一种基于自适应感知的跨场景自动驾驶决策方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明涉及自动驾驶技术领域,尤其涉及一种基于自适应感知的跨场景自动驾驶决策方法。
背景技术
随着自动驾驶技术的快速发展,绝大多数自动驾驶技术均由模块化的感知-决策框架作为自动驾驶车辆的眼睛和大脑。此类感知和决策的设计方式旨在帮助自动驾驶车辆理解周围的动态环境并做出相应的转向/速度变化决策。感知和决策模块这两个组件均可以基于经典的规则方法或深度学习方法来进行开发,它们尝试取代人类驾驶员的观察和决策来防止危险驾驶行为(例如,急刹车和突然变道)的发生。尽管它们在特定的试验场景中实现了安全、高效、舒适的自动驾驶,但它们在面对变化较大的测试场景或者完全陌生场景时并不具备理解新场景的能力,由此导致决策系统失效。这也是为什么我们还没有看到此类技术部署在自动驾驶汽车上的原因之一。由此可见如何设计一个跨场景使用的自动驾驶感知决策框架是一个非常具有挑战性的难题。
随着计算机视觉领域技术的飞速发展,自动驾驶车辆的感知模块可以通过使用硬件和算法的组合来感知和解释周围环境。例如可以通过摄像头以及激光雷达感知周围环境的相关信息,并通过算法将多模态感知结果融合到鸟瞰图(BEV)图像中,之后使用卷积神经网络提取相关特征并获得其低维表示。尽管类似的感知方式可以很好的保留道路结构和周围车辆的状态,但理解自动驾驶车辆视野内的复杂多变的场景仍然是一项具有挑战性的任务。另外决策阶段通常利用从感知阶段收集的信息,通过规则匹配算法或者基于强化学习的方法来做出相应的决策。但例如自适应巡航控制等基于规则的算法严重依赖规则匹配算法,很难在复杂的交通系统中做出合理的决策。以及基于强化学习的方法虽然可以在固定的场景中做出合适的决策,但其训练经验无法覆盖所有可能的交通状况,导致遇到不熟悉的场景时车辆会做出错误的决策。
总的来说,现有方法既不能适应复杂场景,也不能扩展到未见过的场景,这阻碍了自动驾驶的发展。开发能够适应不同场景的感知和决策框架一直是自动驾驶领域一个悬而未决的问题。其中一种简单的解决方案是收集尽可能多的试验场景来训练常规的感知和决策模块。然而这种方法不仅需要探索大量的极端情况,而且会消耗较长的训练时间。因此在资源和训练场景有限的情况下,优先发展自动驾驶车辆在道路布局简单的基础场景中的决策能力,然后再扩展到更复杂的场景是一种较为合理的解决方案。但此方案面临着诸多的困难,例如:(1)如何通过感知模块理解复杂多变的交通场景,同时将这些变化的场景映射到基本且可解释的空间比较困难。(2)基于强化学习的决策方式可以很好地适应动态的基本场景,但难以确保基本场景的决策结果在复杂场景中仍然有效。
发明内容
本发明的目的是要提供一种基于自适应感知的跨场景自动驾驶决策方法。
为达到上述目的,本发明是按照以下技术方案实施的:
本发明包括以下步骤:
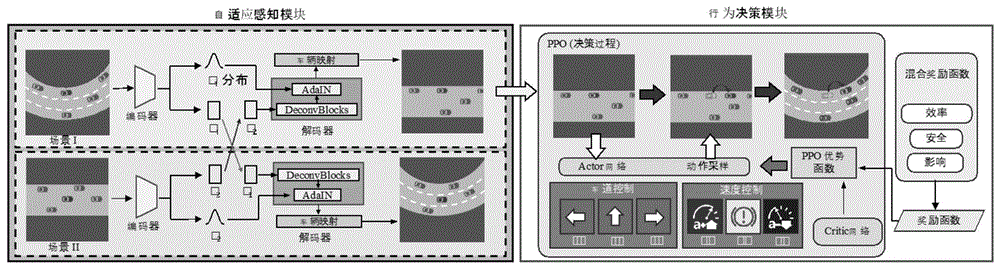
S1:自适应感知模块获取复杂场景下捕获的鸟瞰图并将它们分别编码为场景几何拓扑特征和场景位置分布特征;
S2:通过基于变分自编码器的自适应感知模块将复杂场景中的几何特征替换为基本场景的几何特征,并将其组合解码以生成新的BEV图像;
S3:将自适应感知模块的生成结果作为行为决策模块的输入,行为决策模块由深度强化学习模型和混合奖励函数组成,所述行为决策模块基于感知模块所提供的信息执行优秀的变道和变速决策。
本发明的有益效果是:
本发明是一种基于自适应感知的跨场景自动驾驶决策方法,与现有技术相比,本发明能够有效地将复杂环境信息转化为基础场景,并在这些基础场景上做出决策。这种独特的方法模仿了人类驾驶员的学习方式,首先从简单环境入手,并利用类比策略来处理更加复杂的驾驶挑战。在感知环节中,利用鸟瞰图(BEV)图像对复杂场景的信息进行捕捉和编码,进一步转化为几何和分布特征。这些特征经过处理和解码后,会被转化为针对基础场景的新的BEV图像,从而让自动驾驶系统快速并准确地理解其所处的动态环境。在决策阶段,结合深度强化学习模型和混合奖励机制,系统能够做出换道和速度调整的策略,旨在优化基本场景中的驾驶安全和效率。这种策略确保了在不同场景,尤其是复杂场景中,决策的适用性和准确性。相较于传统的自动驾驶技术,本发明在复杂交通环境中显示出显著优势。传统基于规则的方法在未知或异常交通状况下难以做出正确的决策,而深度学习和强化学习尽管在决策训练场景中效果显著,但在未知的交通场景下仍可能产生误判。然而,本发明能够在面对不熟悉的场景时利用已有的训练经验以及转换后的感知图像,降低了对大量数据和长时间训练的依赖。而本发明通过模拟人类的学习和驾驶过程,使得在不熟悉的场景中,自动驾驶系统能够利用已有的训练知识进行准确决策,从而避免了对大量训练数据和长时间训练的依赖。通过这种自适应的感知机制,本发明还能够处理并转化不同复杂度的鸟瞰图像,为决策模块提供更加易于理解的输入。因此与其他方法相比,本发明提供了一种更为高效且适应性强的自动驾驶解决方案。
附图说明
图1为本发明自适应感知的行为决策框架的总体架构图;
图2为本发明自适应感知的模块EVA-AIN的网络结构图;
图3为本发明行为决策的模块的网络结构图。
具体实施方式
下面结合附图以及具体实施例对本发明作进一步描述,在此发明的示意性实施例以及说明用来解释本发明,但并不作为对本发明的限定。
如图1-3所示:首先自适应感知模块获取复杂场景下捕获的鸟瞰图并分别编码为场景几何拓扑特征和场景位置分布特征。之后通过基于变分自编码器的自适应感知模块将复杂场景中的几何特征替换为基本场景的几何特征,并将其组合解码以生成新的BEV图像。其中生成的BEV图像同时具备复杂场景中关键驾驶信息的感知内容以及便于理解的基础场景风格。由此将复杂多变的场景映射到基本且可解释的空间,以提升自动驾驶车辆在面对未知陌生环境下做出安全决策的能力。同时将自适应感知模块的生成结果做为行为决策模块的输入。行为决策模块由深度强化学习模型和混合奖励函数组成。它的目的是基于感知模块所提供的信息执行优秀的变道和变速决策。
在自适应感知模块EVA-AIN的训练阶段,将在相似场景中所提取的两个BEV图像分别编码为场景几何和场景分布特征。之后通过交换两者间的场景几何特征并分别解码为新的BEV图像,并计算转换前后的BEV图像之间的损失函数,由此提高EVA-AIN对感知信息的解纠缠能力,例如EVA-AIN所编码的场景几何特征中并不会包含场景分布的相关信息。在自适应感知模块具备对特征良好的解纠缠能力后,EVA-AIN可以通过编码代表复杂场景中几何拓扑结构和道路位置分布特征的两个独立空间。之后将几何拓扑结构特征替换为基础场景的对应特征并解码,由此将复杂多变的场景映射到基本且易于理解的空间。其中编码器由一个预训练的ResNet18以及两个全连接层组成,表示为Enc(x)=(f
DecBlock(x)=LeakyReLU(AdaIN[G
其中通过四个卷积块将编码器的输出由128通道解码至1通道的BEV图像,其中几何结构的特征G
损失函数L
利用自适应感知模块,可以将真实场景的BEV图像转化为基本场景的风格,之后基于强化学习的行为决策模块只需要在基本场景上进行训练即可适应真实场景。因此,目标是使用具有混合奖励的基于深度强化学习的模型完成单场景MDP的问题,重点学习基本场景下的最优决策。其中,使用具有Actor-Critic结构的PPO算法,其中Actor网络负责在给定当前环境状态的情况下选择最佳操作,而Critic网络代表状态价值函数,与环境所反馈的奖励相结合,用于计算PPO优势函数以指导策略的更新。其中行为决策模块的特征提取器由三个卷积层组成,它们将t时刻的输入图像转换为一个64通道的特征图M
其中φ
Critic网络与Actor网络计算状态值函数的输入相同,任务是预测在给定状态下的可获得的奖励,计算过程如下:
其中φ
接下来将详细描述行为决策模块的奖励函数部分,该部分用于评估自动驾驶车辆行为的优劣,主要分为3个部分:安全驾驶能力、驾驶效率、对周围环境的干扰。对于安全驾驶能力的测量,使用自动驾驶车的TTC指标进行评估,其计算公式如下:
在此奖励函数中,碰撞指的是车辆碰撞或违反道路边界。通常自动驾驶汽车当TTC
对于驾驶效率的奖励值,使用自动驾驶车辆的车道方向速度直接衡量其行驶效率,定义如下
其中,A
对周围环境的干扰的评估奖励,使用自动驾驶车的后车受干扰情况来进行评估:
其中v
如图3所示:自适应感知模块EVA-AIN的转换能力进行了评估,即将车辆在50x50米范围内捕捉的BEV图像从真实场景映射到基本且可解释的空间。在场景转换过程中,本发明在高速公路和环线公路场景利用车辆在模拟器中所收集的观察结果完成了自适应感知模块的训练。预训练的自适应感知模块能够支持自动驾驶汽车在所训练场景下的灵活映射,由此帮助在基本场景下进行决策学习的自动驾驶车辆可以有效的理解其他经过变化的场景。例如,当基于强化学习的决策模块自动驾驶汽车在场景A(高速公路)中进行训练,它可以使用自适应感知模块将所遇到的场景B(环状公路)中的驾驶信息转化为可解释的场景A的风格,从生成的结果可以明显看出自动驾驶车辆所处车道位置和周围车辆的相对位置在场景转换前后保持不变,确保基于转换后的场景的决策仍然有效。同时我们对生成结果进行了过滤,当像素值范围为0-1时,将小于0.3的像素修正为0,将大于0.3的像素修正为1,以保证生成结果的质量。
本发明在交通模拟器的高速公路以及环形公路两个场景中,与不具备自适应感知模块的自动驾驶训练方案进行对比,其中两种对比方法的决策模块均在高速公路场景中进行强化学习训练。其中带有自适应感知模块EVAIN的方案在与周围车辆的撞击率NCC、驶出车道率NCL、平均到达时间AvgT、最小碰撞时间M-TTC、平均速度AvgVel以及后车的平均速度变化DecC等指标上均表现良好。并且在高速公路场景下训练的决策模型配合自适应感知模块可以很好的适应场景的变化,在环形公路也可以适用。而不具备自适应感知模块的强化学习决策模型则无法在环形公路做出正确的决策。
本发明具有显著的优势。传统的自动驾驶方法,如基于规则匹配的算法,往往在复杂的交通系统中难以做出决策。例如,自适应巡航控制和基于规则的变道模型都重度依赖于预设规则,当面临不熟悉或异常的交通情况时,其决策往往受限。而深度学习和强化学习方法虽然在某些场景中表现出色,但由于训练经验无法覆盖所有可能的交通情况,它们在未知场景下通常会做出错误的决策。本发明摒弃了对海量数据的依赖和长时间的训练过程,模拟人类学习和驾驶的方法,让自动驾驶系统在面对不熟悉的场景时,能够使用已学到的基础知识和技能进行决策。此外自适应感知模块能够有效处理并简化复杂的鸟瞰图像,使其转换为拥有简单路网的基本场景,从而进一步优化决策的效率和准确性。总之,本发明提供了一种经济、高效且具有强大适应性的自动驾驶决策框架。
本发明的技术方案不限于上述具体实施例的限制,凡是根据本发明的技术方案做出的技术变形,均落入本发明的保护范围之内。
- 一种焊接图像采集方法、装置、电子设备和存储介质
- 一种焊接仿真系统、焊接仿真方法、电子设备及介质
- 焊接拉力的仿真方法、仿真装置、电子设备及存储介质