一种基于互注意力融合和蒸馏机制的场景识别方法和系统
文献发布时间:2024-04-18 20:01:30
技术领域
本发明属于图像处理技术领域,尤其涉及一种基于互注意力融合和蒸馏机制的场景识别方法和系统。
背景技术
场景识别作为计算机视觉领域的一个分支,在现实生活中有着重要的作用。在AI领域,场景识别则是其先行任务,AI首先要对当前场景做出判断才能进一步执行后续动作。场景识别属于分类任务,但由于场景图像的复杂性又使其不同于一般的分类任务。在判断一幅场景所属类别时,不但需要识别场景内的多个物体,也需要获取场景中物体的空间布局。而且对于一类场景而言,有的场景变化差异性较大,且容易受到遮挡、光照等因素的干扰。这些因素也使得仅依靠RGB图像这种单一模态场景数据识别出来的场景结果较差。
然而随着深度传感器的普及可以更为容易的得到场景的深度数据,科研人员发现RGB数据与深度数据有着较强的互补性,利用这两种互补性数据进行训练有着天然的优势,通过RGB数据提取场景的轮廓、色彩等特征,通过深度数据提取场景的空间位置等特征,并设计网络对这些特征进行融合用于场景识别相较于使用单模态场景数据而言有着更好的效果。现有的基于深度神经网络的多模态场景识别方法主要依赖卷积操作实现,但是由于卷积核的感受野有限,对于全局特征提取能力有限,且很难发掘到不同局部特征之间的联系,所以提取场景的空间位置能力依然存在不足,也使得场景识别准确率无法进一步提升。
在近些年,最开始应用于自然语言处理领域的注意力机制由于其在特征提取方面的优势被广泛应用于图像处理领域,使用注意力机制不仅可以提取到场景的全局特征,由于该机制的特殊性,也可以使场景中不同的局部图像块之间进行信息交互。将这一机制应用于多模态场景识别,对于场景图像的特征提取以及互补性场景数据的融合都有着重要的作用。
发明内容
本发明的主要目的是,提供一种基于互注意力融合和蒸馏机制的场景识别方法和系统,适用于多模态场景,该系统和方法提高了多模态场景识别的准确率。此外,所设计的互注意力机制用于互补性数据的融合相比其他机制也有着更好的融合效果。
本发明提供了一种基于互注意力融合和蒸馏机制的场景识别方法,适用于多模态场景,具体包括以下步骤:
步骤1、使用卷积神经网络对多模态场景数据集进行训练,得到在当前多模态场景数据集上的预训练权重,其中,所述多模态场景数据集包括RGB图像和HHA图像;
步骤2、对多模态场景数据集做预处理,包括:将RGB图像和HHA图像进行序列化并添加位置编码,以得到RGB数据、HHA数据以及早期融合数据;
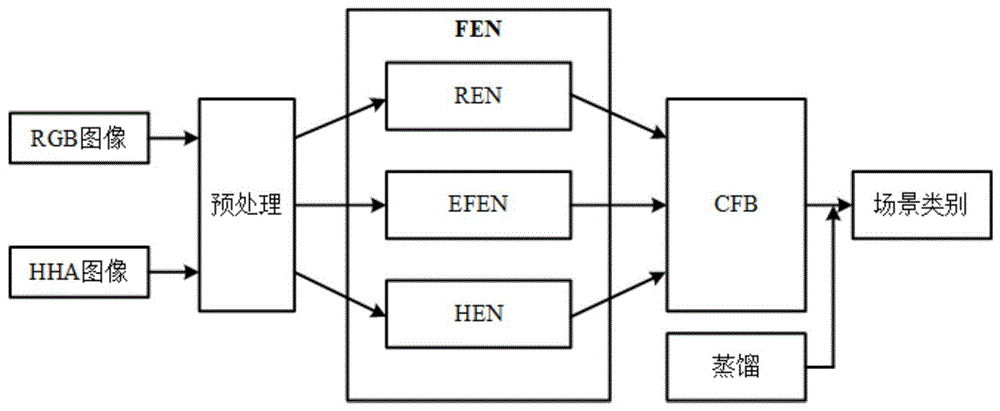
步骤3、构建端到端可训练的神经网络模型SAD,所述神经网络模型SAD基于自注意力机制,并包括场景特征提取网络FEN、互补性特征融合模块CFB以及蒸馏模块;
步骤4、将未序列化的多模态场景数据集输入蒸馏模块,将步骤2中得到的RGB数据、HHA数据以及早期融合数据输入FEN,之后再输入CFB模块以预测出具体的场景类别,并使用蒸馏模块指导整个网络的训练,其中,步骤1中得到的预训练权重即为所述蒸馏模块中的训练权重,所述蒸馏模块以所述训练权重指导整个网络的训练;
步骤5、识别多模态场景图像的场景类别,包括:对需要识别的多模态场景图像进行序列化并添加位置编码,以得到相对应的序列化数据,将所述序列化数据输入FEN,以提取多模态场景的特征,再将提取出的多模态场景的特征输入CFB模块,以得到所述场景图像的场景类别。
作为本发明的进一步改进,在步骤1中,使用异构的卷积神经网络对多模态场景数据集进行训练,以得到在当前多模态场景数据集上的预训练权重,并将所述预训练权重作为步骤4中所述蒸馏模块所包括的教师模型的训练权重,所述教师模型以所述训练权重来指导所述SAD进行训练。
作为本发明的进一步改进,在步骤2中,使用卷积操作分别对RGB图像和HHA图像进行序列化,以得到相对应的RGB序列和HHA序列,在保留所述RGB序列和所述HHA序列的情况下,将所述RGB序列和所述HHA序列拼接以得到早期融合序列,在所述RGB序列、HHA序列和早期融合序列上拼接初始化的分类序列,并添加位置编码以表明所述RGB序列、HHA序列和早期融合序列的位置信息。
作为本发明的进一步改进,FEN是基于全局自注意力机制的网络,具体包括:
RGB特征提取网络REN:用于提取RGB支路的色彩纹理等RGB图像中的场景特征;
HHA特征提取网络HEN:用于提取HHA支路的空间布局等HHA图像中的场景特征;以及
早期融合特征提取网络EFEN:用于同时提取RGB和HHA图像中的公有特征。
作为本发明的进一步改进,CFB是基于互注意力机制的模块,包括:HHA支路对RGB支路的融合模块,RGB支路对HHA支路的融合模块,以及用于RGB支路、HHA支路以及早期融合支路上的相加融合模块,其中,CFB由2个并行的互注意力层、2个残差结构、三个归一化层和一个全连接层堆叠而成。
作为本发明的进一步改进,将原始的场景图像输入教师模型,输出教师模型预测结果;使用交叉熵损失函数分别计算SAD预测结果与教师模型预测结果和真实场景的损失,并按照不同占比使其构成最终的损失函数结果。
作为本发明的进一步改进,在步骤5中,将需要识别的多模态场景图像的序列化数据输入到SAD网络模型,分别得到将所述多模态场景图像预测为不同场景类别的概率值,如果最大概率对应的场景类别与真实类型相同,则说明预测正确;最终得到所述多模态场景数据集的分类准确率,所述分类准确率为正确预测数量与总预测数量之比。
本发明还提供了一种基于互注意力融合和蒸馏机制的场景识别系统,适用于多模态场景,用于执行前述的方法。
本发明的有益效果是:本发明的基于互注意力融合和蒸馏机制的场景识别方法和系统,通过应用全局自注意力机制有效的学习了每类输入中各部分之间的关系,在提取了每类序列场景序列局部特征的前提下,利用自注意力机制的特性使序列中不同部分之间进行交互,从而提取到其全局特征;在早期融合序列中利用自注意力机制提取到场景不同模态之间的部分公共特征,CFB基于互注意力机制,分别可以提取到HHA数据对RGB数据的互补性特征和RGB数据对HHA数据的互补性特征,在经过归一化层之后使三路数据进行相加后通过全连接层和softmax层可以有效的融合三路数据特征。蒸馏机制则引入了基于卷积的教师模型,为SAD赋予学习归纳偏置的能力,提高了模型的特征提取能力与训练效率;总体而言,本发明提出的SAD提高了非实验室环境下场景识别的准备率,在SUN RGB-D和NYUD2两个多模态场景数据集上分别取得了top1和top2的准确率,有效的改善了多模态场景识别的现状。
附图说明
图1是本发明的整体流程图;
图2是本发明中蒸馏模块的流程图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
需要强调的是,在描述本发明过程中,各种公式和约束条件分别使用前后一致的标号进行区分,但也不排除使用不同的标号标志相同的公式和/或约束条件,这样设置的目的是为了更清楚的说明本发明特征所在。
如图1与图2所示,本发明提供了一种基于互注意力融合和蒸馏机制的场景识别方法,主要包括以下步骤:
步骤1:使用卷积神经网络对多模态场景数据集进行训练,得到在当前多模态场景数据集上的预训练权重,其中,所述多模态场景数据集包括RGB图像和HHA图像;
步骤2:将RGB图像和HHA图像进行序列化并添加位置编码,以得到RGB数据、HHA数据以及早期融合数据;
步骤3:构建端到端可训练的神经网络模型SAD,所述神经网络模型SAD基于自注意力机制,并包括场景特征提取网络FEN、互补性特征融合模块CFB以及蒸馏模块;
步骤4:将未序列化的多模态场景数据集输入蒸馏模块,将步骤2中得到的RGB数据、HHA数据以及早期融合数据输入FEN,之后再输入CFB模块以预测出具体的场景类别,并使用蒸馏模块指导整个网络的训练,其中,步骤1中得到的预训练权重即为所述蒸馏模块中的训练权重,所述蒸馏模块以所述训练权重指导整个网络的训练;
步骤5:识别多模态场景图像的场景类别,包括:对需要识别的多模态场景图像进行序列化并添加位置编码,以得到相对应的序列化数据,将所述序列化数据输入FEN,以提取多模态场景的特征,再将提取出的多模态场景的特征输入CFB模块,以得到所述场景图像的场景类别。
以上结合附图对本发明的方法进行详细介绍。
步骤1:使用卷积神经网络对多模态场景数据集进行训练,得到在当前多模态场景数据集上的预训练权重,其中,所述多模态场景数据集包括RGB图像和HHA图像。
在步骤1中,将多模态场景数据集中RGB图像和HHA图像分别通过卷积神经网络,在网络的最后一层将两个卷积神经网络分别提取到的RGB特征和HHA特征进行相加用于训练卷积神经网络在当前多模态场景数据集上的预训练权重。
步骤2:对多模态场景数据集做预处理,包括:将RGB图像和HHA图像进行序列化并添加位置编码,以得到RGB数据、HHA数据以及早期融合数据。
在步骤2中,经过处理后的RGB序列、HHA序列以及早期融合序列作为特征提取网络FEN的三路输入。SAD分别输入224×224的RGB图像和HHA图像,再分别使用卷积核大小为16×16,步距为16,卷积核个数为768的卷积操作和展开长宽维度的操作使RGB图像和HHA图像成为大小为196×768的序列。为了进行早期融合,再另外将序列化后的RGB序列和HHA序列进行拼接形成早期融合序列。为了便于特征提取,在RGB序列、HHA序列和早期融合序列上再拼接上等维度的分类序列。此外,为了让网络学习到输入中的位置信息,需要添加大小为197×768位置编码,最终得到三路输入R,H∈197×768,RH∈397×768。
步骤3:构建端到端可训练的神经网络模型SAD,所述神经网络模型SAD基于自注意力机制,并包括场景特征提取网络FEN、互补性特征融合模块CFB以及蒸馏模块。
SAD中特征提取网络FEN包括三个基于全局自注意力机制的子网络,这些子网络均由12个全局自注意力层实现。其中,REN用于提取RGB序列的场景特征,HEN用于提取HHA序列的场景特征,EFEN用来提取RGB序列和HHA序列的部分公共特征。
SAD中的CFB是基于互注意力机制的模块,该模块包括HHA支路对RGB支路的融合模块,RGB支路对HHA支路的融合模块,并包括最后一部分的相加融合模块用于RGB支路、HHA支路以及早期融合支路上特征的融合,其中CFB由2个并行的互注意力层、2个残差结构、三个归一化层和一个全连接层堆叠而成。在经过步骤2得到的三种序列经过FEN后,RGB支路上使用互注意力层做HHA支路对RGB支路的融合、HHA支路上使用互注意力层做RGB支路对HHA支路的融合,然后两个支路再分别与未经过互注意力层的数据进行残差。最后使三个支路分别经过归一化层后进行相加并通过全连接层。
蒸馏模块可以在样本数量有限的情况下更有效的训练模型,该蒸馏模块的教师模型使用了基于卷积的深度神经网络。将原始的场景图像输入教师模型,输出教师模型预测结果;使用交叉熵损失函数分别计算SAD预测结果与教师模型预测结果和真实场景的损失,并按照不同占比使其构成最终的损失函数结果。
步骤4:将未序列化的多模态场景数据集输入蒸馏模块,将步骤2中得到的RGB数据、HHA数据以及早期融合数据输入FEN,之后再输入CFB模块以预测出具体的场景类别,并使用蒸馏模块指导整个网络的训练,其中,步骤1中得到的预训练权重即为所述蒸馏模块中的训练权重,所述蒸馏模块以所述训练权重指导整个网络的训练。
在步骤4中,使用卷积神经网络作为蒸馏模块教师模型进行训练,将其得到的损失与由SAD训练得到的损失按照3:7的比例来构成总的损失用于指导整个模型的训练。整个训练过程采用了Lamb优化算法,设定训练样本的批处理尺寸为12,学习周期为200次迭代,初始化学习率为0.001,期间使用cosine函数以0.05的衰减率进行衰减。其中,预训练权重作为蒸馏模块中的教师模型的训练权重,教师模型以训练权重来指导所述SAD进行训练。
步骤5:识别多模态场景图像的场景类别,包括:对需要识别的多模态场景图像进行序列化并添加位置编码,以得到相对应的序列化数据,将所述序列化数据输入FEN,以提取多模态场景的特征,再将提取出的多模态场景的特征输入CFB模块,以得到所述场景图像的场景类别。
在经过步骤2得到RGB序列、HHA序列和早期融合序列后,输入到SAD网络模型中最终得到该图像预测为每一类场景的概率值,如果最大概率对应的场景类别与真实类型相同,则说明预测正确;最终得到该多模态场景数据集的分类准确率,即正确预测数量与总预测数量之比。
本发明还提供了一种基于互注意力融合和蒸馏机制的场景识别系统,适用于多模态场景,用于执行前述的场景识别方法。
本发明的一种基于互注意力融合和蒸馏机制的场景识别方法及系统,为了更好的提取场景的全局特征以及多模态场景的互补性特征,使用了自注意力机制,并设计了互注意力融合机制,同时引入蒸馏机制指导模型训练,进一步提高了模型的识别准确率与训练效率。
以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
- 一种Cu-NiPO纳米纤维材料及其制备方法与应用
- 一种高强度、高弹性模量、优良延展性的碳纳米管纤维材料及制备方法
- 一种浮雕纳米涂料制备工艺及喷涂由该工艺制备的涂料的浮雕面板及制作工艺
- 一种再生料制备纳米纤维材料的工艺
- 一种纳米纤维材料及其制备工艺