ccctcaggtg gcggctaccg gcgacggccc tgatatcatt 180
ttctgggcac atgatcgttt tggcggttac gcgcagtctg gcctgctggc agaaatcacg 240
ccggataagg cgttccagga caaactgtac ccttttacct gggacgcggt gcgttacaac 300
ggcaaactga tcgcttaccc gatcgcagtg gaagctctgt ccctgatcta caataaggac 360
ctgctgccga acccgcctaa aacgtgggaa gaaatcccgg ccctggacaa agaactgaaa 420
gcaaaaggta agagcgctct gatgttcaat ctgcaggaac cgtacttcac ttggccgctg 480
atcgcagctg acggcggtta tgcgtttaaa tacgaaaacg gtaaatatga cattaaggac 540
gtcggcgttg ataacgccgg cgccaaagcg ggcctgacct ttctggtcga cctgatcaaa 600
aacaaacaca tgaacgctga caccgattat tctattgcgg aggcggcttt taacaagggc 660
gagaccgcaa tgaccatcaa cggtccgtgg gcttggtcta acatcgacac ctccaaagta 720
aattacggtg ttaccgtcct gccgaccttc aaaggtcaac cgagcaaacc gttcgtgggc 780
gtgctgtccg caggtatcaa cgctgcctcc ccaaacaaag agctggccaa agagttcctg 840
gaaaactatc tgctgaccga cgaaggcctg gaagctgtta ataaagacaa accgctgggt 900
gctgttgcac tgaaatccta tgaagaagaa ctggtcaaag atccgcgtat tgccgccact 960
atggagaacg cgcagaaagg tgaaatcatg ccgaacatcc cgcaaatgtc cgctttttgg1020
tacgcggtgc gtaccgctgt aattaacgcg gcgtccggtc gtcagactgt cgatgaagcg1080
ctgaaagatg ctcagactaa ctctagctct aacaataaca ataataacaa caacaacaat1140
ctgggtattg aaggtcgcat ctct 1164
<210>7
<211>528
<212>PRT
<213>人工合成
<400>7
Lys Ile Glu Glu Gly Lys Leu Val Ile Trp Ile Asn Gly Asp Lys Gly
1 5 1015
Tyr Asn Gly Leu Ala Glu Val Gly Lys Lys Phe Glu Lys Asp Thr Gly
202530
Ile Lys Val Thr Val Glu His Pro Asp Lys Leu Glu Glu Lys Phe Pro
354045
Gln Val Ala Ala Thr Gly Asp Gly Pro Asp Ile Ile Phe Trp Ala His
505560
Asp Arg Phe Gly Gly Tyr Ala Gln Ser Gly Leu Leu Ala Glu Ile Thr
65707580
Pro Asp Lys Ala Phe Gln Asp Lys Leu Tyr Pro Phe Thr Trp Asp Ala
859095
Val Arg Tyr Asn Gly Lys Leu Ile Ala Tyr Pro Ile Ala Val Glu Ala
100 105 110
Leu Ser Leu Ile Tyr Asn Lys Asp Leu Leu Pro Asn Pro Pro Lys Thr
115 120 125
Trp Glu Glu Ile Pro Ala Leu Asp Lys Glu Leu Lys Ala Lys Gly Lys
130 135 140
Ser Ala Leu Met Phe Asn Leu Gln Glu Pro Tyr Phe Thr Trp Pro Leu
145 150 155 160
Ile Ala Ala Asp Gly Gly Tyr Ala Phe Lys Tyr Glu Asn Gly Lys Tyr
165 170 175
Asp Ile Lys Asp Val Gly Val Asp Asn Ala Gly Ala Lys Ala Gly Leu
180 185 190
Thr Phe Leu Val Asp Leu Ile Lys Asn Lys His Met Asn Ala Asp Thr
195 200 205
Asp Tyr Ser Ile Ala Glu Ala Ala Phe Asn Lys Gly Glu Thr Ala Met
210 215 220
Thr Ile Asn Gly Pro Trp Ala Trp Ser Asn Ile Asp Thr Ser Lys Val
225 230 235 240
Asn Tyr Gly Val Thr Val Leu Pro Thr Phe Lys Gly Gln Pro Ser Lys
245 250 255
Pro Phe Val Gly Val Leu Ser Ala Gly Ile Asn Ala Ala Ser Pro Asn
260 265 270
Lys Glu Leu Ala Lys Glu Phe Leu Glu Asn Tyr Leu Leu Thr Asp Glu
275 280 285
Gly Leu Glu Ala Val Asn Lys Asp Lys Pro Leu Gly Ala Val Ala Leu
290 295 300
Lys Ser Tyr Glu Glu Glu Leu Val Lys Asp Pro Arg Ile Ala Ala Thr
305 310 315 320
Met Glu Asn Ala Gln Lys Gly Glu Ile Met Pro Asn Ile Pro Gln Met
325 330 335
Ser Ala Phe Trp Tyr Ala Val Arg Thr Ala Val Ile Asn Ala Ala Ser
340 345 350
Gly Arg Gln Thr Val Asp Glu Ala Leu Lys Asp Ala Gln Thr Asn Ser
355 360 365
Ser Ser Asn Asn Asn Asn Asn Asn Asn Asn Asn Asn Leu Gly Ile Glu
370 375 380
Gly Arg Ile Ser Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
385 390 395 400
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
405 410 415
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
420 425 430
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
435 440 445
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
450 455 460
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
465 470 475 480
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
485 490 495
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
500 505 510
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
515 520 525
- 一种新会柑肉发酵液制作洗洁精的配方及工艺
- 一种大豆蛋白-海藻酸钠植物肉的制作工艺
- 一种多肉植物工艺美术作品的制作方法