一种双端聚类联邦学习方法
文献发布时间:2024-04-18 20:02:18
技术领域
本发明涉及联邦学习技术领域,具体是一种双端聚类联邦学习方法。
背景技术
联邦学习(FL)是一种分布式的机器学习方法,其主要目的是允许多个参与方(例如移动设备、传感器、客户端)在本地维护其数据,并仅共享模型的参数更新,而不共享原始数据。与一般的分布式机器学习框架不同,联邦学习更加强调隐私保护的重要性。在联邦学习中,原始数据严格保持在本地设备上,仅有经过加密的模型参数的微小更新会在设备之间进行共享,从而提供了更高级别的隐私保护。在广泛使用的联邦学习算法FedAvg中,多个被称为客户端的用户无需将本地设备的数据传输至中央服务器,而是通过协同训练一个共享的神经网络模型来实现模型更新。这一算法代表了一种通用的联邦学习方法,吸引了一些学者进一步展开研究,以不断完善和扩展联邦学习的应用领域。
联邦学习以其隐私保护、数据传输减少以及分布式数据场景适用等特点,为应对数据共享和隐私问题提供了有力的解决方案。此外,联邦学习已广泛应用于多个领域,如下一个单词预测和电子健康记录学习等。然而,尽管联邦学习带来了众多优势,仍然伴随着多项挑战。其中一个主要挑战是统计异质性,即参与联邦学习的设备之间的数据分布可能存在显著差异。一些设备可能具备大量数据,而其他设备则仅有有限数据,这可能导致数据量较少的设备在全局模型训练中贡献不足,从而对整体性能产生影响。
为了应对这一挑战,近期的研究工作不再着眼于全局模型的优化,而是提出了新方法,建议每个用户训练适应其本地数据的个性化模型,以克服数据的异质性。聚类联邦学习也受到广泛关注,其核心思想是将设备划分成不同的集群,每个集群内的设备具有相似的数据分布,然后在集群级别进行模型训练,以降低不均匀性的影响。基于CFL框架,许多研究人员进一步研究了如何更好地适应非独立同分布的环境,并证实了CFL在异构环境中比通用FL的全局模型更准确。需要指出的是,客户端分组可以在服务器端完成,也可以在客户端完成。然而,需要注意的是,服务器端聚类通常采用聚类算法,如层次聚类,根据更新梯度进行划分,这种划分通常是不可逆的,可能会影响模型的收敛速度。与此相反,客户端聚类通常依赖经验损失函数来判断客户端所属的簇,但这往往需要较长的时间。
发明内容
为了克服现有技术中存在的不足,本发明提供一种解决了一次性聚类中客户端分类错误的问题,实现了小规模客户端身份的动态调整,提高了聚类的容错性和训练收敛速度的双端聚类联邦学习方法。
技术方案:为实现上述目的,本发明采用的技术方案为:
S1、服务器初始化一个全局模型的参数;
S2、随机挑选部分客户端参与,服务器发送全局模型给参与客户端,客户端利用模型和本地数据进行训练,并发送更新梯度给服务器进行聚合平均,重复执行r轮;
S3、服务器初始化客户端的警惕值,根据参与客户端的更新梯度,构建相似性矩阵,通过矩阵执行聚类算法将参与客户端分组;
S4、服务器按照聚类结果将全局模型扩展成k个簇,每个簇内进行聚合平均更新,并将更新后的模型全部发送给未参与客户端,未参与客户端交替计算经验损失,比较模型性能,以确认自身身份,并将身份发送给服务器。
S5、客户端根据簇模型进行本地训练,并上传更新梯度。
S6、服务器在各个簇内构建相似性矩阵,选取相似性较差的客户端增加警惕值,剩余客户端减小警惕值,当警惕值达到阈值时,认为客户端的身份需要重新识别,进入S7,否则进入S8。
S7、客户端根据全部簇模型交替计算经验损失,获取新的身份发送给服务器。
S8、服务器会根据通信轮数是否达到迭代次数来判断训练是否结束,若完成训练,则进入步骤9输出最终预测模型;若未完成训练,则由服务器使用FedAvg算法聚合各个簇的客户端参数,获得更新的全局模型;
S9、联邦训练结束,输出最终预测模型。
作为本发明的一种优选实施方式:所述S2步骤包括:
S201、服务器从全部客户端中按比例随机选择部分客户端,并向这些客户端发送全局模型;
S202、客户端接收服务器发送的全局模型,并通过本地数据进行训练,最终得到更新梯度,并发送更新梯度给服务器,服务器进行更新梯度的聚合;
S203、重复执行S201-S202操作r次。
作为本发明的一种优选实施方式:所述S4步骤包括:
S401、服务器按照聚类结果进行簇内模型更新,各个簇的初始模型为当前的全局模型,并将更新后的全部簇模型发送给未参与客户端;
S402、未参与客户端接收服务器发送的全部簇模型,并交替计算经验损失,选择损失最小的模型最为自身的身份,并将身份发送个服务器;
S403、服务器接收未参与客户端的身份,并加入到聚类结果中。
作为本发明的一种优选实施方式:所述S6步骤包括:
S601、在各个簇中,服务器根据更新梯度构建相似性矩阵,并选取相似度较差的客户端,增加这些客户端的警惕值,减少其余客户端;
S602、服务器判断是否存在客户端的警惕值达到阈值,如果达到,则进入S7,并将该客户端的当前身份删除;
S603、服务器根据剩下的未达到警惕值阈值的客户端梯度更新进行聚合更新簇模型,并进入S8。
作为本发明的一种优选实施方式:所述S8步骤包括:
S801、重复执行S5-S6步骤的联邦学习通讯过程,设定期望的通讯轮数;
S802、当联邦训练达到指定的联邦学习通讯轮数,停止联邦学习通讯,输出最终预测模型。
本发明相比现有技术,具有以下有益效果:
本发明减轻了聚类对全局模型收敛的要求,不再要求全局模型达到一定程度的收敛以确保所有客户端正确分类;解决了一次性聚类中客户端分类错误的问题,实现了小规模客户端身份的动态调整,提高了聚类的容错性和训练收敛速度;减轻了服务器聚类需要全部客户端参与的要求,扩展了应用场景。
附图说明
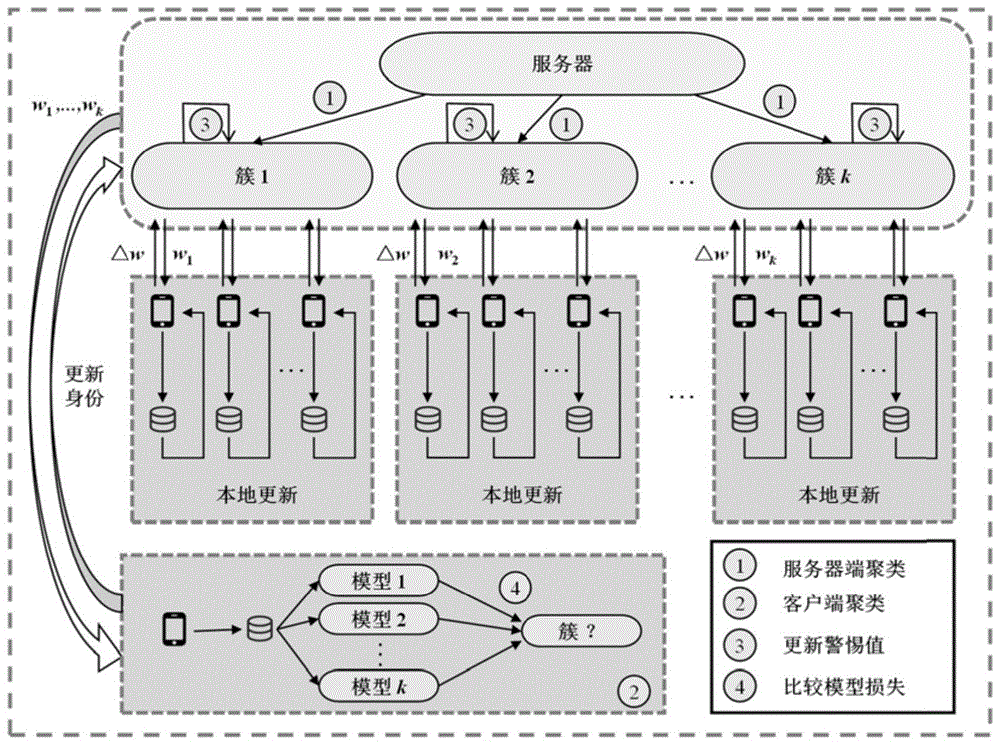
图1为本发明实施例提供的自动调整的双端聚类联邦学习方法的整体框架图;
图2为本发明实施例提供的自动调整策略的原理示意图;
图3为本发明实施例提供的自动调整策略的流程图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示为一种为本发明提出的自动调整的双端聚类联邦学习方法的整体框架。我们可在公共图像数据集(EMNIST、FashionMNIST、Cifar-10)进行评估,并选择合适的模型作为其初始化的模型。以Cifar-10数据集为例,使用VGG网络作为全局模型,网络分为两部分:一部分主要由卷积层和汇聚层组成,第二部分由全连接层组成。具体模型由五个VGG块和三个全连接层组成,且客户端和服务器的模型结构相同。
自动调整的双端聚类联邦学习方法其对应具体伪代码实施步骤如下:
算法1AACFL
输入:簇数k,训练轮数T,聚类轮数阈值κ,参与率q,聚类参与率q
输出:簇模型
1执行双端聚类,获得聚类结果C,簇模型
2始化客户端警惕值a
3在簇c内,从簇内全部客户端N
4服务器广播模型参数
5簇内计算
6在簇c内,计算
7
8未参与客户端S
9服务器根据s更新聚类结果C,当t 具体实施步骤如下: S1、服务器初始化一个全局模型的参数; S2、服务器随机挑选部分客户端参与,并发送全局模型给参与客户端,客户端利用模型和本地数据进行训练,并发送更新梯度给服务器进行聚合平均,重复执行r轮。对于第i个参与客户端,第t轮中本地更新向量如下: S3、服务器初始化客户端的警惕值v,根据参与客户端的更新梯度,构建相似性矩阵,通过矩阵执行聚类算法将参与客户端分组,其中计算余弦相似的公式如下: S4、服务器按照聚类结果将全局模型扩展成k个簇,每个簇内进行聚合平均更新,并将更新后的模型全部发送给未参与客户端,未参与客户端交替计算经验损失,比较模型性能,以确认自身身份,并将身份发送给服务器。双端聚类其对应具体伪代码实施步骤如下: 算法2双端聚类 输入:簇数k,聚类轮数阈值κ,参与率q,聚类参与率q 输出:聚类结果C={c 1初始化模型参数θ 2当前训练轮数t≠κ,则客户端选择比例为q,否则为q 3服务器广播模型参数θ 4参与客户端N 5当前训练轮数t≠κ,则计算 6计算 7计算 8未参与客户端N-N 9服务器根据s更新聚类结果C。 其中,客户端交替计算经验损失的公式如下: S5、客户端根据簇模型进行本地训练,并上传更新梯度。 S6、服务器在各个簇内构建相似性矩阵,选取相似性较差的客户端增加警惕值,剩余客户端减小警惕值,当警惕值达到阈值时,认为客户端的身份需要重新识别,进入S7,否则进入S8。其中选择相似性较差的客户端的公式为: 其中argmin S7、客户端根据全部簇模型交替计算经验损失,获取新的身份发送给服务器。 S8、服务器会根据通信轮数是否达到迭代次数来判断训练是否结束,若完成训练,则进入步骤9输出最终预测模型;若未完成训练,则由服务器聚合平均各个簇的客户端参数,获得更新的全局模型; S9、联邦训练结束,输出最终预测模型。 本实例评估方法有效性主要从模型的分类准确率和调整兰德指数来衡量,其计算公式如下所示: 其中,TP=真正例,TN=真负例,FP=假正例,FN=假负例。 其中,RI是兰德系数表达式,E(RI)是获取兰德系数的期望值。ARI的值越大意味着聚类结果与真实情况越吻合。 以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。