基于神经网络与多视图一致性的三维场景重建方法和装置
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及一种计算机视觉技术领域的三维场景重建方法,具体涉及一种基于神经网络与多视图一致性的三维场景重建方法和装置。
背景技术
随着人工智能的发展,稠密三维重建在自动驾驶、虚拟现实、增强现实、医疗3D建模等领域有着广泛的应用。现有三维场景重建技术可分为基于多视图几何约束的优化方法和基于神经网络的学习方法。其中,基于多视图几何约束的优化方法通过匹配不同视角图像帧之间的特征信息,计算获取图像帧深度图并投影至三维空间融合,从而实现三维重建场景,例如文献Im S,Jeon H G,Lin S,et al.DPSNet:End-to-end Deep Plane SweepStereo[C].International Conference on Learning Representations.2018.中所述,可通过模拟传统平面扫描的方法,计算图片像素级特征之间的相似度获得匹配信息,从而预测图片深度信息,然后通过传感器获取相机位姿、相机标定计算得到相机内参,并将图片投影至三维空间融合得到三维场景重建。
基于神经网络的学习方法通过训练大型神经网络,从图像帧直接学习拟合及预测三维几何信息,例如文献Sun J,Xie Y,Chen L,et al.NeuralRecon:Real-time coherent3D reconstruction from monocular video[C].Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.2021:15598-15607.中所述,利用卷积神经网络提取图像特征,将特征投影至三维空间,并使用卷积GRU融合模块将特征融合进三维全局隐式表征(Global Hidden State)中,最终通过训练学习预测输出场景的三维场景重建表达。
以上是现有三维场景重建的代表性方法,主要缺点包括三方面。第一,基于多视图几何约束的优化方法在相机图像低纹理区域、光照剧烈变化、遮挡区域表现不佳,特征匹配容易出错,从而导致重建出的三维场景过于稀疏。第二,基于神经网络的学习方法非常依赖海量数据驱动学习鲁棒几何信息,然而现有三维场景重建数据集数量及多样性有限,该类重建方法在现实场景中缺少鲁棒性。第三,两种方法大多依赖传感器获取相机位姿,应用场景受限。
发明内容
本发明的目的是针对现有技术的不足,提供一种基于神经网络与多视图一致性的三维场景重建方法和装置,该方法利用神经网络学习鲁棒深度信息,结合多视图一致性几何约束进行优化,减少现有方法对传感器依赖的同时,提升三维场景重建方法的稠密程度与鲁棒性。
本发明第一个方面提供了一种基于神经网络与多视图一致性的三维场景重建方法,包括以下步骤:
步骤1、构建预训练的单目绝对深度估计模型;
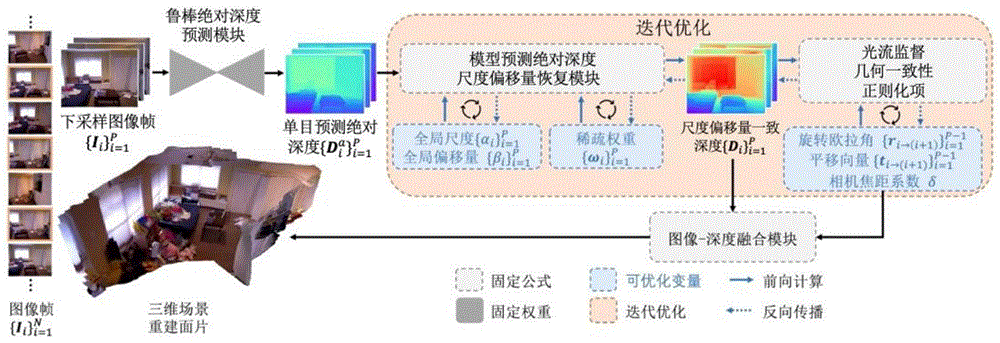
步骤2、从待处理的视频数据中提取图像帧并进行下采样,得到下采样图像帧,将下采样图像帧输入步骤1的预训练的单目绝对深度估计模型,获取单目预测绝对深度图,采用模型预测绝对深度尺度偏移量恢复模块中的可优化深度参数,对单目预测绝对深度图间不一致的尺度与偏移量进行恢复,得到尺度偏移量一致深度图,将尺度偏移量一致深度图通过可优化的相机参数,在下采样图像帧间进行投影;
步骤3、利用LoFTR算法提取每张下采样图像帧的稀疏特征,并与其他下采样图像帧进行匹配,选取局部关键帧,根据两帧下采样图像之间的相对旋转角度选取全局关键帧,基于投影结果构建监督信号L,基于监督信号L对深度参数和相机参数进行训练,优化深度参数及相机参数;
步骤4、将单目预测绝对深度图和优化后的深度参数输入模型预测绝对深度尺度偏移量恢复模块,获取尺度偏移量一致深度图,将获取的尺度偏移量一致深度图与下采样图像帧和优化后的相机参数输入图像-深度融合模块,输出三维场景重建结果。
本发明以一段视频序列作为输入,首先对输入视频序列提取图像帧,将视频格式的输入信息转化为时序上离散化后的视频图像帧,便于使用图像处理的相关知识处理视频信息。首先,本发明通过利用神经网络强大的学习能力,在千万量级海量图片-深度图数据对上进行学习训练,实现根据输入的单张图片预测每一帧图像帧的绝对深度信息;其次,网络预测的绝对深度信息仍存在帧间不一致,通过图片帧与帧之间的关联,利用多视图几何一致性约束,恢复神经网络模型逐帧预测的绝对深度图中帧间不一致的尺度信息与偏移量信息,优化相机参数和深度参数。在优化阶段针对视频中提取的图像帧进行下采样和关键帧匹配对选取,并设计合理的优化目标作为优化的监督信号。最后,将下采样图像帧及其对应的绝对深度、优化完成的深度参数和相机参数进行后处理,输出三维场景面片表达。
进一步地,步骤1中,所述的构建预训练的单目绝对深度估计模型的方法为:收集RGB-D图片-深度真值匹配对数据并分为高、中、低三种质量,采用不同的监督信号学习训练单目绝对深度估计模型,在模型训练时,设置标准相机空间,并根据拍摄图片相机的实际相机内参与标准相机空间的比例,将拍摄图片统一转换到标准相机空间进行学习,在推理时通过该变换的逆变换转换回原相机空间推理获取绝对深度。
本发明通过训练单目绝对深度估计模型,获取图像帧的基础深度信息。该步骤中收集的海量数据数量应尽可能多,多样性应尽可能广泛,且训练时需要根据数据标注质量的不同,采用不同的损失函数监督。
进一步地,步骤2中,所述的下采样策略为:首先选定第1帧图像帧为第1帧下采样图像帧,针对第i帧下采样图像帧,往时间轴增加的方向挑选图像帧,当挑选到的图像帧与第i帧下采样图像帧之间的变化程度大于1/6时,选定该帧为第i+1帧下采样图像帧,i从1开始迭代此过程,直至遍历所有图像帧。
由于单目绝对深度估计模型预测的绝对深度帧间含有不一致的尺度与偏移量,会导致重建点云或面片产生重影或形变,降低三维场景重建精度。本发明步骤2中采用模型预测绝对深度尺度偏移量恢复模块中的可优化深度参数对单目预测绝对深度图间不一致的尺度与偏移量进行恢复。
进一步地,步骤2中,所述的可优化深度参数包括全局尺度、全局偏移量和稀疏权重,基于全局尺度和全局偏移量对单目预测绝对深度图间全局尺度偏移量进行恢复,基于稀疏权重对单目预测绝对深度图间局部尺度偏移量进行恢复。
本发明采用最小二乘拟合和基于地理加权回归实现全局和局部尺度偏移量恢复,基于全局尺度、全局偏移量和稀疏权重更佳地恢复帧间一致的绝对深度信息。
进一步地,步骤2中,所述的可优化的相机参数为相机位姿和相机内参,包括每两帧图像间的相对相机位姿欧拉角、平移向量和相机焦距优化系数。
根据绝对深度信息和彩色图像帧,可将二维图像像素投影至相机坐标系的三维空间中形成带颜色的点云,投影过程中需要已知相机内参。此外,帧与帧之间仍存在着相机位姿差异,需要通过旋转矩阵与平移矩阵纠正和对齐相机的姿态变化。本发明提出相机参数优化方案,设定相机内参的焦距、以及每相邻两帧之间的相对相机位姿为可优化变量,利用帧间的一致性,自适应迭代优化得到相机参数。
进一步地,步骤3中,所述的监督信号L由各关键帧之间的光流监督L
L=λ
其中,
在步骤2中的优化参数设计完成之后,需要采用合适的优化目标,根据图像帧之间的一致性,迭代优化获取相机参数及深度参数。本发明步骤3中采用光流监督与几何一致性监督相结合的方案,既保证了图像帧间的匹配准确,又保证了帧间投影关系满足多视图几何一致性约束。本发明的关键帧选取并分为局部关键帧选取和全局关键帧选取两部分,局部关键帧利用LoFTR算法针对图像关键帧进行采样与优化,可以保证重建结果的局部一致性;全局关键帧选取策略根据每两帧之间的相对相机外参,概率性地选取重叠区域合适的两帧作为关键帧匹配对,优化整体三维场景重建结果。此外,针对深度参数尺度、偏移量优化不当导致重建点云形变过大的情况,本发明还采用另一个正则化项,对局部尺度偏移量恢复中的稀疏权重进行正则化限制,能够重建出更精确的点云。
进一步地,步骤4中,采用基于截断的带符号距离函数对获取的尺度偏移量一致深度图与下采样图像帧和优化后的相机参数进行融合处理,输出三维场景重建结果。
本发明将获取的尺度偏移量一致深度图与下采样图像帧和优化后的相机参数输入截断的带符号距离函数融合,自适应地针对帧与帧之间不一致的点云做平滑去噪处理,并输出三维场景面片表达。
本发明第二个方面提供了一种基于神经网络与多视图一致性的三维场景重建装置,包括:
模型训练模块,用于构建预训练的单目绝对深度估计模型;
下采样及模型预测绝对深度尺度偏移量恢复模块,从待处理的视频数据中提取图像帧并进行下采样,得到下采样图像帧,将下采样图像帧输入预训练的单目绝对深度估计模型获取单目预测绝对深度图,采用模型预测绝对深度尺度偏移量恢复模块中的可优化深度参数,对单目预测绝对深度图间不一致的尺度与偏移量进行恢复,得到尺度偏移量一致深度图,将尺度偏移量一致深度图通过可优化的相机参数,在下采样图像帧间进行投影;
关键帧选取及参数优化模块,用于利用LoFTR算法提取每张下采样图像帧的稀疏特征,并与其他下采样图像帧进行匹配,选取局部关键帧,根据两帧下采样图像之间的相对旋转角度选取全局关键帧,基于投影结果构建监督信号L,基于监督信号L对深度参数和相机参数进行训练,优化深度参数及相机参数;
三维场景重建后处理模块,用于将单目预测绝对深度图和优化后的深度参数输入模型预测绝对深度尺度偏移量恢复模块,获取尺度偏移量一致深度图,将获取的尺度偏移量一致深度图与下采样图像帧和优化后的相机参数输入图像-深度融合模块,输出三维场景重建结果。
本发明第三个方面提供了一种计算机设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述的基于神经网络与多视图一致性的三维场景重建方法。
本发明第四个方面提供了一种存储介质,存储有程序,所述程序被处理器执行时,实现上述的基于神经网络与多视图一致性的三维场景重建方法。
相比于现有技术,本发明具备以下有益效果:
(1)本发明利用神经网络学习鲁棒深度信息,结合多视图一致性几何约束进行优化,减少现有方法对传感器依赖的同时,提升三维场景重建方法的稠密程度与鲁棒性,解决了现有三维场景重建方法鲁棒性与稠密性难以兼得的问题。
(2)本发明对获取的视频图像帧进行下采样,获取下采样图像帧及其深度信息,采用最小二乘拟合和基于地理加权回归实现全局和局部尺度偏移量恢复,基于全局尺度、全局偏移量和稀疏权重,更佳地恢复帧间一致的绝对深度信息,解决了单目绝对深度估计模型预测的绝对深度帧间含有不一致的尺度与偏移量,会导致重建点云或面片产生重影或形变,降低三维场景重建精度的问题。
(3)本发明采用光流监督与几何一致性监督相结合的方案对深度参数和相机参数进行优化,既保证了图像帧间的匹配准确,又保证了帧间投影关系满足多视图几何一致性约束,同时优化过程中采用正则化项对局部尺度偏移量恢复中的稀疏权重进行正则化限制,能够重建出更精确的点云。
附图说明
图1是实施例中的基于神经网络与多视图一致性的三维场景重建方法的流程图。
图2是实施例中的模型预测绝对深度尺度偏移量恢复模块示意图。
图3是实施例中的三维重建结果示意图。
具体实施方式
下面结合附图对本发明的技术方案做进一步说明,本发明的基于神经网络与多视图一致性的三维场景重建方法的流程图如图1所示,包括以下步骤:
步骤1:构建预训练的单目绝对深度估计模型。
收集海量单目深度数据,训练单目绝对深度估计模型,该模型具有较高的精度和准确性。其中,训练数据分为高质量、中质量、低质量三类,高质量数据包含雷达等传感器获取的准确深度信息,中等质量包含双目匹配等方案匹配计算获取的深度信息,低质量包含光流生成的深度信息伪标签,并针对不同质量数据采用不同损失函数。高质量数据监督逐像素法向量回归、多尺度梯度损失、图像排序损失,中质量监督多尺度梯度损失、图像级别的法向量回归、深度排序损失,低质量监督仅监督深度排序损失。在模型训练时,设置标准相机空间,并根据拍摄图片相机的实际相机内参与标准相机空间的比例,将拍摄图片统一转换到标准相机空间进行学习,在推理时通过该变换的逆变换转换回原相机空间推理获取绝对深度。
步骤2、从待处理的视频数据中提取图像帧并进行下采样,得到下采样图像帧,将下采样图像帧输入步骤1的预训练的单目绝对深度估计模型,获取单目预测绝对深度图,采用模型预测绝对深度尺度偏移量恢复模块中的可优化深度参数,对单目预测绝对深度图间不一致的尺度与偏移量进行恢复,得到尺度偏移量一致深度图,将尺度偏移量一致深度图通过可优化的相机参数,在下采样图像帧间进行投影。
步骤2-1:针对输入的彩色视频数据,提取N张图像帧
步骤2-2:由于单目预测绝对深度图间不一致的尺度与偏移量会导致其投影至三维空间中的点云发生重影与形变,因此引入模型预测绝对深度尺度偏移量恢复模块,恢复多张图像帧的尺度与偏移量并在时序上对齐。模型预测绝对深度尺度偏移量恢复模块如图2所示,包含全局尺度偏移量对齐和局部尺度偏移量对齐两部分。全局对齐针对每张单目预测绝对深度图,恢复每张图像帧的像素间共享的尺度值α
其中,上式全局对齐输出得到的深度图
其中M的值为25,符号⊙表示逐像素乘法,f
采用模型预测绝对深度尺度偏移量恢复模块对单目预测绝对深度图间不一致的尺度与偏移量进行恢复后,得到尺度偏移量一致深度图。
步骤2-3:将步骤2-2得到的尺度偏移量一致深度图通过可优化的相机位姿与相机内参,在下采样后的图像帧间进行投影。其中,相机位姿初始化为每两张相邻图像帧之间的相对旋转欧拉角r
其中,P
相机位姿P
然后利用相机内参、相机位姿以及图像帧深度,在下采样后的图像帧之间投影:
d
d
其中,f
本发明中的可优化变量为全局尺度、全局偏移量、稀疏权重值、相对欧拉角、相对位姿平移量以及相机焦距系数。设定好可优化参数表达与初始化后,需要选取对应关键帧进行帧间一致性优化,该步骤涉及到优化关键帧选取以及优化监督信号选择。
步骤3:利用LoFTR算法提取每张下采样图像帧的稀疏特征,并与其他下采样图像帧进行匹配,选取局部关键帧,根据两帧下采样图像之间的相对旋转角度选取全局关键帧,基于投影结果构建监督信号L,基于监督信号L对深度参数和相机参数进行训练,优化深度参数及相机参数。
步骤3-1:关键帧的选取可分为局部关键帧选取和全局关键帧选取两个部分,分为两个阶段。在优化第一阶段,利用LoFTR算法提取每张图片稀疏特征,并与其他关键帧进行匹配。针对获取的匹配图像对,对其进行均匀采样,并根据公式(12)中设计的监督信号批量优化,直至关键帧之间的局部几何达到一致。局部关键帧的采样概率如下:
其中,p
在优化第二阶段,除了局部关键帧的选取之外,还需根据两帧之间的相对旋转角度选取全局关键帧。具体而言,计算每两帧之间的旋转角度,关键帧采样概率的大小随着旋转角度的增大逐渐增大后逐渐减小,并在旋转角度为φ处达到最大值。在第二阶段,全局采样概率和局部采样概率分别占总采样概率的1/2,如下式所示:
其中,θ
步骤3-2:在优化过程中,对于步骤3-1中选定的关键帧第i帧和第j帧,将第i帧投影至第j帧,监督信号L由各关键帧之间的光流监督L
L=λ
其中,每一次迭代最小化的可优化参数包括:从第i帧到第j帧每两帧相机位姿之间的相对旋转欧拉角
整体优化迭代次数为6000次,每次优化采样50个关键帧匹配对。其中第一阶段2000次迭代,监督信号损失超参数λ
步骤4:将单目预测绝对深度图和优化后的深度参数输入模型预测绝对深度尺度偏移量恢复模块,获取尺度偏移量一致深度图,将获取的尺度偏移量一致深度图与下采样图像帧和优化后的相机参数输入基于截断的带符号距离函数融合后处理(TSDF-Fusion),输出精确且鲁棒的三维场景重建结果(如图3所示)。
本实施例还提供了一种基于神经网络与多视图一致性的三维场景重建装置,包括:
模型训练模块,用于构建预训练的单目绝对深度估计模型;
下采样及模型预测绝对深度尺度偏移量恢复模块,从待处理的视频数据中提取图像帧并进行下采样,得到下采样图像帧,将下采样图像帧输入预训练的单目绝对深度估计模型获取单目预测绝对深度图,采用模型预测绝对深度尺度偏移量恢复模块中的可优化深度参数,对单目预测绝对深度图间不一致的尺度与偏移量进行恢复,得到尺度偏移量一致深度图,将尺度偏移量一致深度图通过可优化的相机参数,在下采样图像帧间进行投影;
关键帧选取及参数优化模块,用于利用LoFTR算法提取每张下采样图像帧的稀疏特征,并与其他下采样图像帧进行匹配,选取局部关键帧,根据两帧下采样图像之间的相对旋转角度选取全局关键帧,基于投影结果构建监督信号L,基于监督信号L对深度参数和相机参数进行训练,优化深度参数及相机参数;
三维场景重建后处理模块,用于将单目预测绝对深度图和优化后的深度参数输入模型预测绝对深度尺度偏移量恢复模块,获取尺度偏移量一致深度图,将获取的尺度偏移量一致深度图与下采样图像帧和优化后的相机参数输入图像-深度融合模块,输出三维场景重建结果。
本实施例还提供了一种计算机设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述的基于神经网络与多视图一致性的三维场景重建方法。
本实施例还提供了一种存储介质,存储有程序,所述程序被处理器执行时,实现上述的基于神经网络与多视图一致性的三维场景重建方法。
- 一种用于好氧颗粒污泥系统的压力流污水均布处理装置及其使用方法
- 一种污泥处理系统及一种真空污泥干燥装置
- 一种污泥高干脱水装置及其使用方法
- 一种河道污泥中浮动层的沉淀清除装置及其量度方法
- 一种基于污泥旁侧预处理的污泥减量化的装置与方法
- 一种市政管理用河道污泥处理装置及使用方法
- 一种清理河道污泥的吸污装置及其河道污泥吸污处理方法